
One of the most important problems that Linkerd Service Mesh solves is observability: providing a detailed view of service behavior, Linkerd’s value proposition for observability is that it can provide golden metrics for your HTTP and gRPC services that are executed automatically, without code changes or developer involvement.
Out of the box, Linkerd provides these metrics on a per-service basis: all requests across services, regardless of what those requests are. However, sometimes it is necessary to get more granular metrics. For example, for the Emoji microservice in the Emojivoto application earlier, the metrics reported by Linkerd as seen in the previous section are aggregated across all endpoints of that service. Under real-world scenarios, we may also want to see the success rate or latency of specific endpoints, for example, one endpoint may be particularly critical to the service, or particularly slow.
To solve this problem, Linkerd uses the concept of a service profile, which is an optional configuration that informs Linkerd about the different types of requests for a service, categorized by their routes. A route is simply an endpoint (for gRPC) or an HTTP verb and endpoint (for HTTP).
Service profiles allow Linkerd to provide per-route (pre-route) for services instead of per-service metrics, and in later sections we will also see that service profiles allow Linkerd to perform configurations such as retries and timeouts on services, but for now let’s just focus on metrics.
It is also important to note that service profiles are not simply required for a service to run with Linkerd, they are optional configuration bits that enable more advanced behavior of Linkerd, and they are one of the few examples of Linkerd using Kubernetes CRD. Next we will still illustrate the use of service profiles with the Emojivoto application.
Generating a service profile
Linkerd’s service profile is implemented by instantiating a Kubernetes CRD named ServiceProfile. The ServiceProfile will enumerate the routes that Linkerd expects for that service.
We can create ServiceProfiles manually, but they can also be generated automatically. the Linkerd CLI has a profile command that can generate service profiles in a few different ways. One of the most common ways is to generate them from the service’s existing resources, such as the OpenAPI/Swagger specification or protobuf files.
|
|
The above help command output lists the flags that can be used to generate YAML for a ServiceProfile resource, and you can see that one of them is the -open-api flag, which instructs the ServiceProfile resource to generate a service profile from the specified OpenAPI or Swagger document, and the --proto flag to indicate that the service profile will be generated from the specified Protobuf file.
The web service for Emojivoto has a simple Swagger specification file that reads as follows.
Now we can use the above specification file to generate a ServiceProfile object with the following command.
|
|
The above command will output the ServiceProfile resource manifest file for service web-svc. Note that just like the linkerd install command, the linkerd profile command only generates YAML, which does not apply YAML to the cluster, so we redirect the output to the web-sp.yaml file, which corresponds to the following generated file contents.
|
|
The resource manifest file above is a typical way of declaring a ServiceProfile object, spec.routes is used to declare all routing rules, each route contains a name and condition attribute.
nameis used to indicate the name of the route for display use.conditionis used to describe the specification of the route. Theconditiongenerated in the above example has two fields.method: the HTTP method that matches the request.pathRegex: the regular expression used to match the path. In our example, these are exact match rules, but usually these are regular expressions.
In addition to the service configuration files that can be generated via OpenAPI, they can also be generated via Protobuf. The gRPC protocol uses protobuf to encode and decode requests and responses, which means that each gRPC service also has a protobuf definition.
The Voting microservice for the Emojivoto application contains a protobuf definition, the contents of which are shown below.
|
|
Also now we can use the linkerd profile command to generate the corresponding ServiceProfile object.
|
|
The output of this command will be much more than the output of the previous command because the Voting.proto file defines more routes. We can look at the voting-sp.yaml file and compare it with the ServiceProfile resource created above.
There is also another way to dynamically generate ServiceProfile, where Linkerd can monitor live requests coming in during a specified time period and collect routing data from them. This is a very powerful feature for cluster administrators who are not aware of the internal routing provided by the service, as Linkerd takes care of processing the requests and writing them to a file, the underlying principle of this feature is the Tap feature for watching requests in real time mentioned in the previous section.
Now, let’s use the linkerd profile command to monitor the emoji service for 10 seconds and redirect the output to a file. As with all the commands we learned earlier, the output will be printed to the terminal and this command will redirect the output to a file, so we only have to run the command (and wait 10 seconds) once.
