Preface
Some time ago when we upgraded the Pulsar version, we found that the last node never had any traffic after the upgrade.
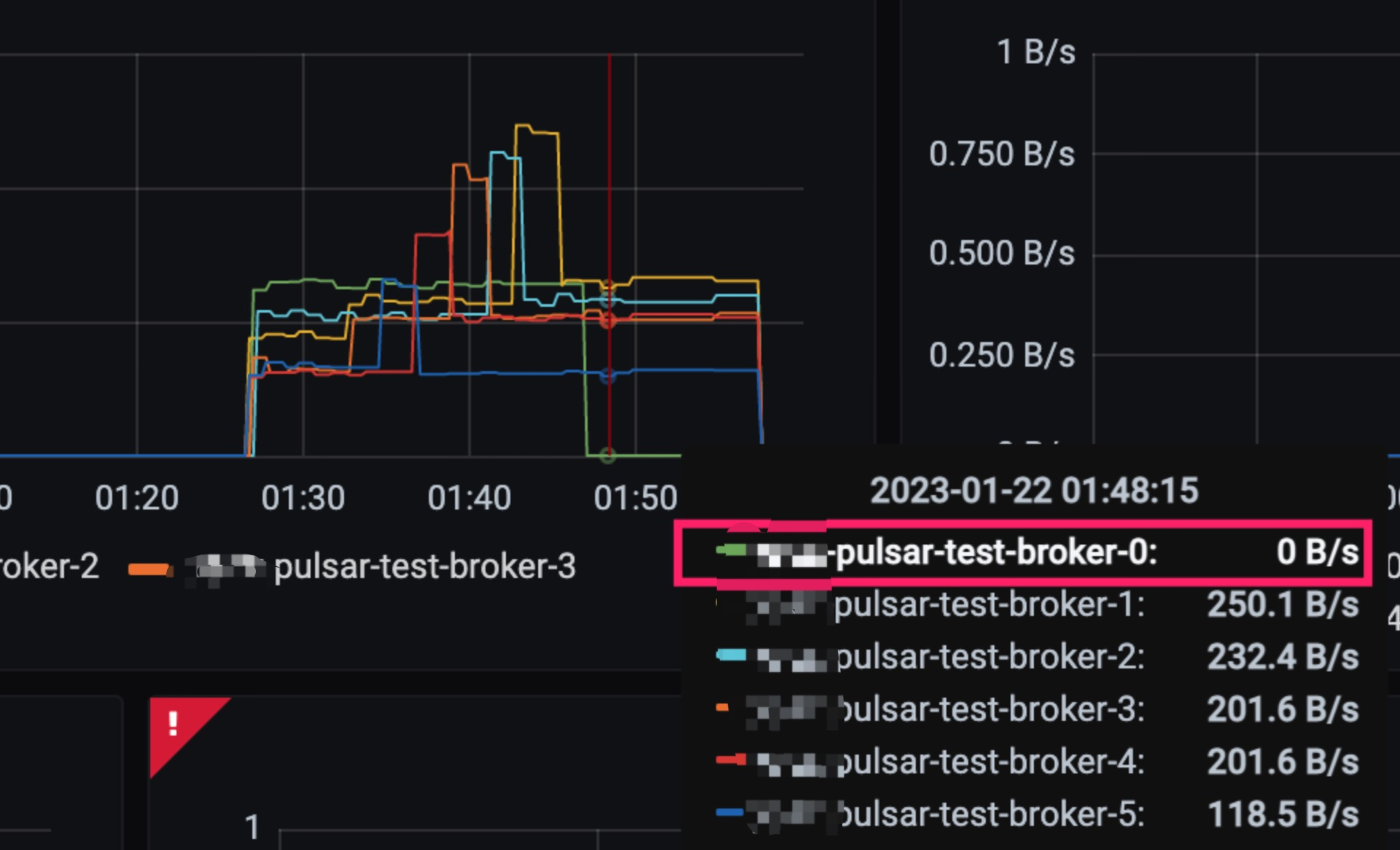
Although there is no impact on business usage, uneven load can lead to wasted resources.
After talking to my colleague, I learned that this happened with the previous upgrade, and eventually the load balancing was done manually by calling Pulsar’s admin API.
I didn’t find any similar problem in Google or Pulsar community, so I don’t know if we didn’t encounter it or rarely upgrade the cluster.
Pulsar Load Balancing Principle
Load balancing is very important when a cluster can scale horizontally. The fundamental purpose is to allow each node that provides the service to handle requests evenly, otherwise scaling would be meaningless.
