Keep clear commit records
Uniformly standardize commit messages
Git forces commit to have a summary message, but there are no restrictions on the content. Take a look at the following commit history.
-
Randomly written
-
More explicit (django-oscar)
-
Normative (Vim)
1 2 3 4 5 6 7 8 9 10patch 9.0.0316: screen flickers when 'cmdheight' is zero Problem: Screen flickers when 'cmdheight' is zero. Solution: Redraw over existing text instead of clearing. patch 9.0.0315: shell command is displayed in message window Problem: Shell command is displayed in message window. Solution: Do not echo the shell command in the message window. -
Normative (React)
I think most developers should agree that the commit message should at least describe what was done in this commit, so in contrast, in fact, the first kind of writing is equal to not writing, at least to do the second kind of form, in order to be considered a useful commit record.
In many commit message specification, the specification proposed by the front-end framework Angular team should be the most popular, the specification will mention the commit summary into three parts: header, body, footer, where the header is required.
The header contains three parts.
type: commit type,test,feat,fix, etc.scope: scopesubject: subject, a short description of the modification, starts with a lowercase letter, present tense, no period at the end
body is a complement to subject, including the motivation for this change, compared to the previous behavior.
footer is mainly a description of Breaking Changes or closing a related issue
This format looks a bit complicated, but it can be done with the help of tools, such as the helper script I wrote commit-formatter.
Clean up useless commit messages
amend
Sometimes when you finish a git commit operation and suddenly find a spelling mistake, you can fix it and commit again, but there is no need to create an extra commit record for such a small change (this can be avoided with lint or git-hook, but that’s a different issue). In this case, you can add the changed file to the staging area and then rewrite the commit with git commit --amend to add the minor changes to the last commit. This will open up the default editor for you to edit the commit information, or you can use git commit --amend --no-edit if you don’t need to change the commit record.
squash
Sometimes we need to compress multiple commits into one, such as when developing a feature that generates multiple unnecessary commits for a small change, or when participating in an open source project where we need to commit a PR based on our own branch and the Reviewer has suggested some changes to us. This is the time to use squash.
For example, there is the following commit.
Use the command git rebase -i HEAD~3, which opens the default editor in the terminal.
|
|
Each commit message is preceded by the word pick, and in the comments below, the meaning of the other words before pick is explained, you can see that the meaning of s or squash is to keep the message but merge it into the previous commit, now edit the last two picks and change them as follows.
After saving and confirming, you can use git log again to view the commit history and see that the three commits have been merged.
Using rebase synchronization
Sometimes, the reason for the confusing commit history of some projects can be that developers use inappropriate actions, such as only knowing to use pull and push for remote branches.
Many of you will have seen this warning when using git pull.
|
|
Now suppose A and B are working on the same dev branch, and A modifies the code and creates commit1, which is pushed to the server via git push, when B also creates commit2 locally, he will get an error using git push, because B has not synchronized the latest changes in the remote dev branch.

Image from Gitbucket
If he pulls the remote branch at this point, he will create an additional merge commit. Actually, the pull operation here is equivalent to git fetch <remote> && git merge <remote>/branch, which downloads the changes to the remote branch locally and then merges them into the local branch.

How do you avoid this merge commit? You can use git pull --rebase.