The Linkerd Viz extension also has its own profile subcommand that can be used in conjunction with the Tap function to generate service profiles from live traffic! As shown in the command below.
|
|
When requests are sent to the emoji service, these routes are collected via the Tap function. We can also use the Emoji.proto file to generate a service profile and then compare the definitions of the ServiceProfile resources created with the -proto and -tap flags.
The contents of the generated ServiceProfile resource manifest file are shown below.
|
|
If you need to write a service profile manually, the -linkerd profile command has a -template flag that generates a scaffold for the ServiceProfile resource, which can then be updated with your service’s details.
|
|
The above command will output the fields containing the ServiceProfile resources and a detailed description of each field, or if you need a quick reference to the ServiceProfile definition, you can use the --template flag!
At this point we understand how to generate the ServiceProfile resource manifest file, next let’s look at the metrics data for each route defined in the service profile.
View Per-Route Metrics in Linkerd Dashboard
Above we learned how to use the linkerd profile command to generate a ServiceProfile resource manifest file, now let’s rerun the generate command and apply the generated ServiceProfile object directly to the cluster.
|
|
Once the above command has run successfully, let’s open the Linkerd dashboard to see the metrics, and we’ll start by navigating to Web Deployment to see the metrics for each route.
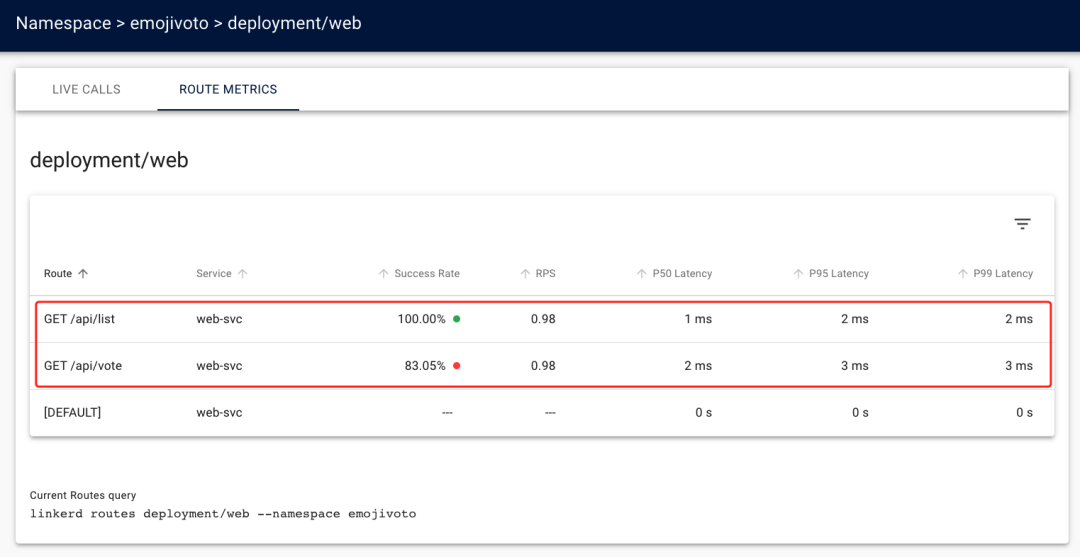
From the above figure, we can see that under the ROUTE METRICS tab there are two more routes than the default [DEFAULT] route, which are the two routes we generated from the web.swagger file with the linkerd profile --open-api command. Each metric data for both routes. Before deploying the ServiceProfile object, we could only see the aggregated metrics for the web service, after deployment we can now see that the /api/list route is 100% successful and the /api/vote route has some errors.
Again before the service profile we only knew that the web service was returning errors, now we have errors coming from the /api/vote route, and the additional [DEFAULT] default route indicates the route Linkerd uses when there is no route in the service profile to match the request, and it will catch any traffic observed before the ServiceProfile. any traffic observed before ServiceProfile.
