ZooKeeper is a typical distributed data consistency solution dedicated to providing a high performance, highly available, distributed orchestration service with strict sequential access control. In the previous article Principles and Implementation of etcd, a Distributed Key-Value Store we learned about the implementation principles of the distributed orchestration service etcd key modules, in this article we take a look at the ZooKeeper implementation ideas.
ZooKeeper was created by Yahoo, an Internet company, and uses the Zab protocol, a consensus algorithm designed specifically for the service. Based on this protocol, ZooKeeper implements a master-slave model system architecture, which guarantees the consistency of data across replicas in a cluster. In the following, we will introduce the principle of ZooKeeper with Zab protocol as the center.
Zab Protocol
The full name of the Zab protocol is ZooKeeper Atomic Broadcast Protocol, and as you can see from the name, the Zab protocol is an atomic message broadcast protocol.
The Zab protocol borrows from the Paxos algorithm and has some similarities, but unlike Paxos, which is a general distributed consistency algorithm, it is an atomic broadcast protocol designed specifically for ZooKeeper to support crash recovery.
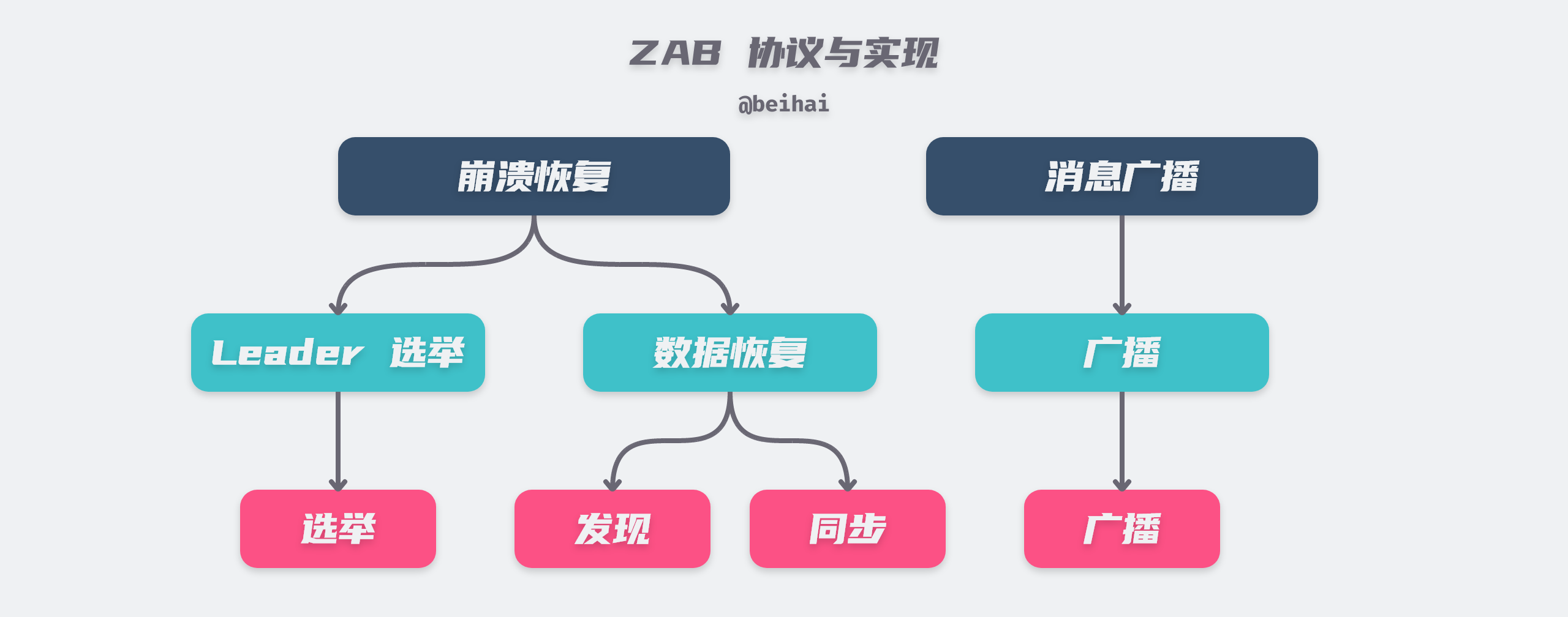
The principles of the ZooKeeper and Zab protocols are confusing. Broadly speaking, the principles of the Zab protocol can be subdivided into four phases:Leader Election, Discovery, Synchronization, and Broadcast. However, in the ZooKeeper implementation, the two parts of discovery and synchronization are combined into one part of data recovery, so it can be divided into three phases by implementation:Leader Election, Recovery Phase, and Broadcast Phase. According to the different functions, it can be divided into two basic modes: Message Broadcast and Crash Recovery. The message broadcast mode is used to handle client requests, and the crash recovery mode is used to quickly recover when a node unexpectedly crashes and continue to provide services to the public, allowing the cluster to reach a highly available state.
