Like other operating systems such as Window, Linux boots in two phases: boot and startup. The boot phase starts when the power switch is turned on, followed by the on-board program BIOS which starts the power-up self-test process and ends when the kernel initialization is complete. The boot phase takes over the rest of the work until the OS is initialized into an operable state and can perform functional user tasks.
We won’t spend too much time explaining the process of loading and running the hardware onboard program during the boot phase. In fact, since much of the behavior on the on-board program is essentially fixed and difficult for programmers to intervene, we will focus on how the motherboard’s bootloader loads the kernel and the boot process for each service after control is handed over to the Linux operating system.
GRUB Bootloader
The so-called bootloader, an intelligent program used by the computer to find the operating system kernel and load it into memory, is usually located on the first sector of the hard disk and is loaded into memory by the BIOS for execution. Why is the bootloader needed instead of loading the operating system directly by the BIOS? The reason is that BOIS automatically loads only 512 bytes of the first sector of the hard disk, and the size of the operating system is much larger than that, which is why the bootloader is loaded first, and then the operating system is loaded into memory via the bootloader.
GRUB (GRand Unified BootLoader) is currently the dominant bootloader for all Linux distributions, and has several main functions.
- Has a menu interface that allows the user to choose which system to boot
- Can call other bootloaders to implement multi-system boot
- Load the kernel program of the operating system
GRUB1 is now gradually deprecated and has been replaced by GRUB2 on most modern distributions. GRUB2 is configured via /boot/grub2/grub.cfg, and eventually GRUB locates and loads the Linux kernel program into memory and transfers control to the kernel program.
Kernel programs
The kernel files are located in the /boot directory and are prefixed with the prefix vmlinuz. The kernel files are stored in a self-extracting compressed format to save space, and the selected kernel program is loaded into memory and started executing since it is unpacked.
|
|
init process
Once the kernel files are self-extracting, the Linux operating system starts running the first program, /sbin/init, which serves to initialize the operating system environment. Since the init process is the first program to be run by the operating system, it has a pid of 1. All other processes are derived from it, so the init process is the ancestor of all other processes. In fact, init exists as a daemon.
The system that defines, manages, and controls the init process is called the init system.
We know that there is no real point in just getting the kernel up and running; the init system must bring the entire Linux operating system into an operational state. init is primarily responsible for running these boot programs. However, there are different occasions when different programs need to be started to enter different preset run modes. For example, start shell for human-computer interaction, so that the computer can execute some predefined programs to accomplish meaningful tasks, or start the X graphics system to provide a friendly human-computer interface to accomplish tasks more efficiently. Here, shell, which runs the command line interface, and X, which runs the graphical interface, are different preset modes of operation.
History of the init system
Most Linux distributions have an init system that is compatible with System V, called SysVInit, which is the original init system. In the days when Linux was mainly used on servers and PCs, the SysVInit concept was simple, clear and stable. However, it relied heavily on shell scripts and was therefore slow to boot. This did not matter much on servers that rarely needed rebooting, but as the Linux kernel evolved and the Linux operating system was increasingly used on mobile devices, the slow boot time seriously affected the user experience and was increasingly criticized.
To solve the problem of slow boot, people started to think about improving SysVInit, and two major new generation init systems emerged, UpStart and Systemd. UpStart has been in development for more than 8 years and has replaced SysVInit on many systems, while Systemd came later, but has evolved faster and is on the verge of replacing UpStart in every Linux distribution. In fact, Ubuntu and RHEL have replaced the legacy SysVInit with UpStart. Fedora distributions have been using Systemd since version 15.
SysVInit
For older Linux distributions that use SysVInit, a “Run Level” is used to define different reserved run modes. Such Linux distributions typically have seven preconfigured run levels (0-6). Typically, 0 means shutdown, 1 means single-user mode (also known as maintenance mode), and 6 means reboot. Run levels 2-5 vary from distribution to distribution, but are basically multi-user mode (a.k.a. normal mode).