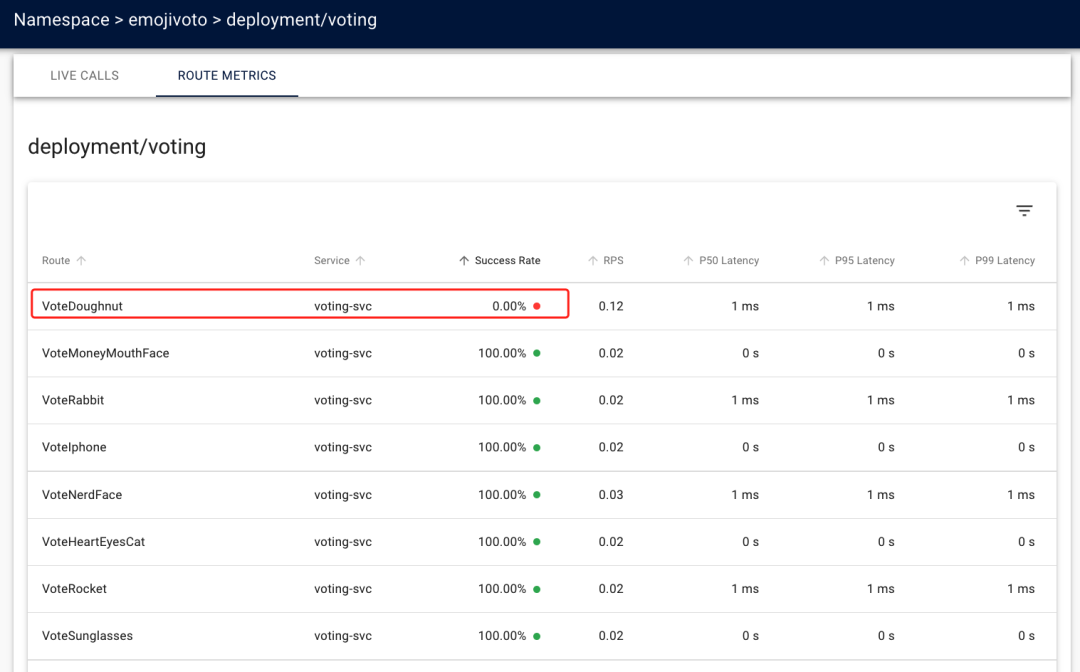
Now let’s go to the other service profile, where the Voting service is more representative because it contains a lot of routes. On the Linkerd Dashboard page go to Voting Deployment on the emojivoto namespace and switch to the ROUTE METRICS tab. We will have a very large number of routes under this service, the web service above we know that the /api/vote route has a success rate of less than 100%, each route information in all voting services may provide related error messages, since there are so many routes, we can directly sort them in ascending order by the Success Rate column, normally you can See that the VoteDoughnut route has a success rate of 0.
Viewing Per-Route Metrics via Linkerd CLI
We’ve already learned how to view per-route metrics for services in the Emojivoto application via the Dashboard, so let’s try using the CLI tool to view per-route metrics.
The linkerd viz routes command uses the same metrics as the Dashboard, so let’s take a look at using the Linkerd CLI to view the routes for the emoji service, as shown below.
|
|
We can see that both routes defined for the emoji service were successful and processed the request within 1ms, which shows that these routes are healthy. Note also our default route, marked as [DEFAULT], again this is the route Linkerd uses when there is no route in the service profile that matches the request.
Now we use the linkerd viz routes command in the same way to see the routes for the voting and web services, as follows.
|
|
The output of the voting service is long because it has many routes, so you can find VoteDoughnut routes with the grep command: linkerd viz routes deploy/voting -n emojivoto | grep VoteDoughnut (or you can use the -o json flag and tools like jq to parse the output).
At this point we’ve learned about Linkerd’s service profile functionality, and for now we’ll focus on the observability features of the service profile, where we can look at the golden metrics of each route we learned about earlier. Next we will dive further into ServiceProfile and explore Linkerd’s retry and timeout features.
Retries and Timeouts
Next, we’ll look at how to configure timeouts and retries using ServiceProfile. Linkerd can ensure reliability through traffic splitting, load balancing, retries and timeouts, each of which plays an important role in improving the overall reliability of the system.
But what kind of reliability do these features actually add? It comes down to the fact that Linkerd can help prevent transient failures. If the service shuts down completely, or always returns a failure, or always hangs, then no amount of retries or load balancing will help. But if an instance of the service goes down, or if the potential problem is only temporary, then that’s when Linkerd can come in handy, and these partial, temporary failures are the most frequent problems with distributed systems!
Here are two important things to understand when it comes to Linkerd’s core reliability features of load balancing, retries, and timeouts (traffic segmentation, also a reliability feature, but a little less so, which we’ll address in a later section).
