A file system is a mechanism for organizing data and metadata on a storage device, and with such a broad definition, implementations vary greatly from file system to file system, including ext4, NFS, /proc, etc. Linux uses a layered architecture that separates the user interface layer, the file system implementation, and the drivers for the storage device, and is thus compatible with different file systems.
The Virtual File System (VFS) is a software layer in the Linux kernel that provides a standard, abstract set of file operations in the kernel, allows different file systems to coexist, and provides a unified file system interface to user space programs. The following diagram illustrates the overall structure of the Linux virtual file system.
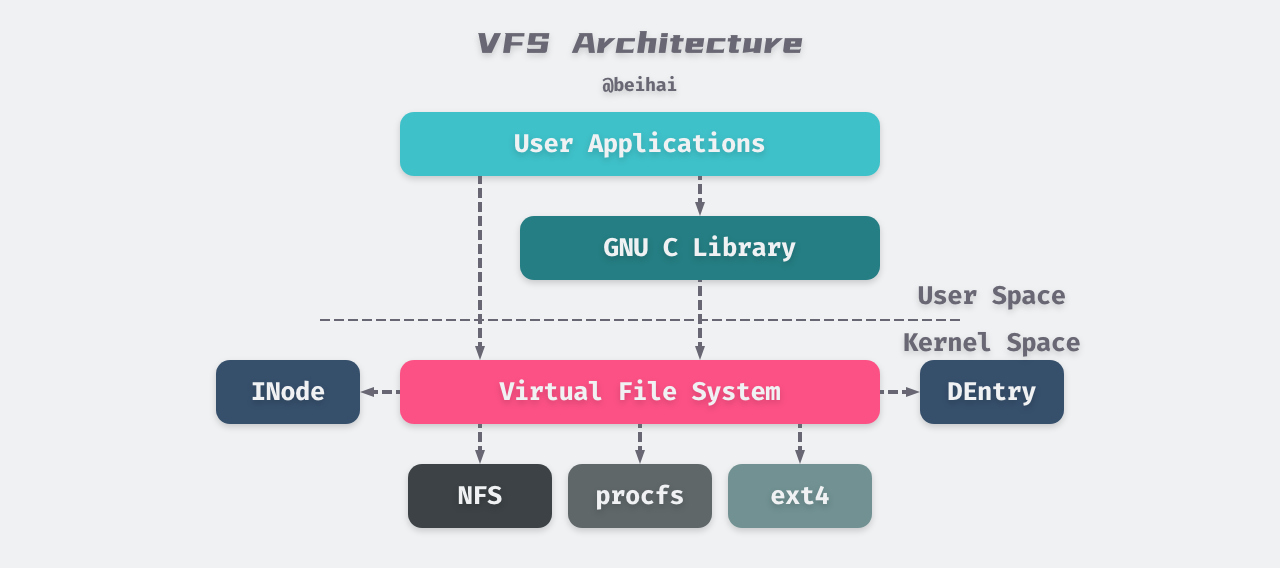
As you can see from the above diagram, user-space applications perform file operations either directly or indirectly through library functions provided by the programming language. User-space applications perform file operations either directly or indirectly by calling the System Call interface provided by the kernel (e.g. open(), write(), etc.) through library functions provided by the programming language.
The System Call interface then passes the application’s parameters to the virtual file system for processing.
Each file system implements a set of common interfaces for VFS, and specific file systems manipulate the data on disk according to their own organization of the data. When an application operates on a file, VFS finds the corresponding mount point based on the file path, gets the specific file system information, and then calls the corresponding operation function for that file system.
VFS provides two caches for file system objects, INode Cache and DEntry Cache, which cache recently used file system objects and are used to speed up accesses to INode and DEntry. The Linux kernel also provides Buffer Cache buffers to cache requests between the file system and associated block devices, reducing the number of accesses to physical devices and speeding up accesses. The Buffer Cache manages buffers in the form of LRU lists.
The benefit of VFS is that it decouples the application’s file operations from the specific file system, making it easier to program.
- Application-level programs can perform file operations simply by using the
read(),write(), and other interfaces provided externally by VFS, without caring about the details of the underlying file system implementation. - The file system only needs to implement the VFS interface to be compatible with Linux, making it easy to port and maintain.
