In distributed systems and microservice architectures, different systems or different nodes of the same system share the same or a set of resources, then access to these resources often requires mutual exclusion to prevent interference with each other and ensure consistency.
Distributed locks provide mutually exclusive access to shared resources in a distributed environment, and businesses rely on distributed locks to pursue efficiency gains or rely on distributed locks to pursue absolute mutual exclusivity of access. At the same time, in the process of accessing distributed lock service, the cost of integration, service reliability, distributed lock switching accuracy and correctness should be considered, and the correct and reasonable use of distributed locks is something that needs to be continuously thought about and optimized.
Overview
In general, distributed locks need to satisfy the following properties.
- exclusivity: at any given moment, only one client can hold the lock.
- Deadlock-free: even if one client crashes while holding a lock and does not actively unlock it, other subsequent clients are guaranteed access to the lock.
- locking and unlocking must be the same client, and the client cannot release the lock added by other clients.
- fault tolerance: a few nodes fail, the lock service can still provide external unlocking services.
Among them, the deadlock of distributed locking is different from the concept of deadlock of programming language to provide locking, the latter deadlock describes the situation where multiple threads are blocked forever due to waiting for each other, the deadlock of distributed locking means that if the request execution is unexpectedly exited for some reason, resulting in the creation of a lock but not releasing it, then the lock will always exist to the extent that subsequent lock requests are blocked. The TTL policy has some drawbacks, because if the process executing the task is not finished, but the lock is automatically released because of the TTL expiration, it may be re-locked by other processes, which causes multiple processes to get the lock at the same time.
Redis Distributed Locks
Redis Standalone Locks
Redis standalone locks are very simple to implement, just execute the command SET key random_value NX PX 60000 to get a lock with a TTL of 60s. The Redis lock requires the client to implement an algorithm that ensures that all lock requests generate a random unique value, and that the value is stored so that when the client finishes executing the code to release the lock, it first obtains the Redis value and compares it to the locally stored value. Only when the two match will the lock be released by the DEL operation.
The random value is to ensure that a lock held by a client is not incorrectly released by another client. Imagine a scenario where client A gets a lock on key1, but some time-consuming operation blocks it for a long time, and Redis automatically releases the lock after the timeout period is reached; then client B gets a lock on key1, and client A finishes its operation and tries to delete the lock on key1 that is already held by client B. Using the above atomic operation script ensures that each client uses a random string as a “signature” and that each lock can only be removed and released by the client that obtained it.
Thanks to Redis’s memory-based data storage and excellent programming, standalone Redis can support 10w+ QPS requests, which can satisfy most scenarios. The problem with standalone locks is that, first, they are not fault-tolerant. If Redis has a single point of failure, all services that need to obtain a distributed lock will block, and second, even if Redis uses a master-slave replication architecture, the latest data is not replicated to the slave node when the master node crashes, making the slave node lose some data when it takes over the master node, which violates the exclusivity of locks.
Redlock Distributed Locks
Redlock is a cluster-mode Redis distributed lock given by Redis author antirez, and can be seen as an extension of the single-computer locking implementation. It is based on an implementation of N completely independent Redis Master nodes that do not replicate data or use any implicit distributed coordination algorithm between them. For a client to obtain a lock, the following steps are performed.
- the client obtains the current time in milliseconds.
- the client requests locks on N nodes sequentially with the same key and random_value. In this step, the client requests a lock on each Master with a timeout that is much smaller than the total lock TTL, e.g. if the lock auto-release time is 10s, the timeout for each node lock request may be in the range of 5 to 50ms. The timeout prevents the client from blocking on a downed Master node for too long, and if a Master node is unavailable, the client will try the next Master node as soon as possible.
- the client calculates the time taken to acquire the lock in the second step, and if the client successfully acquires the lock on more than N/2 + 1 Master nodes and the total time consumed does not exceed the TTL, then the lock is considered to be successfully acquired.
- if the lock acquisition is successful, then the true TTL of the lock is the original TTL - the total time consumed.
- if the lock acquisition fails, either because no more than half of the locks were successfully acquired (N/2+1) or because the total time consumed exceeds the lock release time, the client releases the lock to each Master node, including those that did not acquire the lock.