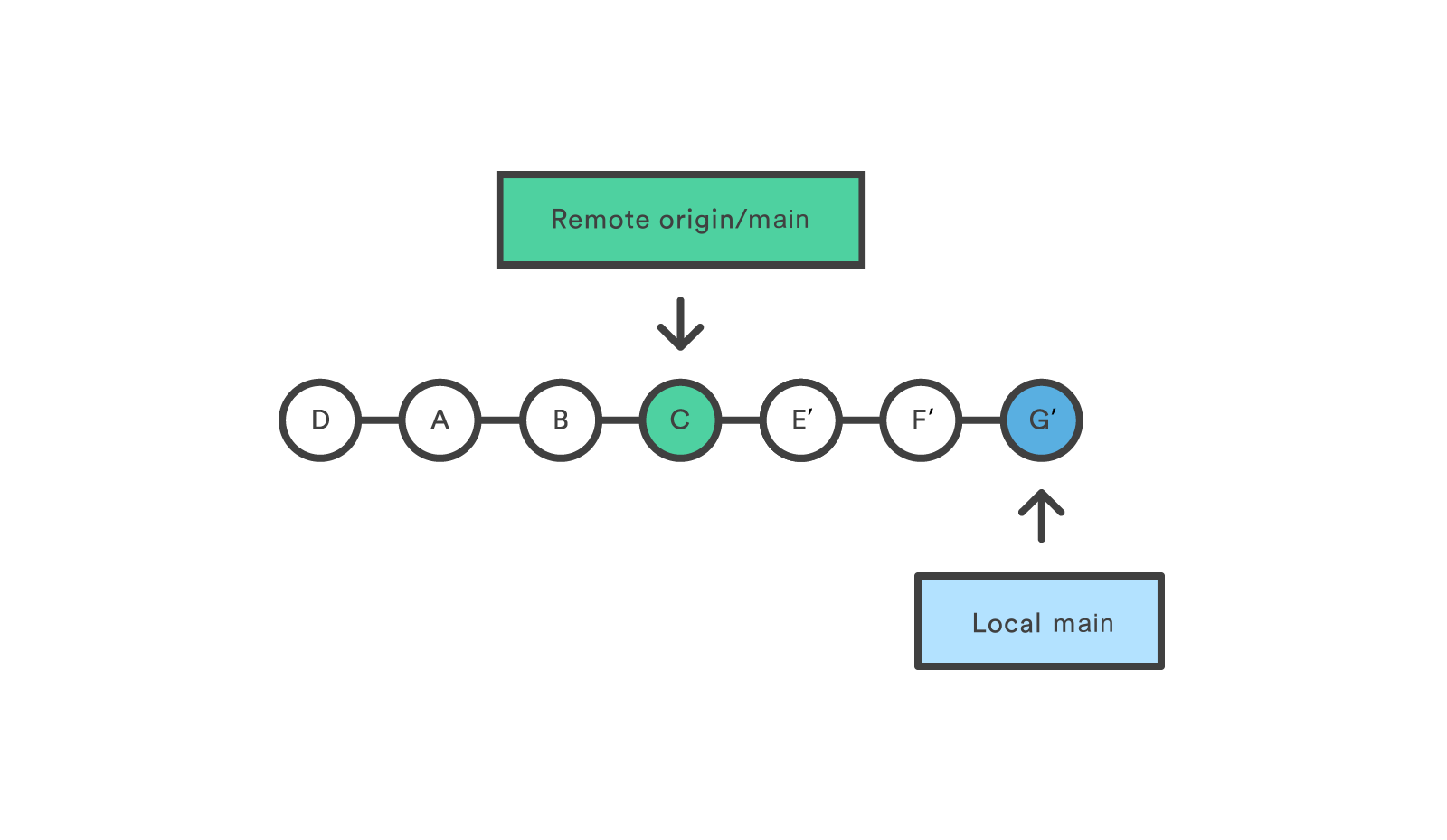
The rebase looks like it takes the local commit first and inserts it at the top of another branch, so that you get a linear commit history. Notice in the diagram that what was originally local E F G becomes E’ F’ G’, which will be mentioned later.
Looking back at the previous warning, the default pull operation can be set to git pull --rebase by using git config pull.rebase true.
Similarly, for different branches on the same machine, you can actually use the git rebase other-branch operation instead of merge.
The Golden Rule of Rebase
There is a golden rule for rebase operations: **Don’t use rebase on shared branches!
Perhaps because of this rule, some programmers are afraid to use rebase.
