Introduction to Karmada
Before we start talking about Resource Interpreter Webhook, we need to have some understanding of Karmada’s infrastructure and how to distribute applications, but that part has been mentioned in previous blogs, so we won’t go over it again in this post.
An example: Creating an nginx application
Let’s start with the simplest example, creating and distributing an nginx application in Karmada; the first step is to prepare the nginx resource template, which is the native K8s Deployment and does not require any changes.
Prepare a PropagationPolicy to control which clusters nginx is distributed to.
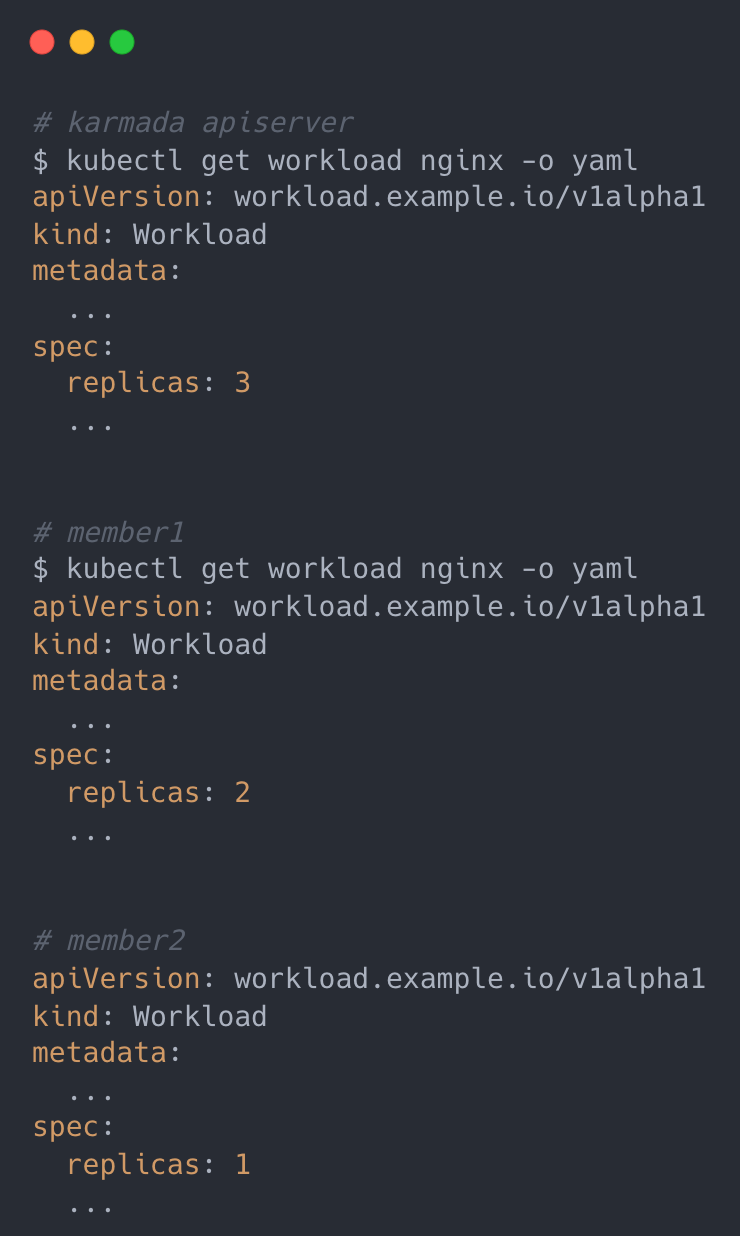
Here we will distribute it directly to the member1 and member2 clusters.
