
After studying the previous two articles, we know about the various Arrow array types and their layouts in memory, and we understand some of the mechanisms and usage principles of the Go arrow implementation for memory management.
Arrow’s array type is just a fixed-length sequence of values of the same type. In practice, the array type more often than not serves as a base type, and we need more advanced data structures that have the ability to combine base types. In this article, we will look at the Arrow specification and some of the implementation of the advanced data structures provided, including Record Batch, Chunked Array and Table.
Let’s start with Record Batch.
1. Record Batch
The name Record reminds me of Record in the Pascal programming language. In Pascal, the role of Record is roughly similar to that of Struct in Go. , which is also a collection of heterogeneous fields. Here is an example of a Record from the book “In-Memory Analytics with Apache Arrow”:
1
2
3
4
5
6
|
// golang
type Archer struct {
archer string
location string
year int16
}
|
A Record Batch is, as the name suggests, a batch of Records, i.e. a collection of Records: [N]Archer.
If we take the Record fields as columns and each Record in the batch as a row, we can get the structure as shown in the following diagram:
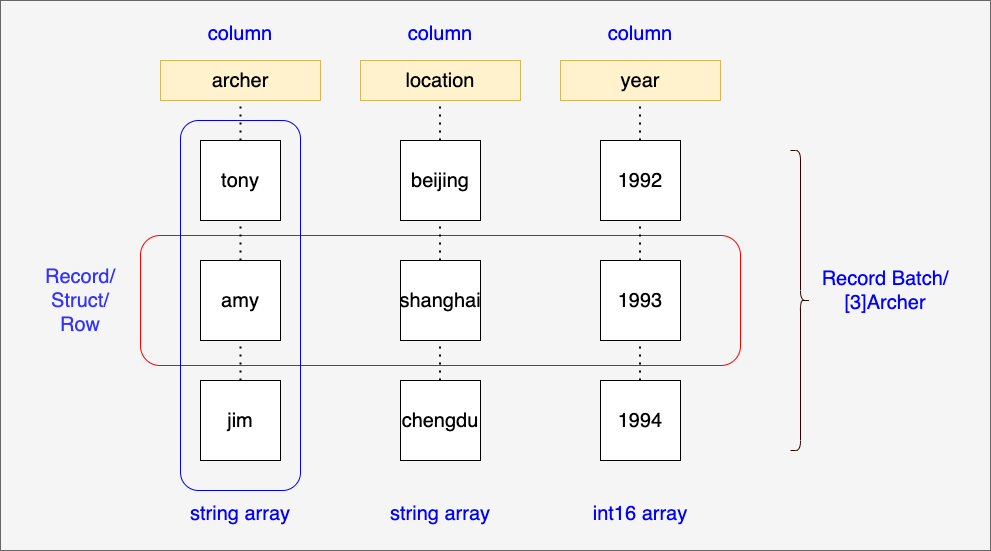
The Go Arrow implementation does not use the name “Record Batch” directly, but instead uses “Record”, which actually represents a Record Batch. The following is the Record interface defined by the Go Arrow implementation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// github.com/apache/arrow/go/arrow/record.go
// Record is a collection of equal-length arrays matching a particular Schema.
// Also known as a RecordBatch in the spec and in some implementations.
//
// It is also possible to construct a Table from a collection of Records that
// all have the same schema.
type Record interface {
json.Marshaler
Release()
Retain()
Schema() *Schema
NumRows() int64
NumCols() int64
Columns() []Array
Column(i int) Array
ColumnName(i int) string
SetColumn(i int, col Array) (Record, error)
// NewSlice constructs a zero-copy slice of the record with the indicated
// indices i and j, corresponding to array[i:j].
// The returned record must be Release()'d after use.
//
// NewSlice panics if the slice is outside the valid range of the record array.
// NewSlice panics if j < i.
