etcd is an open source project initiated by CoreOS to build a highly available distributed key-value storage system. etcd can be used to store critical data and implement distributed orchestration and configuration services, playing a key role in modern cluster operations.
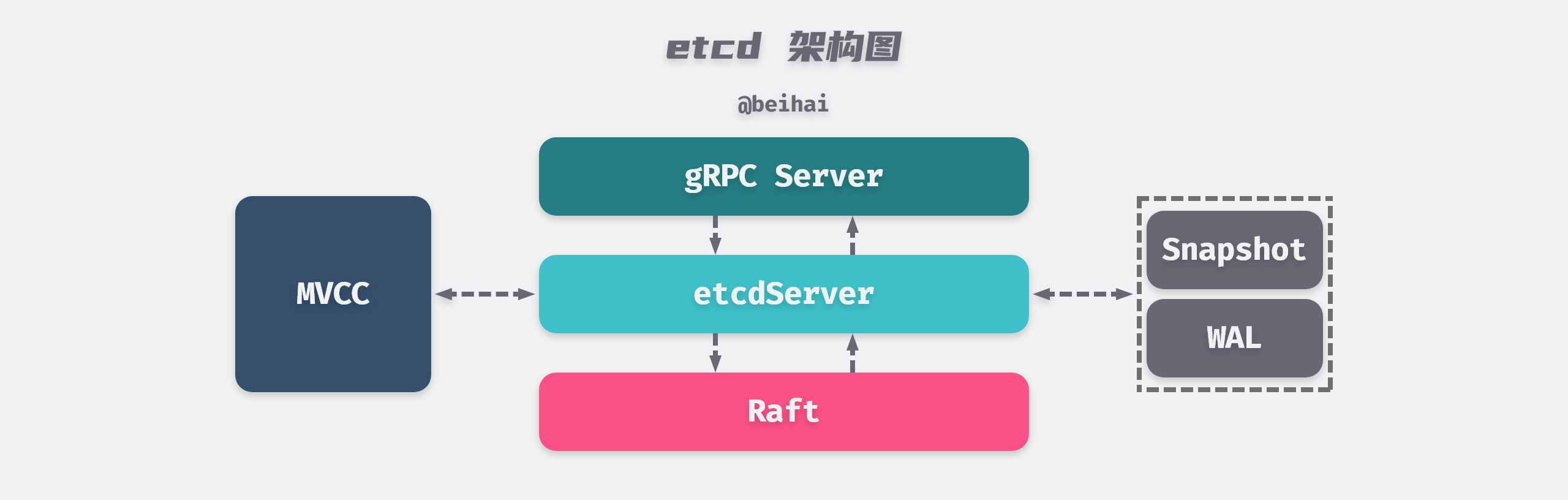
etcd is a distributed key-value storage service based on the Raft consensus algorithm. The project structure is modular, with the Raft module for distributed consensus, the WAL module for data persistence, and the MVCC module for state machine storage. These modules communicate and assign tasks through the etcdServer module. This article will focus on these three modules to analyze how etcd is implemented, how to achieve data consistency among multiple nodes of etcd, how to achieve high performance concurrent read and write transactions, and finally, how etcd solves the important problem of linear consistency reads. This article will give us a better understanding of the key features of etcd.
Distributed Consensus
The consensus problem is one of the most important and fundamental problems in distributed computing, commonly understood as the goal of getting multiple nodes to agree on something, so before analyzing the specific implementation of etcd introduce some important concepts in Raft’s consensus algorithm. It is highly recommended to read the Raft paper In Search of an Understandable Consensus Algorithm first, which is very helpful for understanding the principles of etcd implementation is very helpful.
State Machine Replication
In a distributed environment, if we want to make a service fault-tolerant, the most common way is to have multiple copies of a service running on multiple nodes at the same time. To ensure that the state of multiple replicas is synchronized at runtime, i.e., that the client gets the same result no matter which node it sends the request to, State Machine Replication is often used.
State machine replication is implemented using log replication. etcd instantiates logs as Entry logs, and each node stores a series of Entry logs, which are identical and in the same order for each node. The state machine executes the commands in the Entry in order, so each state machine processes the same sequence of commands, which results in the same data state and output sequence.
Raft’s job is to ensure that the replication logs are consistent. The Consensus module on the server node receives write requests from clients and adds them to the WAL (Write Ahead Log). This server then communicates with the Consensus modules on the other servers to ensure that the same sequence of logs is available on each server. The state machine on each server executes the commands sequentially and returns the execution results to the client, thus creating a highly available replicated state machine.
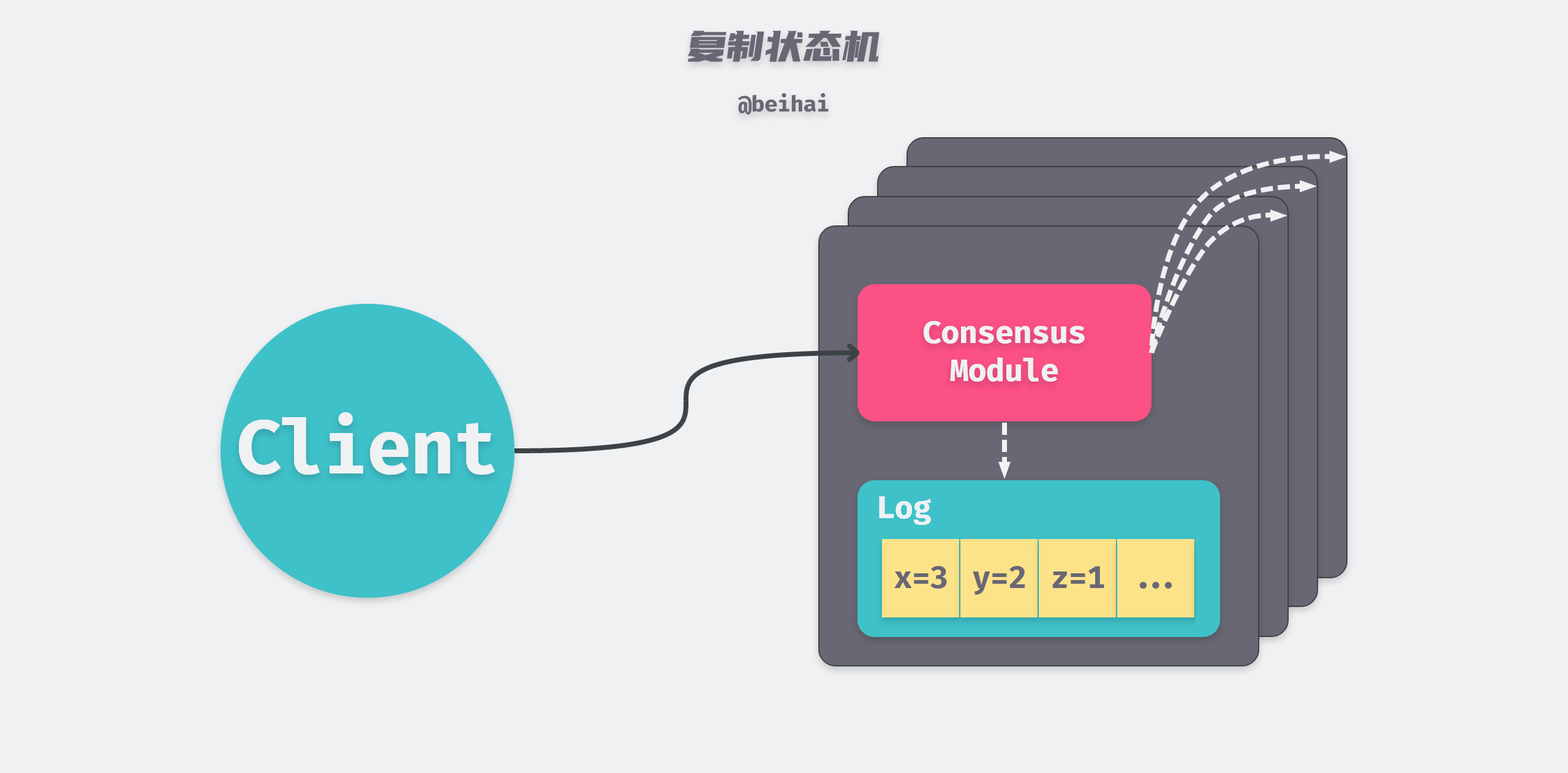
The above figure is modified from the paper: In Search of an Understandable Consensus Algorithm Figure 1
The replication state machine is an abstract module, and the state machine data is maintained by a separate back-end storage module. Each write request from the client is first persisted to a WAL file, and then the state machine data is modified based on the contents of the write request. A read request for data requires querying the data from the state machine instead of directly fetching the latest log entry maintained by the current node. To prevent data overload, etcd periodically generates snapshots to compress the data. Normally, as long as more than a quorum (n/2+1) of nodes in the cluster respond to a single round of remote procedure calls, the client’s request is considered to have been executed, and a few slow servers do not affect the overall system performance.
Leader Election
Raft is an algorithm used to manage the log replication process. Raft elects a Leader through a “leader election mechanism”, which manages log replication for consistency. A Raft cluster consists of several server nodes, each with a unique identification ID.
The Raft algorithm paper specifies three node identities: Leader, Follower, and Candidate, and the etcd implementation adds PreCandidate and Learner.
