From the kube-scheduler’s perspective, it calculates the best node to run a Pod through a series of algorithms, and when a new Pod appears for scheduling, the scheduler makes the best scheduling decision based on its resource description of the Kubernetes cluster at that time. But Kubernetes clusters are very dynamic. As a result of cluster-wide changes, such as a node that we first perform an eviction operation for maintenance purposes, all Pods on that node will be evicted to other nodes, but when we finish maintenance, the previous Pods do not automatically come back to that node. Because Pods do not trigger rescheduling once they are bound to a node, due to these changes, the Kubernetes cluster may become unbalanced over time, so a load balancer is needed to rebalance the cluster.

Of course, we can do some cluster balancing manually, such as manually deleting some Pods and triggering rescheduling, but obviously this is a tedious process and not the way to solve the problem. In order to solve the problem that cluster resources are not fully utilized or wasted in practice, we can use the descheduler component to optimize the scheduling of cluster Pods; descheduler can help us rebalance the cluster state according to some rules and configuration policies, and its core principle is to find Pods that can be removed and evict them according to its policy configuration, which itself It does not schedule the evicted Pods, but relies on the default scheduler to do so. Currently, the following policies are supported.
- RemoveDuplicates
- LowNodeUtilization
- HighNodeUtilization
- RemovePodsViolatingInterPodAntiAffinity
- RemovePodsViolatingNodeAffinity
- RemovePodsViolatingNodeTaints
- RemovePodsViolatingTopologySpreadConstraint
- RemovePodsHavingTooManyRestarts
- PodLifeTime
- RemoveFailedPods
These policies can be enabled or disabled as part of the policy, and some parameters associated with the policy can also be configured, and by default, all policies are enabled. In addition, there are some general configurations, as follows:
nodeSelector: restrict the nodes to be processedevictLocalStoragePods: evict Pods that use LocalStorageignorePvcPods: whether to ignore Pods configured with PVCs, default is FalsemaxNoOfPodsToEvictPerNode: the maximum number of Pods allowed to be evicted by a node
We can configure it with the DeschedulerPolicy as shown below.
|
|
Installation
descheduler can be run as CronJob or Deployment within a k8s cluster, also we can use Helm Chart to install descheduler.
|
|
By Helm Chart we can configure descheduler to run as CronJob or Deployment, by default descheduler will run as a critical pod to avoid being evicted by itself or kubelet, you need to make sure the cluster has system-cluster-critical as Priorityclass.
By default, a Helm Chart installation will run as a CronJob with an execution period of schedule: "*/2 * * * *" so that descheduler tasks are executed every two minutes, and the default configuration policy is shown below.
|
|
By configuring the strategies of DeschedulerPolicy, you can specify the execution policy of descheduler, these policies can be enabled or disabled, we will introduce them in detail below, here we can use the default policy, just use the following command to install it directly.
|
|
When deployment is complete, a CronJob resource object is created to balance the cluster state.
|
|
Normally a corresponding Job will be created to execute the descheduler task, and we can see what balancing operations were done by looking at the logs.
|
|
From the logs, we can clearly see which Pods were evicted due to what policies.
PDB
Since using descheduler will evict Pods for rescheduling, but if all copies of a service are evicted, it may cause the service to be unavailable. If the service itself has a single point of failure, the eviction will definitely cause the service to be unavailable, in this case we strongly recommend using anti-affinity and multiple copies to avoid a single point of failure, but if the service itself is broken up on multiple nodes, and all these Pods are evicted, this will also cause the service to be unavailable. In this case we can avoid all replicas being deleted at the same time by configuring the PDB (PodDisruptionBudget) object. For example, we can set at most one copy of an application to be unavailable at the time of eviction by creating a manifest as shown below.
More details about PDB can be found in the official documentation: https://kubernetes.io/docs/tasks/run-application/configure-pdb/.
So if we use descheduler to rebalance the cluster state, then we strongly recommend to create a corresponding PodDisruptionBudget object for the application to protect.
Policy
PodLifeTime: Evict pods that exceed the specified time limit
This policy is used to evict Pods older than maxPodLifeTimeSeconds. You can configure which kind of status Pods will be evicted by podStatusPhases and it is recommended to create a PDB for each application to ensure the availability of the application. For example, we can configure the policy shown below to evict Pods that have been running for more than 7 days.
RemoveDuplicates
This policy ensures that only one RS, Deployment, or Job resource object associated with a Pod is running on the same node; if there are more Pods, these duplicate Pods are evicted to better spread the Pods across the cluster. This can happen if some nodes crash for some reason and the Pods on those nodes drift to other nodes, resulting in multiple Pods associated with RS running on the same node, and this policy can be enabled to evict these duplicate Pods once the failed node is ready again.