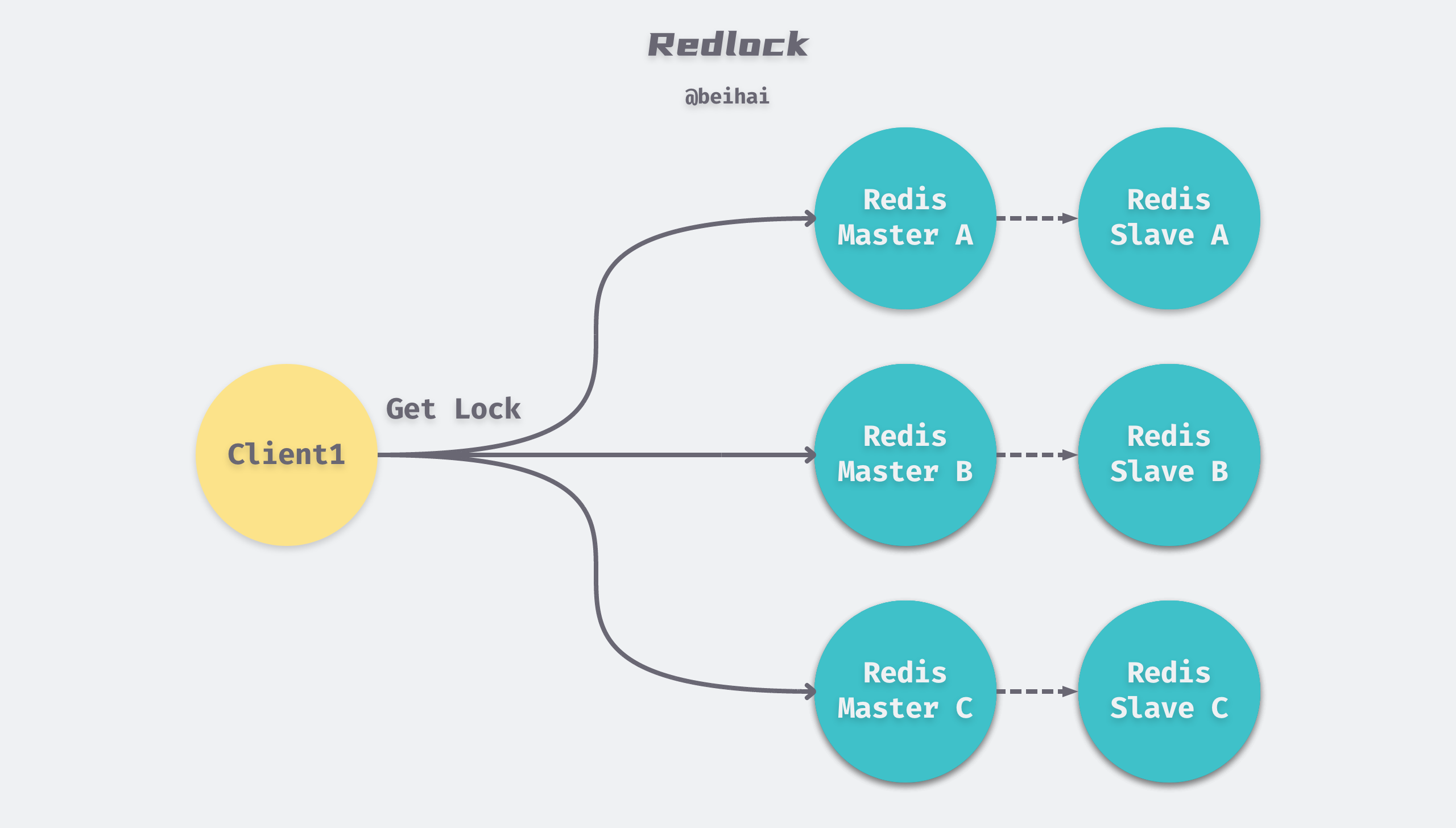
When Redlock fails to acquire a lock, it will keep retrying after a random delay until the maximum number of times. The random delay is used to avoid the situation where different clients retry at the same time, resulting in no one getting the lock.
Although Redlock uses a half-write policy to guarantee the mutual exclusivity of the lock, it relies heavily on the client to repeatedly request the lock service. If our node does not have data persistence enabled, suppose there are 5 Redis nodes: A, B, C, D, E, and the following sequence of events occurs.
- Client1 successfully locks A, B, and C and obtains locks successfully, but D and E are not locked.
- node C crashes and goes down, and the lock Client1 put on C is lost.
- after node C reboots, Client2 locks C, D and E, and obtains locks successfully.