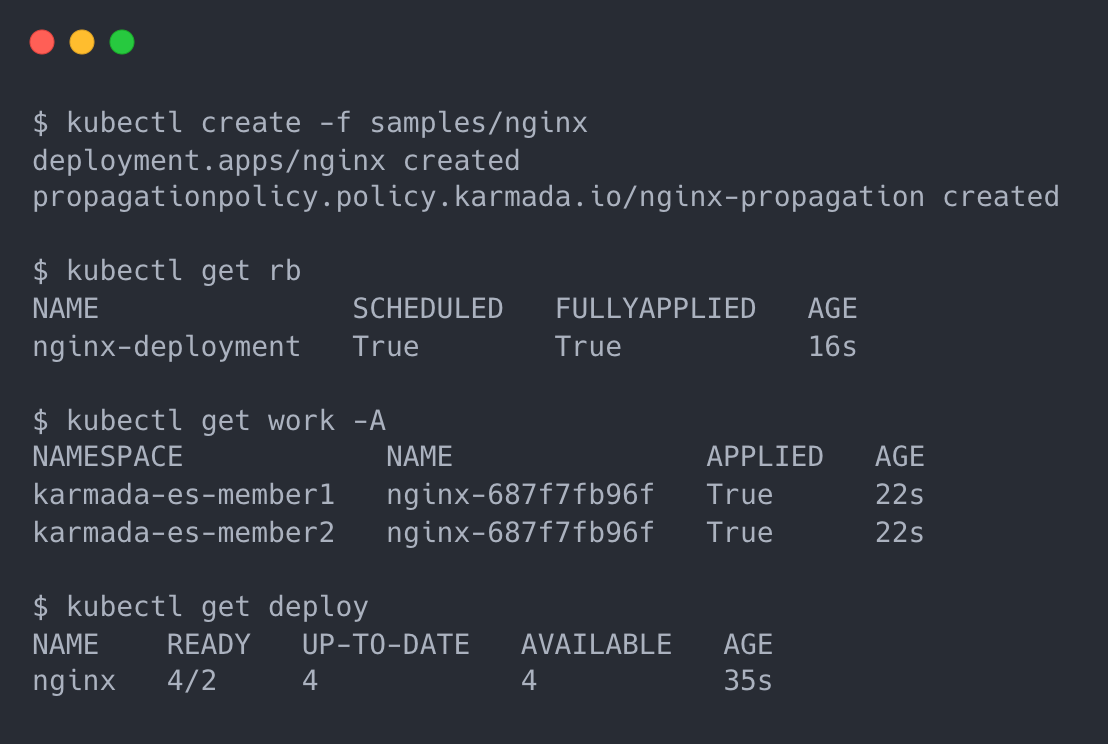
The member1 and member2 clusters each have an nginx Deployment with 2 copies, so there are 4 Pods of this resource.
The above example is very simple, just create Deployment directly in the member cluster based on the template as is, but as you know Karmada supports some more advanced replica scheduling policies, such as the following example.
After the rule is applied, it involves dynamic adjustment of the number of resource replicas on each cluster, and then Karmada needs to add a step to modify the number of replicas when creating Deployment on member clusters.
For a K8s core resource like Deployment, we can directly write code to modify the number of copies because its structure is deterministic, but what if I have a CRD that functions like Deployment? Can Karmada modify its replica count correctly if I also need replica count scheduling? The answer is no, so Karmada introduces a new feature to enable deep support for Custom Resources (CRD).
Resource Interpreter Webhook
To solve the above mentioned problem, Karmada introduces Resource Interpreter Webhook, which implements a complete custom resource distribution capability by intervening in the phases from ResourceTemplate to ResourceBinding to Work to Resource.

From one stage to another, we will pass through one or more predefined interfaces, and we will implement operations such as modifying the number of copies in these steps; the user needs to add a separate webhook server that implements the corresponding interface, and Karmada will call the server to complete the operation through the configuration when the corresponding step is executed.
In the following, we will select four representative hook points to introduce them one by one, and then use the following CRD as an example.
|
|
It is very similar to Deployment and is used to demonstrate how Karmada supports such resources for advanced features such as copy number scheduling.
InterpretReplica
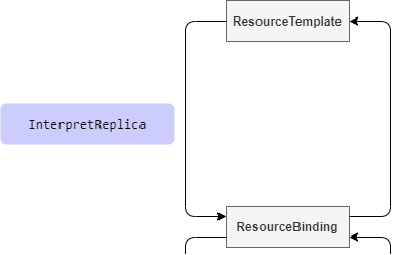
This hook point occurs during the process from ResourceTemplate to ResourceBinding, for resource objects with replica capabilities, such as custom resources like Deployment, and implements this interface to tell Karmada the number of replicas of the corresponding resource.
For our example Workload resource, the implementation is also very simple, just return the value of the number of copies in the webhook server.
Note: All examples are taken from the official Karmada documentation.
ReviseReplica
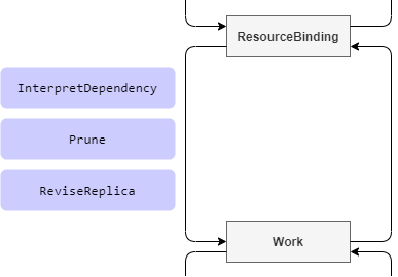
The hook point occurs during the process from ResourceBinding to Work, where you need to modify the number of replicas of a resource object that has replica capabilities according to the request sent by Karmada, which calculates the number of replicas needed for each cluster through its scheduling policy. All you need to do is to assign the final calculated value to your CR object (because Karmada does not know the structure of the CRD).
|
|
The core code is also only the assignment line.
Workload implements copy number scheduling
Going back to our original question, after understanding the InterpretReplica and ReviseReplica hook points, you can implement a custom resource scheduling by replica count, implement the InterpretReplica hook point to tell Karmada the total number of replicas of the resource, implement the ReviseReplica hook point to modify the number of copies of the object, and then configure a PropagationPolicy, the same way as for resources such as Deployment.
|
|
The effect is as follows.