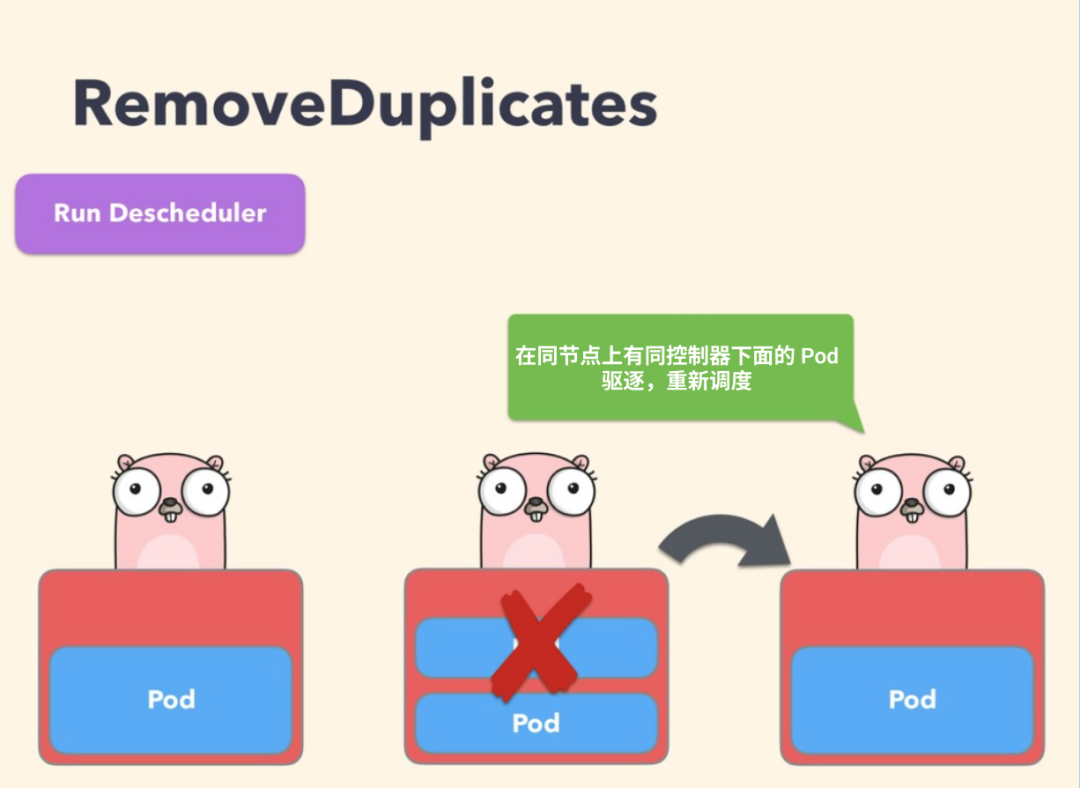
When configuring a policy, you can specify the parameter excludeOwnerKinds for exclusion types, under which Pods will not be evicted.
LowNodeUtilization
This policy is mainly used to find underutilized nodes and evict Pods from other nodes so that kube-scheduler can reschedule them to underutilized nodes. The parameters of this policy can be configured via the field nodeResourceUtilizationThresholds.
Underutilization of nodes can be determined by configuring the thresholds threshold parameter, which can be configured as a percentage of CPU, memory, and number of Pods. A node is considered underutilized if its utilization is below all thresholds.