The init process first reads the runlevel settings file /etc/inittab for the initdefault option, which represents the default runlevel; if there is no default runlevel, then the user needs to enter the operating system console to manually decide which runlevel to enter. The first line of the runlevel configuration file usually looks like this:
|
|
This means that the default runlevel at startup is 2. If you need to specify another level, you need to change this value manually.
But here comes the problem. In different runlevels, the service processes that the system needs to initialize to run and the initial preparation that needs to be done are different, and some Linux distributions do not need to start the GUI system in runlevel 3. How does the system know which programs to load at each level? The answer is that each runlevel has several subdirectories under the /etc directory starting with rc that specify the service programs that need to be loaded for each runlevel. This way, the user only needs to specify which runlevel to enter, and SysVInit will take care of all the initialization required at that level.
|
|
The rc in each of the above directory names indicates run command, and the final d indicates directory. Let’s see what programs are specified in the /etc/rc2.d directory.
|
|
As we can see, except for README, all other files are named in the form of “letter S + two digits + program name”. The letter S stands for Start, which represents the program to be started at the current level; the letter K stands for Kill, which means the program to be closed when switching from other running levels; the two digits after that indicate the processing order, the smaller the number the earlier the processing, so the first program to be started is apport, then rsyslog, uuidd, postfix and so on. When the numbers are the same, the programs will be started in alphabetical order according to their names, so rsyslog will be started before uuidd.
Also, we notice that the programs listed in /etc/rcN.d are actually set as symbolic links to the real program startup scripts in another directory /etc/init.d, and the init process loads the startup programs one by one, actually running the startup scripts in this directory. The advantage of this is that if you need to manually shut down or restart a process, you can just go to /etc/init.d and look for the corresponding startup script. For example, to restart the ssh service, just run the following command.
|
|
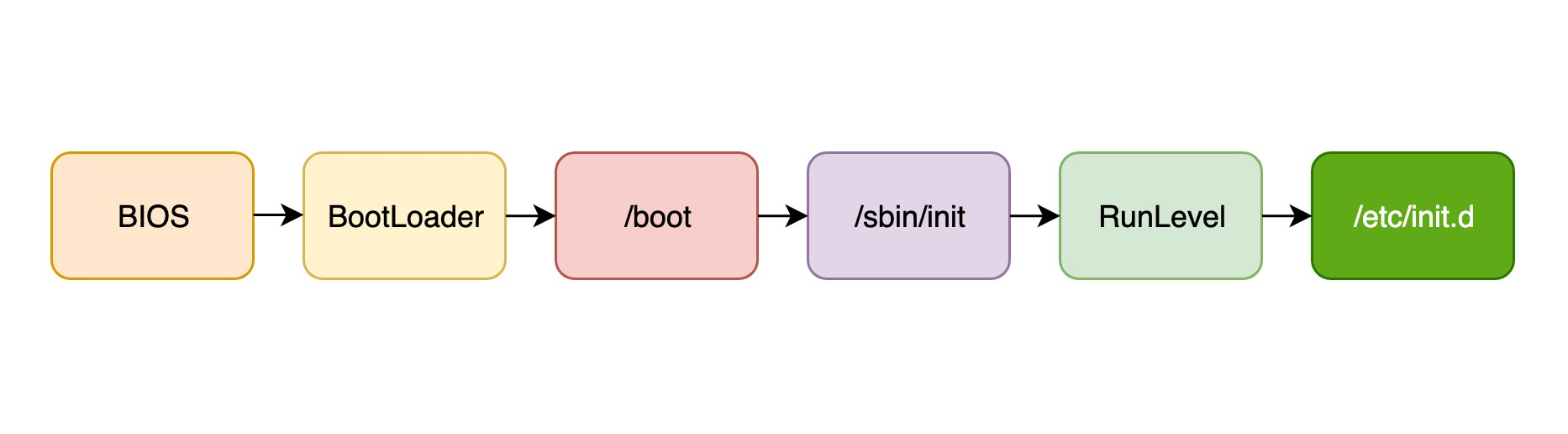
From the above, we understand that for an operating system that uses SysVInit to boot, the general process from BIOS power-up to the completion of each OS process can be described by the following diagram.