- all of these techniques occur on the client side: the agent making the call is the agent performing these functions, not the server-side agent. If your server is on the grid, but your client is not, then these features will not be enabled in the calls between the two!
- These three features work best together. Without retries, timeouts are of little value; and without load balancing, retries are almost worthless.
We can start by understanding load balancing, Linkerd automatically load balances requests between possible destinations, note the word request - unlike quad or TCP load balancing, which balances connections, Linkerd will establish connections to the set of possible endpoints and balance requests between all these connections. This allows for more granular control of traffic and, in the background, Linkerd’s approach is very sophisticated, using techniques such as Exponentially Weighted Moving Average of Server Latency (EWMA) to optimize where requests go; pool connections across endpoints where possible; and automatically escalate HTTP/1.1 traffic to HTTP/2 connections between proxies. However, from our perspective, there is no configuration, just the knowledge that Linkerd automatically balances requests across its endpoints .
Next, look at timeouts, which are a way to set a maximum time on a route. Let’s say you have a route named getValue() on your service, and the performance of getValue() is unpredictable: most of the time getValue() will return within 10 milliseconds, but sometimes it takes 10 minutes to return, perhaps because of lock contention on some contested resource. If there is no timeout, calling getValue() will take anywhere between 10 milliseconds and 10 minutes, but if a timeout of 500 milliseconds is set, then getValue() will take up to 500 milliseconds.
Adding a timeout can be used as a mechanism to limit the system’s worst-case latency by allowing the caller of getValue() to have more predictable performance and not take up resources waiting for a 10-minute long call to return. Second, and more importantly, the timeout can be combined with retry and load balancing to automatically resend the request to a different instance of the service. If getValue() is slow on instance A, it may be fast on instance B or C, and even multiple retries will be far less than waiting 10 minutes.
So let’s look at retry, which is when Linkerd automatically retries a request. In what scenarios would this be useful? Again due to some temporary errors: if a specific route on a specific instance returns an error and simply retrying the request may result in a successful response, it is of course important to realize that simply retrying the request does not guarantee a successful response. If the underlying errors are not temporary, or if Linkerd is unable to retry, then the application will still need to handle them.
In practice, implementing retries can be cumbersome. There is also a risk that taking it for granted may add additional load to the system, a load that may make things worse. One common failure scenario is the retry storm: a transient failure in service A triggers retries by B on its requests; these retries cause A to overload, which means that B starts a failed request; this triggers retries by its caller C on B, which then causes B to overload, and so on. This is especially true for systems that allow you to configure the maximum number of retries per request: a maximum of 3 retries per request may not sound like a problem, but in the worst case it will increase the load by 300%.
Linkerd minimizes the possibility of retry storms by setting parameters for retries using a retry budget rather than a per-request limit. The retry budget is a percentage of the total number of requests that can be retried, and Linkerd’s default behavior is to allow 20% (200) retries for failed requests, plus an additional 10 requests per second. For example, if the original request load is 1000 requests per second, then Linkerd will allow 210 requests per second to be retried. When the budget is exhausted, Linkerd will not retry the request, but will return a 504 error to the client.
In summary: load balancing, retries, and timeouts are all designed to protect application reliability in the event of partial, temporary failures and to prevent those failures from escalating into global outages. But they are not a panacea, and we must still be able to handle errors in our applications.
Using Per-Route Metrics to Determine When to Retry and Timeout
We learned above about the reasons for using retries and timeouts in Linkerd, so let’s build on the observability features we learned about earlier and use metrics to make decisions about applying retries and timeouts.
First, we’ll look at the statistics of all Deployments in the emojivoto namespace, and then we’ll dive into unhealthy services. This is done directly using the linkerd viz stat command, as follows.
The stat command shows us the golden metrics, including success rate and latency, and we can notice that the success rate of the voting and web services is below 100%, and next we can use the linkerd viz edges command to understand the relationship between the services.
|
|
Of course, you can also use the Linkerd Dashboard to see the octopus diagram to understand the relationship between services.