Before analyzing the reason for this problem let’s take a look at the Pulsar load balancing implementation.
We can control the switching of the load balancer through this configuration of this broker, which is enabled by default.
The specific implementation class to be used as the load balancer can also be specified in the configuration file.
The default is ModularLoadManagerImpl.
|
|
When broker starts, it reads the configuration from the configuration file and loads it. If the load fails, it uses SimpleLoadManagerImpl as the fallback policy.
When the broker is a cluster, only the broker at the leader node will perform the load balancer logic.
Leader election is implemented through Zookeeper.
By default, the broker that becomes the Leader node reads the data of each broker every minute to determine if any node is overloaded and needs to be rebalanced.
The basis for determining whether or not to rebalance is provided by the org.apache.pulsar.broker.loadbalance.LoadSheddingStrategy interface, which actually has only one function.
Calculate a broker and bundle that needs to be unloaded based on the load information of all the brokers.
Here is an explanation of the concept of unload and bundle.
bundleis an abstraction of a batch oftopic, and the client will know which broker to connect to only after associatingbundlewithbroker; instead of directly binding topic tobroker, so as to manage a large number of topics.unloadis to manually unbind a bundle that is already bound to a broker, thus triggering the load balancer to select a suitable broker to rebind; usually triggered when the entire cluster is unevenly loaded.
ThresholdShedder Principle
There are currently three implementations of the LoadSheddingStrategy interface, here is the official default ThresholdShedder as an example.
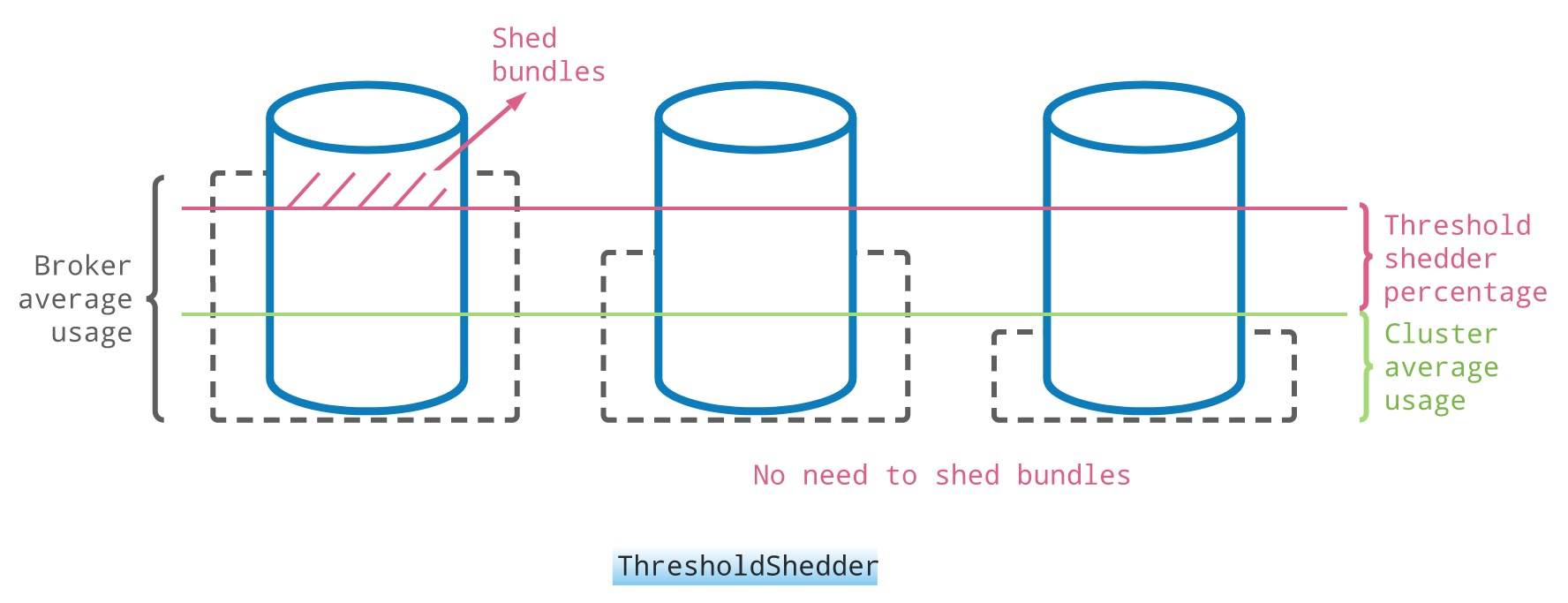
Its implementation algorithm is to calculate the load value of each node based on the weight of each metric such as bandwidth, memory, traffic, etc., after which an average load value is calculated for the whole cluster.