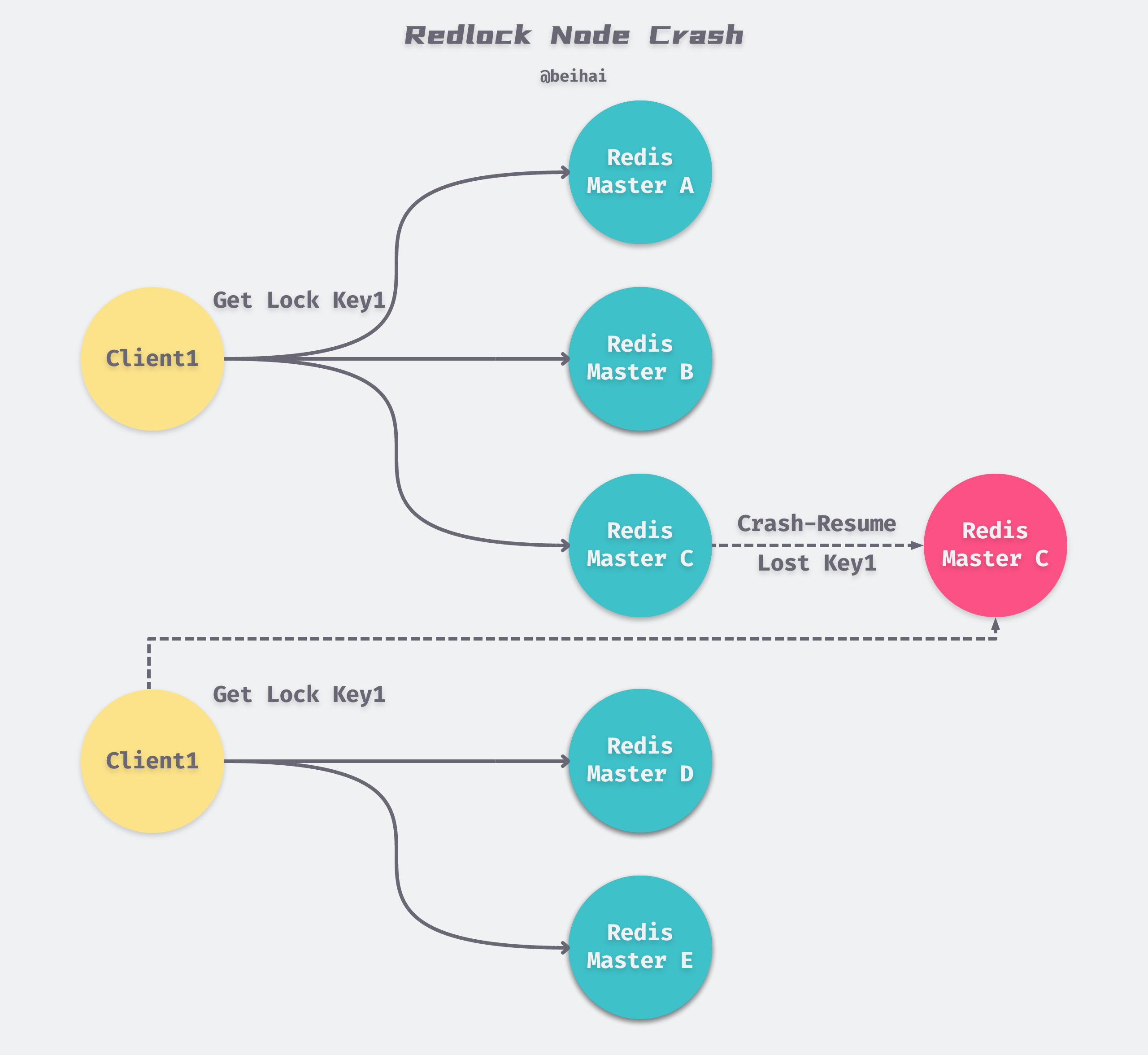
Thus, Client1 and Client2 both acquire locks at the same moment. To solve this problem, Redis author antirez offers two solutions.
-
Enabling AOF persistence: Because the expiration mechanism of Redis keys is timestamp-based, time still passes during node downtime, and the lock state is not contaminated after restart. However, AOF data is written back to disk once per second by default, so some data may be lost before it is written to disk. So we need to configure the policy to fsnyc = always, but this will slow down the performance of Redis.