Node status
All write requests in ZooKeeper must be coordinated by a globally unique Leader server, and the ZooKeeper client will randomly connect to a node in the ZooKeeper cluster and read data directly from the current node if it is a read request, or forward the request to the Leader if it is a write request. After receiving the read/write transaction, the Leader will convert the transaction into a transaction proposal and broadcast the proposal to the cluster. As long as more than half of the nodes succeed in writing the data, the Leader will broadcast the Commit message to the cluster again and commit the proposal.
The current ZooKeeper cluster nodes may be in one of the following four states, which are as follows.
- LOOKING: entering the Leader election state.
- LEADING: a node becomes the Leader and is responsible for coordinating transactions.
- FOLLOWING: the current node is the Follower, obeys the orders of the Leader node and participates in the consensus.
- OBSERVING: Observer node is a read-only node, used to increase the read-only transaction performance of the cluster, not involved in consensus and election.
Observer nodes are server states added to the ZooKeeper implementation, independent of the Zab protocol.
The Zab cluster uses Epoch to represent the current cycle of the cluster. Each Leader is like a leader with its own term value, so each time the Leader changes, 1 is added to the previous epoch.
Follower only listens to the commands of the Leader of the current epoch. After the old Leader crashes and recovers, it will switch to FOLLOWING state if it finds a larger epoch in the cluster.
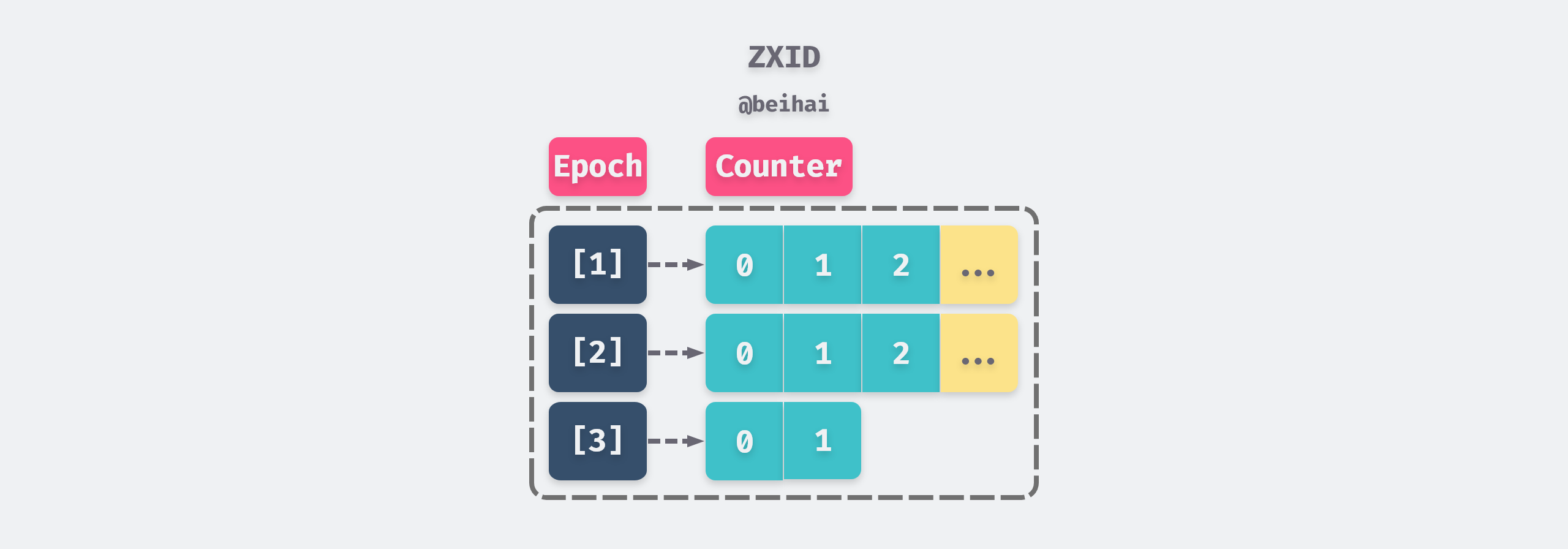
The Zab protocol uses ZXID to represent the global transaction number. ZXID is a 64-bit number, where the lower 32 bits are a monotonically increasing counter that is incremented by 1 for each transaction request from the client; the upper 32 bits represent the Epoch of the current Leader. Whenever a new master server is elected, the largest ZXID is retrieved from the cluster log, the Epoch value is read from it, and then 1 is added as the new Epoch, while the lower 32 bits are counted from 0.