When the load value of a node in the cluster exceeds the average load value by a certain amount (configurable threshold), unload will be triggered, for example, the bundle in red in the leftmost node will be unloaded and then a suitable broker will be recalculated for binding.
The purpose of the threshold is to avoid frequent unloads, which can affect the client’s connection.
Cause of the problem
This load strategy can really handle well when there is a sudden burst of traffic to certain topics, but not necessarily in the case of our cluster upgrade.
Suppose I have three nodes here:
- broker0
- broker1
- broker2
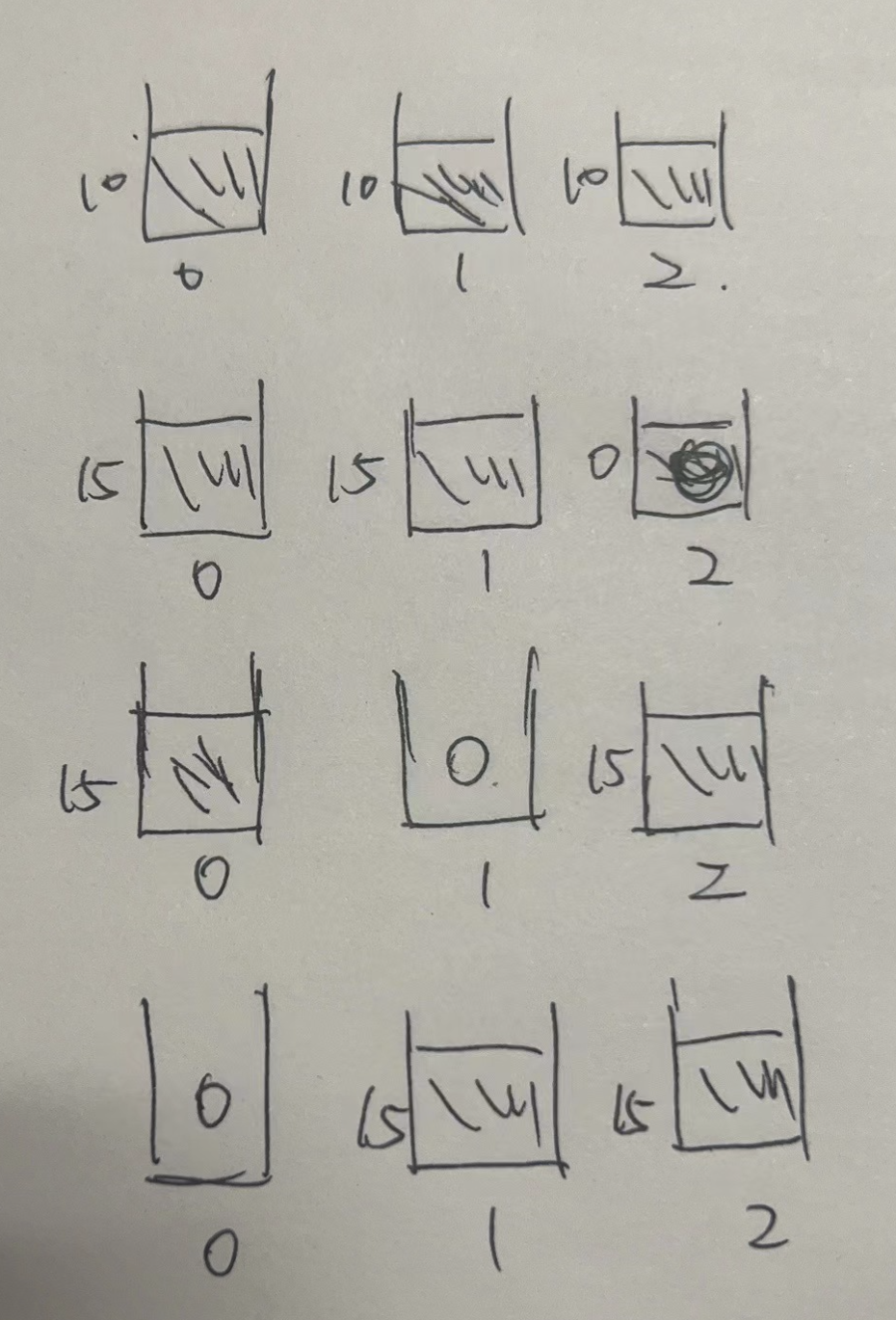
The cluster upgrade will restart with a mirror replacement from broker2->0, assuming that each broker has a load value of 10 before the upgrade.