Upstart
When the Linux kernel entered 2.6, many of the features of the kernel were perfectly suited for desktop systems and even embedded devices, so developers began to experiment with Linux porting. Most notably, Ubuntu developer Scott James Remnant tried to install Linux on a laptop, but found that the old SysVInit was not suitable for desktop systems or portable devices, for the following reasons.
- Desktop systems or portable devices are characterized by frequent reboots and frequent use of hardware hot-plugging techniques, and SysVInit has no way to handle such on-demand peripheral boot requirements.
- The problem of mounting network share disks, where SysVInit analyzes
/etc/fstabbefore network initialization to discover the corresponding mount file and the mount location, but if the network is not booted, network share disks similar to NFS or iSCSI are inaccessible, and of course, no mount operation can be performed.
In response to the above shortcomings of SysVInit, the Ubuntu developers decided to redesign and develop a new init system, UpStart, which will be explained next.
UpStart is based on an event mechanism, e.g. when a USB flash drive is inserted into the USB interface, the udev device is notified by the kernel that a new device has been found and this is a new event. UpStart senses this event and triggers the corresponding wait tasks, e.g. processing the presence of mount points in /etc/fstab. With this event-driven model, UpStart perfectly solves the problems associated with plug-and-play devices, while significantly reducing system boot time by parallelizing the boot process.
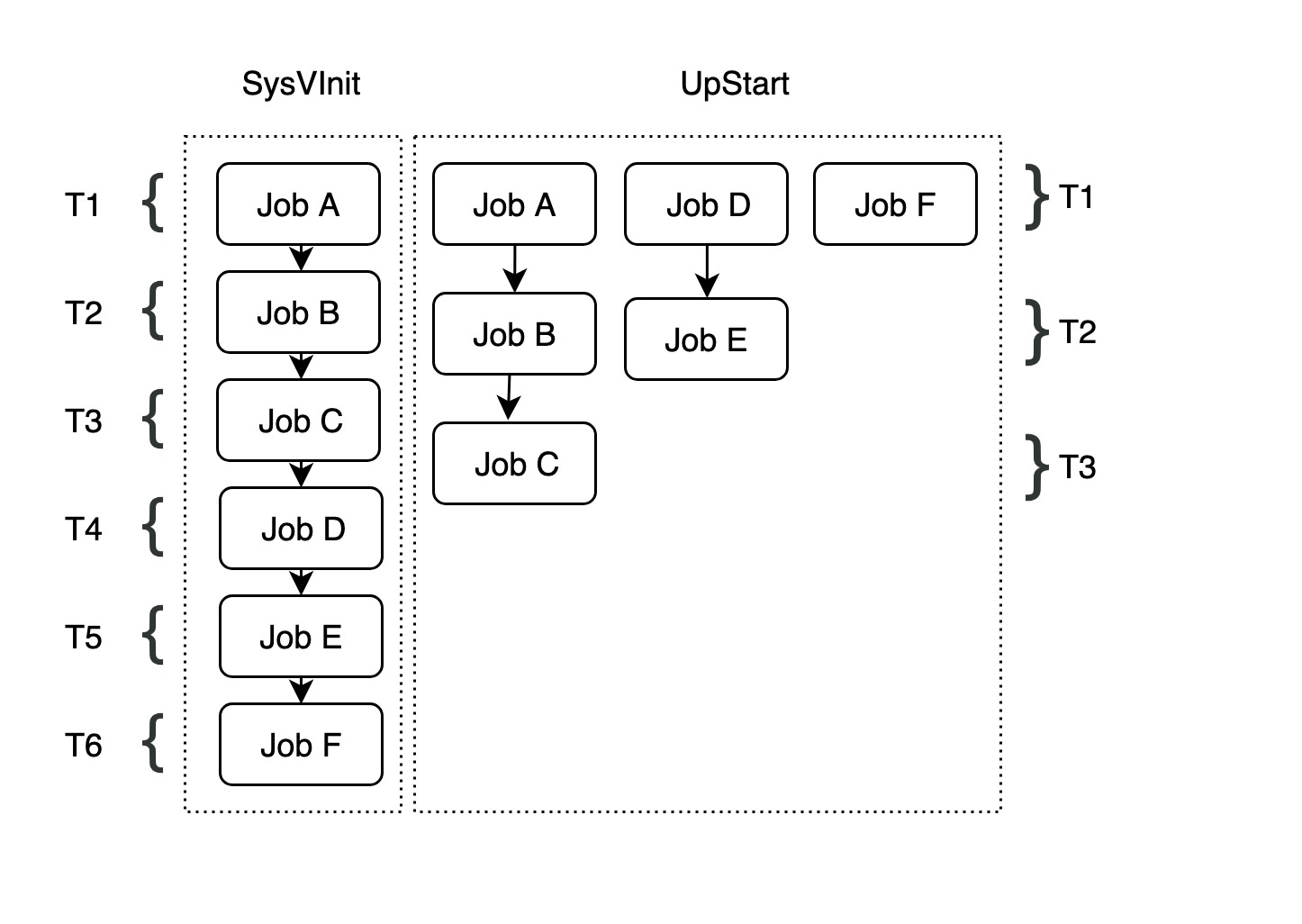
In the above example, there are 7 different programs to be started: JobA JobB JobF. In SysVInit, each startup item is handled by a separate script and they are called serially by SysVInit in order, so the total startup time is T1+T2+T3+T4+T5+T6+T7. Some of these tasks have dependencies, for example JobC, JobB, JobA need to be started sequentially, while JobE depends on JobD and JobF has nothing to do with JobA, JobB, JobC, JobD, JobE. In this case, UpStart can run tasks {(JobA,JobB,JobC),(JobD,JobE),JObF} concurrently, which reduces the total startup time to T1+T2+T3. This definitely increases the parallelism of system startup and thus improves the system startup speed. However, in UpStart, services with dependencies must still be started serially, such as task {(JobA,JobB,JobC)}.