-
Another way to solve this problem is to specify a Max TTL for the Redis lock service. When a node is restarted, the node is unavailable during the Max TTL, so that it does not interfere with the locks that have been applied, and the node will rejoin the cluster only when all the historical locks before it crashes have expired. The disadvantage of this scheme is that if the Max TTL is set too long, the restarted node will be unavailable for several hours, even if the node is normal.
Controversy
Redlock is a distributed lock that does not use a consensus algorithm and is implemented based on time, which has led many people to doubt its reliability. Martin Kleppmann, author of DDIA, published an article How to do distributed locking that critiqued Redlock’s security from two perspectives.
- Redlock is built on a timestamp-based system model, and it is difficult for multiple servers to guarantee consistent timing, which makes the actual expiration times of locks different.
- distributed locks with automatic expiration must provide some fencing token (uniqueness constraint) mechanism, such as monotonically increasing IDs, to guarantee mutual exclusivity over shared resources, and Redlock does not provide such a mechanism.
The fencing token mechanism mentioned in the second point will be discussed in more detail in the section on Chubby below.
Subsequently antirez also responded in Is Redlock safe?. The first case is discussed here first: when the clock jumps, the time of the current server can suddenly become larger or smaller, which can affect the lock expiration time. For example, Client1 successfully locks A, B, and C, but the time of node C suddenly jumps forward by 5 seconds to expire early, and then Client2 successfully locks C, D, and E. In this case, the mutual exclusivity of locks is violated.
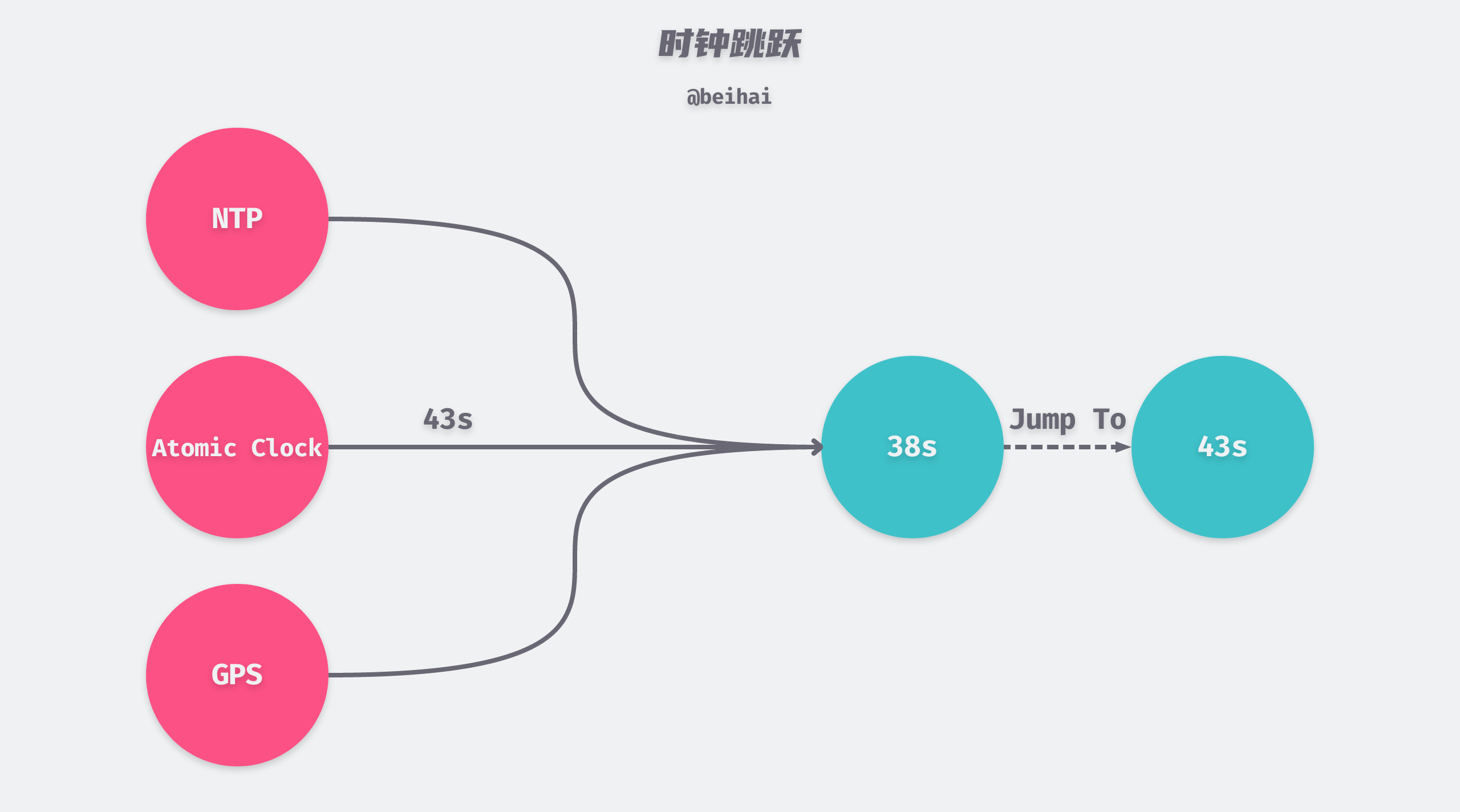
antirez believes that the first case can be avoided by reasonable operation and maintenance means: replace a large clock jump in a clock synchronization process with multiple small clock jumps, and ensure that the time difference between the servers is kept as low as possible. In fact, from antirez’s response, we can see that redlock is not able to solve the problem of clock desynchronization between servers.