As mentioned earlier, a local commit, after rebase, actually generates a new commit with the same content, and the hash of E’ F’ G’ is not the same as the original E F G. Suppose now the branching situation is as follows.
If A rebases a feature in the local dev branch.
Then A wants to push the local dev to the remote end. Here comes the trouble, A’s local dev and the remote end won’t match after B. If A ignores it and uses git push --force, then B will encounter an error if he wants to push his local changes, and B uses git pull, Git will try to merge the branches.
If everyone operated like A, this shared dev branch would end up being very confusing.
But if it’s like mentioned earlier, A’s local dev is A -> B -> C -> D, the remote end was originally A -> B -> C, and after B’s push it becomes A -> B -> C -> E, A uses git pull --rebase which is fine, then the local becomes A -> B -C -> E -> D', why is this operation safe? Here the remote dev branch is shared, but the local dev can be treated as a private branch. git pull --rebase is equivalent to rebasing the remote dev branch, and the final push results in a new commit being pushed to the remote end, which then results in A -> B -> C -> E -> D after B uses git pull.
For example, if you fork a repository on Github, checkout a dev branch and make some changes to create a PR, although this dev branch is on a public code hosting platform where everyone can see it, it is only created to eventually merge into the mainline of the target repository and can still be considered a private branch. Before this PR is merged, changes to the target master branch can be synchronized via rebase, and commits can be compressed with squash, all of which are safe operations.
In summary, the safe use of amend, squash, rebase, etc. is based on the premise that don’t change commits that have been shared and that if A -> B -C on a shared remote branch becomes A -> B -> D -> F, it will cause confusion.
Auxiliary Tools
Git hooks
Git provides a hook mechanism to trigger specific actions before and after specific events. For example, checking test coverage before a code commit, checking code formatting, etc. The Python open source tool pre-commit provides a number of nice hooks.
Git Subcommands
If you write an extended script for Git, then you can name your executable with git-foo, and Git allows you to call custom scripts using the subcommand form of git boo.
Git Aliases
You can configure a short alias for some common and long commands, for example
|
|
EditorConfig
Different editors/IDEs will have their own project configuration files, such as .idea for JetBrains series, .vscode for VSCode, I personally think such files should not be committed to the public repository, because it should not be mandatory for all developers to use the same tools (projects like Android development that are highly tied to IDEs might be is the exception).
So how do you ensure that different developers use different editors while maintaining a uniform code style at this point? One way is to use the aforementioned git hooks to do formatting before committing; another way is to use EditorConfig to place a .editorconfig file in the project to configure indentation, line breaks, etc. Basically, mainstream editors will respect This configuration.
Other
Log Queries
The Git command line provides a number of options to quickly find commits.
- Find by commit information:
git log --all --grep='<pattern>' - Find by committer:
git log --committer=<pattern> - By date:
git log --since=<date>, git log --before=<date>
For more query options, you can check the official documentation.
Tracking Empty Folders
Git itself can’t track empty directories, but sometimes you do need to put an empty directory into the repository, so you can put an empty .gitkeep file under that directory. This filename is just a naming convention and has no special meaning, so you’ll have to go and modify the .gitignore file next.
This allows Git to ignore all files in that directory except for .gitkeep, but keep the directory.
Large files
LFS
Git is designed for text files, but sometimes you need to put large binary files in your repository, such as images, audio, and other design resources. This can make the repository huge, and if the binary changes, the change history can become large. To solve this problem, you can use the LFS (Large File Storage) extension, which simply allows large files to be saved in another repository, keeping a pointer to it locally. See LFS for details.
gc
The git gc command can help clean up the Git database of unneeded files and reduce disk footprint, which is useful when working on large repositories with huge commits like nixpkgs.
Only the most recent commit is needed
Sometimes we only need the latest code from one repository for the time being and don’t need all the Git commit history, so you can use git clone --depth 1 repo-url to clone the repository, which saves download time and local disk footprint.
Ref
https://elliot00.com/posts/use-git-gracefully