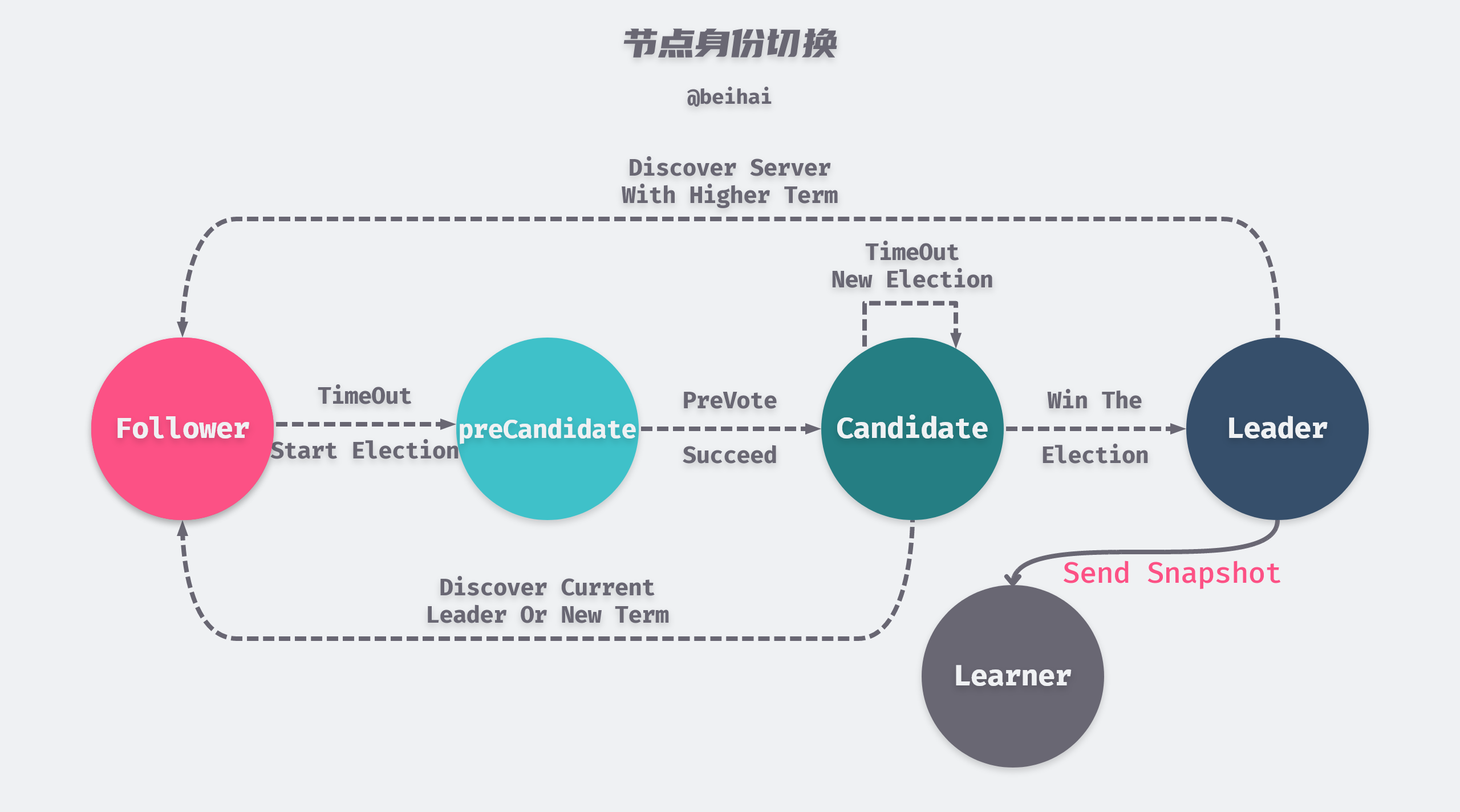
The above figure is modified from the paper In Search of an Understandable Consensus Algorithm Figure 4
The cluster starts with all nodes in the Follower state, and then one node is successfully elected as Leader, and the majority of the time the nodes in the cluster will be in one of these two states. When a Follower node’s election timer times out, it enters the preVote state (switches to PreCandidate status) and before it is ready to initiate an election, it needs to try to connect to other nodes in the cluster and ask them if they want to participate in the election. If the other nodes in the cluster can receive the Leader’s heartbeat message properly, then it will refuse to participate in the election. If more than a quorum of nodes respond and indicate their participation in the new election, the node switches from PreCandidate status to Candidate and initiates a new round of election.
The preVote mechanism prevents outlier nodes from frequently refreshing their tenure values, preventing the node from rejoining the cluster with a larger tenure value to depose the Leader.
|
|
Learner is a new role introduced in etcd 3.4. When a new node joins the cluster without any log entries stored in its state machine, it takes a long time to synchronize the logs, which may cause the cluster to be unable to process new requests. To avoid this availability interval, new nodes join the cluster as non-voting Learner and no election is initiated after the election timer times out (the Leader does not consider them to be in the majority of the cluster.) The Leader sends snapshots to the Learner so that the Learner can quickly catch up with the logs. When the Learner agrees with the Leader log, it switches to its normal identity.
In particular, when a node becomes a Leader, it immediately commits an empty log, sets all logs it carries to commit status, and all log entries before that log entry are also committed, including those created by other Leaders but not yet committed, and then synchronizes to other nodes in the cluster. This ensures the consistency of the cluster data and prevents data loss during the Leader node switchover.
|
|
Data channel
The Raft module well does not provide an implementation of the network layer, but rather encapsulates the messages to be sent into Ready instances that are returned to the upper-level module, which then decides how to send them to other nodes in the cluster.
In etcd’s communication module, etcd defines 19 different types of messages (Messages) depending on the purpose. The size of the data carried by these messages may vary, for example, a heartbeat message sent by a Leader to a Follower node may only be a few tens of bytes, while a PRC snapshot transmission can be larger, even over 1GB.
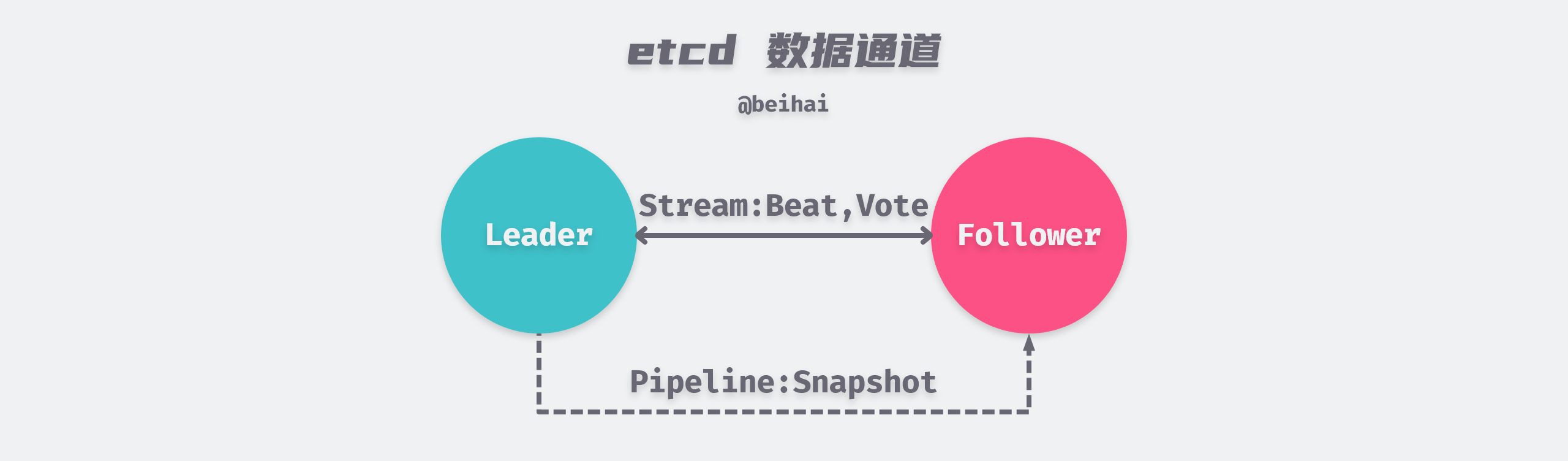
To enable the network layer to efficiently handle messages with different data volumes, etcd takes a categorical approach by abstracting two types of messaging channels, Stream and Pipeline. Both channels use gRPC to transfer data. stream channel is used to handle messages with less data volume that are sent more frequently, such as heartbeat messages, append log messages, etc. Only one HTTP long connection is maintained between nodes, and data is written to the connection alternately. pipeline channel is used to handle messages with more data volume, such as snapshot messages. This type of message needs to be handled separately from heartbeat messages, otherwise it will block the transmission of heartbeat packets, which will affect the stability of the cluster. pipeline channel only transmits data through short connections and closes when it runs out.
Pipeline type channels can also be used to transfer small data volumes when Stream type connections are not available. In addition, Pipeline type channels can be used to send multiple messages in parallel.
The communication module is not the focus of this article, the concepts related to the data channel are described here in general. Perhaps the implementation of gRPC will be explained in detail in a later article.
