Introduction
This article is mainly to learn and understand the characteristics of map by exploring the data structure and source code implementation of map in golang, containing a total of map’s model exploration, access, expansion, etc..
Map’s underlying memory model
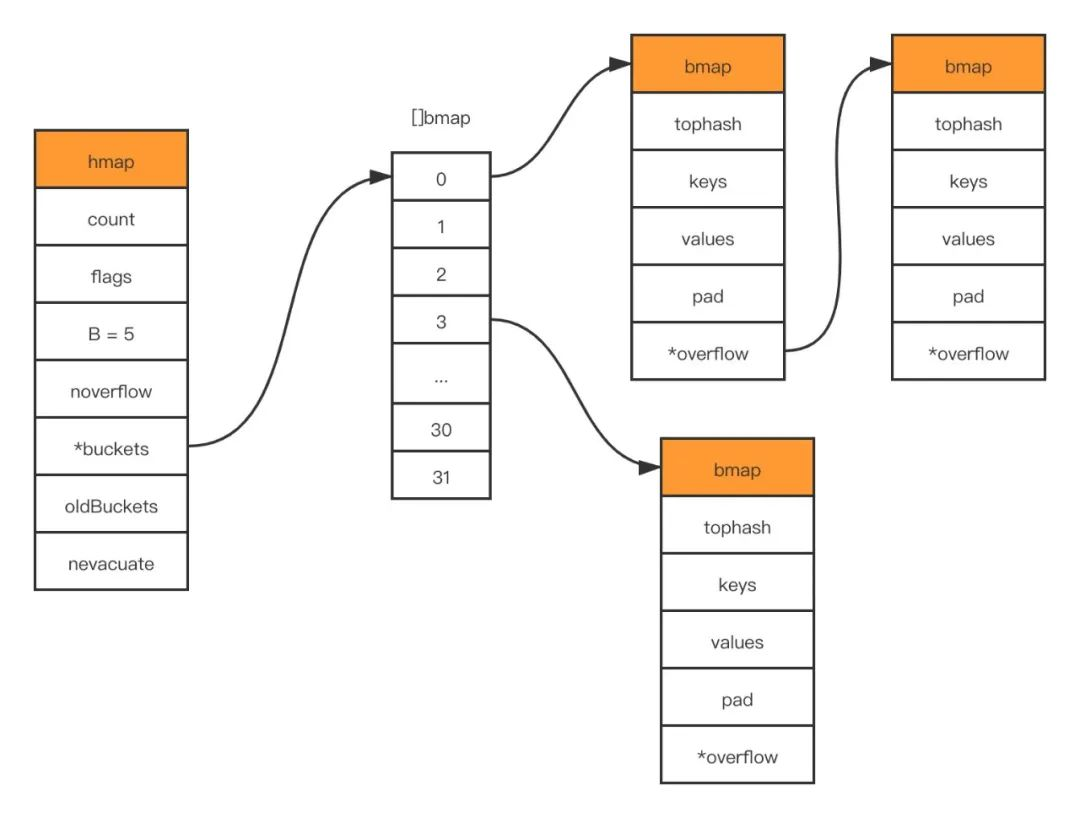
The underlying struct that represents map in golang’s source code is hmap, which is short for hashmap.
|
|
B is the logarithm of the length of the buckets array, i.e., the length of the bucket array is 2^B. A bucket is essentially a pointer to a piece of memory space that points to the struct shown below.
But this is only the surface (src/runtime/hashmap.go) structure, which is spiced up during compilation to create a new structure dynamically.
bmap is the underlying data structure that we often refer to as a “bucket”. A bucket can hold up to 8 keys/values, and the map uses the hash function to get the hash value to determine which bucket to assign it to, and then finds the location of the bucket based on the higher 8 bits of the hash value. The composition of the map is shown below.