For the second point, antirez argues that the order of lock IDs is independent of the order in which operations are actually executed, and that it is sufficient to guarantee mutually exclusive access. Therefore, it does not matter whether the lock ID is incremental or a random string. Redlock does not provide an incremental fencing token, but the same effect can be achieved with the random value generated by Redlock. This random string is not incremental, but it is unique. So Redlock can guarantee the uniqueness constraint of the lock.
Summary
In summary, Redlock is a spin-based distributed locking implementation, which is an asynchronous replication-based distributed system that requires clients to repeatedly request locking services to determine whether a lock can be obtained.
Redlock assumes a fine-grained lock service through a TTL mechanism, and is suitable for services that are time-sensitive, expect to set a short validity period, and have a relatively manageable impact on the business when a lock is lost.
etcd Distributed Locks
etcd is a distributed key-value storage service based on the Raft consensus algorithm, and provides distributed locking capabilities. A etcd cluster contains several server nodes, and a Leader is elected through a ’leader election mechanism’. All write requests are forwarded to the Leader, which manages log replication for consistency. The other nodes are actually copies of the current node, they only maintain a copy of the data and update the database they hold when the master node is updated, and only respond to read requests from clients.
A distributed system based on consensus algorithms has built-in measures to prevent brain-fractured and expired data copies, thus enabling linear data storage, i.e., the entire cluster behaves as if there is only one copy of the data and all operations on it are atomic. The client ends up with the same result no matter which node it sends the request to.
etcd lock usage
etcd can set a lease for a stored key-value pair, which will expire and be deleted when the lease expires. Clients can renew the lease before it expires. While a client is holding the lock, other clients can only wait. To avoid the expiration of the lease while waiting, clients need to create a timed task KeepAlive as a “heartbeat” to keep renewing the lease to avoid the lock expiring before the processing is completed.
If the client crashes while holding the lock, the heartbeat will stop and the key will be deleted due to lease expiration, thus releasing the lock and avoiding deadlock.
|
|
To make it easier to understand the use of etcd locks, a simple example program is posted below, where go1 and go2 occupy the same lock. Even if go1 only sets a TTL of 2s and releases the lock after 5s, the client can automatically renew the lock to ensure its exclusivity.
|
|
etcd Locking Mechanism
In addition to the lease mechanism mentioned above, etcd also provides the following three features to secure distributed locks.
unified prefix
In the above example program, two Goroutines compete for a lock named /test_lock, and the actual keys written by etcd are key1/test_lock/LeaseID1 and key2/test_lock/LeaseID2 respectively. The LeaseID is a global UUID generated by the raft protocol broadcast to ensure the uniqueness of the two keys.
The unified prefix serves the same purpose as the random value generated by the client in Redlock, ensuring that the lock will not be erroneously deleted by other clients.
Revision
etcd generates a 64-bit Revision version number for each key, which is incremented by one for each data write operation, so Revision is globally unique and incremental. The size of the Revision gives an idea of the order in which etcd Server processes writes.

In the above program example, both keys will be written successfully, but their Revision information is different. The client needs to obtain the Revision number of all keys prefixed with /test_lock by interval query, and determine whether it has obtained the lock by the Revision size.