The main concepts in UpStart are job and event. A job is actually a unit of work that accomplishes a specific task, such as starting a background service or running a configuration command. Each job waits for a response to one or more events, and once the response to the event is obtained, UpStart triggers the corresponding job to complete the corresponding work. The process of initializing a Linux distribution using UpStart is a collaborative effort between jobs and events, and can be roughly described as follows: after the kernel is initialized, the init process starts running, and the init process itself emits different events, and these initial events trigger some jobs to run; each job, in the process of running, releases new and different events. Each job will release a new event, which will trigger a new job, and so on, until the whole system is up and running.
So, what events trigger a job to run? This is defined by the job’s configuration file. job configuration text files contain several sections, each of which is a complete definition module that defines an aspect of the job, such as the author section that defines the job’s author. job configuration files are stored in the /etc/init directory, with .conf as the file suffix. Let’s take a look at the definition of the cron job configuration file under Linux.
|
|
As you can see from the output above.
descriptionis a short description of the jobstart onis used to define all events that trigger the jobstop onhas the opposite semantics ofstart onand defines which events the job needs to stop when triggeredexpectis divided into two types,expect forkmeans the process will only fork once;expect daemonizemeans the process will fork twice to turn itself into a background processexecconfigures the commands that the job needs to runscriptdefines the script that the job needs to run
For a detailed definition of the job profile, please refer to http://upstart.ubuntu.com/cookbook/
Note: It is important to note that the traditional Linux distribution system initialization is based on the runlevel, i.e. SysVInit, so many Linux software is still booted using the traditional SysVInit script and no new boot script has been developed for UpStart. Therefore, even on Debian and Ubuntu distributions, the old SysVInit runlevel model must be emulated to be compatible with most existing software.
Systemd
Systemd is the newest init system in most Linux distributions, designed primarily to overcome the inherent flaws of SysVInit and improve system boot speed. systemd and UpStart are competitors, and are gradually replacing UpStart in the domination of Linux distributions.