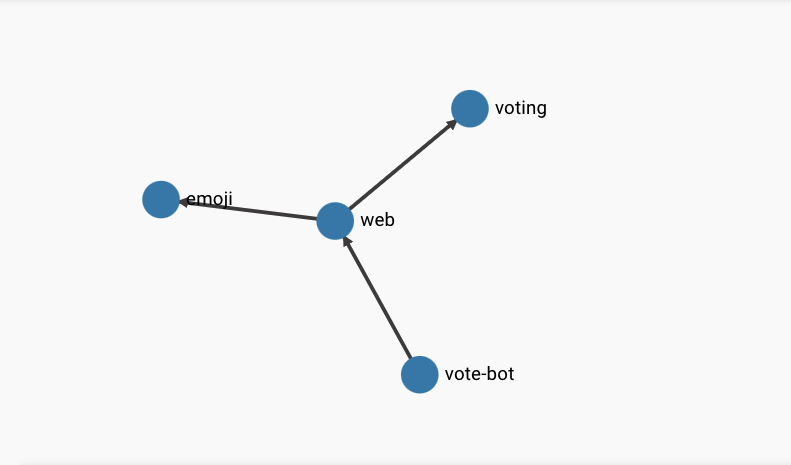
From the above results, we can see that the Pods in the web service are calling the Pods of the voting service, so we can guess that the voting service is causing the errors in the web service, but of course this is not the end of the story. We have metrics for each route and should be able to see exactly which routes have a success rate of less than 100%, so you can find out what the voting service’s route metrics are by using the linkerd viz routes command, as follows.
We can also view the ROUTE METRICS information for the voting service through the Linkerd Dashboard, as shown below.
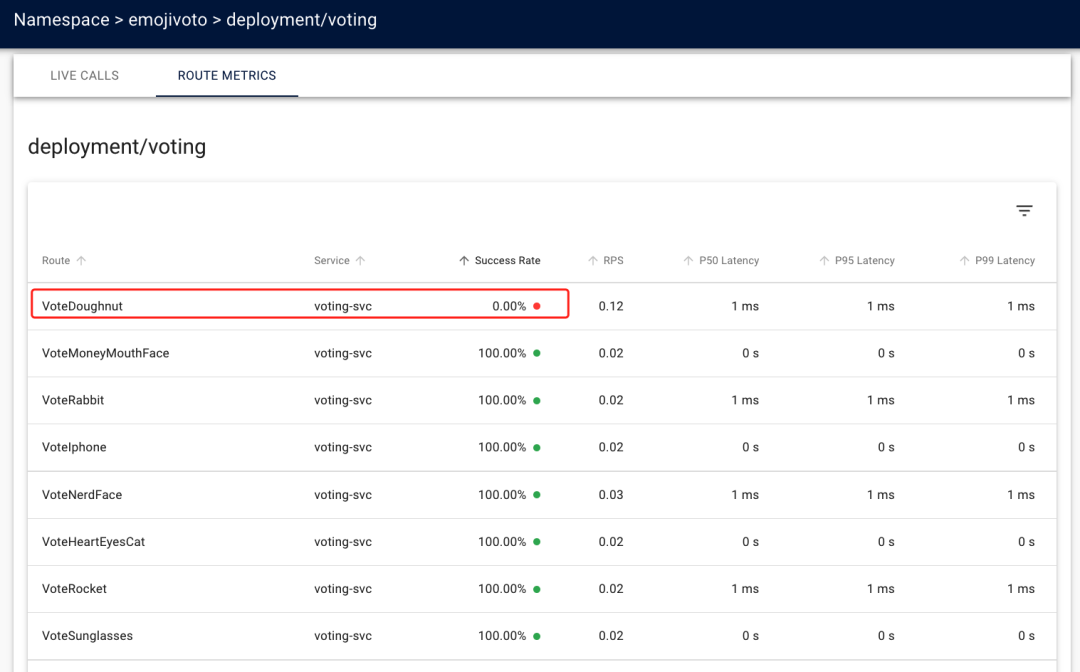
We can finally pinpoint VoteDoughnut as the route where the request failed. Now we not only know that an error occurred between the web service and the voting service, but we also know that an error occurred with the VoteDoughnut route. Next we can use retries to try to resolve the error and also ask the developer to debug the code.
Configuring Retries
Before we start configuring retries for VotingDoughnut routing, we must first take a closer look at the web and voting service metrics, as this will help us really understand if applying retries will solve the problem. Here we will only use the Linkerd CLI because it can show us the actual and valid request volume and success rates by using the -o wide flag. The Linkerd dashboard will show the overall success rate and RPS, but not the actual and valid metrics. The difference between actual and valid metrics is as follows.