Raft module
After understanding the concepts related to distributed consensus, let’s see how the consensus module is implemented. etcd’s consensus module is implemented in the raft structure, which is a very complex structure that implements key features such as logical clock functions, message handling functions, election timers, and so on. Since these are written according to the Raft algorithm, we will not go into the details of the implementation here, but you can read the code in etcd/raft/raft.go if you are interested. In the following, the term ‘Raft module’ is used to refer to the raft structure and its implementation, and the concepts are introduced in a fragmented form where needed.
etcd’s Raft module only implements the basic behavior of the Raft protocol and does not implement network transfers, persistent storage, state machines, etc. etcd separates these modules and the Raft module provides a set of interface implementations for these application layer modules. Let’s understand the concepts involved.
Entry
All data (key-value pairs) maintained by the Raft module are instantiated as Entry log representations, and each Entry log maintains its own private data.There are two main types of Entry logs, one for storing normal key-value pair data (EntryNormal) and another for storing configuration information after a cluster configuration change ( EntryConfChange), when the cluster state changes, also by sending Entry logs to other nodes to transmit the new configuration information.
All write requests in the Raft algorithm are handled by the Leader node, and the data sent by the client needs to be encapsulated into an Entry log before the Leader can append the log. The Data field is the key-value pair sent by the client, the Term field is the term of the current cluster, and the Index field is the index of the Entry log, which is equivalent to a globally unique ID.
These Entry logs are appended to RaftLog after the data is encapsulated.
|
|
RaftLog
The Raft module uses the RaftLog structure to manage Entry logs on nodes. RaftLog maintains two data storage structures unstable and MemoryStorage (in some source code comments, MemoryStorage is described as Stable Storage), both of which Entry logs are maintained in memory.
When the client sends a write request to the etcd cluster, the Raft module saves the Entry logs encapsulated in the request to the unstable, which is unstable because the Entry logs maintained in the unstable are not yet persistent in memory, so if the server goes down, this data will be lost. This data is unstable. The Raft module then notifies etcdServer to persist the Entry logs to a WAL file and then ‘moves’ the Entry logs from the unstable to MemoryStorage.
Although the word “move” is used above, the actual process is that etcdServer first appends the Entry logs to MemoryStorage, and then notifies the Raft module to clear the corresponding logs from the unstable.
|
|
Both unstable and MemoryStorage have an uncomplicated structure. The MemoryStorage.snapshot field maintains the index and term values of the last log contained in the most recent snapshot, so ents[i] represents the entry log with index value i+snapshot.Metadata.Index. Entry log (ents[0] is a dummy data and i is calculated from 1). The unstable.offset field stores the index value of the first log in entries, by which the log with the specified index can be obtained.
etcd applied logs are written to the state machine asynchronously, so RaftLog maintains not only the maximum index value of the committed Entry logs, but also the maximum index value of the applied (written to the state machine) Entry logs, and applied <= committed, two parameters that play an important role in the linear consistency of etcd. The author will analyze this issue in the following.
From these aspects, we can see that the logical structure of RaftLog is viewed as follows.
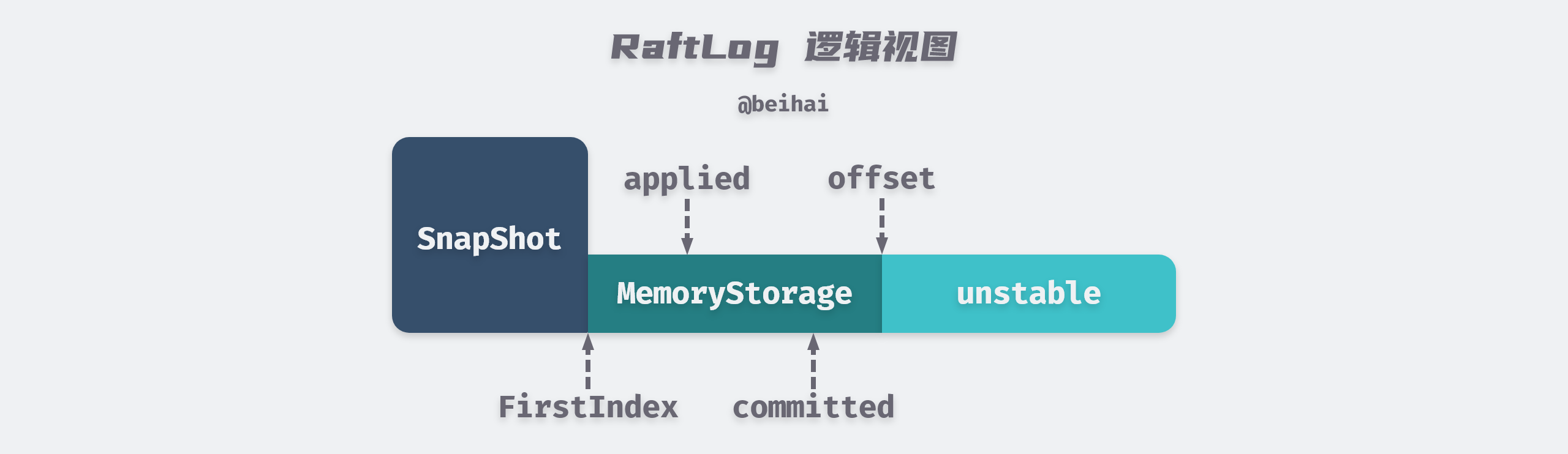
Unstable and MemoryStorage provide many of the same APIs for RaftLog, such as getting the index of the first or last log in the Entry array, getting the term of the log corresponding to a given index, etc. When RaftLog needs this metadata, it will first look it up in unstable, and if it doesn’t find it, then look it up in MemoryStorage.
|
|
If a conflict arises when appending data to the unstable and MemoryStorage, the original conflicting data will be overwritten and the latest data received by the node will take precedence. If the conflicting data when appending to the unstable is so large that it exceeds the boundary between the unstable and the MemoryStorage, RaftLog does not modify the log in the MemoryStorage, but truncates the data and keeps only the second half.
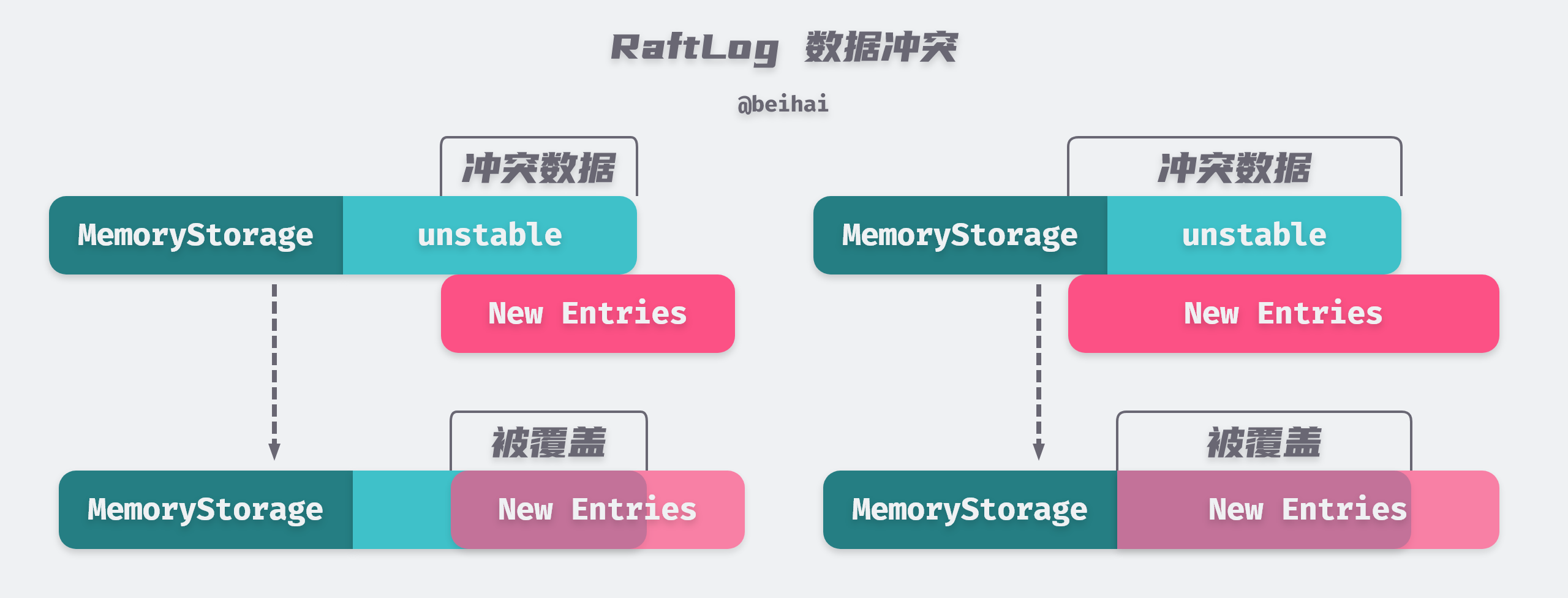
Data conflict scenarios only happen with Follower nodes, and Leaders have the Append-Only feature of never overwriting or deleting their own logs.
Node
etcd represents a node in a cluster with the structure Node, which is a layer of wrappers for the Raft module and provides a relatively simple API interface to the external world. The main role is to bridge the messaging between the application layer and the Raft module, passing messages from the application layer to the Raft consensus module, and feeding the results of the consensus module processing back to the application layer. The goroutine gets caught in a huge for-select-channel event loop, constantly fetching data from the channels for processing. The node.run method has three main purposes.
- One is to check if the Raft module has any data that needs to be processed by the higher-level module, and if so it will encapsulate this data into a
Readystructure and send it to the higher-level module via the readyc channel. - The second is to detect if the Leader node of the cluster has changed, and if so, to pause the processing of client requests (MsgProp type messages).