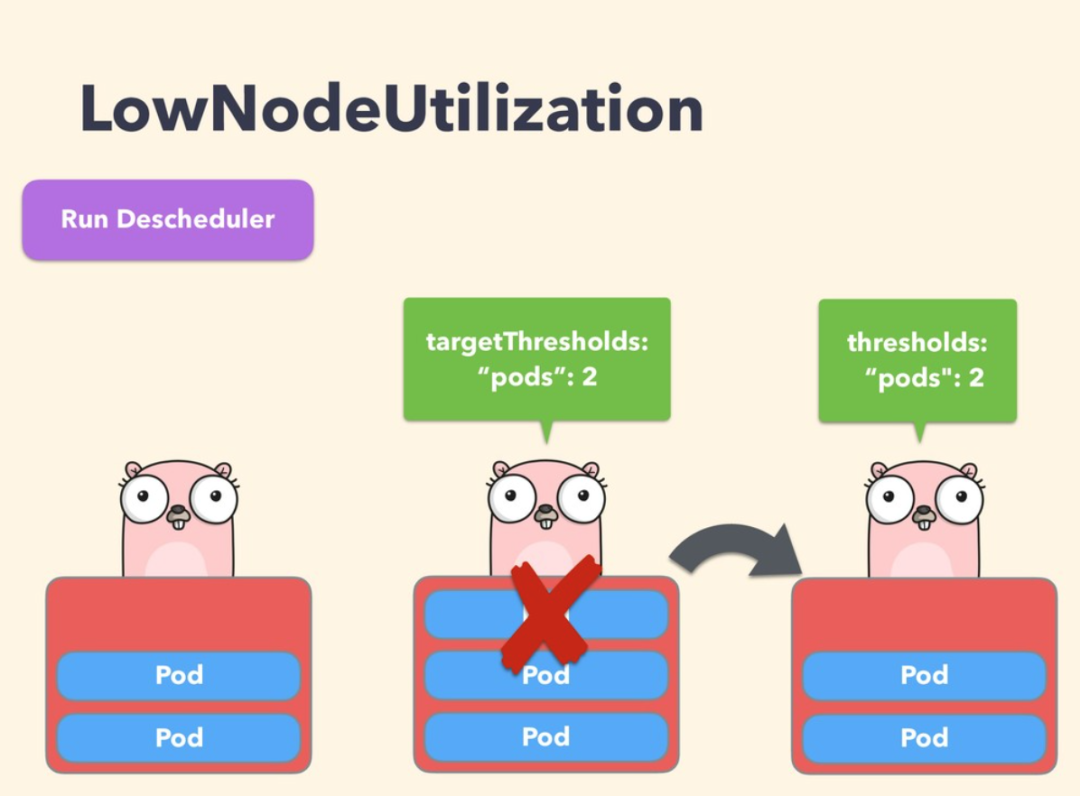
In addition, there is a configurable threshold targetThresholds that counts potential nodes that may evict Pods, and this parameter can also be configured for CPU, memory, and a percentage of the number of Pods. thresholds and targetThresholds can be dynamically adjusted according to your cluster requirements, as shown in the example below.
It is important to note that:
- Only the following three resource types are supported: cpu, memory, pods
thresholdsandtargetThresholdsmust be configured with the same type- Access to parameter values is from 0-100 (percent)
- The same resource type,
thresholdscannot be configured higher thantargetThresholds
If no resource type is specified, the default is 100% to prevent nodes from going from underutilized to overutilized. Another parameter associated with the LowNodeUtilization policy is numberOfNodes, which can be configured to activate the policy only if the number of underutilized nodes is greater than this configured value, which is useful for large clusters where some nodes may be frequently used or underutilized for a short period of time, by default numberOfNodes is 0.
RemovePodsViolatingInterPodAntiAffinity
This policy ensures that Pods that violate Pod anti-affinity are removed from the node. For example, if a node has podA as a Pod and podB and podC (running on the same node) have anti-affinity rules that prohibit them from running on the same node, podA will be expelled from that node so that podB and podC can run normally. This problem occurs when the anti-affinity rule is created after podB and podC are already running on the node.
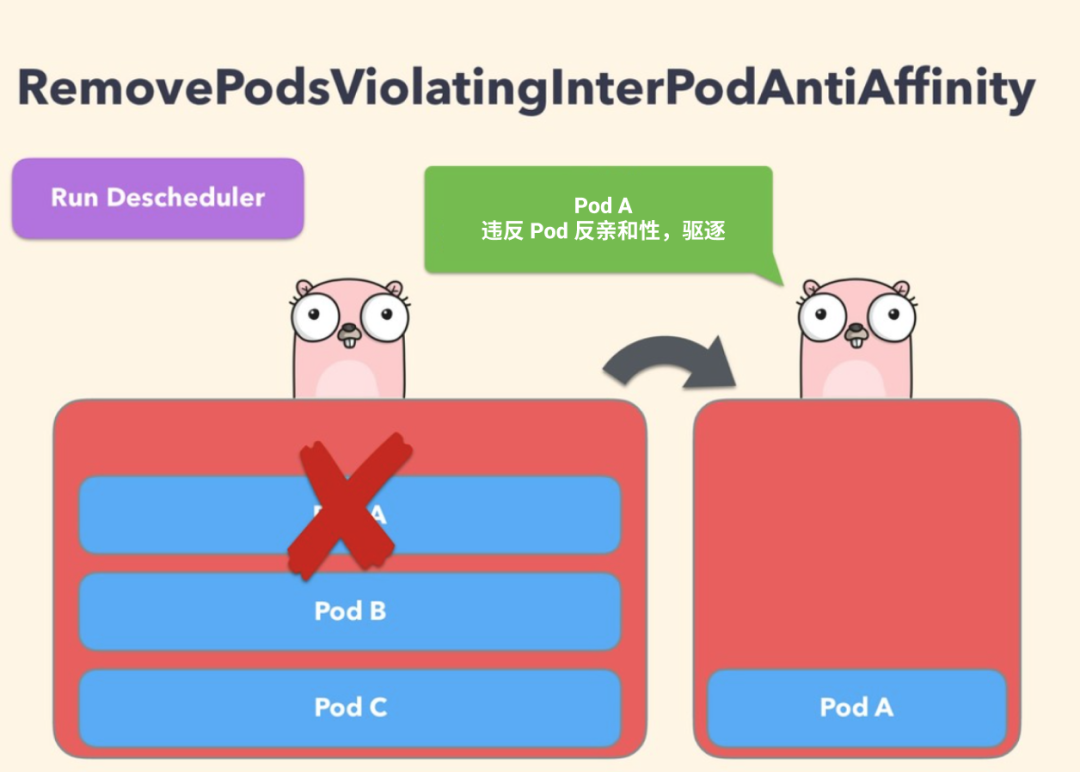
To disable this policy, simply configure it to false.
