Apache Arrow is an open, language-independent columnar memory format, and in the previous articles in this series we have focused on memory representation and memory manipulation.
But for a database system or big data analytics platform, the data can’t and can’t be kept in memory all the time, and although memory is currently big and cheap enough, its volatility also dictates that we still have to serialise the data and store it on disk or some low-cost storage service (e.g., AWS’s S3, etc.) at a given moment.
So what is the storage format to serialise Arrow into, CSV, JSON, clearly these formats are not designed to maximise space efficiency and data retrieval capabilities. In the data analytics world, Apache Parquet is an open, column-oriented data storage format similar to Arrow, designed for efficient data encoding and retrieval and to maximise space efficiency.
Unlike Arrow, which is an in-memory format, Parquet is a data file format. In addition, Arrow and Parquet have each been designed with some trade-offs; Arrow is intended to be manipulated by a vectorised computational kernel to provide O(1) random access lookups on any array index, whereas Parquet employs a variable-length encoding scheme and block compression to drastically reduce the size of the data in order to maximise space efficiency, techniques that come at the cost of losing high-performance random-access lookups.
Parquet is also Apache’s top projects, most of the programming languages that implement Arrow also provide support for Arrow format and Parquet file conversion library implementation, Go is no exception. In this article, we will take a cursory look at how to use Go to read and write Parquet files, that is, Arrow and Parquet conversion.
Note: I’ll probably explain the detailed format of the Parquet file (which is also quite complex) in a follow-up post.
1. Introduction to Parquet
If we don’t talk about the Parquet file format first, it will be slightly difficult to understand what follows. Below is a schematic of the structure of a Parquet file:
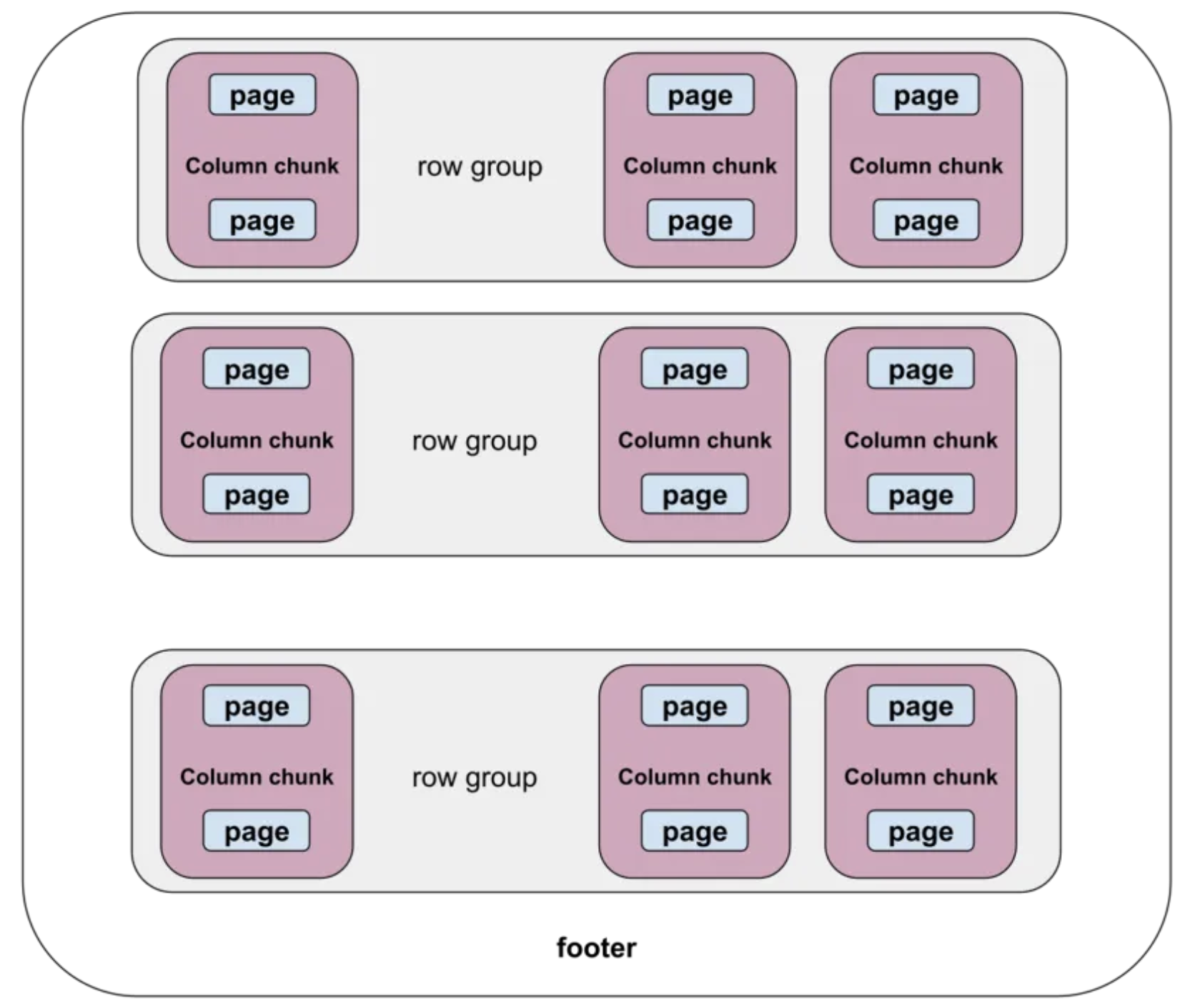
https://www.uber.com/blog/cost-efficiency-big-data
We see that the Parquet format file is divided into row groups, each of which consists of a column chunk for each column. Considering the characteristics of disk storage, each column chunk is further divided into pages. This column chunk of many isomorphic types of column values can be encoded and compressed and stored in each page. The following is a diagram of how data is stored in a Parquet file from the official Parquet documentation.