- Third, it listens or sends data to various types of channels, such as client requests, inter-node communication, etc., and waits for other modules to process the data.
|
|
Since Node is not responsible for data persistence and other functions, the Raft module will pack the data that needs to be processed by the upper-level module into the Ready structure and send Ready to the upper-level module for processing through the readyc channel, and the upper-level module will call the node.Advance() method after processing the data to notify the Raft module that the data has been processed and is ready to send new data for processing.
The Ready structure passes a variety of data that needs to be processed by the upper layer, the specific data types of which are shown in the following snippet.
The raftNode.start method of etcdServer starts a separate goroutine to accept these data and sort them: it writes the Entries, Snapshot of the Ready structure to the persistence file and appends them to MemoryStorage; it applies the CommittedEntries to the state machine; and Messages are broadcast to other nodes in the cluster.
|
|
From here, we can see that the process of applying logs and sending messages by etcd is asynchronous, so the fact that a log has been committed does not mean that it has been applied to the state machine, and the fact that the Leader has applied this log does not mean that all Follower has applied this log, each node will decide the timing of applying the log independently, and there may be some delay in between.
Although the etcd application logging process is asynchronous, this batch strategy enables multiple logs to be written in bulk at once, which can improve the I/O performance of the node.
Writing request flow
After introducing a few important concepts of the Raft module, here is a brief summary of the general flow of etcd writing to an Entry log, so that we can better understand how etcd works.
- when a client sends a write request to the etcd cluster, the Entry log encapsulated in the request is handed over to the Raft module for processing, which first saves the Entry log to the unstable.
- when the time is right (after the etcdServer has processed the last Ready instance), the Raft module encapsulates the Entry log in a Ready instance and returns it to the upper-level module for persistence.
- when the upper module receives the Entry log to be persisted, it first writes it to the WAL file, then broadcasts this data to the other nodes in the cluster, and finally sends a signal to the Raft module for the next step.
- the Raft module ‘moves’ the Entry log from unstable to MemoryStorage.
- when the Entry log is copied to more than half of the nodes in the cluster, the Entry log will be confirmed as committed by the Leader node, and the Leader will reply to the client with a successful write request, and return the Entry log to the upper module in a Ready instance.
- The upper layer module applies the entry logs carried in the Ready instance to the state machine.

With the above steps etcd completes a write operation. However, just because a Leader node applies data to the state machine does not mean that other nodes in the cluster will also apply data to the state machine, so if you read data from etcd at this point you may get old data. etcd has additional mechanisms to address this issue. This part will be described below.
Data Persistence
etcd is persistent as soon as data is updated by default, and uses WAL (Write Ahead Log) for data persistence storage. WAL records the entire process of data changes, and all data in etcd is written to WAL before it is committed. etcd also periodically takes snapshot backups of data, which store all data in etcd at a given time. The WAL file can be deleted if the data is already stored in the snapshot.
Pre-written logs
The Raft module encapsulates the Entry logs sent by the client into a Ready instance and sends it to the upper-level module for persistence. etcdServer receives the Entry logs to be persisted and records them to a WAL file for persistence to disk.
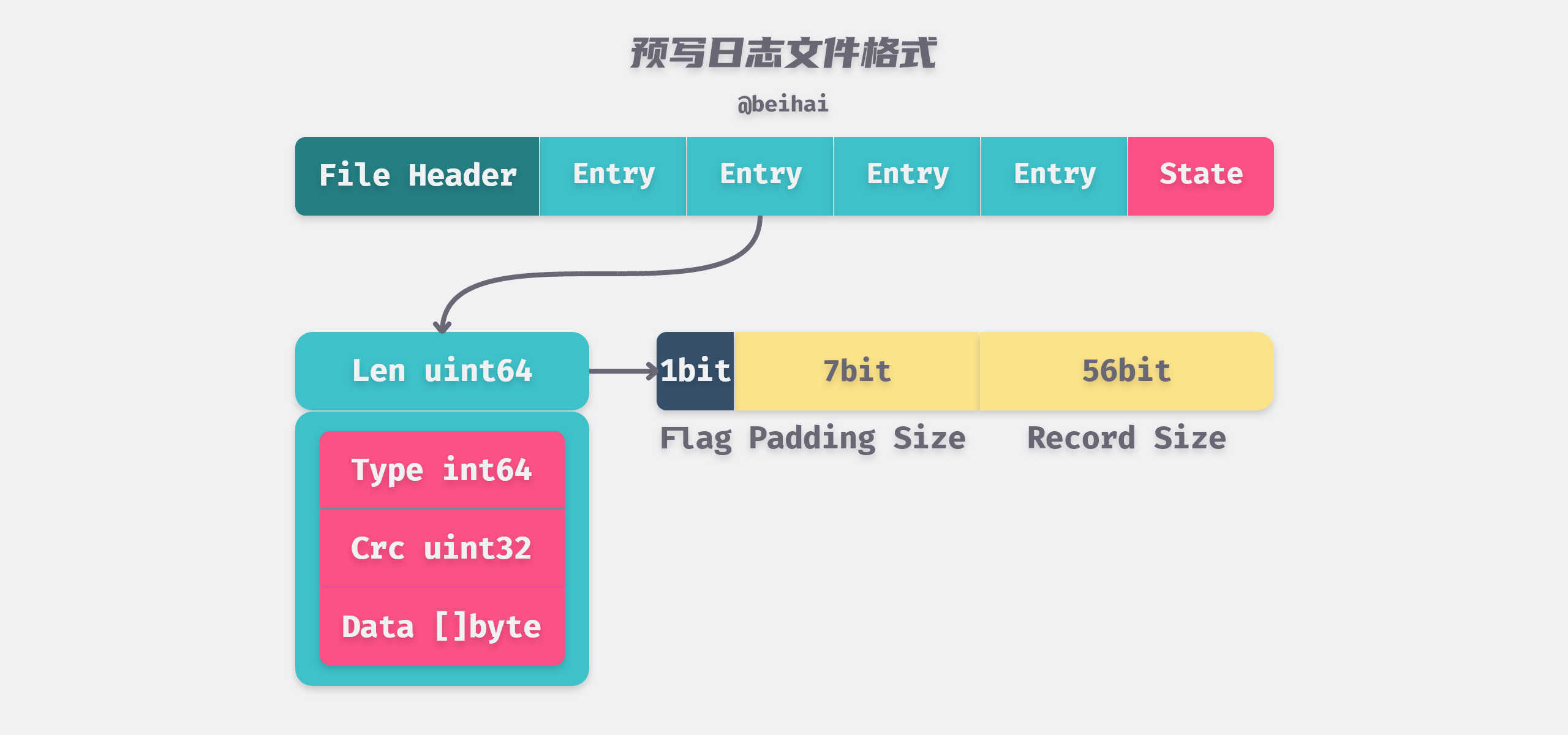
In the WAL log file, each log record is structured as a structure Record, and the structure is serialized into the log file in the format of Protocol Buffers, where the meaning of each field is as follows.
|
|
As you can see from the Record’s instance type, etcd’s WAL files not only store Entry logs, but also cluster status information, snapshot metadata information, and other important data. Each WAL file stores a metadata of type metadataType in the header, which is defined in the Metadata structure of the etcdserver/etcdserverpb/etcdserverpb.pb.go file and holds the NodeID and ClusterID of the current node. ClusterID`, which identifies the state of the cluster at the time the file was created.
File Management
WAL’s externally exposed interface for creating new files is the Create() function, which initializes a temporary file and pre-allocates 64MB of storage, creating the new file by writing metadata of type metadataType and an empty snapshotType record in the header. After the initialization operation is completed, the file is renamed and the system call function fsync() is called to flush the above file operations to disk immediately. Since the whole process is executed synchronously, it is seen as an atomic operation.
|
|
etcd’s pre-write log uses the structure WAL to maintain information about the WAL instance, where the locks field records the handles of all WAL files currently held by the WAL instance. etcd puts a mutex lock on the WAL file, so the WAL file is either read-only (node reboot data recovery) or write-only, which is done to ensure that the data is This is done to ensure data security.
When the WAL file size exceeds 64MB, it needs to be cut and switched, the logic of which is implemented in the WAL.cut() method. The WAL.fp.run() method is responsible for pre-creating temporary files and pre-allocating space, it runs in a separate goroutine to create temporary files ending with .tmp in advance, when it is necessary to switch WAL files, the WAL.cut() method directly gets the temporary files from the background goroutine, rename them and use them.
|
|
Appending Records
WAL implements methods to append records for different types of Records. Save() method implements bulk writing of Entry logs, which recursively encapsulates the Entry logs to be written as Record instances of type entryType, then serializes them and appends them to the log segment file, and then appends a Record of type stateType to the log file after the bulk writing of the Entry logs. and serialize it to the log file. The stateType record records the current node’s term, voting result and index of the submitted log, and is used as the cluster’s state information record. The implementation of the WAL.Save() method is as follows (the locking step is omitted).
|
|
As you can see from the above code snippet, etcd may store multiple Entry logs at a time. The sync() system call is called at the end to flush these Record records to disk synchronously.