- When restarting broker2, the bundle it is bound to is taken over by broker0/1.
- When broker1 is upgraded, its bundle is taken over by broker0/2 again.
- When you finally upgrade broker0, the bundle it is bound to is taken over by broker1/2.
As long as no traffic spike occurs after this to the threshold that triggers the load, then the current load situation will remain, i.e. broker0 will remain without traffic.
After I repeatedly tested, this is indeed the case.
|
|
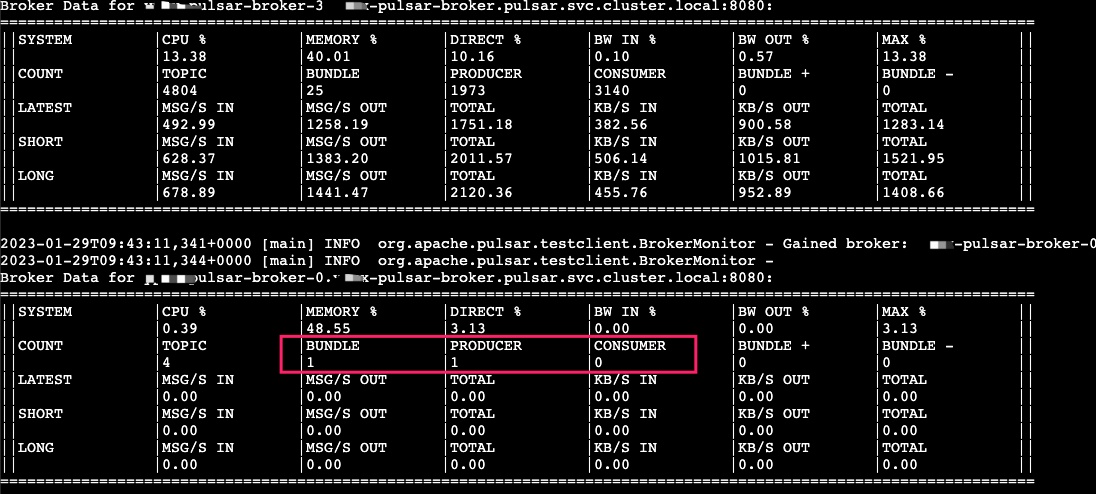
This tool also allows you to view the load of each node.
Optimization Scenario
This scenario is not considered by the current ThresholdShedder, so I made a simple optimization based on the version we are using, 2.10.3.
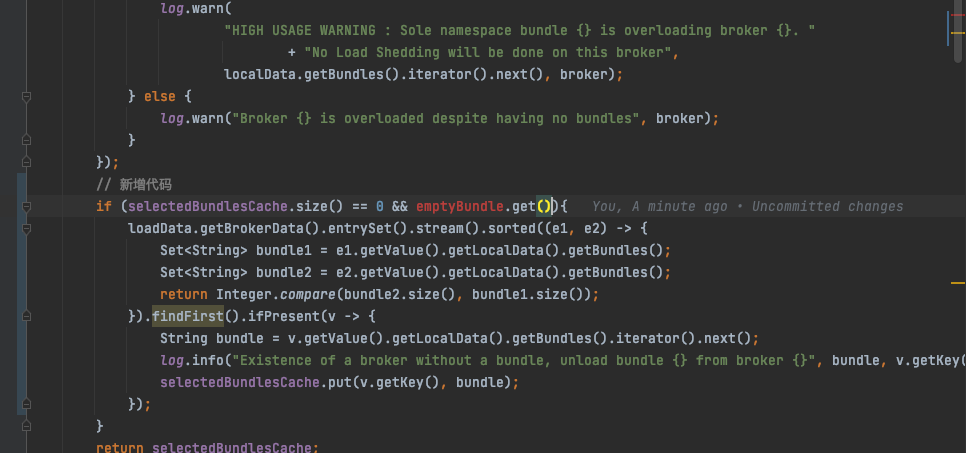
- When there is no bundle that needs to be unloaded after the original logic is finished, and there is also an extremely low-load broker (
emptyBundle), trigger another bundle query. - Select the first bundle of the broker with the highest number of bundles to unload, sorted by the number of bundles bound to the broker.
