The three most important components of the kubernetes master node are kube-apiserver, kube-controller-manager, and kube-scheduler, which are responsible for resource access portal, cluster state management, and resource scheduling of the kubernetes cluster respectively.
This article focuses on the kube-controller-manager component and analyzes how it and its core component informer effectively manage cluster state.
Overview of how Controller Manager & Controller works
We all know that managing resources in kubernetes is relatively simple, usually by writing a YAML manifest, which can be solved directly with the kubectl command. The spec field in the YAML of Deployment may define the desired replicas, where we expect the cluster to maintain a certain number of replicas of a pod, and when we submit the manifest to the cluster, kubernetes will adjust some of the resources in the cluster to our desired state over time; or another scenario, where a pod in the cluster hangs, or we evict a pod from a Worker Node, and then we don’t do anything about it, the Pod automatically rebuilds itself and reaches the specified number of copies, which is a very common scenario.
Who implements the state management of these resources mentioned above? Yes, it is Controller Manager, which is one of the soul components of Kubernetes. It can be said that the idea of achieving cluster resource orchestration management by defining the expected state of resources relies on the Controller Manager component at the bottom.
The role of the Controller Manager is, in short, to ensure that the actual status of the resources in the cluster is consistent with the user-defined desired status.
As officially defined: kube-controller-manager runs the controllers, which are background threads that handle the regular tasks in the cluster.
The Controller Manager is the management control center inside the cluster. The role of the Controller Manager is to ensure that the actual state of various resources in the cluster is consistent with the desired state defined by the user, but what if there is inconsistency? Is it up to the Controller Manager itself to adjust the various resources?
The reason why it is called Controller Manager is that Controller Manager is composed of multiple Controllers responsible for different resources, such as Deployment Controller, Node Controller, Namespace Controller, Service Controller, etc. These Controllers have their own clear division of labor and are responsible for the management of resources within the cluster.
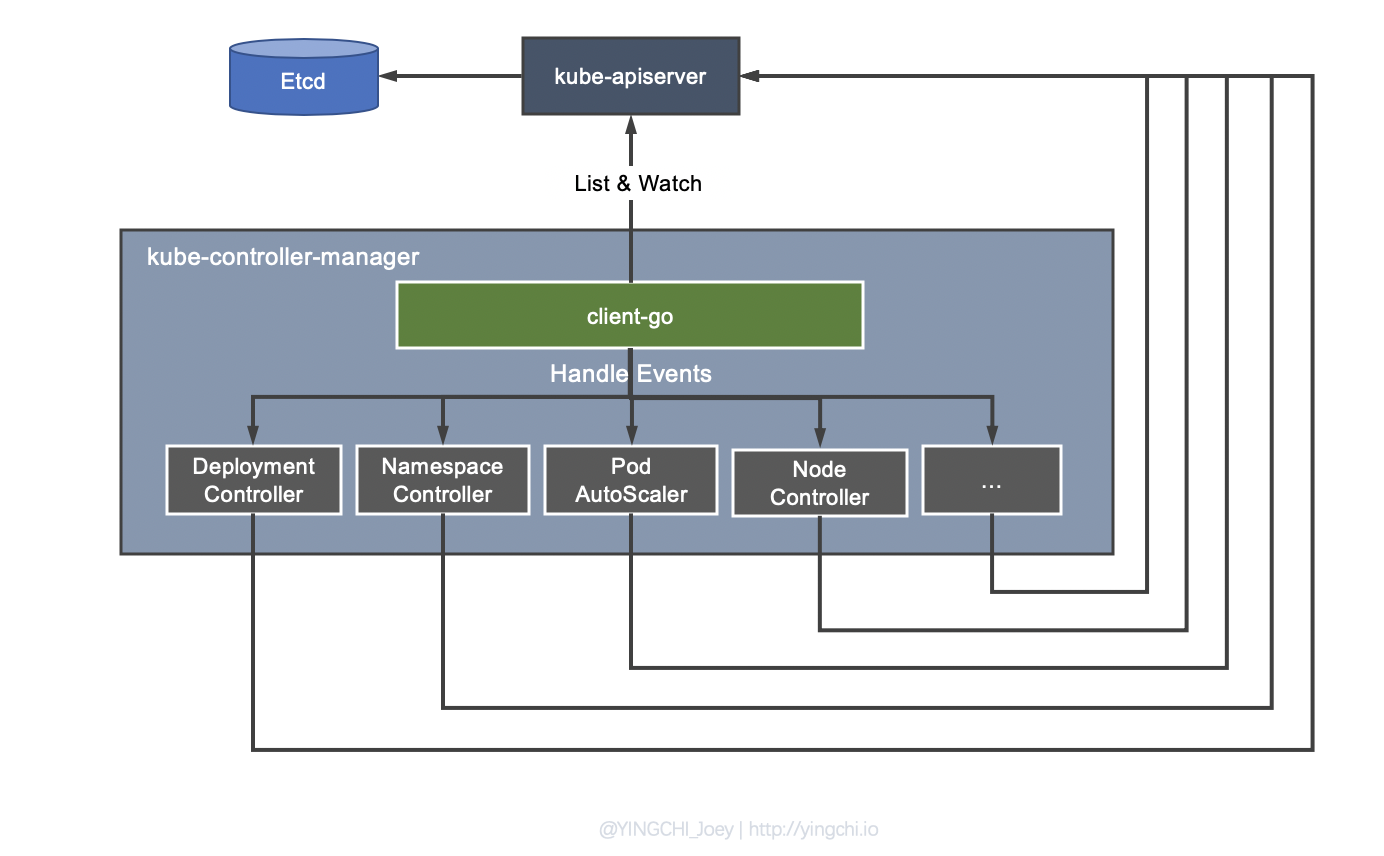
As shown in the figure, when the Controller Manager finds that the actual state of a resource deviates from the desired state, it will trigger the Event Handler registered by the corresponding Controller and let them adjust to the characteristics of the resource itself.