The Record needs to be serialized before it can be written to the persistence file, which is done with the encoder.encode() method. The encode() method aligns the data by 8 bytes and records the number of bytes occupied by the Record in a uint64 field: the first bit of the field is used to mark whether it contains padding (1 if it does), the next seven bits are used to indicate the size of the padding, and the high 56 bits are used to indicate the actual size of the Record.
|
|
The encode() method writes data to a Writer with a buffer, and every time an OS page (4KB) size buffer is filled, a Flush operation is automatically triggered to flush the data to disk. The above code snippet allows us to infer the format of the WAL file.
Snapshots
WAL is an Append Only log file that keeps adding new logs at the end of the file. This can avoid the performance loss caused by a large number of random I/Os, but as the program runs, the node needs to handle a large number of requests from clients and other nodes in the cluster, and the corresponding amount of WAL logs will keep increasing, which takes up a lot of disk space. When a node goes down, if it wants to restore its state, it needs to read all the WAL log files from scratch, which is obviously very time-consuming.
To solve this problem, etcd periodically creates snapshots, serializes the entire node state, and then writes it to a stable snapshot file, so that all log records before the snapshot file can be discarded. When restoring the state of a node, the snapshot file is loaded first, and the snapshot data is used to restore the node to the corresponding state, and then the data after the snapshot is read from the WAL file to restore the node to the correct state.
There are two types of etcd snapshots, one is a data snapshot used to store all the data in etcd at a given time, and the other is an RPC snapshot used for slower nodes in the cluster to catch up on data.
Data Snapshot
When Raft module applies logs to the state machine, it will trigger the save data snapshot function. This function will first determine the difference between the index of the applied log and the index value of the last log saved in the last snapshot, and will save the snapshot only if the difference exceeds the set SnapshotCount, which defaults to 100,000.
etcdServer creates a background goroutine to store the snapshot data. In etcd V2 version, the in-memory data is serialized to JSON and then persisted to disk, while etcd V3 reads the current version of the state machine data, serializes it to a file, and flushes it to disk synchronously.
After the snapshot is created, a Snapshot Record is written to the pre-written log to save the current state information of the node creating the snapshot. When the node restarts, it reads the contents of the snapshot and reads the subsequent log entries from the WAL file according to the index and term values of the last log, so that the node data can be recovered quickly.
|
|
RPC Snapshot
The Leader maintains a Next value for each Follower, which indicates the index value of the next Entry record to be replicated for that Follower node. In case of network failure or communication delay, there may be nodes in the cluster that are lagging behind in log entries. In order to let the lagging nodes catch up with the cluster as soon as possible, the Leader will pack the logs starting from Next into snapshots and send them to the Follower via MsgSnap messages.
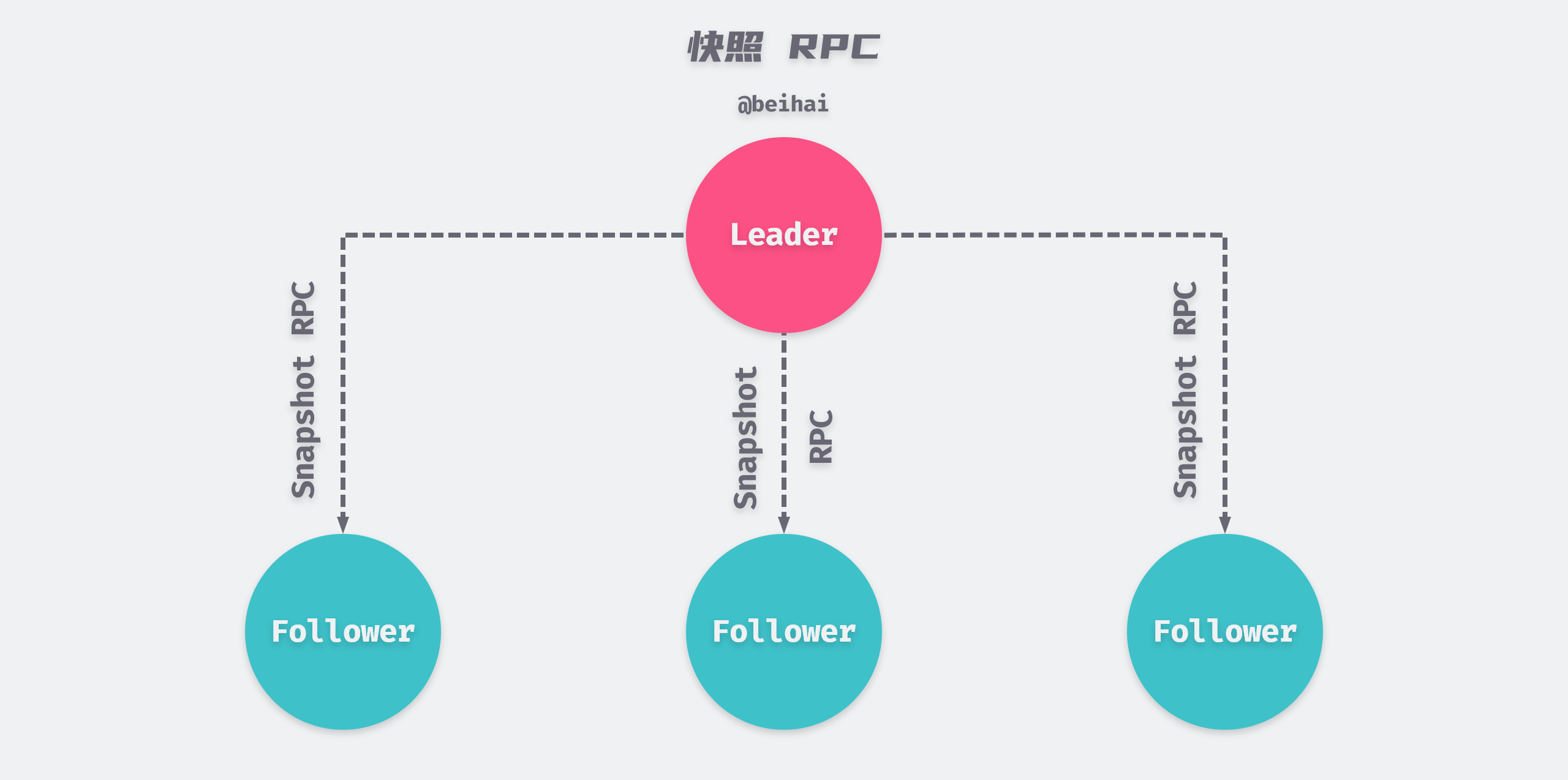
etcd defaults to 5,000 logs behind the Follower catch-up, because the communication delay between cluster nodes is usually in the millisecond range, and etcd V3 has a limit of 10,000 logs per second, so 5,000 logs are enough for the Follower to catch up with the Leader.
|
|
When Follower receives the MsgSnap message, it will give the received data to the Snapshotter.SaveDBFrom method to save it to the snapshot file.Once Follower receives the snapshot, it can apply the data in the snapshot to the state machine.
|
|
Snapshot files are named according to the term value and index value of the last Entry log covered by the snapshot. The file name format of data snapshot is “term-index.snap”, and the file name format of RPC snapshot is “index.snap.db”, we can distinguish snapshot files according to the file name format.
This is what etcd does with snapshot files. We can also use snapshots to back up and restore data, or copy snapshot files from a certain point in time to a new node joining the cluster, which saves time in synchronizing logs and reduces the pressure on the Leader.
State Machine Storage
etcd’s MVCC module implements the state machine storage feature, using the open source embedded key-value storage database BoltDB as its underlying layer, but this project has been archived by the author and is no longer maintained, so the etcd community maintains a bbolt version of itself. This section analyzes how the MVCC module uses multi-version concurrency control to maintain historical version information of the data.
Concurrency Control
Concurrency control is a very challenging topic in the database domain. Common approaches to concurrency control include pessimistic locks, optimistic locks, and multi-version concurrency control. But whether it is pessimistic locking or optimistic locking, they are not really lock concepts, but rather ‘design ideas’ used to describe lock classes.
Pessimistic locking
Pessimistic concurrency control (also known as pessimistic locking) refers to a pessimistic and negative attitude towards data competition. By default, conflicts are bound to arise when data is accessed by the outside world, so various locks are added to the data throughout the data processing to achieve concurrency control and ensure that only one thread can access the data at the same time. If a lock is applied to a row of data during the execution of a transaction, only after this transaction releases the lock can other transactions perform operations that conflict with the lock. Since the locking mechanism is a preventive version control, read operations will block write operations and write operations will block read operations, and concurrency performance is poor when the lock is more granular and longer, and it is mainly used in concurrent environments where data competition is intense and there are more writes and fewer reads.
Optimistic locking
Optimistic concurrency control (also known as optimistic locking), as opposed to pessimistic locking, assumes that multi-user concurrent transactions are processed without affecting each other, so no locks are placed on the data. Before committing the updated data, each transaction checks to see if any other transaction has modified the data since it was read by that transaction. If another transaction has modified the data, the committing transaction will roll back. Optimistic locks are mostly used in environments where there are few data conflicts and the cost of occasionally rolling back a transaction is much lower than the cost of locking the data when it is read, in which case optimistic locks can achieve higher throughput.
MVCC
Multi-Version Concurrency Control (MVCC) is a lock-free transaction mechanism that can be thought of as an implementation of the idea of optimistic concurrency control that works well with pessimistic locking to increase the concurrency of transactions. will pick the most appropriate (either the latest version or the specified version) from a limited number of versions of data and return it directly. In this way, we do not need to be concerned about data conflicts between read and write operations. Therefore, how to manage and efficiently pick versions of data becomes a major problem for MVCC to solve.
