We have always believed that coroutines are a more efficient way to work concurrently than multithreading, and that they are completely controlled by the program itself, i.e., executed in the user state. coroutines avoid the context switching that occurs with thread switching, resulting in significant performance gains.
But in fact, coroutines are much more complex than most people think. Because of their “user state” nature, task scheduling is in the hands of the person who wrote the coroutine task. Relying only on the async and await keywords is far from the level of “scheduling”, and sometimes it will drag down the efficiency of tasks, making it less efficient than the “system state” multi-threaded and multi-process. Let’s explore the scheduling management of Python3’s native coroutine tasks.
Python 3.10 basic operations of async.io
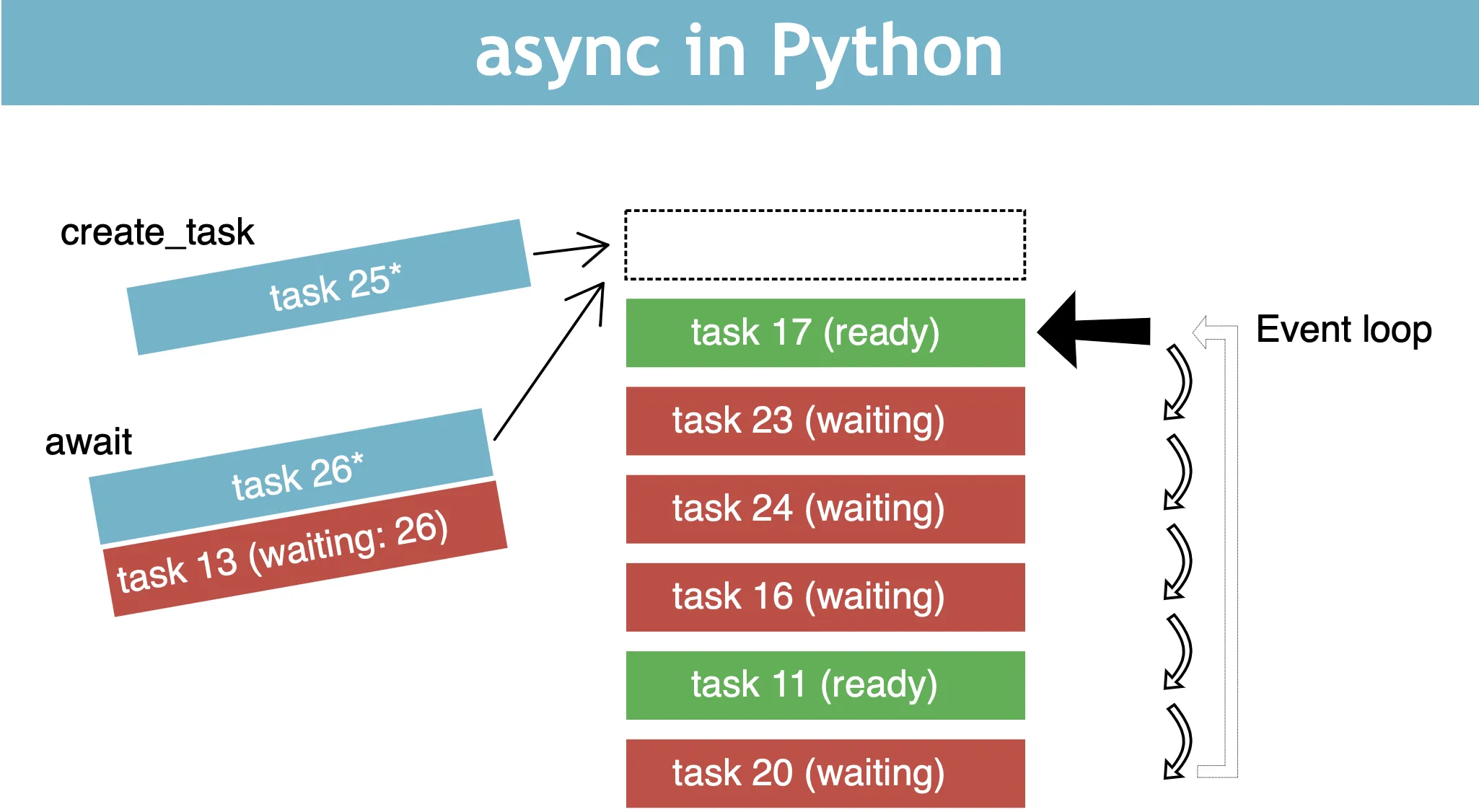
Eventloop is the core of the native coroutine library asyncio and can be understood as the commander-in-chief. eventloop instances provide methods to register, cancel and execute tasks and callbacks.