NewSlice(i, j int64) Record
}
|
We can still use the Builder pattern to create an arrow.Record, and below we’ll use Go code to create [N]Archer the Record Batch:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// record_batch.go
func main() {
schema := arrow.NewSchema(
[]arrow.Field{
{Name: "archer", Type: arrow.BinaryTypes.String},
{Name: "location", Type: arrow.BinaryTypes.String},
{Name: "year", Type: arrow.PrimitiveTypes.Int16},
},
nil,
)
rb := array.NewRecordBuilder(memory.DefaultAllocator, schema)
defer rb.Release()
rb.Field(0).(*array.StringBuilder).AppendValues([]string{"tony", "amy", "jim"}, nil)
rb.Field(1).(*array.StringBuilder).AppendValues([]string{"beijing", "shanghai", "chengdu"}, nil)
rb.Field(2).(*array.Int16Builder).AppendValues([]int16{1992, 1993, 1994}, nil)
rec := rb.NewRecord()
defer rec.Release()
fmt.Println(rec)
}
|
Run the above example and the output is as follows:
1
2
3
4
5
6
7
8
9
10
11
|
$go run record_batch.go
record:
schema:
fields: 3
- archer: type=utf8
- location: type=utf8
- year: type=int16
rows: 3
col[0][archer]: ["tony" "amy" "jim"]
col[1][location]: ["beijing" "shanghai" "chengdu"]
col[2][year]: [1992 1993 1994]
|
In this example, we see a concept called Schema and an instance of arrow.Schema is passed in when the NewRecordBuilder is created. Similar to a database table Schema, a Schema in Arrow is a metadata concept that contains the names and types of a set of fields that act as “columns”.
Schema is not only used in Record Batch, but it is also a required element in the later Table.
arrow.Record can share the memory data of a Record Batch in a ZeroCopy way through NewSlice, which creates a new Record Batch that shares the Record in this Record Batch with the original Record:
1
2
3
4
5
6
7
|
// record_batch_slice.go
sl := rec.NewSlice(0, 2)
fmt.Println(sl)
cols := sl.Columns()
a1 := cols[0]
fmt.Println(a1)
|
The new sl takes the first two records of the rec, and outputting the sl yields the following result:
1
2
3
4
5
6
7
8
9
10
11
12
|
record:
schema:
fields: 3
- archer: type=utf8
- location: type=utf8
- year: type=int16
rows: 2
col[0][archer]: ["tony" "amy"]
col[1][location]: ["beijing" "shanghai"]
col[2][year]: [1992 1993]
["tony" "amy"]
|
Record batch of the same schema can be merged, we just need to allocate a larger Record Batch, and then copy the two to be merged Record batch to the new Record Batch can be, but obviously this is a lot of overhead.
Some implementations of Arrow provide the concept of Chunked Array, which can be used to append an array of columns with lower overhead.
Note: Chunked array is not part of the Arrow Columnar Format.
2. Chunked Array
If Record Batch is essentially a horizontal aggregation of different Array types, then Chunked Array is a vertical aggregation of the same Array type, which is expressed in Go syntax: [N]Array or []Array, i.e. array of array. The following is the structure of a Chunked Array:
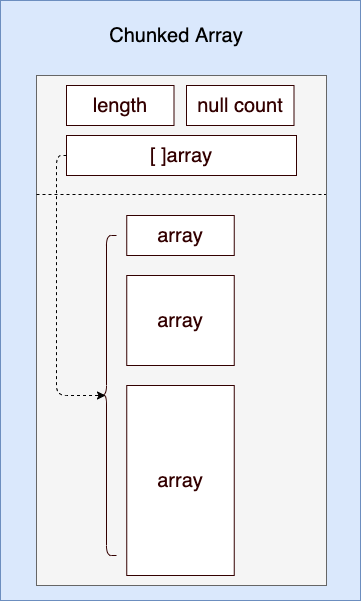
We see: Go’s implementation of Chunked array uses an Array slice:
1
2
3
4
5
6
7
8
9
10
11
12
|
// github.com/apache/arrow/go/arrow/table.go
// Chunked manages a collection of primitives arrays as one logical large array.
type Chunked struct {
refCount int64 // refCount must be first in the struct for 64 bit alignment and sync/atomic (https://github.com/golang/go/issues/37262)
chunks []Array
length int
nulls int
dtype DataType
}
|
By the very nature of Go slicing, the actual memory buffer between individual element Arrays in a Chunked Array is not contiguous. And as the diagram shows: each Array is not the same length.