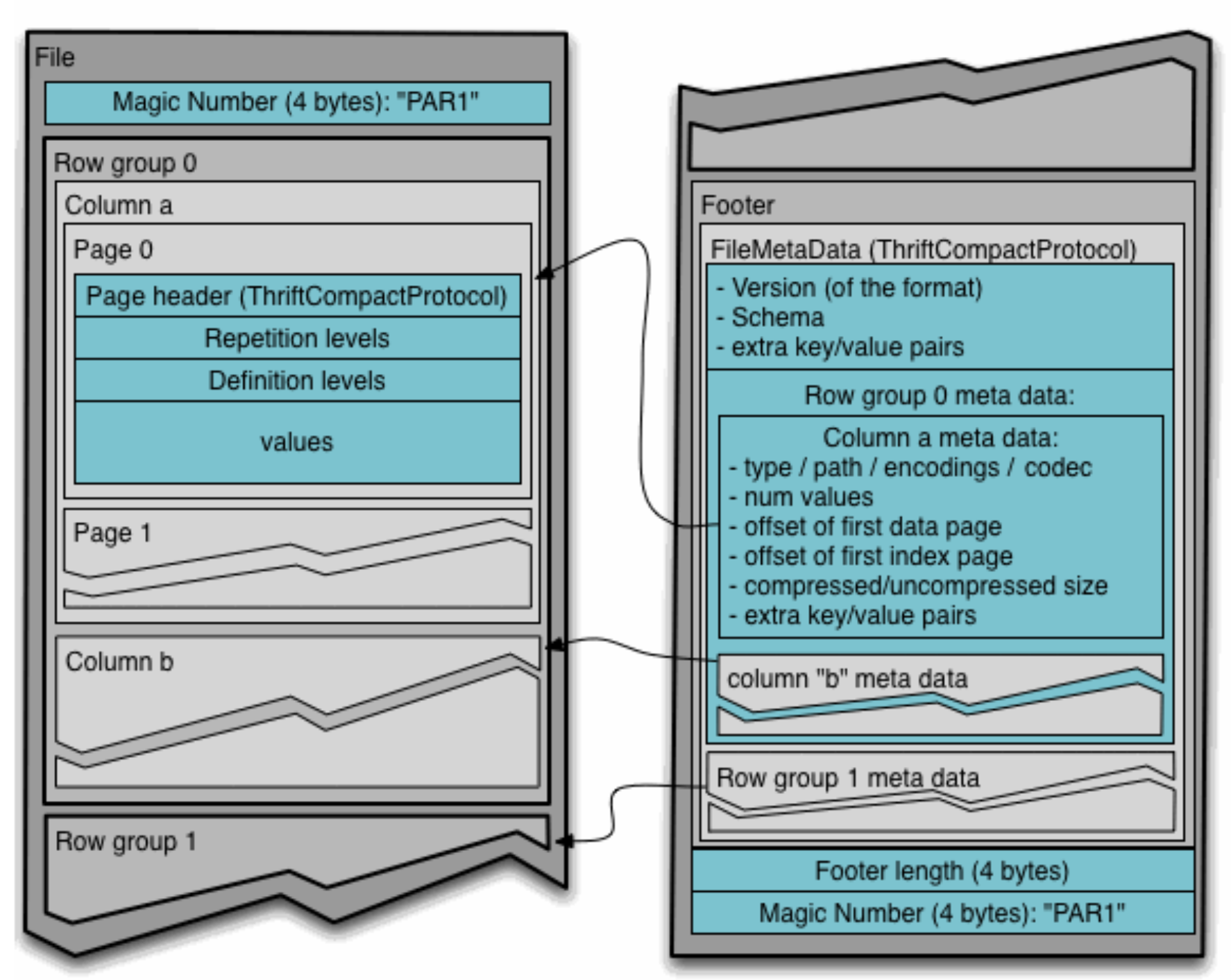
We see that Parquet is sorted backward in row group order, and column chunks in each row group are also sorted backward in column order.
Note: Regarding advanced concepts such as REPETION LEVEL and DEFINITION LEVEL in the above figure, they will not be an obstacle to understanding the content of this paper, and we will leave the systematic explanation to the subsequent articles.
2. Arrow Table <-> Parquet
With the initial knowledge of the Parquet file format above, let’s next look at how to convert between Arrow and Parquet using Go.
In the article Advanced Data Structures, we learned about two advanced structures, Arrow Table and Record Batch. Next we’ll look at how to convert a Table or Record to a Parquet. Once the conversion of advanced structures like Table and Record Batch is done, then those simple data types in Arrow will not be a problem. Moreover, in real projects, we face more advanced data structures of Arrow (Table or Record) and Parquet conversion.