In addition, each node in ZooKeeper has a unique ID myid, which is an integer between [1,255]. myid is not only used to identify the node identity, but also has a role in the Leader election process.
Message Broadcast
The message broadcast process of ZooKeeper is similar to two-phase commit, where the Leader generates a transaction proposal for a client’s read/write transaction request, assigns a ZXID to it, and then broadcasts the proposal to other nodes in the cluster. The Follower node receives the transaction proposal and writes it to the local disk as a transaction log. When the Leader receives the Ack response from more than half of the Follower nodes, it replies to the client that the write operation was successful and sends a Commit message to the cluster to commit the transaction.
When the Follower server receives the Commit message, it completes the commit of the transaction and applies the data to the data copy.
During the message broadcasting process, the Leader server maintains a message queue for each Follower, then puts the proposals to be broadcasted into the queue in turn and sends the messages one by one according to the “first-in-first-out” rule. Since a write operation is considered successful if more than half of the nodes respond, a few slow nodes will not affect the performance of the whole cluster.
Crash Recovery
The Zab protocol supports crash recovery, i.e., when the Leader node crashes and the Follower cannot connect to the Leader, the Follower switches to the LOOKING state and initiates a new round of election. In addition, if the Leader node cannot communicate properly with more than half of the servers, the Leader node will also actively switch to the LOOKING state, giving up the leadership to the node with a better network environment.
In order to maintain data consistency in the cluster, the Zab protocol needs to guarantee the following two characteristics during crash recovery.
- The Zab protocol needs to ensure that transactions that have been committed (Commit) on the Leader server are eventually committed by all servers..
- The Zab protocol needs to ensure that transactions that are only raised on the Leader but are not committed are discarded.