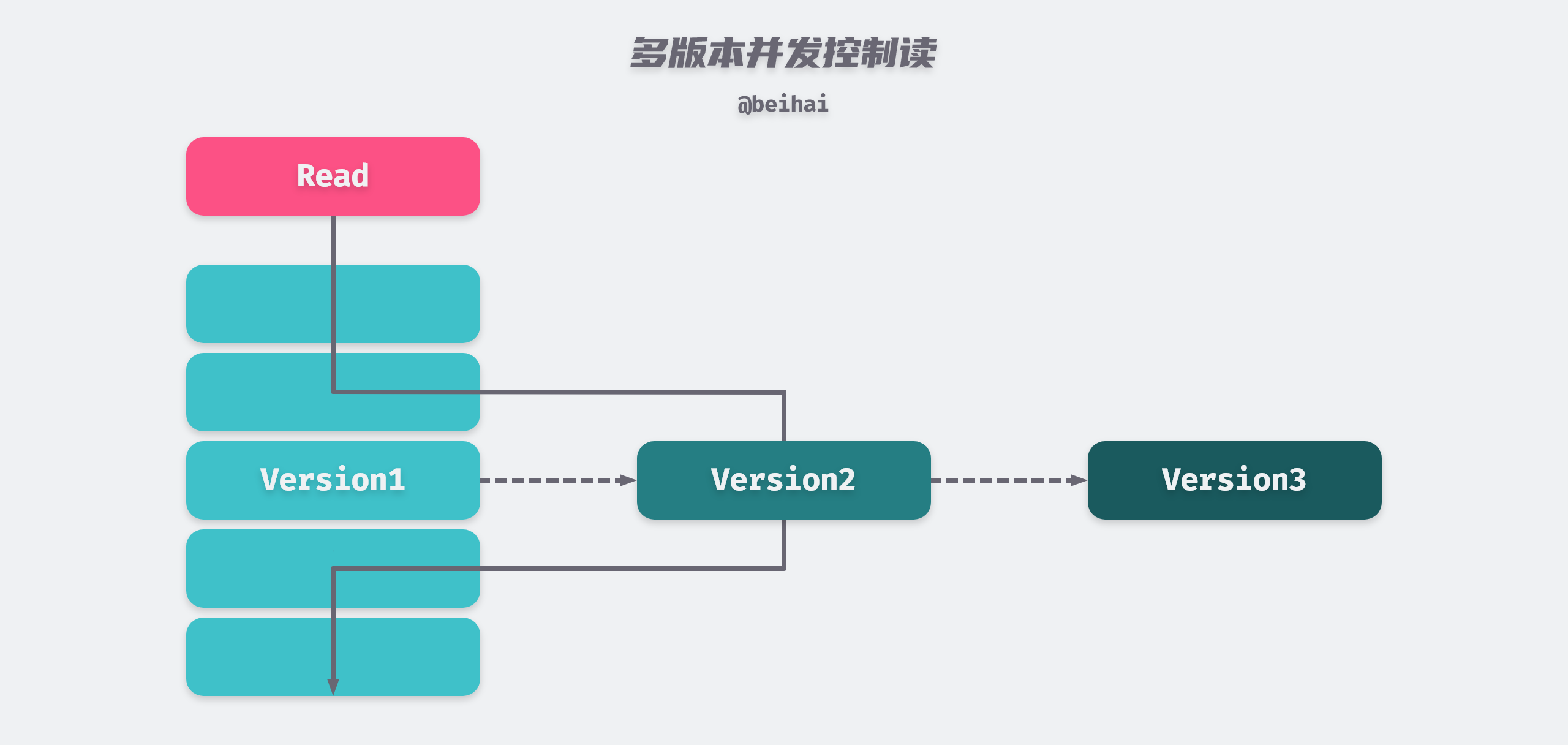
Since etcd is mainly used to store some very important metadata in distributed systems, the read operations of such metadata are much more than the write operations. Under the pessimistic locking mechanism, when a lock is occupied by a write operation, a large number of read operations will be blocked, affecting the concurrency performance, while MVCC can maintain a relatively high and stable read concurrency capability. Whenever a client wants to change or delete a data object, etcd does not modify or delete the existing data object itself in place, but creates a new version of the data object, so that the old version of the data can still be read concurrently while the write operation is in progress.
Index
To achieve multi-version concurrency control, etcd stores each version of the key-value pair in BoltDB. The Key stored by etcd in BoltDB is the revision reversion and the Value is the combination of key-value pairs sent by the client. To better understand this concept, suppose we write two key-value pairs, (key1, value1) and (key2, value2), through the read-write transaction interface, and then we call the read-write transaction interface to update these two key-value pairs, which are (key1, update1) and (key2, update2) after the update, although the two write operations update are two key-value pairs, in fact, four records are written in BoltDB.
The first part is the main reversion, which increments by one for each transaction, and the second part is the sub reversion, which increments by one for each operation of the same transaction, both of which are combined to ensure that the key is unique and incremental. In the above example, the main reversion of the first transaction is 1, and the main reversion of the second transaction is 2.
As we can see from the format of the data stored in Backend, if you want to query a key-value pair from BoltDB, you have to look it up by reversion. However, the client only knows the Key value of the specific key-value pair, but not the reversion information of each key-value pair.
To associate the original key-value pair information provided by the client with the reversion, etcd uses the btree data structure implemented by Google Open Source to maintain the mapping between the Key and the reversion. The value part of BTree stores the original Key and the value part stores a keyIndex instance. A keyIndex instance maintains all the historical revision information of a Key.
|
|
The keyIndex uses generation generation to represent the data changes of the same Key during a certain lifetime, and multiple revisions can be stored in each generation. The first time a Key value given by a client is created, the corresponding generation 0 lifecycle generation[0] is also created, and revision information is continuously added to generation[0] as the client keeps modifying the Key.
When a tombstone Tombstone is added to generation[0], it means that the life cycle of generation 0 is over. keyIndex creates a new instance of generation and adds revision information to generation[1] when the key is subsequently modified. The structure of a keyIndex is shown in the following figure.
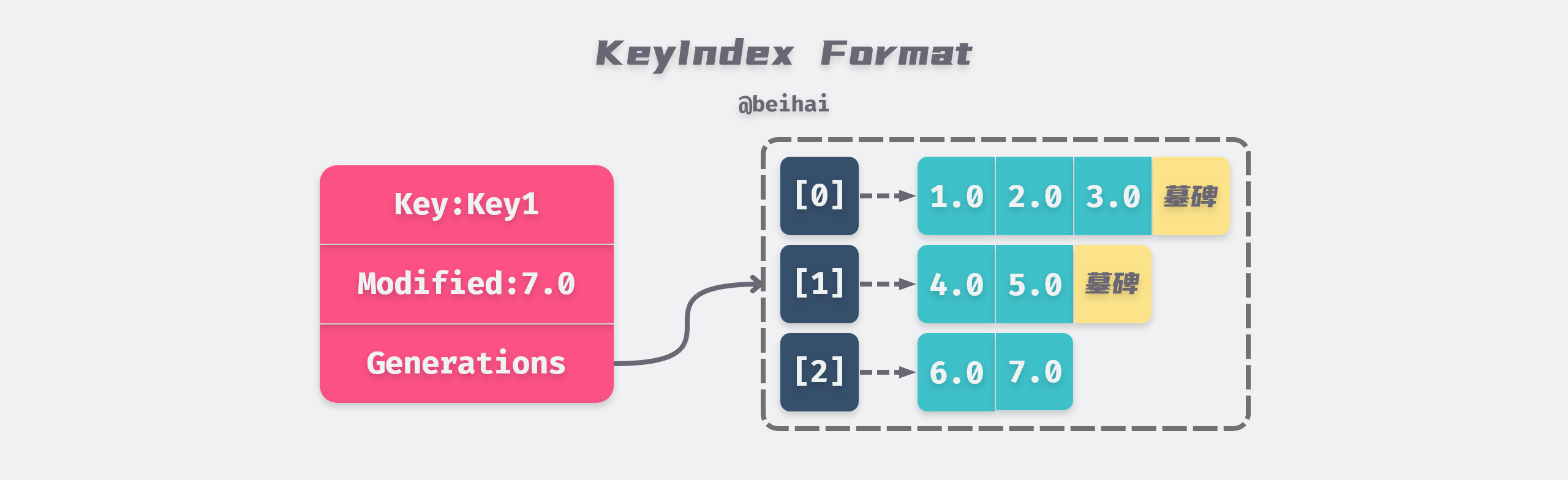
Since etcd stores the history of keyspace versions, the revision information recorded in the keyIndex will keep increasing as the client keeps modifying the key-value pairs, we can call the compact() method to compress the keyIndex to avoid performance degradation and storage space exhaustion.
When compressing the keyIndex, all revision instances with a value less than the specified value in the main part are deleted, and the compressed revision is not accessible. If there is an empty generation instance in the compression process, it will be deleted. And each Key corresponds to at least one generation instance, if all the generation instances in the keyIndex are cleared, then the keyIndex instance will be deleted as well.
Take the data maintained in the above image as an example to show the compression process.
The keyIndex structure provides two methods for querying revisions. The since() method is used to find the revision with the main part greater than the specified value in bulk, and if the query results in multiple revision instances with the same main part, only the largest revision in the sub part is returned; the get() method is used to find the largest revision with the main part less than the specified value.