Retain
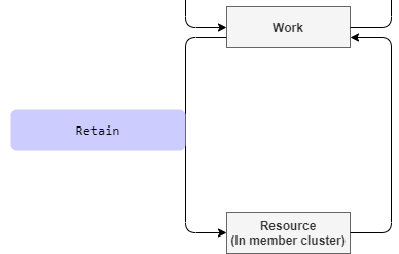
This hook occurs during the process from Work to Resource, and can be used to tell Karmada to keep certain fields in case the contents of spec are updated separately in the member cluster.
Take paused as an example, the function of this field is to suspend the workload, the controller of member cluster will update this field separately, the Retain hook is to better collaborate with the controller of member cluster, you can use this hook to tell Karmada which fields are not to be need to be updated and kept.
|
|
The core code is a single line that updates the Paused field of wantedWorkload to the contents of the previous version.
AggregateStatus
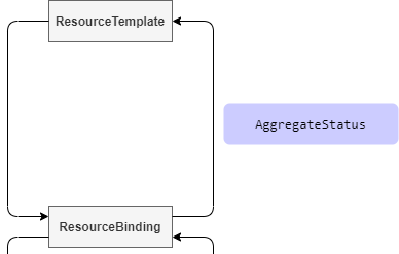
This hook point occurs during the process from ResourceBinding to ResourceTemplate. For resource types that need to aggregate status information to the Resource Template, the status information of the Resource Template can be updated by implementing this interface.
Karmada collects the status information of each cluster Resouce into ResourceBinding.
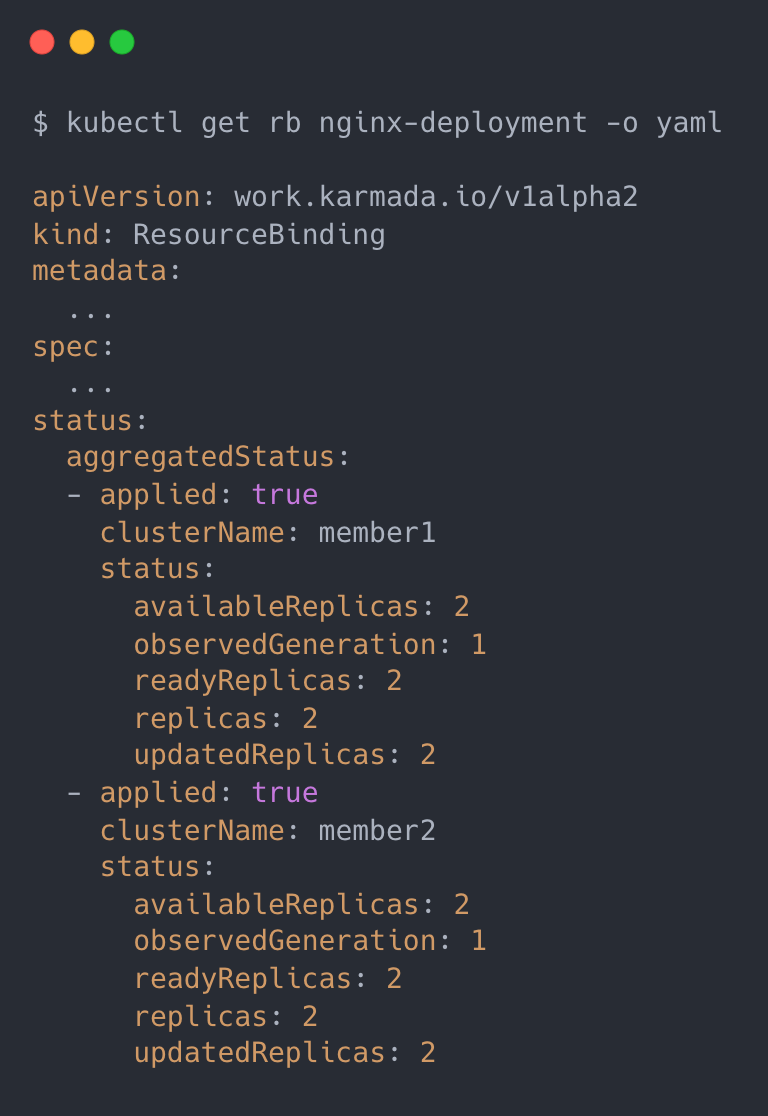
the AggregateStatus hook needs to do is to update the status information in the ResourceBinding to the Resource Template.
|
|
The logic is also very simple, based on the status information in the ResourceBinding to calculate (aggregate) the total status information of the resource and then update it to the Resource Template; the effect is similar to Deployment, you can directly query the status information of the resource in all clusters after aggregation.