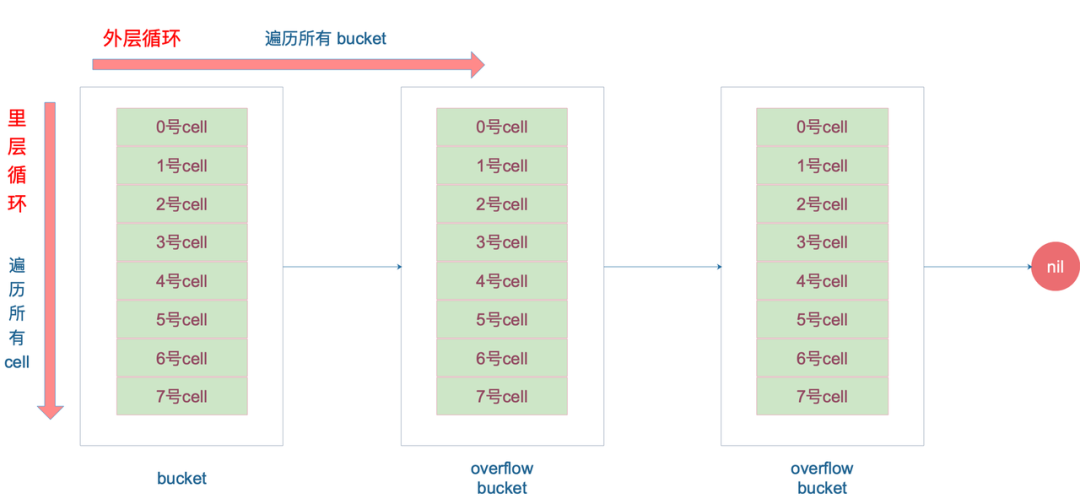
Map’s put and get
Both put and get in a map are essentially doing one thing, and that is:
- look up the current location where k/v should be stored.
- get/put, so we understand how to locate the location of the key in the map we understand get and put.
Underlying code
|
|
Addressing process

Map expansion
Like slice, map in golang first requests a small amount of memory space at initialization, and then dynamically expands it as the map is deposited. There are two types of expansion, incremental expansion and equivalent expansion (rearranging and reallocating memory). Let’s understand how the expansion is triggered.
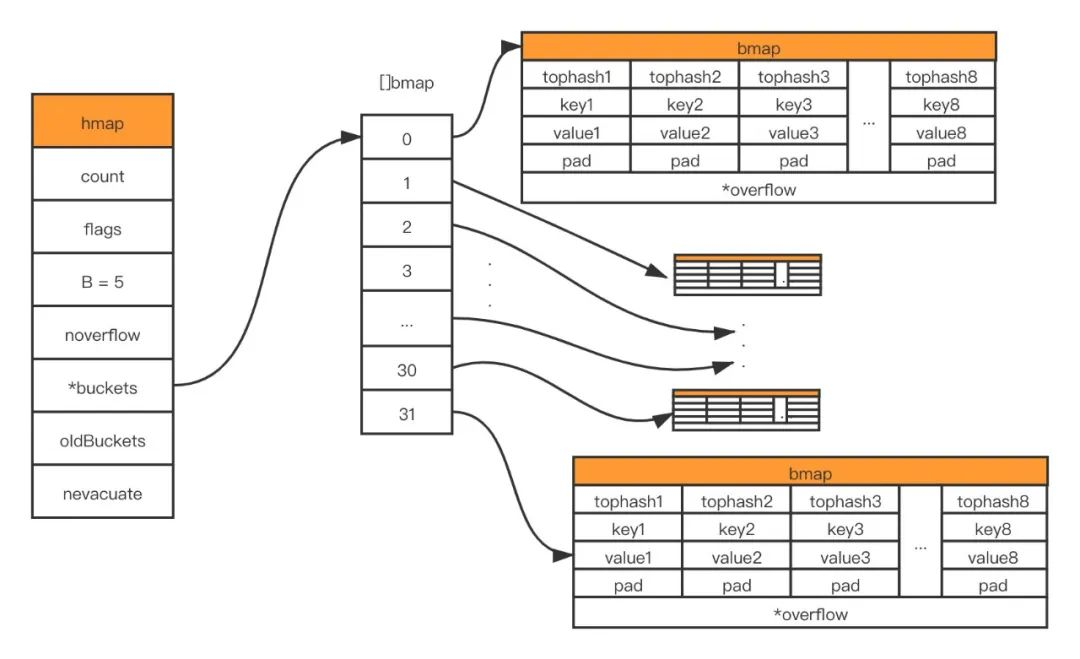
- the load factor exceeds the threshold value, the threshold value defined in the source code is 6.5.(trigger incremental expansion)
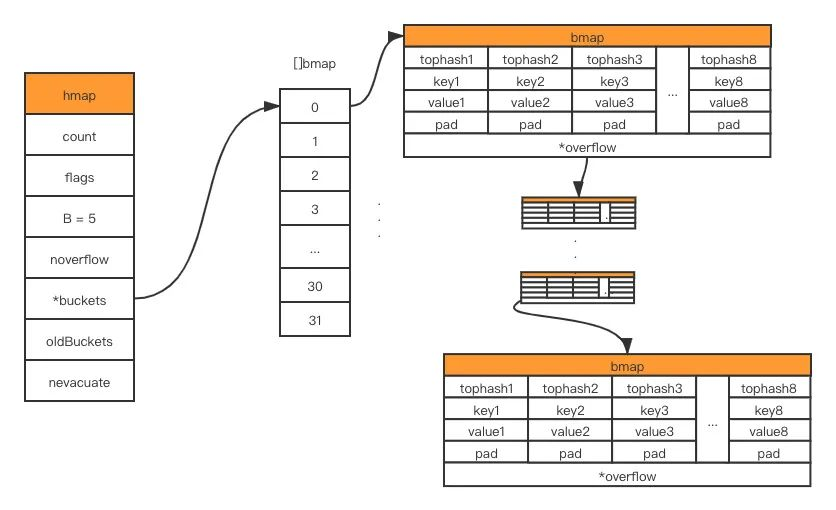
- Too many buckets in overflow: when B is less than 15, that is, the total number of buckets 2^B is less than 2^15, if the number of buckets in overflow exceeds 2^B; when B >= 15, that is, the total number of buckets 2^B is greater than or equal to 2^15, if the number of buckets in overflow exceeds 2^15. 15.(trigger equivalent expansion)
The first case
The second case
Orderliness of Map
First of all, the map in golang is unordered, to be precise, it is not strictly guaranteed to be ordered, from the source code above we know that the map in golang, after expansion, may move part of the key to the new memory, because in the process of expansion and moving data, the original data location is not recorded, and in the golang data structure does not save the order of the data, so this part is actually unordered after expansion.
The process of traversal is actually traversing the memory addresses sequentially, and traversing the keys in the memory addresses sequentially, but this is already out of order. But if I just have a map, and I make sure I don’t modify or delete the map, then it is reasonable to assume that no changes will occur without expansion. But because of this, GO is in the source code. But there is an interesting phenomenon that even if the map is not expanded by insertion and deletion, it is still unordered during the traversal.
|
|
The result of the above code runs as follows.

It is easy to see that even if the map is not expanded, it is still unordered when it is traversed multiple times. This is because golang is officially designed to add random elements to randomize the order of traversing the map to prevent users from traversing it sequentially.