Note: Similar to UpStart, Systemd introduces a new way of configuration. There are also some new requirements for application development. However, for historical reasons many applications on Linux have not had time to change for it. If Systemd is to replace the currently running init system, it must be compatible with existing applications. In fact, Systemd does provide compatibility with SysVInit, so that services and processes already on the system can be managed by Systemd without modification, which reduces the cost of migrating to Systemd and makes it possible to replace the existing init system.
1. Faster startup
Systemd provides a more aggressive parallel start capability than UpStart, using techniques such as socket/D-Bus activation to start services, with the following ultimate goal.
- Start as few processes as possible
- Start as many processes in parallel as possible
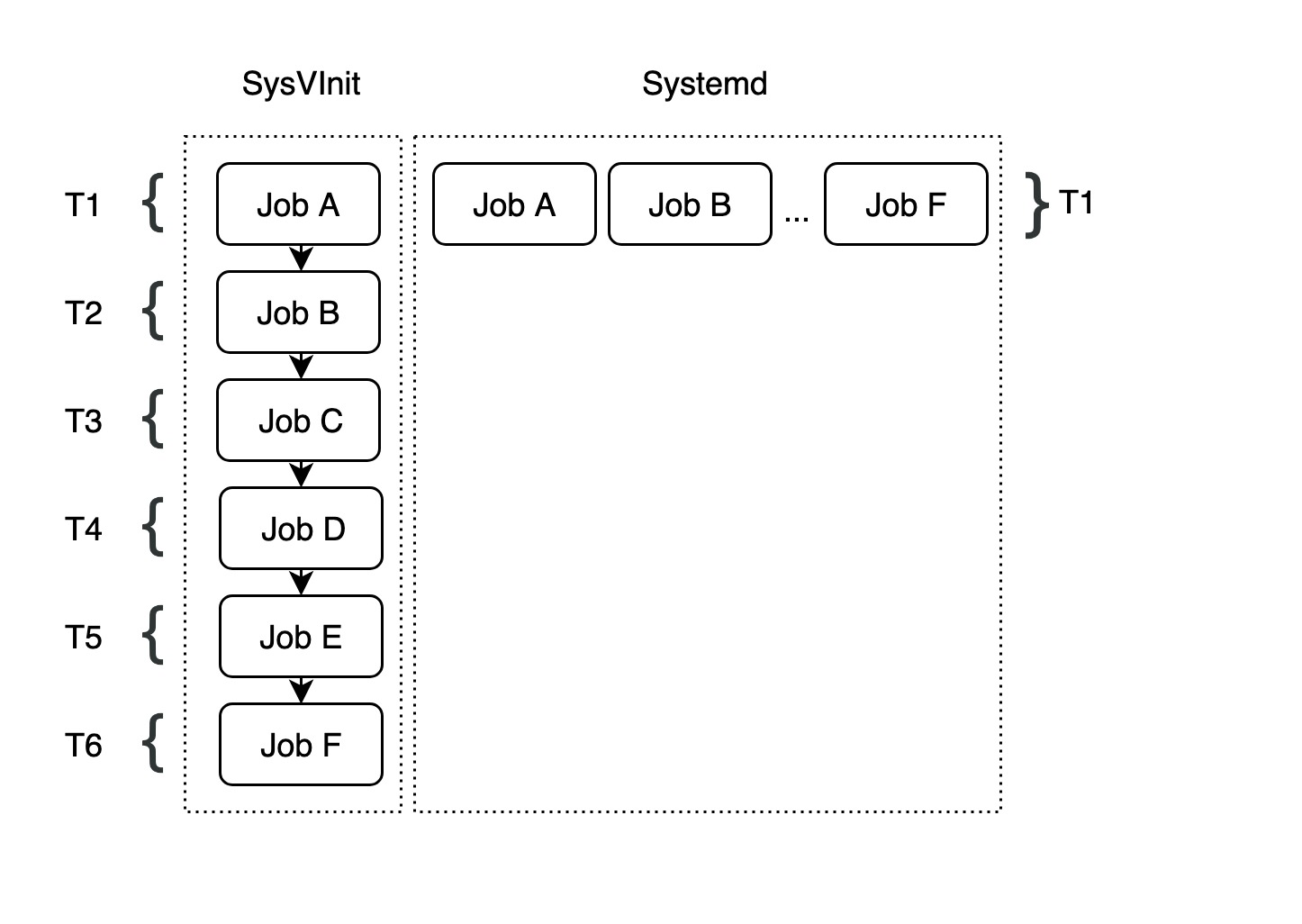
As shown in the figure above, Systemd improves the concurrency of multiple startup programs on top of UpStart, even for programs that depend on each other and must be started serially. Since all tasks can be executed concurrently, the total startup time is further reduced to T1.