The first feature is that, since the Zab protocol requires that as soon as more than half of the nodes write data and respond, the Leader will reply to the client that the write operation was successful, and if the Leader node crashes, only a few Follower nodes may have received the Commit message. For example, in the figure below, only Follower2 node received the Commit message, so during the election process, Follower2 node needs to be successfully elected as Leader and synchronize its data to other nodes in the cluster.
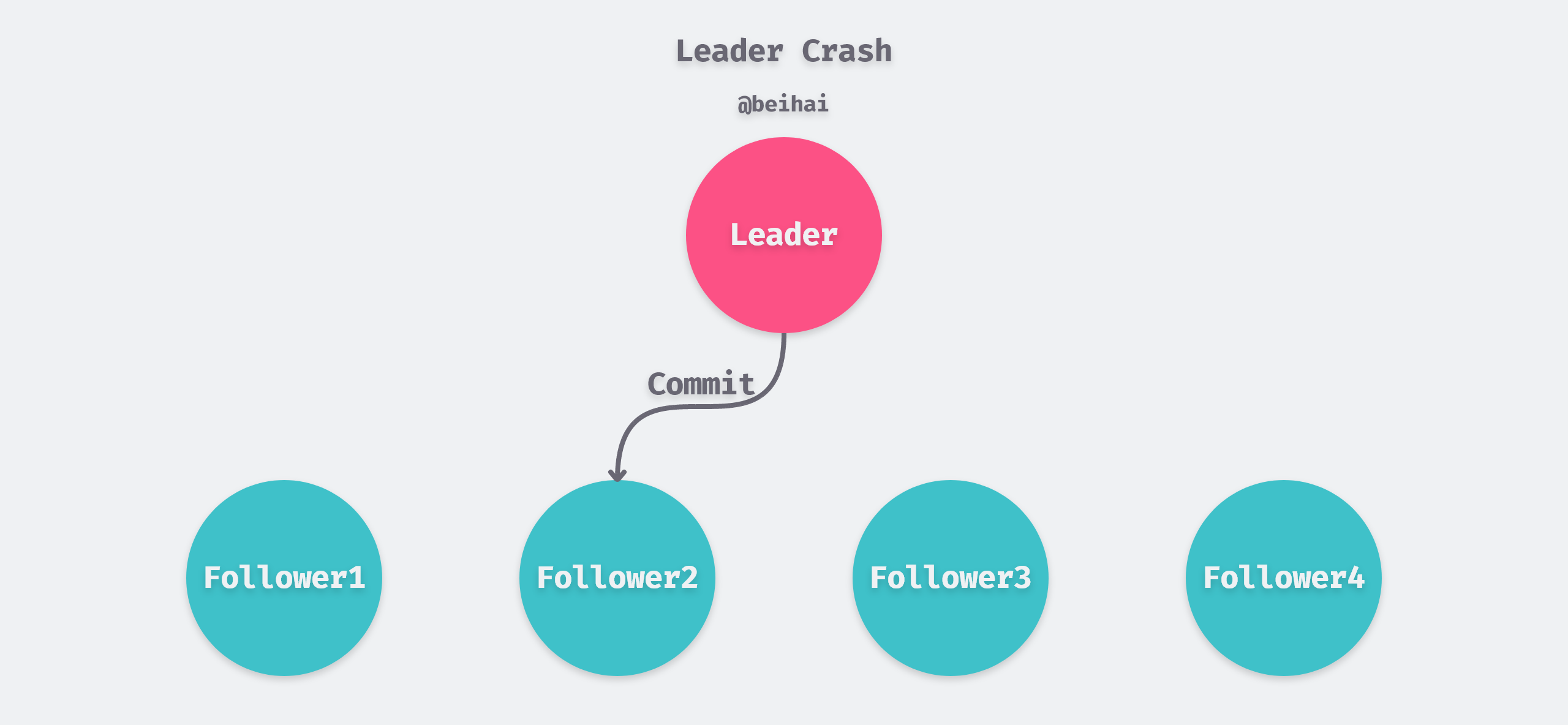
The situation where the second characteristic arises is more complicated. The Leader node may crash while waiting for an Ack response from half of the Follower, or it may crash before sending a Commit message, or it may even crash during the process of broadcasting a transaction proposal. But in either case, it is certain that none of the Follower’s in the cluster will commit the data. So when a new Leader is created, it discards the transactions that were recorded in the transaction log but not committed.
From the client’s point of view, since the Leader has not committed the transaction yet, it does not receive a successful response from the master node for the write operation, and the transaction fails.
In the ZooKeeper implementation, crash recovery requires two phases: Leader election and data recovery.
Leader Election
When a cluster conducts a Leader election, all servers in the cluster are in the LOOKING state and each node sends a poll message to all other machines. The voting message contains the following key fields.
|
|
At the first vote, each server makes itself the subject of the vote and broadcasts the vote message to the cluster. In order to achieve the first feature, the Zab protocol needs to ensure that the server with the most recent data is elected Leader, so each machine processes the votes received from other nodes according to the following rules and decides whether it needs to change its vote.
- compare itself with the Epoch of the elected person in the voting message and choose the greater of the two as the new election server, if equal go to the second step of comparison.
- compare itself with the ZXID of the electee in the voting message and select the greater of the two as the new election server, and if equal go to the third step of comparison.
- compare itself with the myid of the elected person in the voting message and choose the greater of the two as the new election server.