- File operations across file systems are implemented without concern for specific implementation details.
After understanding the overall structure of the Linux file system, the following is an analysis of the technical principles of Linux VFS. Since the implementation of the file system and device drivers is very complex, and I have not been exposed to this area, I will not cover the implementation of specific file systems in this article.
VFS Structure
Linux views all file systems in terms of a set of generic objects, and the relationship between objects at each level is shown in the diagram below.
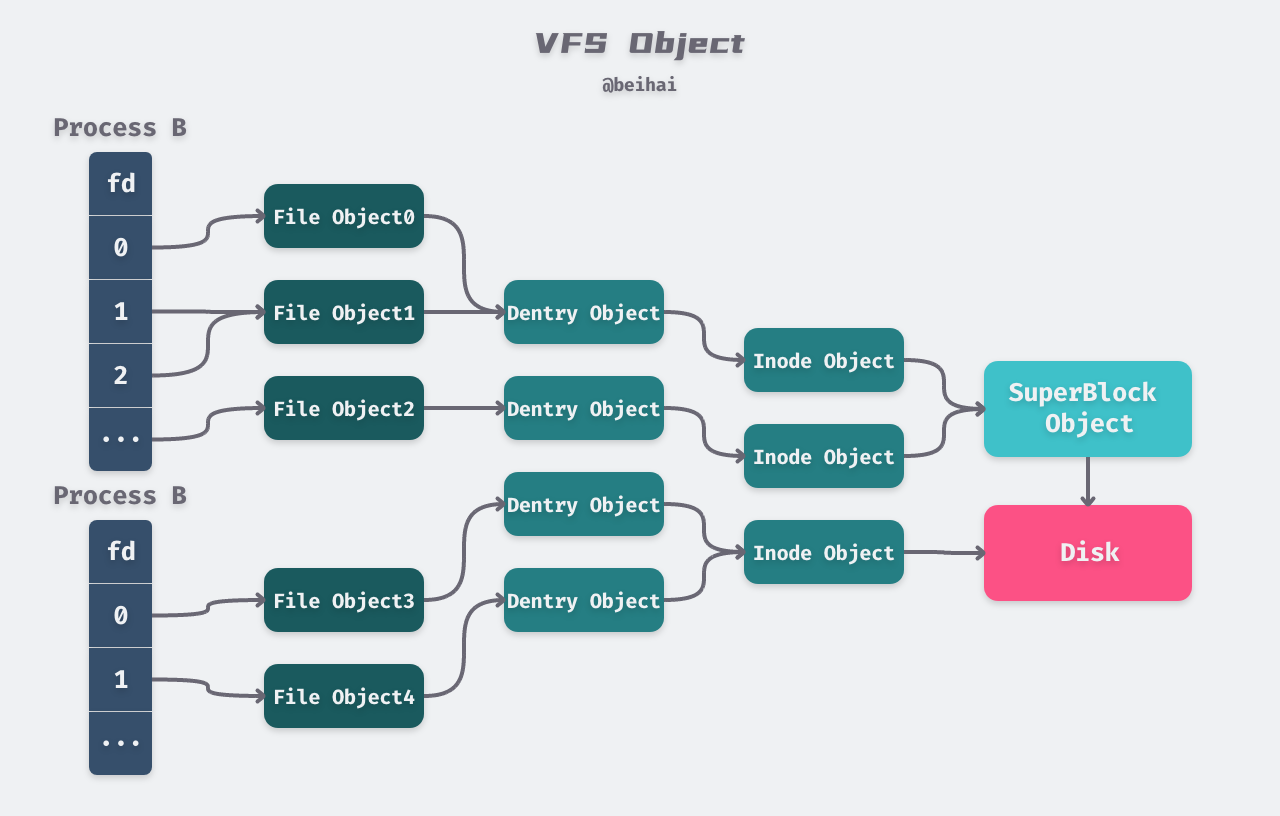
fd and file
each process holds an fd[] array, which holds a pointer to a file structure; different fds of the same process can point to the same file object.
file is a data structure in the kernel that represents a file that is opened by a process and associated with the process. When an application calls the open() function, VFS creates the corresponding file object. It holds the status of the opened file, such as file permissions, paths, offsets, etc.
|
|
As you can see from the above code, the path to the file is actually a pointer to the DEntry structure, and VFS indexes to the location of the file via DEntry.
