In recent years, front-end and back-end separation has become popular. In a typical front-end and back-end separated application architecture, the back-end mainly acts as a Model layer to provide the API for data access to the front-end, and the communication between the front-end and back-end needs to be carried out between heterogeneous networks that are not trusted (Zero Trust). In order to ensure the secure and reliable transmission of data between the client and server, it is important to implement client-side authentication. The HTTP protocol itself is stateless, and the basis for client-side authentication of the server is to record the conversation status of the client and the server.
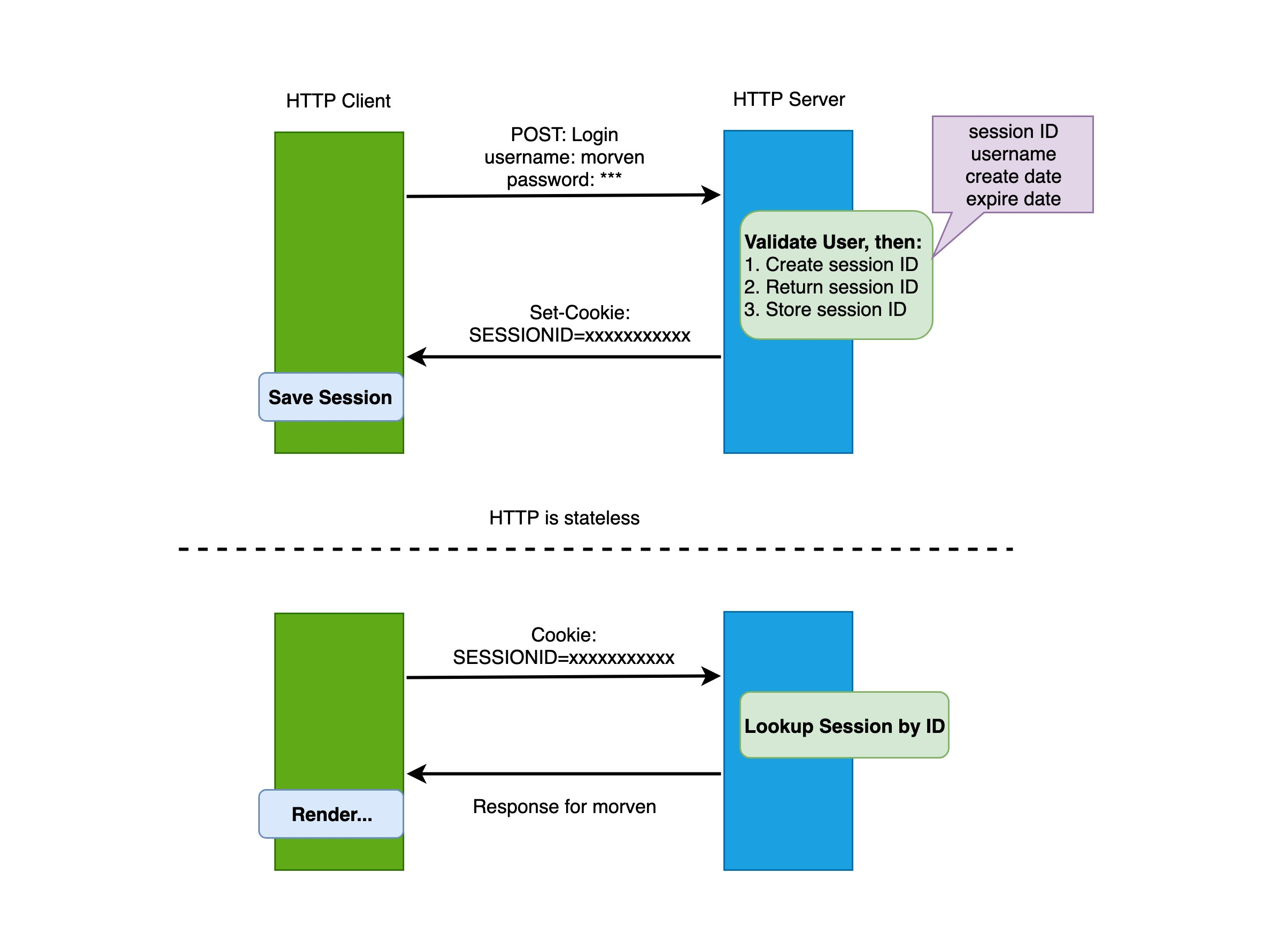
The most familiar way to authenticate the client is the session/cookie-based state logging method, and the basic process is as follows.