2. On-demand start-up capability
The traditional SysVInit system initialization will start all the background service processes used, and the system must wait until all programs are ready to start before the OS initialization is completed. This not only results in long boot times, but also wastes system resources. In fact, some services may not be used for a long period of time, or even for the entire duration of the server, and the time spent on starting these services is unnecessary and causes unnecessary waste of resources.
The traditional SysVInit system initialization will start all the background service processes used, and the system must wait until all programs are ready to start before the OS initialization is completed. This not only results in long boot times, but also wastes system resources. In fact, some services may not be used for a long period of time, or even for the entire duration of the server, and the time spent on starting these services is unnecessary and causes unnecessary waste of resources.
Systemd can provide the ability to start on demand, starting a service only when it is actually requested. When that service is finished, Systemd can shut it down and wait for it to be started again the next time it is needed.
3. Using CGroup to track processes
An important role of the init system is to track and manage the life cycle of a service process, which must not only be able to start a service, but must also be able to stop it. In fact, stopping a service is more complicated than you might think, because the service process usually runs as a background process, and for this reason the service process sometimes forks twice. As we mentioned earlier in the expect keyword in UpStart’s job configuration file, expect needs to be configured correctly in the configuration file so that UpStart can count the fork system calls to get the PID of the real background process. But finding the correct PID is difficult in practice, so UpStart uses the clunky scheme of strace to keep track of fork, exit, and other system calls. Systemd, on the other hand, uses the CGroup feature to accomplish the task of service process tracking. When it comes time to stop a service process, by querying the CGroup, Systemd can ensure that all relevant processes are found, and thus stop the service process cleanly.
Note: CGroup is mainly used to implement system resource quota management, it provides a file system like interface, when a process creates a child process, the child process will inherit the CGroup of the parent process. So no matter how the service starts a new child process, all the related processes will belong to the same CGroup, and Systemd can simply iterate through the specified CGroup to find all the related processes correctly.
4. Logging Service
Systemd comes with its own logging service, Journal, to overcome the shortcomings of the existing syslog service on Linux systems.
- syslog is not secure and the content of messages cannot be verified. Each local process can claim to be
Apache PID 4711, but syslog does not have any mechanism to verify this and saves the log directly to disk. - There is no strict format for the data. Automated log analyzers need to analyze natural human language strings to identify messages. syslog’s lack of strict formatting makes analysis difficult and inefficient, and changes in log format can cause analysis code to be updated or even rewritten.
Systemd’s own logging service, Journal, stores all logging information in binary format, and users use the journalctl command to view the logging information. There is no need to write your own complex and fragile string parsing processors.
5. Configuration Units
As a new generation init system, Systemd abstracts each task of starting a service or configuration during system initialization into a configuration unit, Unit. A service is a configuration unit, a mount point is a configuration unit, and the configuration of a swap partition is a configuration unit. systemd groups configuration units into a number of different types, as follows.