- Actual values are from the perspective of the server receiving the request
- Valid values are from the point of view of the client sending the request
In the absence of retries and timeouts, obviously the two figures are the same. However, once retries or timeouts are configured, they may not be the same. For example, a retry can make the actual RPS higher than the valid RPS, because from the server’s perspective, the retry is another request, but from the client’s perspective, it is the same request. Retries can make the actual success rate lower than the effective success rate because the failed retry call also occurs on the server but is not exposed to the client. And a timeout may have the opposite effect: depending on the exact return time, a timeout request that eventually returns successfully may make the actual success rate higher than the valid success rate, because the server sees it as a success, while the client only sees a failure.
The overall point is that Linkerd’s actual and valid metrics may differ in the case of retries or timeouts, but the actual number represents the actual hit to the server, while the valid number represents that the client effectively got a response to its request after Linkerd’s reliability logic had done its job.
For example, we check the routing metrics of the vote-bot service with the following command.
|
|
In the above command we added a -o wide flag so that the output will contain both actual and valid success and RPS metrics. Looking at the vote-bot service, the effective success rate and actual success rate for the /api/vote route for the web service are both below 100%, because we do not have retries configured yet. And we can’t assume that all requests are retryable; retry requests are very specific to Linkerd.
-
Right now, requests using the HTTP POST method are not retryable in Linkerd. Because POST requests almost always contain data in the request
body, retrying the request means that the proxy must store that data in memory. Therefore, to keep memory usage to a minimum, the proxy does not store POST requestbodiesand they cannot be retried. -
As we mentioned earlier, Linkerd only treats the
5XXstatus code in the response as an error, while both2XXand4XXare recognized as success status codes. The4XXstatus code indicates that the server looked but could not find the resource, which is correct server behavior, while the5XXstatus code indicates that the server encountered an error while processing the request, which is incorrect behavior.
Now let’s verify what we have learned by adding a retry function to the /api/vote route of the web service. Let’s look at the ServiceProfile object of the web service again, which looks like this.
|
|
Next we add an attribute isRetryable: true to the route /api/vote, as follows.
Reapply the ServiceProfile object after updating.
|
|
After application we can observe the change in the routing metrics of the vote-bot service.
|
|
You can see that the actual success rate becomes very low, because the retry result may still be wrong. We mentioned above that Linkerd’s retry behavior is configured by the retry budget, and that when isRetryable: true is configured, the default retry budget rules are applied, and the following YAML fragment of the ServiceProfile resource shows the retryBudget object configuration with default values.
where the retryBudget parameter is with three main fields.
retryRatio: the retry rate, which indicates the maximum ratio of retry requests to original requests. AretryRatioof 0.2 means that retry will increase the request load by up to 20%.minRetriesPerSecond: this is the number of retries per second allowed in addition to those allowed byretryRatio(this allows retries when the request rate is very low), default is 10 RPS.ttl: indicates how long requests should be considered when calculating the retry rate, a larger value will consider a larger window and therefore allow more retries. The default is 10 seconds.
Configuring Timeouts
In addition to the retry and retry budget, Linkerd also provides a timeout feature that allows you to ensure that requests for a given route never exceed a specified amount of time.
To illustrate this, let’s take a fresh look at each of the routing metrics for the web and voting services.
We have already learned that the delay between web and voting is close to 1ms. To demonstrate the timeout, we set the /api/vote route timeout to 0.5ms, so that basically it will not be able to meet the requirements and timeout will occur, Linkerd will send the error to the client, and the success rate will become 0.
Modify the ServiceProfile object of the web service and add the timeout property, as follows.
|
|
After applying the above object, both the valid and actual success rates of the service drop to 0, because /api/vote times out within 0.5ms, so the success rate becomes 0.
|
|
At this point we understand the use of retries and timeouts in Linkerd, which are part of Linkerd’s overall policy to increase reliability in the event of a transient failure. We decide when and how to configure retries and timeouts by using per-route metrics in the service profile, and Linkerd parameters its retries with a retry budget to avoid “retry storms” where the agent will stop sending requests to the service when the retry budget is exhausted to avoid overloading the service and potentially affecting the rest of the application.