We can create a Chunked Array using the NewChunked function provided by the arrow package, see the source code below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// chunked_array.go
func main() {
ib := array.NewInt64Builder(memory.DefaultAllocator)
defer ib.Release()
ib.AppendValues([]int64{1, 2, 3, 4, 5}, nil)
i1 := ib.NewInt64Array()
defer i1.Release()
ib.AppendValues([]int64{6, 7}, nil)
i2 := ib.NewInt64Array()
defer i2.Release()
ib.AppendValues([]int64{8, 9, 10}, nil)
i3 := ib.NewInt64Array()
defer i3.Release()
c := arrow.NewChunked(
arrow.PrimitiveTypes.Int64,
[]arrow.Array{i1, i2, i3},
)
defer c.Release()
for _, arr := range c.Chunks() {
fmt.Println(arr)
}
fmt.Println("chunked length =", c.Len())
fmt.Println("chunked null count=", c.NullN())
}
|
We see that the Chunked Array aggregates multiple instances of row.Array, and the length of these instances of row.Array may not be the same, arrow.Chunked Len() returns the sum of the lengths of the Arrays in the Chunked. The following is the output of the sample program:
1
2
3
4
5
6
|
$go run chunked_array.go
[1 2 3 4 5]
[6 7]
[8 9 10]
chunked length = 10
chunked null count= 0
|
In this way, Chunked Array can be viewed as a logical large Array.
Record Batch is used to aggregate equal-length array types, so is there some kind of data structure that can be used to aggregate equal-length Chunked Array? The answer is yes! Here we will look at this structure: Table.
3. Table
Table, like Chunked Array, is not part of the Arrow Columnar Format, but was originally just a data structure in the C++ implementation of Arrow, and the Go Arrow implementation provides support for Table.
The structure of a Table is schematized below (diagram taken from the book In-Memory Analytics with Apache Arrow):
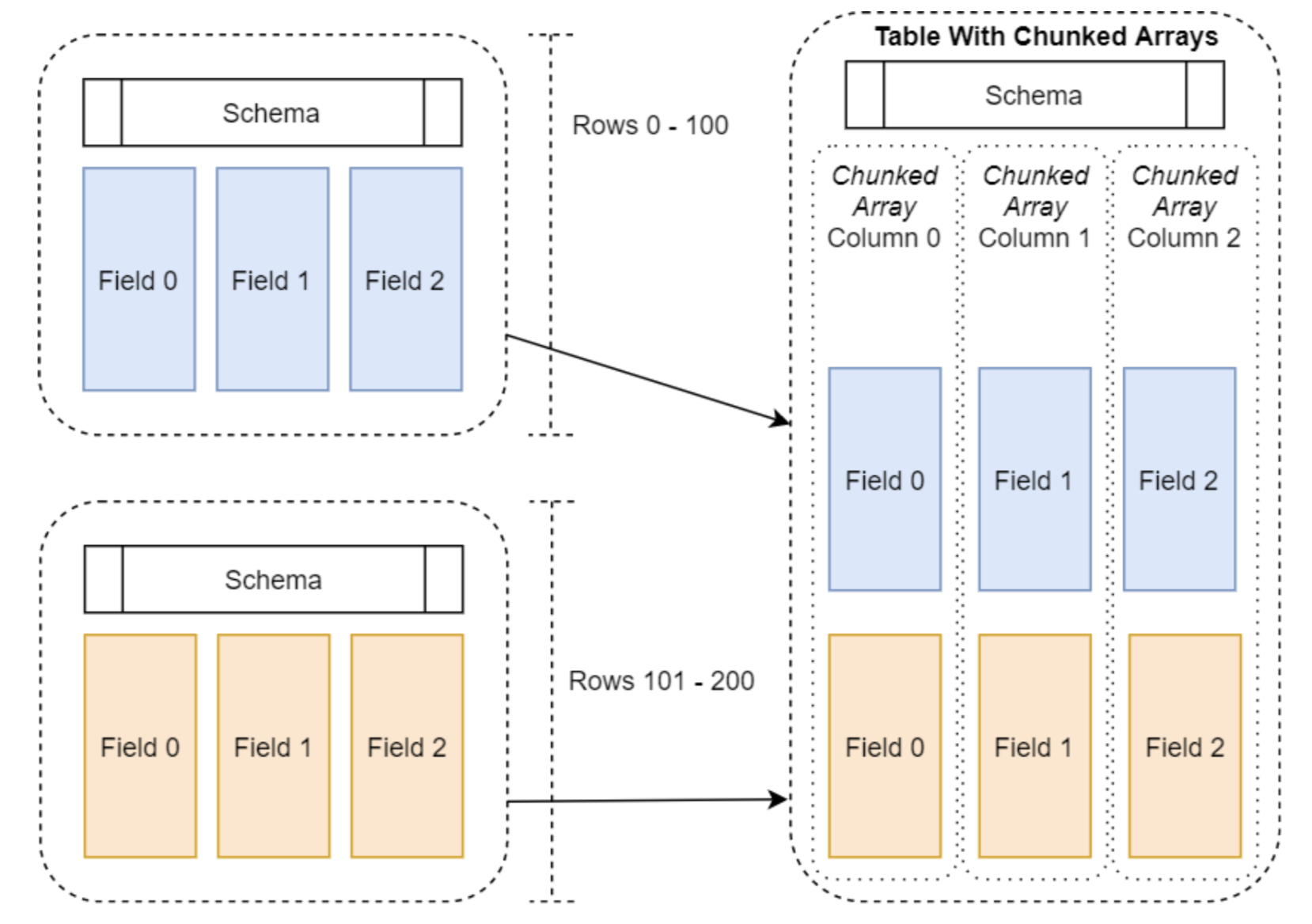
We see that: unlike Record Batch where each column is an array, Table has a chunked array for each column, the length of the chunked array is the same for all columns, but the length of the arrays in the chunked array for each column can be different.
Table and Record Batch are similar in that they have their own Schema.