service: The most common type of configuration unit, representing a background service process, such asmysqld.socket: This type of configuration unit encapsulates a socket in network communication. Currently, Systemd supports AF_INET, AF_INET6, and AF_UNIX sockets for streaming, datagram, and continuous packets. each socket configuration unit has a corresponding service configuration unit. The corresponding service is started when the first “connection” enters the socket (for example:nscd.socketstartsnscd.servicewhen a new connection is made)device: These configuration units encapsulate a device that exists in the Linux device tree. Each device tagged with theudevrule will appear as a device configuration unit in Systemdmount: This type of configuration unit encapsulates a mount point in the file system structure hierarchy. systemd will monitor and manage this mount point, for example by automatically mounting it at boot time and automatically unmounting it under certain conditions. systemd will convert all entries in/etc/fstabto mount points and process them at boot timeautomount: This type of configuration unit encapsulates a self-mount point in the system structure hierarchy. Each self-mount configuration unit corresponds to a mount configuration unit, and when the automount point is accessed, Systemd performs the mount behavior defined in the mount pointswap: Similar to the mount configuration unit, the swap configuration unit is used to manage swap partitions. Users can use the swap configuration unit to define swap partitions on the system that can be made active at boot timetarget: These configuration units are logically grouped for other configuration units, they do not actually do anything themselves, they just refer to other configuration units, so that you can have a unified control over the configuration units, thus implementing the concept of “runlevel” in the SysVinit system. For example, if you want to put the system into graphical mode, you need to run a number of services and configuration commands, which are represented by individual configuration units, and combining all these configuration units into a target means that you need to execute all these configuration units in order to enter the running state of the system represented by the target (e.g.,multi-user.targetis equivalent tomulti-user.targetin a traditional system using SysVInit system, the runlevel is set to 5)timer: Timer configuration units are used to trigger user-defined actions at regular intervals, replacing traditional timing services such as atd, crond, etc.snapshotSimilar to thetargetconfiguration unit, a snapshot is a set of configuration units that stores the current operational state of the system
Note: As Systemd is rapidly evolving and new features are being added, the number of configuration unit types will continue to increase.
Each configuration unit has a corresponding configuration file, and it is the system administrator’s task to write and maintain these different configuration files, such as the MySQL service corresponding to the configuration file named mysql.service. The syntax of such configuration files is very simple, and users do not need to write and maintain complex system scripts.
6. Dependencies
Although Systemd eliminates the dependency of a large number of boot tasks, they can be started concurrently. However, there are still some tasks that have “inherent dependencies” on each other, for example: mounts must wait for a mount point to be created in the file system; mounts must also wait for the corresponding physical device to be ready. To solve such dependencies, Systemd’s configuration units can define dependencies on each other.
Systemd uses keywords in the configuration unit definition file to describe dependencies between configuration units, e.g., unit A depends on unit B, which can be represented by require A in the definition of unit B. This way, Systemd will ensure that unit A is started before unit B.
7. target and runlevel
Systemd replaces the traditional SysVinit system concept of “runlevel” with target, providing more flexibility to create your own new target by inheriting an existing target and adding other service programs. The following table shows the correspondence between targets and common runlevels under Systemd.
| SysVInit runlevel | Systemd target | Description |
|---|---|---|
| 0 | runlevel0.target, poweroff.target | Shutdown System |
| 1, s, single | runlevel1.target, rescue.target | Single-user mode |
| 2, 4 | runlevel2.target, runlevel4.target, multi-user.target | User defined/domain specific runlevel, default equal to 3 |
| 3 | runlevel3.target, multi-user.target | Multi-user non-graphical, users can log in through multiple consoles or networks |
| 5 | runlevel5.target, graphical.target | Multi-user graphical, usually with a graphical login for all services running level 3 |
| 6 | runlevel6.target, reboot.target | Reboot |
| emergency | emergency.target | Emergency Shell |
8. Systemd usage
-
Writing unit configuration files
Similar to the UpStart job configuration file, the developer needs to define the command line syntax for starting the service application and the dependencies with other services in the
unitconfiguration unit file. For example, the following shows the configuration unit file for an SSH service application, with.serviceas the filename extension.1 2 3 4 5 6 7 8 9 10 11 12 13# cat /etc/system/system/sshd.service [Unit] Description=OpenSSH server daemon [Service] EnvironmentFile=/etc/sysconfig/sshd ExecStartPre=/usr/sbin/sshd-keygen ExecStart=/usrsbin/sshd -D $OPTIONS ExecReload=/bin/kill -HUP $MAINPID KillMode=process Restart=on-failure RestartSec=42s [Install] WantedBy=multi-user.targetAs you can see, the SSH service configuration unit file is divided into three sections: the first is the