Except for the file offset f_pos, which is private to the process, all other data comes from INode and DEntry and is shared with all processes. The file objects of different processes can point to the same DEntry and Inode, thus enabling file sharing.
DEntry and INode
The Linux file system assigns two data structures to each file, a Directory Entry (DEntry) and an Index Node (INode).
DEntry is used to hold the mapping between file paths and INode, thus supporting movement within the file system. DEntry is maintained by VFS, shared by all file systems, and is not associated with a specific process. The dentry objects start at the root directory “/” and each dentry object holds its own subdirectories and files, thus forming a file tree. For example, if you want to access the file “/home/beihai/a.txt” and operate on it, the system will resolve the file path, starting with the dentry object in the root directory “/”, then finding the directory “home/”, followed by “beihai/”, and finally find the dentry structure of “a.txt”, the d_inode field inside the structure corresponds to the file.
|
|
Each dentry object holds a corresponding inode object, representing a specific directory entry or file in Linux.INode contains all the metadata needed to manage objects in the file system, as well as the operations that can be performed on that file object.
|
|
The virtual file system maintains a DEntry Cache, which is used to store the most recently used DEntry and speed up query operations. When the open() function is called to open a file, the kernel will first look for the corresponding DEntry in the DEntry Cache based on the file path, and if it finds it, it will directly construct a file object and return it. If the file is not in the cache, then VFS will load it down one level according to the nearest directory found until it finds the corresponding file. During this time VFS caches all the dentrys generated by the load.
The data stored in an INode is stored on disk and organized by a specific file system. when an INode needs to be accessed, the file system loads the corresponding data from disk and constructs an INode. an INode may be associated with more than one DEntry, i.e. it is equivalent to creating multiple file paths for a particular file (usually by creating hard links to the files).
SuperBlock
A SuperBlock represents a specific loaded file system and is used to describe and maintain the state of the file system, defined by VFS, but populated with data based on the specific file system. Each SuperBlock represents a specific disk partition and contains information about the current disk partition, such as file system type, space remaining, etc. An important member of the SuperBlock is the chain s_list, which contains all modified INodes, using which it is easy to distinguish which files have been modified and to write the data back to the disk with the kernel thread. Another important member of SuperBlock is s_op, which defines all operations on its INode, such as marking, releasing index nodes, etc.
|
|
A SuperBlock is a very complex structure that allows us to mount a physical file system on Linux or to add, delete, or check an INode. That’s why file systems usually store multiple copies of SuperBlock on the disk to prevent accidental data corruption that could make the whole partition unreadable.
Applications
procfs
The /proc directory is a virtual file system provided by Linux that stores a series of special files on the current state of the kernel. The user can use these files to check information about the system hardware and the currently running processes, and can even change the running state of the kernel by changing some of these files.
/proc is not a real file system, it does not take up storage space, only a limited amount of memory. However, /proc implements an interface to the virtual filesystem, allowing us to manipulate the contents of the /proc directory as if it were a normal file.
For more information about the usage of /proc, please refer to the document proc(5) - Linux manual page, in the Linux system similar to procfs There are also sysfs, tmpfs and other pseudo-file systems similar to procfs in Linux.
An important concept of Linux is that “everything is a file”, from here we can see that whether it is an ordinary file, a special directory, a device, etc., as long as the relevant interface is implemented, VFS can treat them as files equally and operate on them by the same set of file operations. When we open a file, VFS gets the file system format corresponding to that file, and when VFS passes control to the actual file system, the actual file system then makes specific distinctions and performs different operations on different file types.
Summary
The virtual file system is a very important layer of abstraction in the operating system.Its main role is to allow the upper layer of software, in a unified way, to communicate with the different file systems at the bottom. Between the operating system and the underlying file systems, the virtual file system provides a standard operating interface that allows the operating system to quickly support new file systems. It is also because of VFS support that many different actual file systems can coexist in Linux and cross file system operations can be implemented.