2.1 Table -> Parquet
As we know from the Advanced Data Structures article, each column of an Arrow Table is essentially a Schema+Chunked Array, which has a high degree of compatibility with the Parquet file format.
Arrow Go’s parquet implementation provides good support for Tables, we can persist an in-memory Arrow Table to a Parquet file through a WriteTable function, let’s take a look at the following example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
|
// flat_table_to_parquet.go
package main
import (
"os"
"github.com/apache/arrow/go/v13/arrow"
"github.com/apache/arrow/go/v13/arrow/array"
"github.com/apache/arrow/go/v13/arrow/memory"
"github.com/apache/arrow/go/v13/parquet/pqarrow"
)
func main() {
schema := arrow.NewSchema(
[]arrow.Field{
{Name: "col1", Type: arrow.PrimitiveTypes.Int32},
{Name: "col2", Type: arrow.PrimitiveTypes.Float64},
{Name: "col3", Type: arrow.BinaryTypes.String},
},
nil,
)
col1 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
ib := array.NewInt32Builder(memory.DefaultAllocator)
defer ib.Release()
ib.AppendValues([]int32{1, 2, 3}, nil)
i1 := ib.NewInt32Array()
defer i1.Release()
ib.AppendValues([]int32{4, 5, 6, 7, 8, 9, 10}, nil)
i2 := ib.NewInt32Array()
defer i2.Release()
c := arrow.NewChunked(
arrow.PrimitiveTypes.Int32,
[]arrow.Array{i1, i2},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(0), chunk)
}()
defer col1.Release()
col2 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
fb := array.NewFloat64Builder(memory.DefaultAllocator)
defer fb.Release()
fb.AppendValues([]float64{1.1, 2.2, 3.3, 4.4, 5.5}, nil)
f1 := fb.NewFloat64Array()
defer f1.Release()
fb.AppendValues([]float64{6.6, 7.7}, nil)
f2 := fb.NewFloat64Array()
defer f2.Release()
fb.AppendValues([]float64{8.8, 9.9, 10.0}, nil)
f3 := fb.NewFloat64Array()
defer f3.Release()
c := arrow.NewChunked(
arrow.PrimitiveTypes.Float64,
[]arrow.Array{f1, f2, f3},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(1), chunk)
}()
defer col2.Release()
col3 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
sb := array.NewStringBuilder(memory.DefaultAllocator)
defer sb.Release()
sb.AppendValues([]string{"s1", "s2"}, nil)
s1 := sb.NewStringArray()
defer s1.Release()
sb.AppendValues([]string{"s3", "s4"}, nil)
s2 := sb.NewStringArray()
defer s2.Release()
sb.AppendValues([]string{"s5", "s6", "s7", "s8", "s9", "s10"}, nil)
s3 := sb.NewStringArray()
defer s3.Release()
c := arrow.NewChunked(
arrow.BinaryTypes.String,
[]arrow.Array{s1, s2, s3},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(2), chunk)
}()
defer col3.Release()
var tbl arrow.Table
tbl = array.NewTable(schema, []arrow.Column{*col1, *col2, *col3}, -1)
defer tbl.Release()
f, err := os.Create("flat_table.parquet")
if err != nil {
panic(err)
}
defer f.Close()
err = pqarrow.WriteTable(tbl, f, 1024, nil, pqarrow.DefaultWriterProps())
if err != nil {
panic(err)
}
}
|
We created a Table with three columns based on arrow’s Builder pattern and NewTable (the table creation example is from the Advanced Data Structures article). Once we have the table, we call pqarrow’s WriteTable function directly to write the table to a parquet file.
Let’s run the above code:
1
|
$go run flat_table_to_parquet.go
|
After executing the above command, a flat_table.parquet file will appear in the current directory!
How do we view the contents of the file to verify that the data written is consistent with the table? arrow go’s parquet implementation provides a parquet_reader tool can help us do this, you can execute the following command to install this tool.
1
|
$go install github.com/apache/arrow/go/v13/parquet/cmd/parquet_reader@latest
|
After that we can execute the following command to view the contents of the flat_table.parquet file we just generated.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
$parquet_reader flat_table.parquet
File name: flat_table.parquet
Version: v2.6
Created By: parquet-go version 13.0.0-SNAPSHOT
Num Rows: 10
Number of RowGroups: 1
Number of Real Columns: 3
Number of Columns: 3
Number of Selected Columns: 3
Column 0: col1 (INT32/INT_32)
Column 1: col2 (DOUBLE)
Column 2: col3 (BYTE_ARRAY/UTF8)
--- Row Group: 0 ---
--- Total Bytes: 396 ---
--- Rows: 10 ---
Column 0
Values: 10, Min: 1, Max: 10, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 111, Compressed Size: 111
Column 1
Values: 10, Min: 1.1, Max: 10, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 169, Compressed Size: 169
Column 2
Values: 10, Min: [115 49], Max: [115 57], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 116, Compressed Size: 116
--- Values ---
col1 |col2 |col3 |
1 |1.100000 |s1 |
2 |2.200000 |s2 |
3 |3.300000 |s3 |
4 |4.400000 |s4 |
5 |5.500000 |s5 |
6 |6.600000 |s6 |
7 |7.700000 |s7 |
8 |8.800000 |s8 |
9 |9.900000 |s9 |
10 |10.000000 |s10 |
|
The parquet_reader lists the meta data of the parquet file and the values of the COLUMN columns in each row group, which, from the output, is consistent with the data in our arrow table.