[Unit]section, which contains only a short description; the second is the[Service]definition, whereExecStartPredefines the commands that should be run before starting the service, andExecStartdefines the specific command line syntax for starting the service; the third is[Install], whereWangtedByindicates that the service is required in multi-user mode.Since we’re talking about multi-user mode, let’s take a look at the
multi-user.targetconfiguration unit, which belongs to thetargettype of configuration units.The
Requiresfield definition in the first[Unit]indicates that whenmulti-user.targetis started,basic.targetmust also be started; theAfterfield indicates that whenbasic.targetis stopped,multi-user.targetmust also be be stopped. If you look at thebasic.targetconfiguration unit file, you will see that it specifies other units such assysinit.targetin theRequiresfield; alsosysinit.targetwill contain other units, and it is with this nested chain structure that all component services that need to support multi-user mode are eventually will be initialized.In
[Install]there is anAliasdefinition, which defines an alias for this unit, so that when you runsystemctlyou can use this alias to refer to this unit, in this casedefault.target.In addition, under the
/etc/systemd/systemdirectory you can also see directories such as*.wants, where the configuration unit files are equivalent to thewantskeyword in[Unit], i.e., these service units need to be started when this unit is started. We can put our ownfoo.servicefile into themulti-user.target.wantsdirectory, and it will be started by default every time. -
Systemd command line tool: systemctl
Similar to other init system management tools such as
service,chkconfigandtelinit,systemctlcan also perform complex service process management tasks, with a slightly different syntax, e.g.1# systemctl restart mysql.serviceUsed to restart the MySQL service.
1# systemctl list-unit-files --type=serviceUsed to list the list of service programs that can be started or stopped.
1# systemctl enable mysql.serviceSet the service program to start automatically at the next startup or when other trigger conditions are met.
For more detailed instructions on the use of
systemctl, please refer to:https://www.digitalocean.com/community/tutorials/how-to-use-systemctl-to-manage-systemd-services-and-units
User Login
Login methods
Once all the service processes have been initialized, the Linux operating system is ready for the user to log in, and generally Linux distributions provide three ways for the user to log in.
- Command line login
- SSH login
- Graphical interface login
Each of these user login methods has a corresponding authentication method.
- Command line login: the init process calls the getty program, gets the username and password, then calls the login program, checks the password, and if the username and password combination is correct, reads the shell specified by the user from the file
/etc/passwdand starts the shell. - SSH login: similar to command line login, except that the init process system calls the SSHD service instead of getty and login, and then launches the corresponding shell
- GUI login: the init process calls the display manager, the corresponding display manager for the Gnome GUI is GDM, gets the username and password entered by the user, and if the username and password combination is correct, it reads
/etc/gdm3/Xsessionand starts the user session
Enter the shell
A shell is simply a command line interface that allows end users to interact directly with the operating system. In fact, the shell initialization operation is different for different user login methods.
-
Command line login: first read
/etc/profile, which is valid for all users; then look for the following three configuration files for the current user in order.Note: As long as one of the above three files exists, it will not continue to read in the following files.
-
SSH login: exactly the same as command line login
-
GUI login: only
/etc/profileand~/.profileare loaded,~/.bash_profilewill not run whether it exists or not
Open non-login shell
In fact, after the user enters the operating system, a special shell called non-login shell is often opened, which is different from the shell that appears when logging in, and does not read configuration files such as /etc/profile and .profile. The non-login shell reads the user’s bash configuration file ~/.bashrc, and most of the time, customizations to bash are written in this file. Even if you do not enter the non-login shell, .bashrc will run normally, and we can see code snippets like the following in the ~/.profile file.
Anyway, in either case, .bashrc will be executed when the user logs in, and the user’s settings can be safely written to this file.
The reason why there are so many complex login setup files is due to historical reasons. In the early days of Linux, computers were very slow and it took a long time to load configuration files, so most shell authors had to divide the configuration files into several parts and load them in stages. General system settings were placed in /etc/profile, user-specific settings that needed to be inherited by all child processes were placed in .profile, and settings that did not need to be inherited were placed in .bashrc.