When implementing distributed locking, if more than one client is competing for the lock at the same time, they can get the lock in order according to the Revision number size to avoid “Thundering herd problem” and achieve fair locking.
Watch
The Watch mechanism supports Watching a fixed key and Watching a range of intervals. When the key being watched changes, the client will receive a notification.
When implementing distributed locking, if the locking fails, the pre-key with the smallest difference in Revision can be obtained from the Key-Value list returned by the interval query and listened to it. When the DELETE event of the pre-key is watched, it means that the pre-key has been released and the lock can be held at this time.
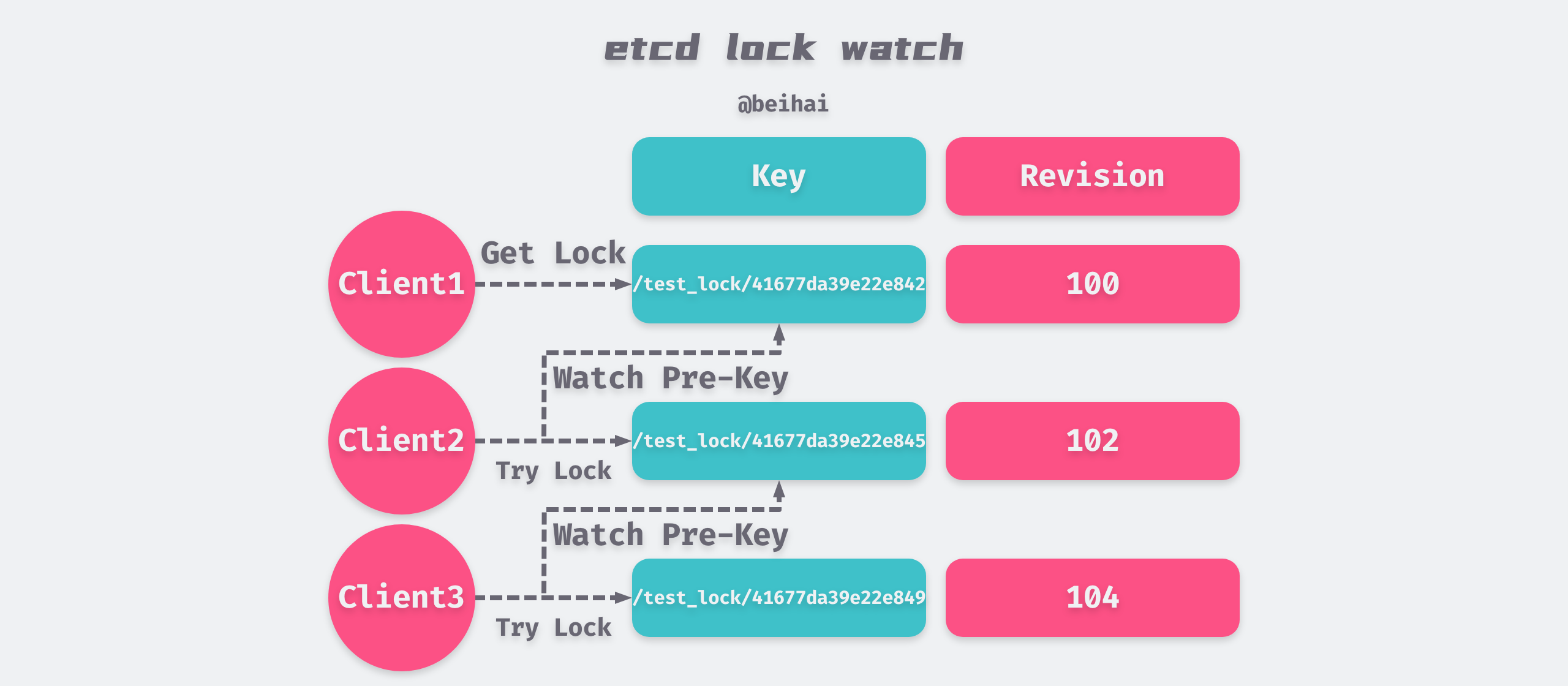
etcd lock implementation
After understanding the concept of the four mechanisms described above, it is simple to look at the process of locking and unlocking etcd:
- assemble the lock name and LeaseID that needs to be held as the actual key written to etcd.
- perform a put operation to write the created key binding lease to etcd, and the client needs to record the Revision so that it can determine whether it has obtained the lock in the next step.