Let’s go back to the WriteTable function, which has the following prototype:
1
2
|
func WriteTable(tbl arrow.Table, w io.Writer, chunkSize int64,
props *parquet.WriterProperties, arrprops ArrowWriterProperties) error
|
Here we talk about the first three parameters of WriteTable, the first is the structure of the arrow table obtained through NewTable, the second parameter is easy to understand, is a writable file descriptor, we can easily get through the os.Create, the third parameter for the chunkSize. What is this chunkSize? Will it have an impact on the parquet file writing results? In fact, this chunkSize is the number of rows in each row group. At the same time parquet through the chunkSize can also calculate the “arrow table” to “parquet” file after the conversion of how many “row group”.
The value of chunkSize in our example is 1024, so there is only one row group in the entire parquet file, so let’s change it to 5 and take a look at the contents of the output parquet file:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
$parquet_reader flat_table.parquet
File name: flat_table.parquet
Version: v2.6
Created By: parquet-go version 13.0.0-SNAPSHOT
Num Rows: 10
Number of RowGroups: 2
Number of Real Columns: 3
Number of Columns: 3
Number of Selected Columns: 3
Column 0: col1 (INT32/INT_32)
Column 1: col2 (DOUBLE)
Column 2: col3 (BYTE_ARRAY/UTF8)
--- Row Group: 0 ---
--- Total Bytes: 288 ---
--- Rows: 5 ---
Column 0
Values: 5, Min: 1, Max: 5, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 86, Compressed Size: 86
Column 1
Values: 5, Min: 1.1, Max: 5.5, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 122, Compressed Size: 122
Column 2
Values: 5, Min: [115 49], Max: [115 53], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 80, Compressed Size: 80
--- Values ---
col1 |col2 |col3 |
1 |1.100000 |s1 |
2 |2.200000 |s2 |
3 |3.300000 |s3 |
4 |4.400000 |s4 |
5 |5.500000 |s5 |
--- Row Group: 1 ---
--- Total Bytes: 290 ---
--- Rows: 5 ---
Column 0
Values: 5, Min: 6, Max: 10, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 86, Compressed Size: 86
Column 1
Values: 5, Min: 6.6, Max: 10, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 122, Compressed Size: 122
Column 2
Values: 5, Min: [115 49 48], Max: [115 57], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 82, Compressed Size: 82
--- Values ---
col1 |col2 |col3 |
6 |6.600000 |s6 |
7 |7.700000 |s7 |
8 |8.800000 |s8 |
9 |9.900000 |s9 |
10 |10.000000 |s10 |
|
When the chunkSize value is 5, the parquet file’s row group becomes 2, and then the parquet_reader tool will output their meta information and column value information according to the format of the two row groups respectively.
Next, let’s take a look at how to read data from the generated parquet file and convert it to an arrow table.
2.2 Table <- Parquet
Like the WriteTable function, arrow provides a ReadTable function to read a parquet file and convert it to an in-memory arrow table.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
// flat_table_from_parquet.go
func main() {
f, err := os.Open("flat_table.parquet")
if err != nil {
panic(err)
}
defer f.Close()
tbl, err := pqarrow.ReadTable(context.Background(), f, parquet.NewReaderProperties(memory.DefaultAllocator),
pqarrow.ArrowReadProperties{}, memory.DefaultAllocator)
if err != nil {
panic(err)
}
dumpTable(tbl)
}
func dumpTable(tbl arrow.Table) {
s := tbl.Schema()
fmt.Println(s)
fmt.Println("------")
fmt.Println("the count of table columns=", tbl.NumCols())
fmt.Println("the count of table rows=", tbl.NumRows())
fmt.Println("------")
for i := 0; i < int(tbl.NumCols()); i++ {
col := tbl.Column(i)
fmt.Printf("arrays in column(%s):\n", col.Name())
chunk := col.Data()
for _, arr := range chunk.Chunks() {
fmt.Println(arr)
}
fmt.Println("------")
}
}
|
We see that ReadTable is very simple to use, because the parquet file contains meta information, we call ReadTable, some parameters use the default value or zero value can be.
Let’s run the above code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
$go run flat_table_from_parquet.go
schema:
fields: 3
- col1: type=int32
metadata: ["PARQUET:field_id": "-1"]
- col2: type=float64
metadata: ["PARQUET:field_id": "-1"]
- col3: type=utf8
metadata: ["PARQUET:field_id": "-1"]
------
the count of table columns= 3
the count of table rows= 10
------
arrays in column(col1):
[1 2 3 4 5 6 7 8 9 10]
------
arrays in column(col2):
[1.1 2.2 3.3 4.4 5.5 6.6 7.7 8.8 9.9 10]
------
arrays in column(col3):
["s1" "s2" "s3" "s4" "s5" "s6" "s7" "s8" "s9" "s10"]
------
|
2.3 Table -> Parquet (compression)
As mentioned earlier, the design of the Parquet file format takes into account the efficiency of space utilisation, plus it is a column-oriented storage format, Parquet supports the compression of columnar data storage, and supports the selection of different compression algorithms for different columns.