For example, when a Pod created by Deployment abnormally exits, the Deployment Controller will accept and handle the exiting Event and create a new Pod to maintain the expected number of copies. The reason for this design is well understood, as it decouples the Controller Manager from the specific state management work, because different resources have different state management, Deployment Controller is concerned with the number of Pod copies, while Service is concerned with the IP, Port, etc. of the Service.
client-go
A key part of the Controller Manager is client-go, which plays a role in distributing events to controllers in the controller manager. Currently, client-go has been extracted as a separate project, and is often used in kubernetes, as well as in the secondary development of kubernetes, such as developing custom controllers through client-go.
One of the core tools in the client-go package is informer, which allows for more elegant interaction with the kube-apiserver.
The main functions of informer can be summarized in two points.
- Resource data caching function, which relieves the pressure of accessing the kube-apiserver.
- Resource event distribution, which triggers a pre-registered ResourceEventHandler.
Another piece of Informer is that it provides an event handler mechanism that triggers callbacks so that the Controller can handle specific business logic based on the callbacks. Because Informer can monitor all events of all resources through List, Watch mechanism, so just add a ResourceEventHandler instance to Informer with callback function instances to implement OnAdd(obj interface{}), OnUpdate(oldObj, newObj interface{}) and OnDelete(obj interface{}), you can handle the creation, update and deletion of resources.
client-go working mechanism
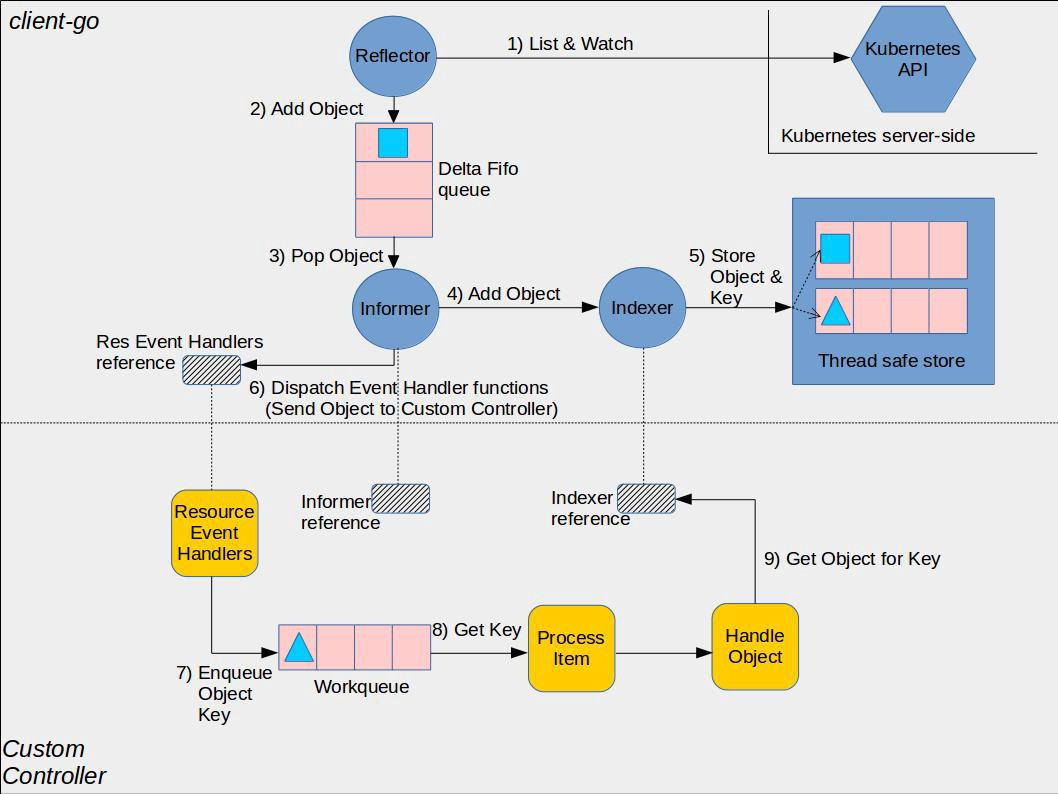
The above diagram shows the principle of client-go and custom controller implementation (from the official).