Relying on the map’s order for traversal is risky code and is strongly discouraged by GO’s strict syntax rules. So we must remember that maps are unordered when we use them, and not rely on their order.
Concurrency of Map
First of all, we all know that map is not a concurrency-safe data structure in golang, and when several goruotines read and write to a map at the same time, there is a concurrent write problem: fatal error: concurrent map writes. but why is map not concurrency-safe? cost and benefit.
The official answer is as follows.
- Typical usage scenario: The typical usage scenario for map is that it does not require secure access from multiple goroutines.
- Atypical scenarios (requiring atomic operations): map may be part of some larger data structure or an already synchronized computation.
Performance Scenario Considerations: Adding security for just a few programs that would cause all operations of map to handle mutexes would degrade the performance of most programs. Meanwhile, golang provides a concurrency-safe sync map.
But we have questions again, why golang map concurrency conflict does not throw an error out, or panic off, but to let the program panic, choose to let the program crash crashed out. Here is the golang official considerations for the tradeoff between risk and map complexity scenarios, first of all, map in the official said clearly does not support concurrent read and write, so concurrent read and write operations on the map itself is incorrect.
Scenario 1: If map chooses to add an error return value when writing or reading, it will cause the program to not be able to use map as it does now. Additional catching and err determination is required.
Scenario 2: If the map selects panic (recoverable), then if there is a concurrent data writing scenario, it will lead into the recover, and if there is no special treatment for this scenario, it will lead to dirty data in the map, and then the program will cause unpredictable errors when using the map. In this case, it is difficult to find the root cause of the problem.
Therefore, after considering these scenarios, golang chooses to explicitly throw crash exceptions to expose the risk in advance. The problem can be clearly located. In summary, when using map, we have to strictly ensure that it is used in a single thread, if there are multi-threaded scenarios, we recommend using sync map.