WriteTable called in the previous example is not compressed by default, which can be seen from the meta-information of the columns read by parquet_reader (e.g., the following Compression: UNCOMPRESSED):
1
2
3
4
|
Column 0
Values: 10, Min: 1, Max: 10, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 111, Compressed Size: 111
|
We can also specify the compression algorithm for each column in the WriteTable via the parquet.WriterProperties parameter, as in the following example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// flat_table_to_parquet_compressed.go
var tbl arrow.Table
tbl = array.NewTable(schema, []arrow.Column{*col1, *col2, *col3}, -1)
defer tbl.Release()
f, err := os.Create("flat_table_compressed.parquet")
if err != nil {
panic(err)
}
defer f.Close()
wp := parquet.NewWriterProperties(parquet.WithCompression(compress.Codecs.Snappy),
parquet.WithCompressionFor("col1", compress.Codecs.Brotli))
err = pqarrow.WriteTable(tbl, f, 1024, wp, pqarrow.DefaultWriterProps())
if err != nil {
panic(err)
}
|
In this code, we build a new WriterProperties via parquet.NewWriterProperties, which uses Snappy compression for all columns by default, and Brotli algorithm compression for col1 column. We write the compressed data to the flat_table_compressed.parquet file. Run flat_table_to_parquet_compressed.go using go run and then use parquet_reader to view the file flat_table_compressed.parquet to get the following result.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
$go run flat_table_to_parquet_compressed.go
$parquet_reader flat_table_compressed.parquet
File name: flat_table_compressed.parquet
Version: v2.6
Created By: parquet-go version 13.0.0-SNAPSHOT
Num Rows: 10
Number of RowGroups: 1
Number of Real Columns: 3
Number of Columns: 3
Number of Selected Columns: 3
Column 0: col1 (INT32/INT_32)
Column 1: col2 (DOUBLE)
Column 2: col3 (BYTE_ARRAY/UTF8)
--- Row Group: 0 ---
--- Total Bytes: 352 ---
--- Rows: 10 ---
Column 0
Values: 10, Min: 1, Max: 10, Null Values: 0, Distinct Values: 0
Compression: BROTLI, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 111, Compressed Size: 98
Column 1
Values: 10, Min: 1.1, Max: 10, Null Values: 0, Distinct Values: 0
Compression: SNAPPY, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 168, Compressed Size: 148
Column 2
Values: 10, Min: [115 49], Max: [115 57], Null Values: 0, Distinct Values: 0
Compression: SNAPPY, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 116, Compressed Size: 106
--- Values ---
col1 |col2 |col3 |
1 |1.100000 |s1 |
2 |2.200000 |s2 |
3 |3.300000 |s3 |
4 |4.400000 |s4 |
5 |5.500000 |s5 |
6 |6.600000 |s6 |
7 |7.700000 |s7 |
8 |8.800000 |s8 |
9 |9.900000 |s9 |
10 |10.000000 |s10 |
|
From the output of parquet_reader, we can see: the Compression information of each Column is no longer UNCOMPRESSED, and the three columns after compression of the Size and uncompressed compared to a certain reduction.
1
2
3
4
5
6
|
Column 0:
Compression: BROTLI, Uncompressed Size: 111, Compressed Size: 98
Column 1:
Compression: SNAPPY, Uncompressed Size: 168, Compressed Size: 148
Column 2:
Compression: SNAPPY, Uncompressed Size: 116, Compressed Size: 106
|
The compression algorithm can also be seen in the file size comparison.
1
2
|
-rw-r--r-- 1 tonybai staff 786 7 22 08:06 flat_table.parquet
-rw-r--r-- 1 tonybai staff 742 7 20 13:19 flat_table_compressed.parquet
|
Go’s parquet implementation supports multiple compression algorithms.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
// github.com/apache/arrow/go/parquet/compress/compress.go
var Codecs = struct {
Uncompressed Compression
Snappy Compression
Gzip Compression
// LZO is unsupported in this library since LZO license is incompatible with Apache License
Lzo Compression
Brotli Compression
// LZ4 unsupported in this library due to problematic issues between the Hadoop LZ4 spec vs regular lz4
// see: http://mail-archives.apache.org/mod_mbox/arrow-dev/202007.mbox/%3CCAAri41v24xuA8MGHLDvgSnE+7AAgOhiEukemW_oPNHMvfMmrWw@mail.gmail.com%3E
Lz4 Compression
Zstd Compression
}{
Uncompressed: Compression(parquet.CompressionCodec_UNCOMPRESSED),
Snappy: Compression(parquet.CompressionCodec_SNAPPY),
Gzip: Compression(parquet.CompressionCodec_GZIP),
Lzo: Compression(parquet.CompressionCodec_LZO),
Brotli: Compression(parquet.CompressionCodec_BROTLI),
Lz4: Compression(parquet.CompressionCodec_LZ4),
Zstd: Compression(parquet.CompressionCodec_ZSTD),
}
|
You just need to choose the most suitable compression algorithm based on the type of your columns.