- the client sends username and password to the server
- The server authenticates, creates a new conversation (session) and saves the relevant data, such as user role, login time, etc.
- The server returns a SESSIONID to the client, which is written to the client’s cookie.
- Each subsequent request from the client will send the SESSIONID back to the server via a cookie.
- The server receives the SESSIONID, takes out the corresponding session and compares it with the saved session information to know the identity of the user.
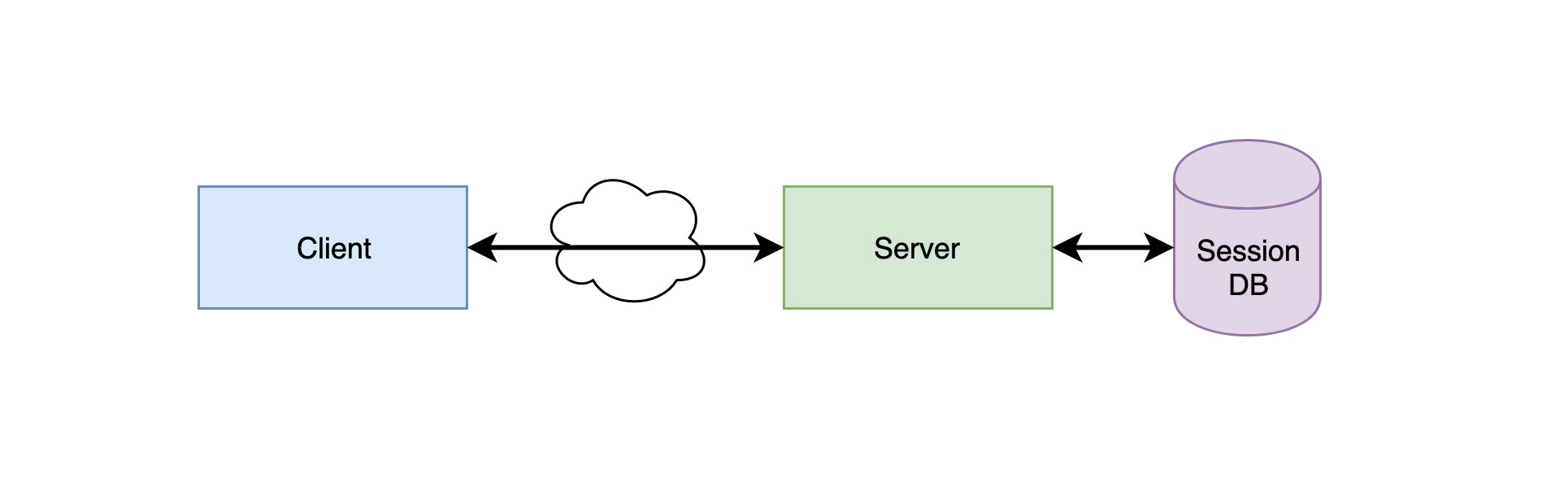
The biggest problem with this authentication approach is that there is no distributed architecture to support horizontal scaling. If a single server is used, the model is perfectly fine. However, if it is a cluster of servers or a service-oriented cross-domain architecture, a unified session database repository is needed to hold session data for sharing so that each server under load balancing can properly authenticate users.
For example, if an enterprise has two different sites A and B serving at the same time, how can a user log in to one of the sites and then it will automatically log in to the other site?
One solution is to use a persistent session infrastructure, such as Redis, to write session data to the persistence layer. When a new client request is received, the server looks up the corresponding session information from the persistence layer. The advantage of this solution is that the architecture is clear, while the disadvantage is that the architecture is more laborious to modify, and the entire validation logic layer of the service needs to be rewritten, which is a relatively large amount of work. And because of the dependence on the persistence layer of the database or similar systems, there will be a single point of failure risk, if the persistence layer fails, the entire authentication system will hang.