The get() method will first call findGeneration() to find the generation instance of the specified main revision, the findGeneration() method will start from the last generation instance of the keyIndex, and when it finds the specified generation, it will call the walk() method to find the eligible revision from the generation.
|
|
The above is how etcd queries multiple versions of data through indexes: when a client looks for a given key-value pair, it will first find the corresponding keyIndex instance through the B-tree index maintained in memory, then find the corresponding revision information through the keyIndex, and finally find the real key-value pair data from BoltDB through the revision.
After understanding the above concepts, let’s finally see how the storage module uses BoltDB to store data.
Backend
etcd uses Backend, a design that encapsulates the implementation details of the storage engine and provides a consistent interface to the upper layers. the implementation of Backend mainly uses the API provided by BoltDB to add, delete, and check data, so in the following we focus on the implementation of the interface and do not post the code related to the operational details.
|
|
Two important concepts of Backend are ReadTx and BatchTx, which implement the interfaces for read-only and read-write transactions, respectively, where BatchTx has ReadTx embedded in it and ‘inherits’ the methods implemented by read-only transactions.
The semantics of ‘inheritance’ can be implemented in the Go language with embedded structs.
|
|
BatchTx provides two methods for updating data, UnsafeSeqPut() differs from UnsafePut() in that the UnsafeSeqPut() method adds a key-value pair to the specified Bucket with the corresponding Bucket instance set to 90% padding, which improves the utilization of the Bucket when writing sequentially.
To improve the efficiency of BoltDB writes, Backend enables a goroutine to commit all read and write transactions asynchronously (default is 100ms), which reduces the number of random writes.
|
|
Read-Only Transactions
Although after using MVCC, read requests are not locked by write requests, which greatly improves the efficiency of read operations. However, since deadlock will occur if you open two read-only and read-write transactions that depend on each other in the same goroutine of BoltDB, readTx introduces a read-write lock sync.RWLock to avoid this situation.
As you can see from the structure, readTx not only references a read-write lock txmu used to protect the read-only transaction tx, but also a read-write lock mu that protects buf, which serves to ensure that no problems occur when reading or writing data in the buffer.
Read-only transactions provide two methods for fetching data to the upper level. UnsafeRange() is used to fetch the Key or a single Key of the specified range. This method will first look up the data from the cache, and if the data in the cache does not meet the requirements, it will be queried from BoltDB via the unsafeRange() function. The UnsafeForEach() method will iterate through the cache of the specified Bucket and all the key-value pairs in the Bucket, and process these iterated key-value pairs with the passed in callback function.
Read-Write Transactions
The implementation of read-write transactions is similar to read-only transactions, but read-write transactions provide both batchTx without caching and batchTxBuffered with caching, the latter with an embedded structure of the former and an additional cache txWriteBuffer to speed up the read operations in read-write transactions.
|
|
The implementation of batchTx write delete operation is also very simple, it just calls the API provided by BoltDB to modify the data in the Bucket, so we will not repeat this aspect.
As BoltDB executes read/write transactions for a long time, it will cause other read/write transactions to hang and wait, so Backend specifies the maximum number of operations in a read/write transaction, and when the threshold is exceeded, the current read/write transaction will be committed automatically.
Although MVCC has solved the problem of data conflicts in concurrent transactions very well, deadlocks and concurrent write conflicts can still occur during operation of BoltDB. etcd combines locking mechanisms to solve this problem: read-write locks are used in read-only transactions and mutually exclusive locks are used in read-write transactions. The good thing is that the probability of lock contention is low and does not block other transactions for a long time.
Linear Consistency Read
A distributed system that correctly implements the consensus algorithm does not mean that linear consistency is achieved; the consensus algorithm can only guarantee that the state of multiple nodes is consistent for a given object. In the etcd implementation, a successful write operation simply means that the data has been dropped through the pre-written log, but the behavior of the state machine Apply log is asynchronous, and multiple nodes cannot guarantee that a log will be applied to the state machine at the same time, meaning that each node cannot be consistent in ‘real time’, so reading the state machine at this point is likely to read out-of-date data.
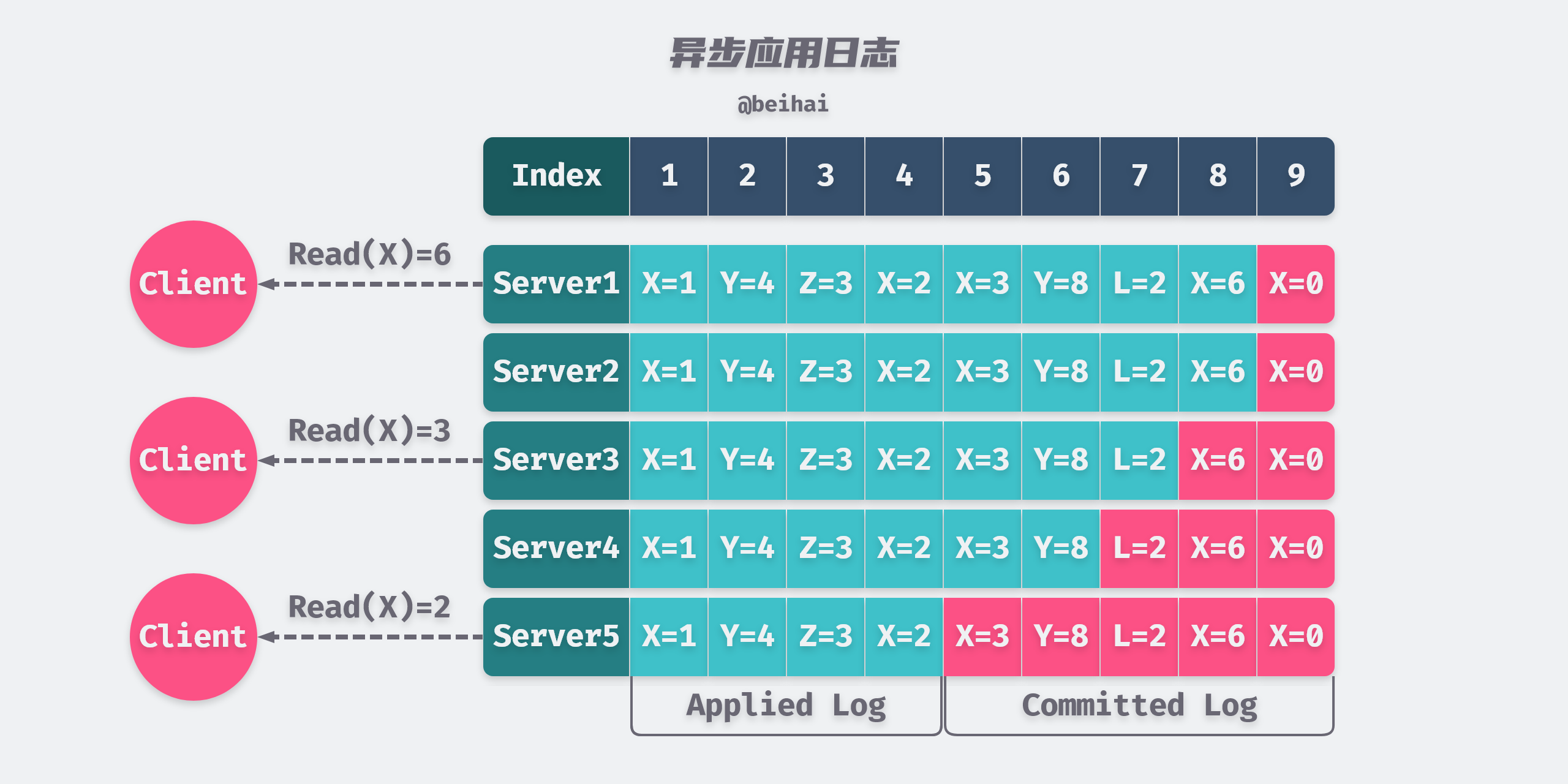
In addition, the Leader’s state machine may not be up-to-date due to possible network partitioning, Leader node switching, and so on. If the Leader does not notice that its status has changed when processing requests, this can lead to a violation of linear consistency throughout the system.
Data Consistency
Data consistency is a concept that originally existed in database systems. The consistency problem in database systems refers to whether the logic between associated data is complete and correct, and usually database systems will use transactions to ensure the consistency and integrity of data. However, data consistency in distributed systems refers to the problem of how to guarantee the consistency of data when data is stored in multiple copies.
In the distributed field, the security of data is no longer guaranteed by hardware only, in order to achieve system disaster recovery and improve the overall performance, data will be written to multiple copies at the same time, and data synchronization between master copies is performed through replication technology to ensure the security of data. When the database writes records to multiple replicas at the same time, how to ensure the data consistency between multiple replicas is called data consistency.
Consistency models in distributed systems can be roughly divided into three categories.
- Linear consistency: when an update operation is executed successfully on a certain replica, all subsequent read operations should be able to obtain the latest data.
- Sequential consistency: when an update operation is executed successfully on a certain replica, the read operations of other processes may not be able to obtain the latest data, but the order of the different values of that data read by each process is consistent.
- Final Consistency: When updating a certain data, it takes a delay for the user to read the latest data.