The following diagram (from here) makes a very intuitive comparison between Table and Chunked Array:
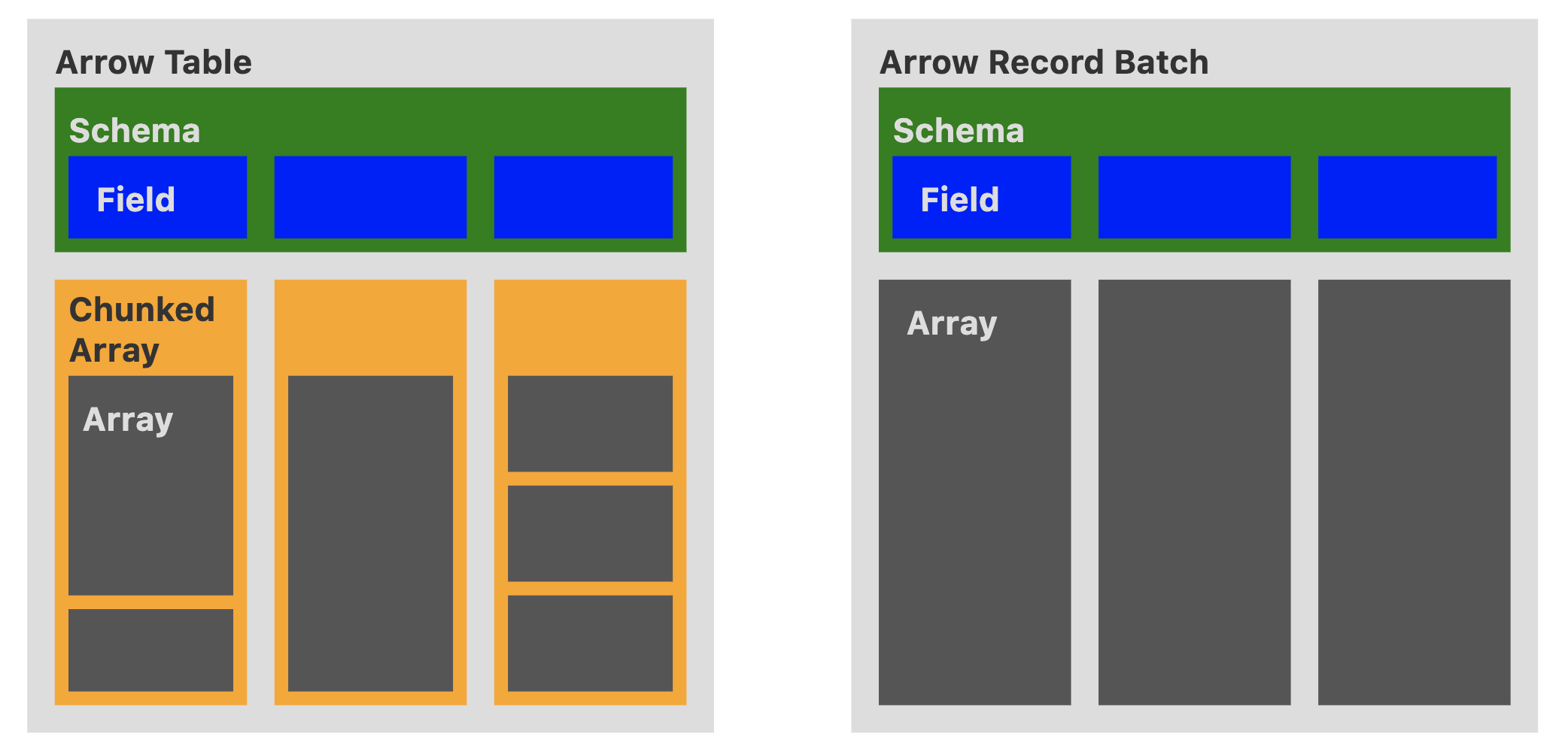
Record Batch is a part of Arrow Columnar format, and all language implementations support Record Batch; however, Table is not a part of format spec, and not all language implementations provide support for it.
In addition, as you can see from the figure, because Table uses Chunked Array as columns, the internal distribution of each array under the chunked array is not continuous, which makes Table lose some localization at runtime.
Below we will use the Go arrow implementation to create a table, which is a table with 3 columns and 10 rows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
|
// table.go
func main() {
schema := arrow.NewSchema(
[]arrow.Field{
{Name: "col1", Type: arrow.PrimitiveTypes.Int32},
{Name: "col2", Type: arrow.PrimitiveTypes.Float64},
{Name: "col3", Type: arrow.BinaryTypes.String},
},
nil,
)
col1 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
ib := array.NewInt32Builder(memory.DefaultAllocator)
defer ib.Release()
ib.AppendValues([]int32{1, 2, 3}, nil)
i1 := ib.NewInt32Array()
defer i1.Release()
ib.AppendValues([]int32{4, 5, 6, 7, 8, 9, 10}, nil)
i2 := ib.NewInt32Array()
defer i2.Release()
c := arrow.NewChunked(
arrow.PrimitiveTypes.Int32,
[]arrow.Array{i1, i2},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(0), chunk)
}()
defer col1.Release()
col2 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
fb := array.NewFloat64Builder(memory.DefaultAllocator)
defer fb.Release()
fb.AppendValues([]float64{1.1, 2.2, 3.3, 4.4, 5.5}, nil)
f1 := fb.NewFloat64Array()
defer f1.Release()
fb.AppendValues([]float64{6.6, 7.7}, nil)
f2 := fb.NewFloat64Array()
defer f2.Release()
fb.AppendValues([]float64{8.8, 9.9, 10.0}, nil)
f3 := fb.NewFloat64Array()
defer f3.Release()
c := arrow.NewChunked(
arrow.PrimitiveTypes.Float64,
[]arrow.Array{f1, f2, f3},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(1), chunk)
}()
defer col2.Release()
col3 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
sb := array.NewStringBuilder(memory.DefaultAllocator)