2.4 Table <- Parquet (compression)
Next, let’s read the compressed Parquet, do we need to pass in special properties when reading the compressed Parquet? The answer is no! Because the Parquet file stored in the metadata, can help ReadTable using the corresponding algorithm to decompress and extract information:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// flat_table_from_parquet_compressed.go
func main() {
f, err := os.Open("flat_table_compressed.parquet")
if err != nil {
panic(err)
}
defer f.Close()
tbl, err := pqarrow.ReadTable(context.Background(), f, parquet.NewReaderProperties(memory.DefaultAllocator),
pqarrow.ArrowReadProperties{}, memory.DefaultAllocator)
if err != nil {
panic(err)
}
dumpTable(tbl)
}
|
Running this program allows us to read the compressed parquet file.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
$go run flat_table_from_parquet_compressed.go
schema:
fields: 3
- col1: type=int32
metadata: ["PARQUET:field_id": "-1"]
- col2: type=float64
metadata: ["PARQUET:field_id": "-1"]
- col3: type=utf8
metadata: ["PARQUET:field_id": "-1"]
------
the count of table columns= 3
the count of table rows= 10
------
arrays in column(col1):
[1 2 3 4 5 6 7 8 9 10]
------
arrays in column(col2):
[1.1 2.2 3.3 4.4 5.5 6.6 7.7 8.8 9.9 10]
------
arrays in column(col3):
["s1" "s2" "s3" "s4" "s5" "s6" "s7" "s8" "s9" "s10"]
------
|
Next, let’s see how another advanced data structure in Arrow, “Record Batch”, can be converted to “Parquet” file format.
3. Arrow Record Batch <-> Parquet
Note: You can revisit the Advanced Data Structures article first to understand the concept of Record Batch.
3.1 Record Batch -> Parquet
The Arrow Go implementation treats a Record Batch as a Row group. The following program writes three records to a Parquet file.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
// flat_record_to_parquet.go
func main() {
var records []arrow.Record
schema := arrow.NewSchema(
[]arrow.Field{
{Name: "archer", Type: arrow.BinaryTypes.String},
{Name: "location", Type: arrow.BinaryTypes.String},
{Name: "year", Type: arrow.PrimitiveTypes.Int16},
},
nil,
)
rb := array.NewRecordBuilder(memory.DefaultAllocator, schema)
defer rb.Release()
for i := 0; i < 3; i++ {
postfix := strconv.Itoa(i)
rb.Field(0).(*array.StringBuilder).AppendValues([]string{"tony" + postfix, "amy" + postfix, "jim" + postfix}, nil)
rb.Field(1).(*array.StringBuilder).AppendValues([]string{"beijing" + postfix, "shanghai" + postfix, "chengdu" + postfix}, nil)
rb.Field(2).(*array.Int16Builder).AppendValues([]int16{1992 + int16(i), 1993 + int16(i), 1994 + int16(i)}, nil)
rec := rb.NewRecord()
records = append(records, rec)
}
// write to parquet
f, err := os.Create("flat_record.parquet")
if err != nil {
panic(err)
}
props := parquet.NewWriterProperties()
writer, err := pqarrow.NewFileWriter(schema, f, props,
pqarrow.DefaultWriterProps())
if err != nil {
panic(err)
}
defer writer.Close()
for _, rec := range records {
if err := writer.Write(rec); err != nil {
panic(err)
}
rec.Release()
}
|
Unlike calling WriteTable to write table to parquet file, here we create a FileWriter and write the built Record Batch one by one through FileWriter. Run the above code to generate flat_record.parquet file and use parquet_reader to display the contents of the file.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
$go run flat_record_to_parquet.go
$parquet_reader flat_record.parquet
File name: flat_record.parquet
Version: v2.6
Created By: parquet-go version 13.0.0-SNAPSHOT
Num Rows: 9
Number of RowGroups: 3
Number of Real Columns: 3
Number of Columns: 3
Number of Selected Columns: 3
Column 0: archer (BYTE_ARRAY/UTF8)
Column 1: location (BYTE_ARRAY/UTF8)
Column 2: year (INT32/INT_16)
--- Row Group: 0 ---
--- Total Bytes: 255 ---
--- Rows: 3 ---
Column 0
Values: 3, Min: [97 109 121 48], Max: [116 111 110 121 48], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 79, Compressed Size: 79
Column 1
Values: 3, Min: [98 101 105 106 105 110 103 48], Max: [115 104 97 110 103 104 97 105 48], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 99, Compressed Size: 99
Column 2
Values: 3, Min: 1992, Max: 1994, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 77, Compressed Size: 77
--- Values ---
archer |location |year |
tony0 |beijing0 |1992 |
amy0 |shanghai0 |1993 |
jim0 |chengdu0 |1994 |
--- Row Group: 1 ---
--- Total Bytes: 255 ---
--- Rows: 3 ---
Column 0
Values: 3, Min: [97 109 121 49], Max: [116 111 110 121 49], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 79, Compressed Size: 79
Column 1
Values: 3, Min: [98 101 105 106 105 110 103 49], Max: [115 104 97 110 103 104 97 105 49], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 99, Compressed Size: 99
Column 2
Values: 3, Min: 1993, Max: 1995, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 77, Compressed Size: 77
--- Values ---
archer |location |year |
tony1 |beijing1 |1993 |
amy1 |shanghai1 |1994 |
jim1 |chengdu1 |1995 |
--- Row Group: 2 ---
--- Total Bytes: 255 ---
--- Rows: 3 ---
Column 0
Values: 3, Min: [97 109 121 50], Max: [116 111 110 121 50], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 79, Compressed Size: 79
Column 1
Values: 3, Min: [98 101 105 106 105 110 103 50], Max: [115 104 97 110 103 104 97 105 50], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 99, Compressed Size: 99
Column 2
Values: 3, Min: 1994, Max: 1996, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 77, Compressed Size: 77
--- Values ---
archer |location |year |
tony2 |beijing2 |1994 |
amy2 |shanghai2 |1995 |
jim2 |chengdu2 |1996 |
|
We see that parquet_reader outputs metadata and column values for each of the three row groups, each corresponding to a record we wrote.