After modifying, building & releasing, and going through the upgrade process again, the entire cluster load is now balanced.
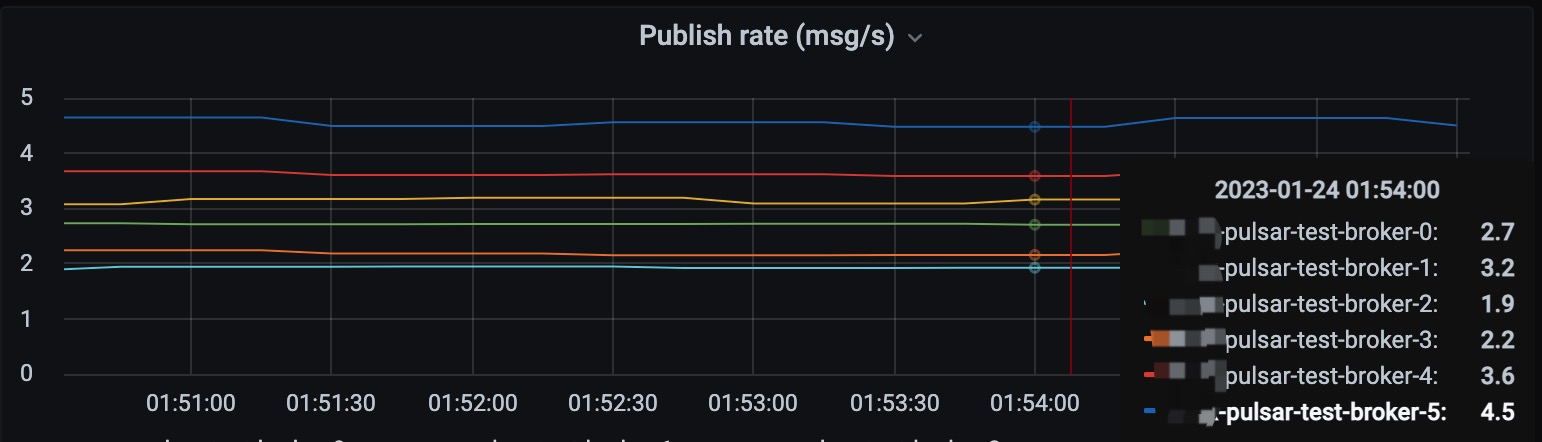
The second selection step focuses on filtering out the highest-loaded bundles in the highest-loaded clusters; this is simply based on the number of bundles, which is not accurate enough.
Just when I was about to keep optimizing, I wanted to see if someone had fixed the problem on master, and it turned out that someone had; it just hadn’t been officially released yet.
https://github.com/apache/pulsar/pull/17456
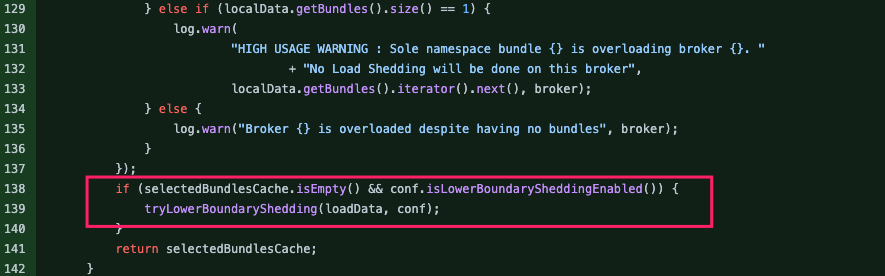
The overall idea is similar, except that filtering the load to unload the bundle is based on the bundle’s own traffic, which is more accurate.
Summary
However, looking at the progress of the community, we don’t know how long it will take for this optimization to finally work, so we made a similar function in the admin console with this idea in mind, and when there is a load imbalance after the upgrade, a logic is triggered manually.
- The system calculates a node and bundle with the highest load based on the load of each node to display on the page.
- Manually confirm twice if you want to uninstall and uninstall after confirming it is correct.
Essentially, it’s just a manual process that replaces the above optimized automatic load process, and the result is the same after testing.
The whole Pulsar project is actually very large, with dozens and hundreds of modules, even if I only change one line of code each time I am ready to release the test, I have to go through a long process of compiling + Docker image building + uploading, which usually takes 1~2 hours; but in general, the harvest is still very big, and I have been submitting some issues and PRs recently, so I hope I can participate more deeply in the community later.
Ref
https://crossoverjie.top/2023/02/07/pulsar/pulsar-load-banance/