defer sb.Release()
sb.AppendValues([]string{"s1", "s2"}, nil)
s1 := sb.NewStringArray()
defer s1.Release()
sb.AppendValues([]string{"s3", "s4"}, nil)
s2 := sb.NewStringArray()
defer s2.Release()
sb.AppendValues([]string{"s5", "s6", "s7", "s8", "s9", "s10"}, nil)
s3 := sb.NewStringArray()
defer s3.Release()
c := arrow.NewChunked(
arrow.BinaryTypes.String,
[]arrow.Array{s1, s2, s3},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(2), chunk)
}()
defer col3.Release()
var tbl arrow.Table
tbl = array.NewTable(schema, []arrow.Column{*col1, *col2, *col3}, -1)
defer tbl.Release()
dumpTable(tbl)
}
func dumpTable(tbl arrow.Table) {
s := tbl.Schema()
fmt.Println(s)
fmt.Println("------")
fmt.Println("the count of table columns=", tbl.NumCols())
fmt.Println("the count of table rows=", tbl.NumRows())
fmt.Println("------")
for i := 0; i < int(tbl.NumCols()); i++ {
col := tbl.Column(i)
fmt.Printf("arrays in column(%s):\n", col.Name())
chunk := col.Data()
for _, arr := range chunk.Chunks() {
fmt.Println(arr)
}
fmt.Println("------")
}
}
|
As we can see: before the table is created, we need to prepare a schema, as well as individual columns, each of which is a chunked array.
Running the above code, we get the following result:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
$go run table.go
schema:
fields: 3
- col1: type=int32
- col2: type=float64
- col3: type=utf8
------
the count of table columns= 3
the count of table rows= 10
------
arrays in column(col1):
[1 2 3]
[4 5 6 7 8 9 10]
------
arrays in column(col2):
[1.1 2.2 3.3 4.4 5.5]
[6.6 7.7]
[8.8 9.9 10]
------
arrays in column(col3):
["s1" "s2"]
["s3" "s4"]
["s5" "s6" "s7" "s8" "s9" "s10"]
------
|
table also supports schema changes, we can add a column to table based on the above code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
|
// table_schema_change.go
func main() {
schema := arrow.NewSchema(
[]arrow.Field{
{Name: "col1", Type: arrow.PrimitiveTypes.Int32},
{Name: "col2", Type: arrow.PrimitiveTypes.Float64},
{Name: "col3", Type: arrow.BinaryTypes.String},
},
nil,
)
col1 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