So how is reading such a parquet file different from a ReadTable? Let’s move on.
3.2 Record Batch <- Parquet
The following is used for reading.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
// flat_record_from_parquet.go
func main() {
f, err := os.Open("flat_record.parquet")
if err != nil {
panic(err)
}
defer f.Close()
rdr, err := file.NewParquetReader(f)
if err != nil {
panic(err)
}
defer rdr.Close()
arrRdr, err := pqarrow.NewFileReader(rdr,
pqarrow.ArrowReadProperties{
BatchSize: 3,
}, memory.DefaultAllocator)
if err != nil {
panic(err)
}
s, _ := arrRdr.Schema()
fmt.Println(*s)
rr, err := arrRdr.GetRecordReader(context.Background(), nil, nil)
if err != nil {
panic(err)
}
for {
rec, err := rr.Read()
if err != nil && err != io.EOF {
panic(err)
}
if err == io.EOF {
break
}
fmt.Println(rec)
}
}
|
We see that compared to converting a parquet to a table, converting a parquet to a record is slightly more complicated, and one of the keys here is the BatchSize field in the ArrowReadProperties passed in when calling NewFileReader, and in order to read out the record correctly, the To read the record correctly, this BatchSize needs to be filled out appropriately. This BatchSize tells the reader the length of each read record batch, that is, the number of rows. Here is passed in 3, that is, 3 rows for a Recordd batch.
The following is the result of running the above code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
$go run flat_record_from_parquet.go
{[{archer 0x26ccc00 false {[PARQUET:field_id] [-1]}} {location 0x26ccc00 false {[PARQUET:field_id] [-1]}} {year 0x26ccc00 false {[PARQUET:field_id] [-1]}}] map[archer:[0] location:[1] year:[2]] {[] []} 0}
record:
schema:
fields: 3
- archer: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- location: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- year: type=int16
metadata: ["PARQUET:field_id": "-1"]
rows: 3
col[0][archer]: ["tony0" "amy0" "jim0"]
col[1][location]: ["beijing0" "shanghai0" "chengdu0"]
col[2][year]: [1992 1993 1994]
record:
schema:
fields: 3
- archer: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- location: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- year: type=int16
metadata: ["PARQUET:field_id": "-1"]
rows: 3
col[0][archer]: ["tony1" "amy1" "jim1"]
col[1][location]: ["beijing1" "shanghai1" "chengdu1"]
col[2][year]: [1993 1994 1995]
record:
schema:
fields: 3
- archer: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- location: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- year: type=int16
metadata: ["PARQUET:field_id": "-1"]
rows: 3
col[0][archer]: ["tony2" "amy2" "jim2"]
col[1][location]: ["beijing2" "shanghai2" "chengdu2"]
col[2][year]: [1994 1995 1996]
|
We see: every 3 rows are read out as a record. If we change the BatchSize to 5, the output is as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
$go run flat_record_from_parquet.go
{[{archer 0x26ccc00 false {[PARQUET:field_id] [-1]}} {location 0x26ccc00 false {[PARQUET:field_id] [-1]}} {year 0x26ccc00 false {[PARQUET:field_id] [-1]}}] map[archer:[0] location:[1] year:[2]] {[] []} 0}
record:
schema:
fields: 3
- archer: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- location: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- year: type=int16
metadata: ["PARQUET:field_id": "-1"]
rows: 5
col[0][archer]: ["tony0" "amy0" "jim0" "tony1" "amy1"]
col[1][location]: ["beijing0" "shanghai0" "chengdu0" "beijing1" "shanghai1"]
col[2][year]: [1992 1993 1994 1993 1994]
record:
schema:
fields: 3
- archer: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- location: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- year: type=int16
metadata: ["PARQUET:field_id": "-1"]
rows: 4
col[0][archer]: ["jim1" "tony2" "amy2" "jim2"]
col[1][location]: ["chengdu1" "beijing2" "shanghai2" "chengdu2"]
col[2][year]: [1995 1994 1995 1996]
|
This time, the first 5 rows are used as a record and the last 4 rows are used as another record.