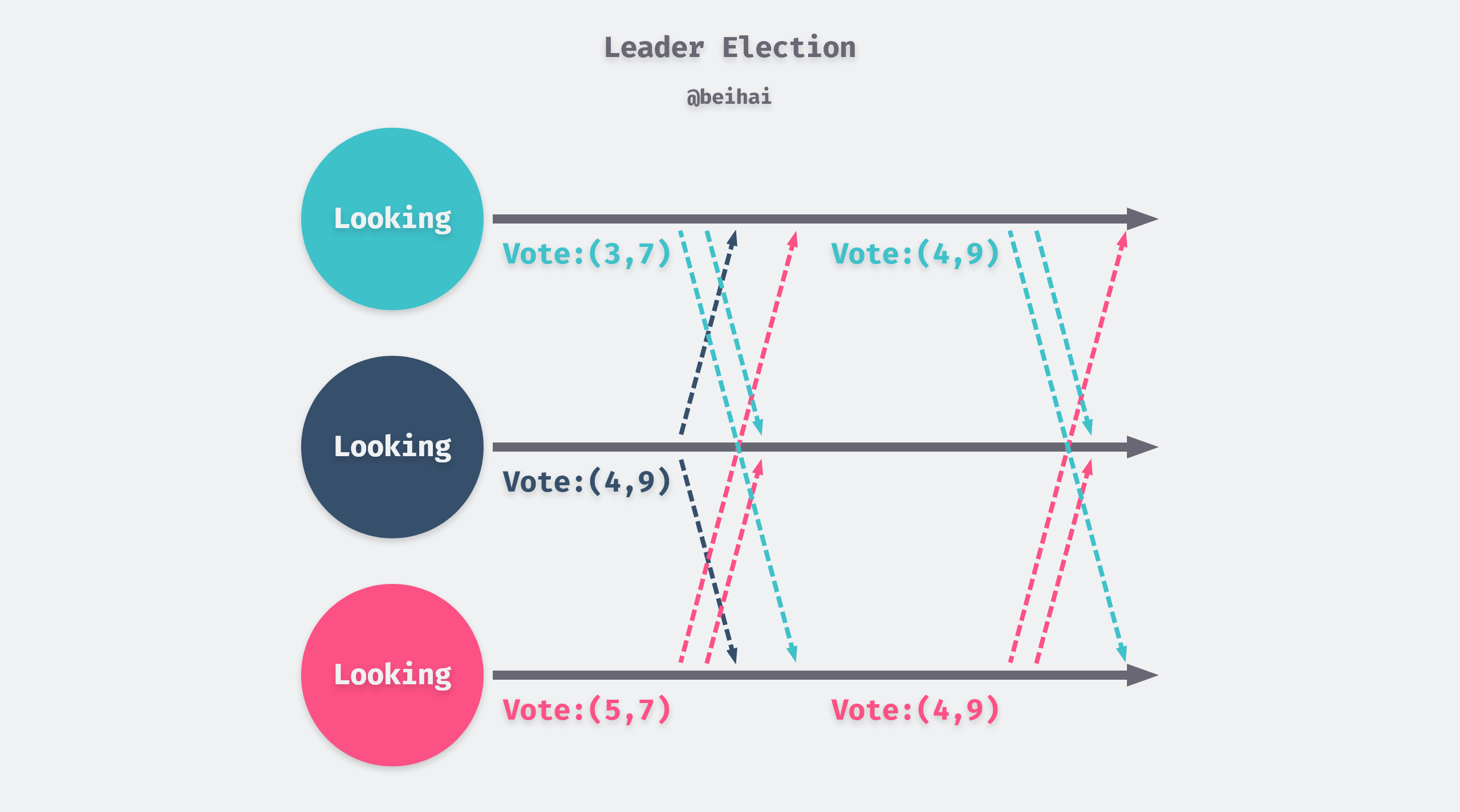
In the above figure, there are three nodes with myid 3, 4, and 5 in the cluster, because node 4 has a larger ZXID of 9, so nodes 3 and 5 have changed their recommended servers. If the server’s recommended node changes, it will broadcast a new voting message to the cluster, and once a node has more than half of the votes, it will switch to the leader.
data recovery
The data recovery phase needs to go through a discovery process first: the elected Leader will establish a long connection with the Follower node, and each Follower will send a FOLLOWERINFO message to the Leader, which contains the current peerEpoch value of the Follower node, from which the Leader will select the largest The Leader selects the largest peerEpoch and adds 1 to the new peerEpoch. The Leader then broadcasts this new Epoch value to the cluster, and the discovery process is designed to bring the cluster into a unified epoch that obeys the Leader’s leadership position.
After the discovery process, the cluster will enter the synchronization process, and Follower will send lastCommittedZxid to Leader, which represents the ID of the last committed transaction of the Follower node. The Leader sends a missing transaction proposal to the Follower based on this value, so that all data replicas in the cluster agree on the state. There is a slight difference between the theory and the implementation of the synchronization protocol, in which Follower only receives proposals larger than its own lastCommittedZxid; however, in the implementation, if the Leader’s lastZxid is smaller than the lastCommittedZxid, then it sends the Follower the TRUNC instruction to the Follower to truncate the later proposals.
After the data recovery phase is complete, the Zookeeper cluster can officially provide transaction services to the public, which means that it enters the message broadcast phase above.
Sequential Consistent Reads
As mentioned in the Linear Consistent Reads section of the previous article, etcd implements linear consistent reads using the ReadIndex mechanism, but because the Zab protocol uses a half-write policy, read operations can only achieve sequential consistency. All processes in the sequential consistency model see all changes in the same order, and reads from other processes may not get the latest data, but the order in which each process reads the different values of that data is the same.
