In many systems, to decouple, or to handle tasks that take a long time (for example, some network requests may be slow, or some requests are CPU-intensive and need to wait for a while), we usually introduce task queues. A typical task queue consists of the following three parts.
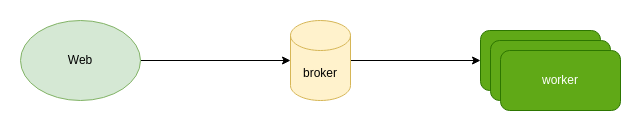
- The first part is the producer, there are two common ones, one is triggered by the user, for example, in web applications, the user needs to send a request to the mail provider when verifying the mailbox; the other one is triggered by the machine, for example, the timing task, I generally call it scheduler.
- The second part is the message broker, which is a middleware. broker is used to persist messages and provide some functions such as ACK, timeout retry, etc. It is mainly used to save various message/task related states.
- The third part is the consumer, which is usually a worker in the application. worker is responsible for taking the corresponding message or task from the broker and executing the corresponding code to consume it according to the category.
Common brokers
Typically, we use these middleware as brokers (there are other options, but they are less common).
- Redis
- SQS
- RabbitMQ
- RocketMQ
- Kafka
In general, we require brokers to support the following features.
- persistent, can not broker down, the message is lost
- FIFO (or roughly ordered), which ensures that tasks are basically consumed in queue order, some can guarantee strictly ordered, some can only guarantee roughly ordered
- Guaranteed consumption once / minimum consumption once / ACK, so that the task can be guaranteed to be consumed
- priority Priority, so that you can distinguish the priority of different functions, if the broker does not support, you can also configure multiple queues in the framework layer to achieve
- dead letter, used to store the execution of some tasks failed
- delayed tasks, used to execute some tasks that need to wait for a period of time
Not all brokers have these features, for example Redis has no ACKs and no priority, but Redis is still adequate for everyday use.
enqueue blocking and dequeue blocking
In both enqueue and dequeue, we can choose whether we want to block or not. This depends on our business scenario. For example, when the queue is full, enqueue blocking will cause the corresponding web request to get stuck; correspondingly, when the queue is empty, dequeue blocking will cause the consumer to block. For general applications, we will choose dequeue blocking.
Queue Monitoring
For the task queue itself, we might want to do some monitoring, mainly including.
- Health checks
- Number of workers, status
- Total number of tasks/number and percentage of tasks in queue, completed, failed, executing, delayed
- Number of queues/number of tasks in each queue and percentage
- Task execution time, status
Flow peak cutting
When we do monitoring, occasionally we will see some traffic peaks, and this time it involves a problem: flow peak cutting
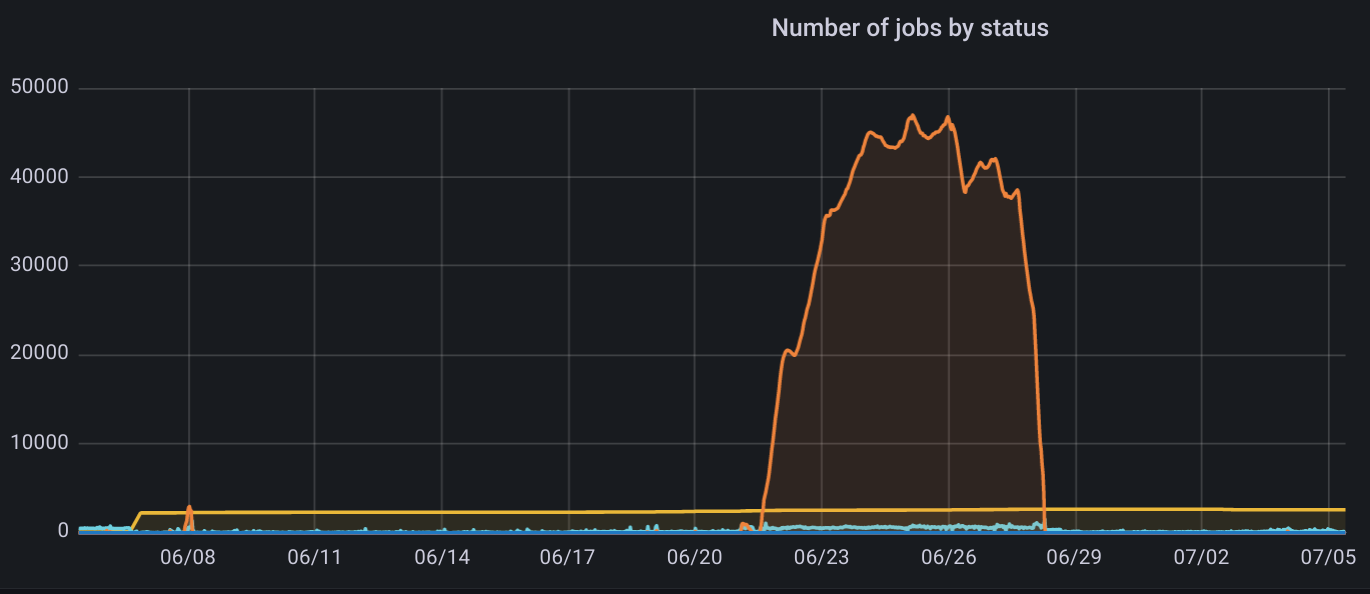
When there is a traffic spike, it is usually a sudden surge of users or a promotion in progress. There’s not really a good way to do this. Usually, if it is a promotion, which is expected, there are only two things we can do.
- Control the traffic at the application level and limit the speed. This will not generate a lot of tasks.
- Scaling in advance, scaling the worker machines in advance (usually horizontally, i.e., adding machines, or vertically, i.e., up the configuration)
For sudden traffic surges, we can do is also emergency expansion, if done well, with monitoring to do automatic expansion and contraction, which will have a certain test of the infra layer.
dead letter
In the task queue, there will inevitably be some task execution failure scenarios, in order to reproduce, we usually need a special queue for storing the task, which is usually what we call dead letter. The purpose of the dead letter itself is to store the information about the failed task execution, such as parameters and logs, so as to facilitate troubleshooting, reproduction and repair.
When a task fails, besides moving it to the dead letter queue immediately, we can also configure a retry policy, for example, retry 3 times, and move it to the dead letter queue after all 3 times fail. For task retries, we usually use exponential fallback for deferral.
Task Granularity and Scheduling
For the simplest case, a task is a task, in which case the granularity of the task is very small, e.g. sending an email to a user. There is also a case where a task may contain multiple subtasks, in which case, to simplify the application layer code, we usually implement it in a task framework, e.g.
For example, the task of creating a virtual machine contains multiple subtasks, and the last step of starting the virtual machine must be executed after all the previous steps.
When there are dependencies between subtasks, the simplest way is to execute them linearly, with the order of execution specified in the dependency description, and we follow the order one by one. A more complex approach is to use directed acyclic graphs, where tasks that do not depend on each other are executed concurrently, but the latter is usually much more difficult.
Summary
In this article, the typical architecture of task queues, common brokers, and some scenarios and concepts that will be involved in task queues are introduced, and we hope they will be helpful to you.