Is there another solution? This is the JWT (JSON Web Token) authentication method we are about to learn.
What is JWT
JWT is an alternative approach to authenticate clients based on tokens, which means that only the corresponding token needs to be attached to the HTTP header of each client request, and the server side is responsible for checking the signature of the token to ensure that the token has not been tampered with, so that each request is sent back to the server side for authentication by the client saving the data instead of the server saving the session data.
JWT is an open standard as defined in Official (RFC 7519), which defines a simple and secure scheme for transferring JSON-formatted token information between client and server.
How JWT works
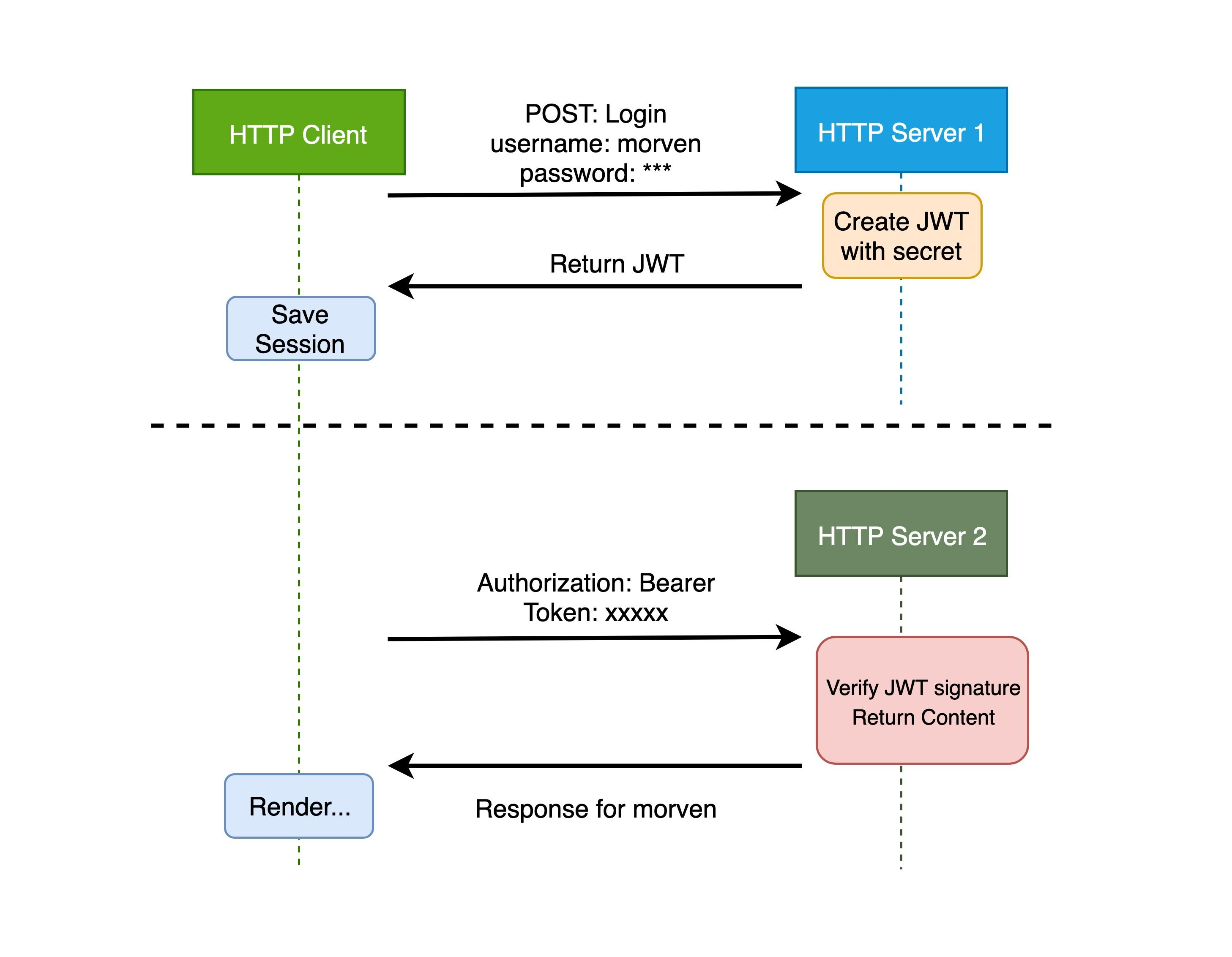
The basic principle of JWT server-side authentication is that after the server has authenticated, a JSON object is generated and sent back to the client, as follows.