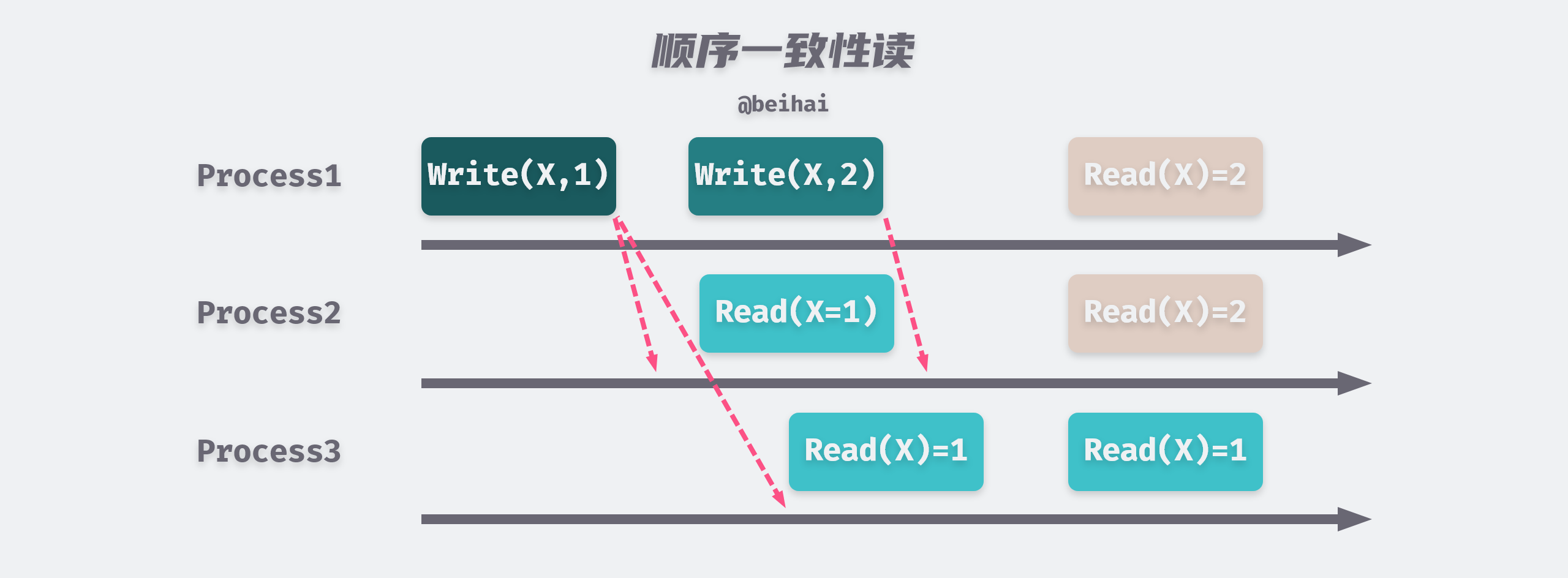
To prevent Follower’s data from becoming obsolete, ZooKeeper provides the sync() method to ensure that the latest data is read. After calling sync(), a virtual write operation is initiated, but no data is written. Since the order is consistent, when the virtual write operation is completed, all the correct data before the sync() time point is guaranteed to be read.
Zab and Raft
After understanding the principle and implementation of the Zab protocol, we can see that the Zab and Raft protocols actually have a lot of similarities in terms of implementation, such as
- both have a unique master node Leader, which sends proposals to all slave nodes.
- Each proposal in the ab protocol contains an Epoch value, called term in Raft.
- Use a two-stage commit with a half-write policy, i.e., commit the current proposal as soon as more than 50% of the nodes have confirmed it.
Both consensus algorithms, Zab and Raft, need to guarantee transactional data consistency between master and slave nodes, where any data replica in the cluster executes the same order of commands as requested by the client, i.e., given a sequence of requests, the data replicas always perform the same internal state transitions and produce the same responses, even if the replicas are received in a different order. During the operation of the cluster, if the primary node goes down due to an error, the other nodes restart the election.
Data and Storage
ZooKeeper’s data storage is divided into two parts: disk persistent storage and in-memory data storage. To guarantee high performance, ZooKeeper stores data in memory and persists it to disk through transaction logs and snapshots.