Linear consistency, also known as strong consistency and strict consistency, is the highest consistency model that a program can achieve. Linear consistency requires that any read operation read the most recent write of some data, and that all processes in the system see the order of operations in the same order as they would under the global clock . Once a value is changed, then no matter how small the time interval between subsequent read operations and this write operation, and no matter which node performs the read operation, the value read afterwards is the newly changed value; similarly, if a read operation is performed, then no matter how fast the subsequent write operation is, the value read by that read operation is still the original value.
Because the global clock required for linear consistency results in a large performance loss, sequential consistency drops the global clock constraint and is implemented with distributed logical clocks instead. All processes in the sequential consistency model see all modifications in the same order. The read operation may not get the previous write updates to the same data from other processes in time, but the order in which each node reads the different values of that data is the same.
Final consistency is also weak consistency, which does not guarantee that the same data on different nodes are the same at the same moment, but the same data on different nodes always change in the direction of convergence as time migrates. There are many kinds of eventual consistency, like causal consistency and monotonic read consistency are its variants.
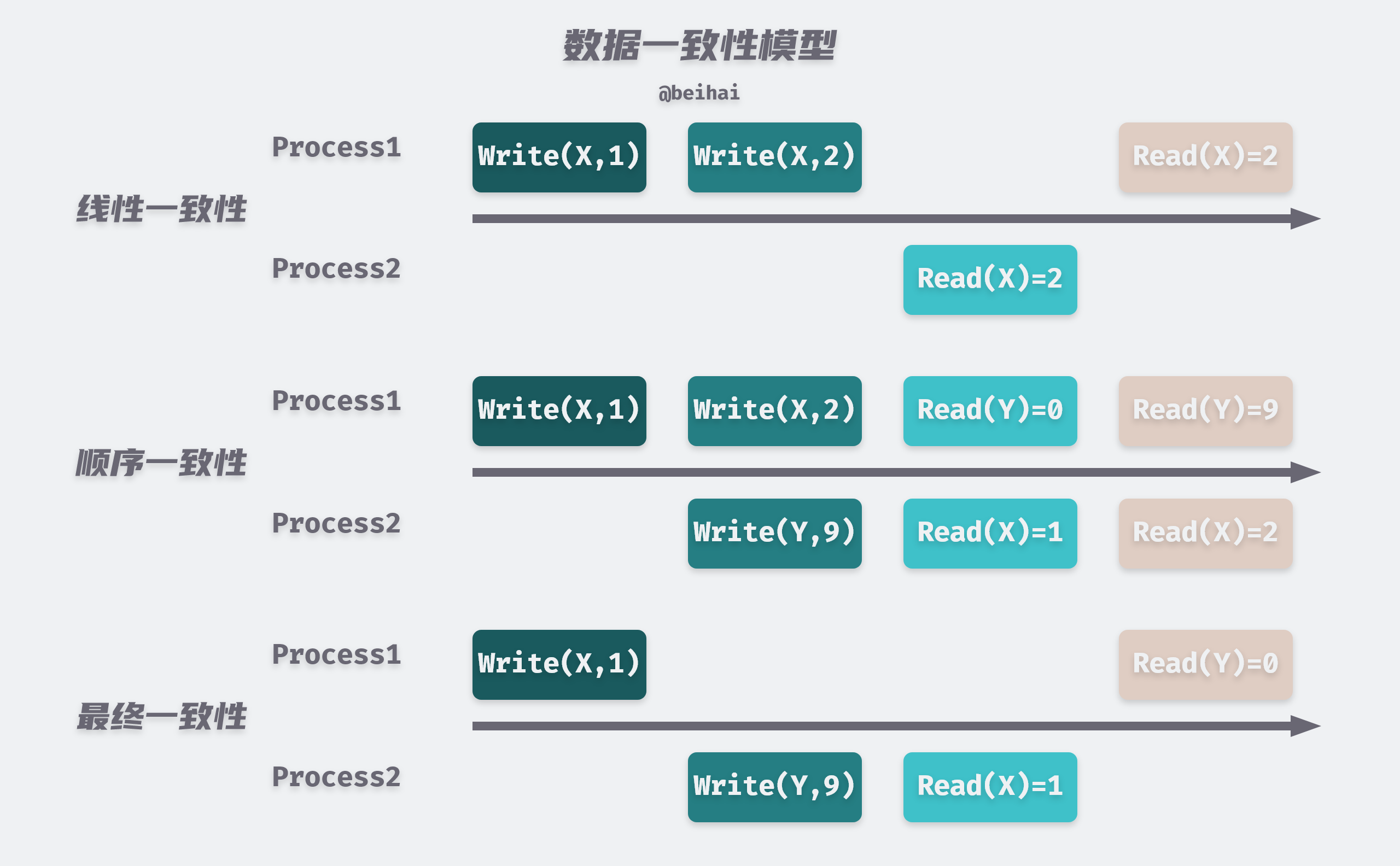
Raft is a strongly consistent consensus algorithm in the distributed domain, whose goal is to achieve linearized semantics. When one of the nodes receives a set of instructions from a client, it must communicate with the other nodes to ensure that all nodes receive the same instructions in the same order, and eventually all nodes will produce consistent results, just like a machine. etcd implements linear consistency using the underlying scheme provided by Raft, and this aspect is described in detail below.
ReadIndex
etcd uses the ReadIndex mechanism to solve the above problem: although the state machine applies the logs asynchronously, the logs that have been submitted satisfy linear consistency, so the read requests can also satisfy linear consistency as long as they wait until they are all applied to the state machine before executing queries.
The execution flow of the ReadIndex mechanism is as follows.
- record the
CommittedIndexof theAt this timecluster before the read operation is executed, asReadIndex. - send a heartbeat message to Follower, and if more than a quorum of nodes respond to the heartbeat message, then the authority of the Leader node is guaranteed.
- wait for the state machine to be applied to
ReadIndex‘at least’, i.e.AppliedIndex>=ReadIndex. - execute the read request and return the result to the Client.
Read-only request handling
Read-only requests for etcd are handled by the EtcdServer.Range() method. Each request needs to determine the consistency level of the client configuration, and if linear consistency is required then the function linearizableReadNotify will be executed and will keep blocking in this function until the linear consistency read condition is met.
|
|
The linearizableReadNotify function sends an empty structure to the channel readwaitc and notifies the send message function that it is safe to execute the read request after the listener function has finished its task.
|
|
The readwaitc listening is done in a separate concurrent linearizableReadLoop that loops through the readwaitc signals, calls the Raft module to execute the readIndex() mechanism when a new request arrives, and then waits for the ReadIndex to be applied to the state machine.
|
|
Raft Consensus
The Raft protocol library performs different processing flows for different identities of nodes. Depending on the identity of the node, the raft.step method will point to a different processing function.
If a Follower node receives a read request from a client, the Follower node forwards the read request to the Leader for processing.
If the Leader receives a read request, the Leader first saves the request in the ReadOnly queue and sends a heartbeat message to the other nodes. When the Leader receives a heartbeat message from more than half of the nodes, it indicates that the ReadIndex has passed the cluster consensus and will call the readOnly.advance() method to add the read state to the readStates queue. At the same time, readStates are continuously encapsulated into Ready structures in the node.run() method for processing by the application layer.
|
|
Application layer processing
The raftNode.start method of the previous article will get the Ready structure wrapped in the Raft module and send only the last readState at a time to the concurrent linearizableReadLoop via the channel readStateC, because the This is because the last read-only request encapsulated in Ready already satisfies the ReadIndex requirement, and then all the previous ones do. Next, wait for the application to be applied to the state machine asynchronously before executing the read request.
|
|
Summary of this section
By analyzing a complete read operation, it can be seen that etcd needs to satisfy the following two conditions in order to reach a linear consistent read.
- Have the Leader handle read-only requests: If the Follower receives a read request, it needs to forward the request to the Leader for processing.
- Ensure the validity of the Leader: The Leader needs to send a broadcast to the cluster, and if it can receive a response from most nodes, it means that the identity of the Leader node is valid, and this process is to ensure that the data of the Leader node are all up-to-date.
Since the ReadIndex mechanism needs to wait for cluster consensus and state machine application logs, especially the consensus process will bring some network overhead, in order to improve the overall performance of read-only requests, etcd also provides an optimized consistency algorithm called LeaseRead: the Leader will take a smaller lease period than ElectionTimeout. Because no election occurs during the lease period, it ensures that the identity of the Leader does not change, so the consensus step in ReadIndex can be skipped, reducing the latency caused by network overhead.
The correctness of LeaseRead is tied to the time implementation, and it is possible to read expired data due to the error of CPU clocks of different hosts.
Implementing linear consistency for read requests in etcd must go through the Raft consistency protocol, and this approach must come at some performance and latency cost. If there is no particularly strong requirement for data consistency, the consistency mode can be configured to be Serializable on the client side. read-only requests in Serializable mode can be provided by any etcd member, but etcd may read out-of-date data as a result.
Summary
The above is the implementation and rationale for the most important parts of etcd. As you can see, etcd’s consensus module handles many of the boundary conditions, adding to the high availability status of the cluster. Although some performance compromises are made in order to achieve strong consistency, etcd also provides additional options that can be freely configured for different demand scenarios. etcd also provides a very good implementation of the Raft algorithm, and analysis of the source code is very helpful for a deeper understanding of Raft.
etcd uses the CSP concurrency model provided by Go in much of its source code. This way of communicating using channel is not intuitive to write, and the context of the code does not reflect the sender or receiver of the message, so extra care should be taken when reading the source code. However, in general the code of the etcd core module does not change much and is suitable for reading and learning.