Reflactor
Reflactor, with the following functions.
- Use List, Watch mechanism to interact with kube-apiserver, List short connection to get full data, Watch long connection to get incremental data.
- Can Watch any resource including CRD.
- The incremental objects from Watch are added to the Delta FIFO queue, and then Informer will fetch the data from the queue;
Informer
Informer is one of the core modules in client-go, its main role includes the following two aspects.
-
Synchronize data to the local cache. informer continuously reads the Object in the Delta FIFO queue, updates the local store before triggering the event callback, and if it is a new Object, and if the event type is Added, then Informer saves the incremented API object to the local cache through the Indexer library. The Informer saves the API object in this increment to the local cache and creates an index for it. Later, the local store cache will be read directly when List / Get operations are performed on the resources via Lister, thus avoiding a lot of unnecessary requests to the kube-apiserver and relieving its access pressure.
-
The client-go informer module will create a shardProcessor when it starts, and the events of various controllers (e.g. Deployment Controller, Custom Controller, etc.) will be triggered according to the corresponding event types. The event handler of various controllers (e.g. Deployment Controller, Custom Controller…) is converted into a processorListener instance when it is registered to the informer, and the processorListener is appended to the Listeners slice of the shardProcessor. The shardProcessor manages these listeners.
The important role of the processorListener is to trigger the corresponding handler when the event arrives, so it keeps getting the event from nextCh and executing the corresponding handler. sharedProcessor is responsible for managing all the Handlers and distributing the events, but the real distribution is done by the distribute method.
Let’s sort out the process in between.
- The Controller registers the Handler with the Informer.
- Informer maintains all Handlers that are converted to processorListener through
sharedProcessor. - When the Informer receives an event, it distributes the event through
sharedProcessor.distribute. - The Controller is triggered with the corresponding Handler to handle its own logic.
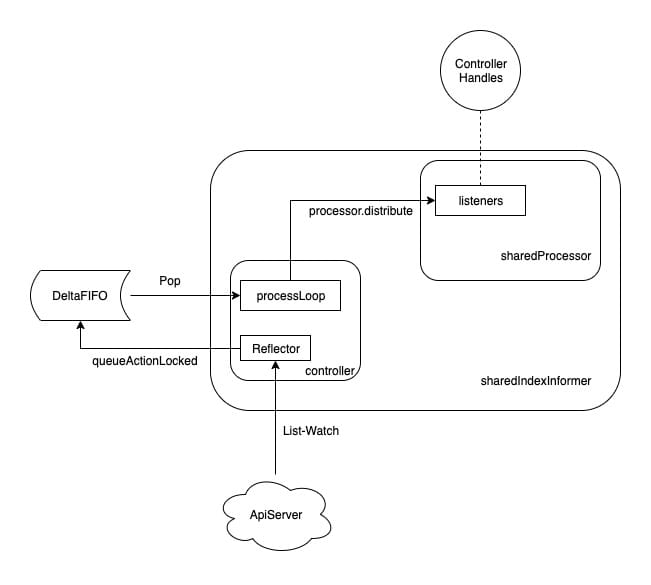
When the Reflactor starts, it executes a processLoop dead loop, which keeps popping the events from the Delta FIFO queue, and when it pops, it takes all the events from the resource and gives them to the HandleDeltas method of the sharedIndexInformer. (The controller is assigned to config.Process when it is created and passed to the Pop parameter’s handler function Pop(PopProcessFunc(c.config.Process))), and HandleDeltas calls processor.distribute to finish distributing the events.
In the registered ResourceEventHandler callback function, it just does some very simple filtering and then puts the Object that cares about the change into the workqueue. After that, the Controller takes out the Object from the workqueue and starts a worker to execute its business logic, usually comparing the current running state of the resource with the desired state, and making corresponding processing to achieve the convergence of the running state to the desired state.
Note that the worker can use the lister to get the resource, so there is no need to access the kube-apiserver frequently, and the list/get of resources will directly access the informer local store cache, and the changes of resources in the apiserver will be reflected in this cache. At the same time, the LocalStore will periodically put all Pod information back into DeltaFIFO.