ib := array.NewInt32Builder(memory.DefaultAllocator)
defer ib.Release()
ib.AppendValues([]int32{1, 2, 3}, nil)
i1 := ib.NewInt32Array()
defer i1.Release()
ib.AppendValues([]int32{4, 5, 6, 7, 8, 9, 10}, nil)
i2 := ib.NewInt32Array()
defer i2.Release()
c := arrow.NewChunked(
arrow.PrimitiveTypes.Int32,
[]arrow.Array{i1, i2},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(0), chunk)
}()
defer col1.Release()
col2 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
fb := array.NewFloat64Builder(memory.DefaultAllocator)
defer fb.Release()
fb.AppendValues([]float64{1.1, 2.2, 3.3, 4.4, 5.5}, nil)
f1 := fb.NewFloat64Array()
defer f1.Release()
fb.AppendValues([]float64{6.6, 7.7}, nil)
f2 := fb.NewFloat64Array()
defer f2.Release()
fb.AppendValues([]float64{8.8, 9.9, 10.0}, nil)
f3 := fb.NewFloat64Array()
defer f3.Release()
c := arrow.NewChunked(
arrow.PrimitiveTypes.Float64,
[]arrow.Array{f1, f2, f3},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(1), chunk)
}()
defer col2.Release()
col3 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
sb := array.NewStringBuilder(memory.DefaultAllocator)
defer sb.Release()
sb.AppendValues([]string{"s1", "s2"}, nil)
s1 := sb.NewStringArray()
defer s1.Release()
sb.AppendValues([]string{"s3", "s4"}, nil)
s2 := sb.NewStringArray()
defer s2.Release()
sb.AppendValues([]string{"s5", "s6", "s7", "s8", "s9", "s10"}, nil)
s3 := sb.NewStringArray()
defer s3.Release()
c := arrow.NewChunked(
arrow.BinaryTypes.String,
[]arrow.Array{s1, s2, s3},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(2), chunk)
}()
defer col3.Release()
var tbl arrow.Table
tbl = array.NewTable(schema, []arrow.Column{*col1, *col2, *col3}, -1)
defer tbl.Release()
dumpTable(tbl)
col4 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
sb := array.NewStringBuilder(memory.DefaultAllocator)
defer sb.Release()
sb.AppendValues([]string{"ss1", "ss2"}, nil)
s1 := sb.NewStringArray()
defer s1.Release()
sb.AppendValues([]string{"ss3", "ss4", "ss5"}, nil)
s2 := sb.NewStringArray()
defer s2.Release()
sb.AppendValues([]string{"ss6", "ss7", "ss8", "ss9", "ss10"}, nil)
s3 := sb.NewStringArray()