- query the list of key-value pairs by prefix, if its Revision is the smallest in the current list, it is considered to have obtained the lock; otherwise, listen to the delete event of the previous key in the list whose Revision is smaller than its own, and once it listens to the pre-key, it obtains the lock.
- After completing the business process, delete the corresponding key and release the lock.
|
|
As you can see, a Context is passed in when locking, which allows etcd to actively release the lock if the overall request times out during locking or if the higher-level logic actively exits, reducing the idle period of the lock.
Similarly, although only the pre-key with the smallest difference in Revision is watched when locking, the exclusivity of the lock is broken if the client of the pre-key releases the lock while other clients are still holding it. Therefore, the waitDeletes() function, after listening to the pre-key’s deletion event, will still visit etcd to determine if there are other clients ahead of it that still hold the lock and listen for their deletion events.
|
|
Summary
Distributed locks based on ZooKeeper or etcd implementations are listening distributed locks, where the client only needs to watch a key and the lock server notifies the client when the lock is available. The more complex consensus logic is done on the server side, without the need for the client to keep requesting lock services.
Comparing redlock and etcd lock implementations, we can see that redis itself does not have a consensus process, and relies more on the client’s constant rotation of requests, and cannot solve the problem of clock synchronization and clock jumps between different machines. etcd, on the other hand, uses a globally unique and incremental Revision to rank the order of lock acquisition and a consensus algorithm to guarantee data consistency between nodes, solving the problem of different key expiration times between different nodes of redlock.
Distributed locking is a more complex application scenario for etcd. Its drawback is that Grant (generate lease ID), Unlock, Expire and other operations have to go through a raft protocol consensus, Lock process may require multiple query operations, which is costly, and watch multiple keys at the same time will also affect the performance of the cluster. In a specific test environment Performance | etcd, etcd can handle 50,000 write requests per second, but for complex distributed lock implementations, it usually cannot support QPS over 10,000. for complex distributed lock implementations.
On the whole, etccd implementations are more secure, but their performance is not outstanding. These locks often assume coarse-grained locking services through a lease/session mechanism, and are suitable for services that are sensitive to security, want to hold locks for a long time, and do not expect lock loss to occur.
Chubby
Chubby is a distributed locking service designed by Google to provide coarse-grained locks, and is used by both GFS and Bigtable to solve problems such as the election of master nodes. Since Chubby is an internal Google service, we can only get a glimpse of it from this 2006 paper The Chubby lock service for loosely-coupled distributed systems to get a glimpse of its design ideas.
Similar to etcd and zookeeper, Chubby uses the Paxos algorithm to ensure data consistency. In a Chubby cluster, only the master node provides read and write services to the outside world. The client gets the location of the master node by sending requests to the replicas, and once it gets the location of the master node, it sends all read and write requests to the master node until it no longer responds. Write requests are propagated to all replicas through the consistency protocol, and the current write is considered to be acknowledged when most nodes in the cluster have synchronized the request.
program stalls
The difference is that Chubby goes a step further in lock reliability guarantees on top of them.
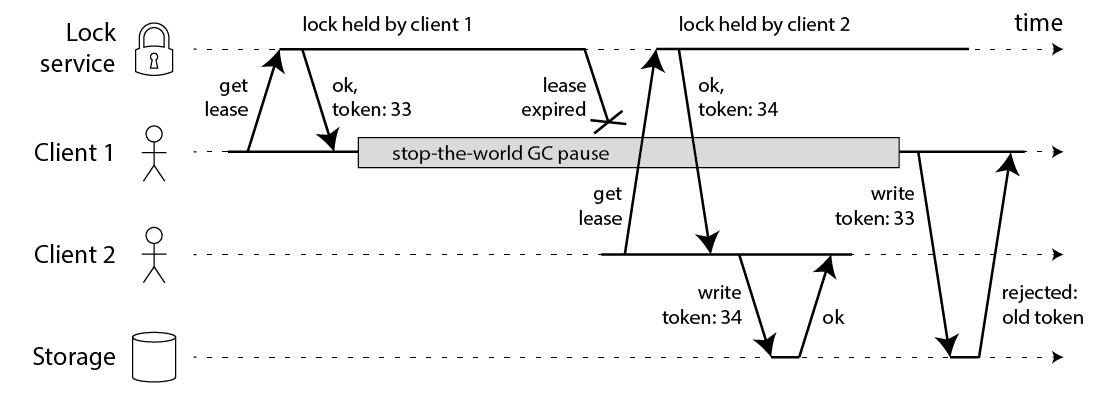
Regardless of the programming language our program is written in, it is possible for a long program stall to occur due to GC, system scheduling, network latency, etc., resulting in the timeout and automatic release of an already held distributed lock, which can then be acquired by other instances and enter the critical zone again, breaking the exclusivity of the lock. To this end Martin also gives an example of a Redlock failure triggered by a client-side GC pause:
- Client1 initiates a lock request to the Redis cluster.