Disk data
The transaction log of ZooKeeper is also essentially a pre-written log (WAL), and the transaction log records every data change operation of the client. Each transaction log has a file size of 64MB and uses the ZXID of the first record of the transaction log file as the file name suffix. In order to improve the write I/O efficiency of the disk, the transaction log file of ZooKeeper adopts the “disk space preallocation” policy, that is, it requests 64MB of disk space from the operating system at the beginning of file creation, and will be preallocated again when the remaining space of the file is less than 4KB.
ZooKeeper also generates snapshot files to back up the entire in-memory data, but the ZooKeeper snapshot is not a snapshot file of the exact moment, but the state of the node’s data during the time period when the snapshot is generated.
ZooKeeper uses asynchronous threads to generate snapshots, and since multiple threads share the same memory space, it is possible that any changes to data during snapshot generation will be recorded in the snapshot.
In order to minimize the impact on overall performance if all nodes in a ZooKeeper cluster start generating snapshots at the same time, ZooKeeper uses the “over half random” policy to determine the snapshot generation after snapCount transactions: if the default value of snapCount is 10,000, then each node will generate a random value between 5,000 and 10,000, and will automatically generate snapshots independently after exceeding that value.
In-memory data
The in-memory data model of ZooKeeper is a tree, where each data node is called a ZNode, and we can write data to the ZNode and create child nodes. All ZNodes are organized in a hierarchical structure to form a DataTree, whose node paths are split using the slash /.
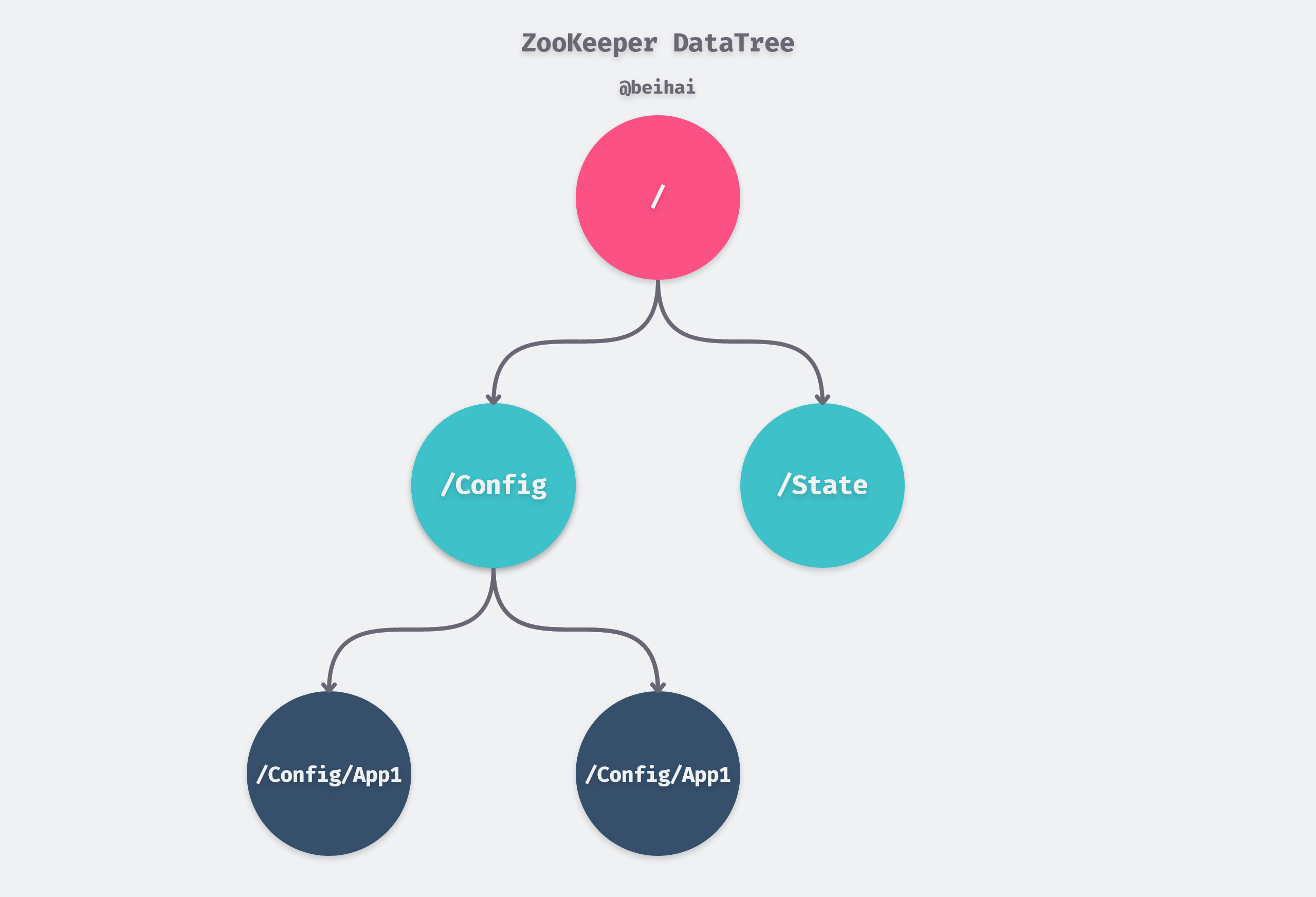
The DataTree maintains the data for the entire tree through a hash table called nodes, defined as follows.