Eventloop can bind some asynchronous methods to the event loop, which will loop through them, but like multithreading, only one method can be executed at the same time, because coroutine is also executed single-threaded. When a method is executed, if it encounters blocking, the event loop will pause its execution to execute other methods, and at the same time register a callback event for the method, so that when a method recovers from blocking, it will continue to execute the next time it is polled, or, if it is not polled, it will recover from blocking early and can be switched by the callback event, and so on. This is the simple logic of the event loop.
And the most core action above is to switch to another method, how to switch? With the await keyword.
The results of the run are as follows.
In fact, the two coroutine tasks do not “collaborate” because they are executed synchronously, so it is not possible to achieve the way the coroutine works by waiting inside the method, we need to start the two coroutine tasks concurrently.
|
|
The results of the run are as follows.
Without the involvement of asyncio.gather, coroutine methods are just plain old synchronous methods. Even if asynchronous is declared via async, it doesn’t help. The basic function of asyncio.gather is to concurrently execute coroutine tasks to achieve “collaboration”.
But in fact, Python 3.10 also supports these kinds of coroutine methods that are written like synchronous methods.
Here we encapsulate job1 and job2 through asyncio.create_task, and the returned object is then called through await, so that the two separate asynchronous methods are bound to the same Eventloop, which looks like a synchronous method, but is actually executed asynchronously.
|
|
The results are as follows.
coroutine task results
Having solved the problem of concurrent execution, now assume that each asynchronous task returns an operation result.
The asyncio.gather method allows us to collect the results of task execution.
Running tasks concurrently.
|
|
The results are as follows.
But the result of the task is just the return value of the method, and there is no other valuable information beyond that, and the details of the execution of the coroutine task are not known.
Now let’s switch to asyncio.wait method.
Still concurrently executed.
|
|
The results are as follows.
|
|
As you can see, asyncio.wait returns the task object, which stores most of the task information, including the execution status.
By default, asyncio.wait waits for all tasks to complete (return_when=‘ALL_COMPLETED’), and it also supports return_when='FIRST_COMPLETED' (return on first coroutine completion) and return_when='FIRST_ EXCEPTION' (return when the first exception occurs).
This is very exciting, because if the asynchronous consumption task is a task that needs to count the reach rate like sending an SMS, using the asyncio.wait feature, we can record the task completion time or the exact time of the exception in the first place.
coroutine task guarding
Suppose for some reason we manually terminate the coroutine.
|
|
Exception:
Here job1 is cancelled manually, but it affects the execution of job2, which is against the coroutine’s characteristics.
In fact, the asyncio.gather method can catch exceptions of coroutine tasks.
|
|
The results are as follows.
You can see that job1 is not executed and the exception replaces the task result as the return value.
However, if the coroutine task is started, you need to ensure that the task will not be cancelled in any case, you can use the asyncio.shield method to guard the coroutine task at this time.
|
|
coroutine task callback
Suppose that after a coroutine task is executed, a callback operation needs to be performed immediately, such as pushing the task result to other interface services.
|
|
Here we specify the callback method for job1 via the add_done_callback method, and the callback will be called when the task is finished executing.
The result is as follows.
Meanwhile, the add_done_callback method not only gets the coroutine task return value, it also supports parameter argument passing itself.
|
|
The result is as follows.
Summary
The scheduling of coroutine tasks is far more complex than the system-level scheduling of multithreads, which can cause business “synchronization” blocking if you are not careful, making it counterproductive. This explains why the appearance rate of multithreading is much higher than coroutine in similar scenarios, because multithreading does not need to consider the “switching” problem after startup.