Later, when the client communicates with the server, the client needs to send back this JSON object in the request. The server relies only on the contents of this JSON object to authenticate the client. To prevent man-in-the-middle from tampering with the data, the server adds a signature to the JSON object when it is generated. However, the server does not store any session data, i.e., the server becomes stateless, making it easier to scale.
Data format of a JWT
The data structure of a typical JWT looks like the following diagram.

The JWT object is a very long string, with characters separated by . is divided into three substrings, and there is no line break between the strings, each substring represents a functional block with the following three parts in total.
JWT Header
The JWT header is a JSON object that describes the JWT metadata, usually as follows.
In the above code snippet, the alg attribute indicates the algorithm used for the signature, the default is HMAC SHA256; the typ attribute indicates the type of the token, JWT tokens are uniformly written as JWT; finally, the above JSON object is converted to a string using the Base64URL algorithm and saved.
JWT Payload
The payload section, which is the main content section of the JWT, is also a JSON object that contains the data to be passed.
The JWT specifies seven default fields to choose from.
iss: Issuerexp: expiration timesub: subjectaud: usernbf: not available until theniat: time of publicationjti: JWT ID to identify the JWT
In addition to the above default fields, we can also customize private fields as shown in the following example.
Note: By default JWT is unencrypted and anyone can decode its content, so do not construct sensitive information fields, such as storing confidential information, to prevent information leakage.
JSON objects are also saved as strings using the Base64URL algorithm.
Signature
The signature hash part is to sign the above two parts of the data and generate the hash value by the specified algorithm to ensure that the data will not be tampered with.
First, a key (secret) needs to be specified. This key is stored in the server only and cannot be disclosed to the client. Then, the signature is generated using the signature algorithm specified in the header (by default HMAC SHA256) according to the following formula.
|
|
After the signature hash is calculated. <Header>. <Payload>. <Signature> three parts using . to concatenate them into a string, which forms the entire JWT object.
Advantages
- Small size: one string, fast transmission speed
- Versatile transmission: can be transmitted via HTTP Header/URL/POST parameters, etc.
- Rigorous structuring: it contains all user-related authentication messages (in the payload section), such as user-accessible routes, access expiration dates, etc. The server does not need to connect to the database to verify the validity of the information, and the payload section supports application customization
- Cross-domain authentication support: mostly used for single sign-on
In fact, in addition to the above readily apparent advantages, JWT has the following advantages over traditional server-side authentication.
-
Full reliance on stateless API, in line with RESTful design principles
JWT is designed to fit the stateless principle: after a user logs in, the server returns a token and stores it locally, and all subsequent server accesses take this token with them to gain access to relevant routes, services and resources. For example, single sign-on uses JWT more often because it is small and can support cross-domain operations after a simple process (using the
Authorizationfield in the HTTP request header withAuthorization: Bearer <token>). -
easy to implement CDN, distributed management of static resources
In the traditional session/cookie authentication method, the server must save the SESSIONID, which is used to verify with the cookie passed by the user. In the beginning, the session is only saved on one server, so it can only be answered by one server, and even if other servers are available, they can’t answer, so the advantages of distributed servers can’t be fully utilized. JWT relies on the authentication information stored locally on the client, and does not need to use the information stored on the server to authenticate, so any server can answer, and the resources of the server can be better utilized.
-
Decoupled Authentication, Generate Anywhere
No need to use a specific authentication scheme, as long as you have the authentication information required to generate token, you can call the corresponding interface to generate token anywhere, without cumbersome coupling of authentication operations, so it can be said that once generated, always used.