Of course, we can also use the code in flat_table_from_parquet.go to read flat_record.parquet (change the name of the read file to flat_record.parquet), except that since the parquet data will be converted to a table, the output will change to the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
$go run flat_table_from_parquet.go
schema:
fields: 3
- archer: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- location: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- year: type=int16
metadata: ["PARQUET:field_id": "-1"]
------
the count of table columns= 3
the count of table rows= 9
------
arrays in column(archer):
["tony0" "amy0" "jim0" "tony1" "amy1" "jim1" "tony2" "amy2" "jim2"]
------
arrays in column(location):
["beijing0" "shanghai0" "chengdu0" "beijing1" "shanghai1" "chengdu1" "beijing2" "shanghai2" "chengdu2"]
------
arrays in column(year):
[1992 1993 1994 1993 1994 1995 1994 1995 1996]
------
|
3.3 Record Batch -> Parquet (compression)
Recod also supports compression to write Parquet, the principle is the same as the previous table compression storage, are set by the WriterProperties to achieve.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// flat_record_to_parquet_compressed.go
func main() {
... ...
f, err := os.Create("flat_record_compressed.parquet")
if err != nil {
panic(err)
}
defer f.Close()
props := parquet.NewWriterProperties(parquet.WithCompression(compress.Codecs.Zstd),
parquet.WithCompressionFor("year", compress.Codecs.Brotli))
writer, err := pqarrow.NewFileWriter(schema, f, props,
pqarrow.DefaultWriterProps())
if err != nil {
panic(err)
}
defer writer.Close()
for _, rec := range records {
if err := writer.Write(rec); err != nil {
panic(err)
}
rec.Release()
}
}
|
But this time for arrow.string and arrow.int16 type compression effect is very “poor”.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
$parquet_reader flat_record_compressed.parquet
File name: flat_record_compressed.parquet
Version: v2.6
Created By: parquet-go version 13.0.0-SNAPSHOT
Num Rows: 9
Number of RowGroups: 3
Number of Real Columns: 3
Number of Columns: 3
Number of Selected Columns: 3
Column 0: archer (BYTE_ARRAY/UTF8)
Column 1: location (BYTE_ARRAY/UTF8)
Column 2: year (INT32/INT_16)
--- Row Group: 0 ---
--- Total Bytes: 315 ---
--- Rows: 3 ---
Column 0
Values: 3, Min: [97 109 121 48], Max: [116 111 110 121 48], Null Values: 0, Distinct Values: 0
Compression: ZSTD, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 79, Compressed Size: 105
Column 1
Values: 3, Min: [98 101 105 106 105 110 103 48], Max: [115 104 97 110 103 104 97 105 48], Null Values: 0, Distinct Values: 0
Compression: ZSTD, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 99, Compressed Size: 125
Column 2
Values: 3, Min: 1992, Max: 1994, Null Values: 0, Distinct Values: 0
Compression: BROTLI, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 77, Compressed Size: 85
--- Values ---
archer |location |year |
tony0 |beijing0 |1992 |
amy0 |shanghai0 |1993 |
jim0 |chengdu0 |1994 |
--- Row Group: 1 ---
--- Total Bytes: 315 ---
--- Rows: 3 ---
Column 0
Values: 3, Min: [97 109 121 49], Max: [116 111 110 121 49], Null Values: 0, Distinct Values: 0
Compression: ZSTD, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 79, Compressed Size: 105
Column 1
Values: 3, Min: [98 101 105 106 105 110 103 49], Max: [115 104 97 110 103 104 97 105 49], Null Values: 0, Distinct Values: 0
Compression: ZSTD, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 99, Compressed Size: 125
Column 2
Values: 3, Min: 1993, Max: 1995, Null Values: 0, Distinct Values: 0
Compression: BROTLI, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 77, Compressed Size: 85
--- Values ---
archer |location |year |
tony1 |beijing1 |1993 |
amy1 |shanghai1 |1994 |
jim1 |chengdu1 |1995 |
--- Row Group: 2 ---
--- Total Bytes: 315 ---
--- Rows: 3 ---
Column 0
Values: 3, Min: [97 109 121 50], Max: [116 111 110 121 50], Null Values: 0, Distinct Values: 0
Compression: ZSTD, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 79, Compressed Size: 105
Column 1
Values: 3, Min: [98 101 105 106 105 110 103 50], Max: [115 104 97 110 103 104 97 105 50], Null Values: 0, Distinct Values: 0
Compression: ZSTD, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 99, Compressed Size: 125
Column 2
Values: 3, Min: 1994, Max: 1996, Null Values: 0, Distinct Values: 0
Compression: BROTLI, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 77, Compressed Size: 85
--- Values ---
archer |location |year |
tony2 |beijing2 |1994 |
amy2 |shanghai2 |1995 |
jim2 |chengdu2 |1996 |
|
The more compressed it is, the larger the size of the parquet file will be. Of course, this issue is not the focus of this article, just remind you of the importance of choosing the appropriate compression algorithm.
3.4 Record Batch <- Parquet(compressed)
Like reading table-converted compressed parquet files, reading record-converted compressed parquet does not require any special setup, just use flat_record_from_parquet.go (you need to change the name of the file you are reading), so I won’t go into details here.
4. Summary
The purpose of this article is to introduce the basic methods of using Go to convert Arrow and Parquet files to each other, we take two high-level data structures as examples, table and record, respectively, to introduce the methods of reading and writing parquet files and compression of parquet files.
Of course, the examples in this article are “flat (flat)” simple examples, parquet file also supports more complex nested data, we will follow up in-depth explanation of the parquet format of the article mentioned.