RemovePodsViolatingNodeTaints
This policy ensures that Pods that violate the NoSchedule taint are removed from the node. For example, if there is a Pod named podA that is allowed to be dispatched to a node with that taint configuration by configuring the tolerance key=value:NoSchedule, and if the taint of the node is subsequently updated or removed, the taint will no longer be satisfied by the Pods’ tolerance. It will then be evicted.
RemovePodsViolatingNodeAffinity
This policy ensures that Pods violating node affinity are removed from the node. e.g. Pod named podA is scheduled to node nodeA, podA satisfies the node affinity rule requiredDuringSchedulingIgnoredDuringExecution at the time of scheduling, but over time, node nodeA no longer satisfies the rule, then podA is evicted from node nodeA if another node, nodeB, satisfying the node affinity rule is available, as shown in the following example policy configuration.
RemovePodsViolatingTopologySpreadConstraint
This policy ensures that Pods that violate topology distribution constraints are removed from the node, specifically, it attempts to remove the minimum number of Pods needed to balance the topology domain into maxSkew for each constraint, although this policy requires a k8s version higher than 1.18 to be used.
By default, this policy only handles hard constraints, and will also support soft constraints if the parameter includeSoftConstraints is set to True.
RemovePodsHavingTooManyRestarts
This policy ensures that Pods with too many restarts are removed from the node. Its parameters include podRestartThreshold, which is the number of restarts that should be expelled from the Pod, and include InitContainers, which determines whether restarts of the initialized container should be considered in the calculation. The policy configuration is shown below.
Filter Pods
When evicting Pods, sometimes it is not necessary for all Pods to be evicted, descheduler provides two main ways to filter: namespace filtering and priority filtering.
Namespace filtering
This policy allows you to configure whether to include or exclude certain namespaces. The following can be used with this policy.
- PodLifeTime
- RemovePodsHavingTooManyRestarts
- RemovePodsViolatingNodeTaints
- RemovePodsViolatingNodeAffinity
- RemovePodsViolatingInterPodAntiAffinity
- RemoveDuplicates
- RemovePodsViolatingTopologySpreadConstraint
For example, if you only evict Pods under certain command spaces, you can use the include parameter to configure them, as shown below.
Or to exclude Pods under certain command spaces, you can use the exclude parameter as shown below.
Priority Filtering
All policies can be configured with a priority threshold below which only Pods will be evicted, which we can specify by setting the thresholdPriorityClassName (which sets the threshold to the value of the specified priority class) or the thresholdPriority (which sets the threshold directly) parameter. By default, the threshold is set to the value of the PriorityClass class system-cluster-critical.
For example, use thresholdPriority.
Or use thresholdPriorityClassName for filtering.
However, note that you cannot configure both thresholdPriority and thresholdPriorityClassName. If the specified priority class does not exist, the descheduler will not create it and will raise an error.
Caution
When using descheduler to evict Pods, the following points need to be noted:
- Critical Pods will not be evicted, such as Pods with
priorityClassNameset tosystem-cluster-criticalorsystem-node-critical - Pods that are not managed by RS, Deployment or Job will not be evicted
- Pods created by DaemonSet will not be evicted
- Pods with
LocalStoragewill not be evicted unlessevictLocalStoragePods: trueis set - Pods with PVCs will not be evicted unless
ignorePvcPods: trueis set - Under the
LowNodeUtilizationandRemovePodsViolatingInterPodAntiAffinitypolicies, Pods are evicted in descending order of priority. Pods of typeBesteffortare evicted before typesBurstableandGuaranteedif they have the same priority - Pods with
descheduler.alpha.kubernetes.io/evictfield inannotationscan be evicted, this annotation is used to override the check to prevent eviction and the user can choose which Pods to evict - If Pods fail to evict, you can set
-v=4to find out why in thedeschedulerlog, and not evict such Pods if the eviction violates the PDB constraint