|
|
NodeHashMap is a hash table implemented by ZooKeeper itself, and all the data in DataTree is stored in this hash table. The key of this hash table is a string type node path name, the value is a DataNode object, and each DataNode represents the data and state of a node path.
The DataNode definition contains a data field for storing data, where the values of the key-value pairs sent by the client are stored. the DataNode also maintains a list of child nodes, children, which establishes the parent-child node correspondence through children.
|
|
In fact, the whole DataTree is a huge dictionary, which is a parallel data structure in physical storage but provides a logical view of the tree to the outside world by establishing parent-child correspondence between data nodes.
Versioning and concurrency control
ZooKeeper introduces the concept of version numbers for data nodes, and each data node has three types of versioning information.
- version: the version number of the data content of the current data node.
- cversion: the version number of the current data node’s child nodes.
- aversion: the version number of the ACL (Access Control List) permission of the current data node.
where version is the number of times the current node is modified, even if the data content does not change before and after the modification, version will still +1; cversion indicates the number of times the child node list information is changed, it will be self-incremented when adding and deleting word nodes, but will not sense the change of child node data content.
ZooKeeper uses optimistic locking CAS (Compare And Switch) for concurrency control, during processing read and write requests, it will get the version expectedVersion of the current request and the version currentVersion in the data node in the server. If the total expectedVersion of the request is -1, it means that the client does not require the optimistic lock and can write the data directly, otherwise the two version numbers are compared and if they are the same, they are written to the data node after incrementing the value.
|
|
Sessions
Session is one of the important concepts in ZooKeeper, where the client is configured with a list of ensemble servers. When the client starts, it tries to establish a long connection with one of the servers. If the connection attempt fails, then it will continue to try to connect to the next server until the connection succeeds or the connection attempt fails altogether.
A Session is created by the client during the process of establishing a network connection. The Session starts in the CONNECTING state and switches to the CONNECTED state when the client connects to one of the servers in the ZooKeeper cluster. During normal operation, the Session will be in one of these two states. If a non-recoverable error occurs, such as a session expiration or authentication failure, or if the application closes the session connection, the Session will switch to the CLOSED state.
Each session contains four basic attributes: a unique ID for the session (sessionID), a session timeout (TimeOut), the next timeout point for the session (TickTime), and a token indicating whether the session has been closed (isClosing).
The session expiration time is set by the client application that created the session. If the server does not receive any message from the client within this time period, the session will be considered expired and the temporary data nodes created during this session will be deleted and the session cannot be recreated, and a new instance will need to be created if the connection is to be re-established.
Zookeeper uses session manager SessionTracker to create, manage and clean up all sessions. It adopts a “bucketing policy” to manage sessions, and SessionTracker assigns sessions to different blocks according to their next timeout point, so that sessions in different blocks can be segregated and sessions in a unified block can be handled uniformly.
The next timeout point for a session can be roughly thought of as equal to the current time plus the session timeout time, but in reality it is slightly different.
Summary
This article does not cover the implementation details of ZooKeeper in detail, but mainly analyzes how the Zab protocol is used to build a highly available primary backup system. In fact, both Zab and Raft sacrifice transient availability to ensure consistency once node partitioning occurs, which satisfies the CP property in CAP theory, but ensures both high availability and consistency when no partitioning occurs.
Therefore, the commonly accepted CAP of two out of three does not mean that the system maintains CP or AP all the time, but it is a process that changes: all conditions are satisfied during normal operation, and when partitioning occurs, it is necessary to make a trade-off between C and A.