- each Redis node has returned the result of the lock acquisition to Client1, but Client1 enters a long GC pause before receiving the result of the request.
- the lock has expired on all Redis nodes.
- Client2 has obtained a lock after
- Client1 recovers from the GC pause and receives the request result from each Redis node in step 2; Client1 thinks it has successfully acquired the lock.
- both Client1 and Client2 are holding the same lock.
Martin’s example is not only applicable to Redis, but also to distributed locks based on zookeeper, etcd and other implementations. If the heartbeat message does not reach the etcd server in time due to network latency or GC, the lock will fail prematurely, resulting in multiple clients holding the lock at the same time.
sequencer
For this scenario, to ensure that locks can eventually be dispatched, Chubby gives a mechanism to alleviate this problem called a sequencer. the holder of a lock can always request a sequencer, a three-part byte string consisting of
- The name of the lock.
- the mode of acquisition of the lock: exclusive or shared lock.
- the lock generation number, a 64-bit monotonically increasing number equivalent to a unique identification ID.
After the client gets the sequencer, it passes it to the resource server when it operates on the resource. Then, the resource server is responsible for checking the validity of the sequencer. The check can be done in two ways.
- calling the API
CheckSequencer()provided by Chubby and passing the sequencer to Chubby for validity checking to ensure that the lock held by the client is still valid for resource access. - compare the size of the sequencer from the client with the latest sequencer currently observed by the resource server, and deny it to operate on the resource if the lock generation number is smaller.
The second of these is similar to the fencing token uniqueness constraint described by Martin, which artificially sorts the order of client operations and acquires locks in that order. Even if the exclusivity of the lock is broken for various reasons, if a client with version number 34 has updated the resource, then any operation with a version number smaller than his is not legal.
The disadvantage of the above two Chubby solutions is that they are intrusive to the requested resource system, and if the resource service itself is not easily modified, Chubby also provides a lock-delay mechanism: Chubby allows a client to specify a lock-delay time value for the lock it holds, and when Chubby finds that the client is passively disconnected, it does not When Chubby discovers that a client has been passively disconnected, it does not immediately release the lock, but prevents other clients from acquiring it for the time specified in the lock-delay.
The lock-delay mechanism is designed to give the client that previously held the lock sufficient time to complete operations on the resource before assigning the lock to a new client.
Summary
To deal with lock failures, Chubby provides three handling options: CheckSequencer() checksum, comparison with the latest sequencer at the last processing, and the lock-delay mechanism, which allows the resource server to use it to provide stronger security guarantees when needed.
The drawbacks of Chubby are also obvious. The first two options require the resource server to customize the function to check if the lock is still valid, and such a modification is not necessary for many systems unless the system requires a high level of mutual exclusivity.
Summary
This article first discusses some of the features that distributed locks must have, then introduces specific implementations of Redlock and etcd distributed locks, and finally discusses Google Chuby’s solution in the case of exclusive lock failure due to program stalls, and references Martin and antirez’s discussion of distributed locks.
So far, there is no solution for distributed locks that guarantees complete security, and even Chubby requires a third-party service to double-check the validity of locks. In Martin’s critique of Redlock, he also makes the insightful point that there are two uses for locks.
- For efficiency: to coordinate clients to avoid duplication of work, even if the lock occasionally fails, it just does some operations one more time without other undesirable consequences, such as sending the same email over and over again; if a distributed lock is used for efficiency, allowing for occasional lock failures, then using a Redis standalone lock is sufficient, simple and efficient, and Redlock is an overweight implementation (Redlock also improves the availability of locking services; Redis standalone locks cannot avoid single points of failure).
- For correctness: similar to common in-memory locks, lock failures should not be allowed under any circumstances, as they can mean data inconsistency, data loss, file corruption, or other serious problems; if distributed locks are used in very strict situations for correctness, then do not use Redlock, which is not an algorithm that can strictly Instead, consider something like Zookeeper/etcd.