defer s3.Release()
c := arrow.NewChunked(
arrow.BinaryTypes.String,
[]arrow.Array{s1, s2, s3},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(arrow.Field{Name: "col4", Type: arrow.BinaryTypes.String}, chunk)
}()
defer col4.Release()
tbl, err := tbl.AddColumn(
3,
arrow.Field{Name: "col4", Type: arrow.BinaryTypes.String},
*col4,
)
if err != nil {
panic(err)
}
dumpTable(tbl)
}
|
Run the above example and the output is as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
$go run table_schema_change.go
schema:
fields: 3
- col1: type=int32
- col2: type=float64
- col3: type=utf8
------
the count of table columns= 3
the count of table rows= 10
------
arrays in column(col1):
[1 2 3]
[4 5 6 7 8 9 10]
------
arrays in column(col2):
[1.1 2.2 3.3 4.4 5.5]
[6.6 7.7]
[8.8 9.9 10]
------
arrays in column(col3):
["s1" "s2"]
["s3" "s4"]
["s5" "s6" "s7" "s8" "s9" "s10"]
------
schema:
fields: 4
- col1: type=int32
- col2: type=float64
- col3: type=utf8
- col4: type=utf8
------
the count of table columns= 4
the count of table rows= 10
------
arrays in column(col1):
[1 2 3]
[4 5 6 7 8 9 10]
------
arrays in column(col2):
[1.1 2.2 3.3 4.4 5.5]
[6.6 7.7]
[8.8 9.9 10]
------
arrays in column(col3):
["s1" "s2"]
["s3" "s4"]
["s5" "s6" "s7" "s8" "s9" "s10"]
------
arrays in column(col4):
["ss1" "ss2"]
["ss3" "ss4" "ss5"]
["ss6" "ss7" "ss8" "ss9" "ss10"]
------
|
This support for schema change operations is also very useful in real-world development.
4. Summary
This article explains three advanced data structures based on the array type: Record Batch, Chunked Array, and Table, where Record Batch is a structure in the Arrow Columnar Format, which is supported by all programming languages that implement arrows, and Chunked Array and Table are created in some programming language implementations.
The three concepts are easily confused and can be summarized briefly as follows:
- Record Batch: schema + multiple arrays of the same length
- Chunked Array: []array
- Table: schema + multiple Chunked Arrays of the same total length
5. Ref
https://tonybai.com/2023/07/08/a-guide-of-using-apache-arrow-for-gopher-part3/