Robust, readable and efficient code is a common goal for all of us developers. In this article, we will combine the features of Go language to give advice on common data structures, memory management and concurrency for writing more efficient code. Without further ado, let’s learn the techniques of Go high-performance programming together.
1. Common Data Structures
1.1 Don’t abuse reflection
The standard library reflect provides the Go language with the ability to dynamically obtain the types and values of objects and dynamically create objects at runtime. Reflection can help abstract and simplify code, making development more efficient.
The Go language’s reflection capabilities are used in the Go standard library and in many open source software, such as json for serialization and deserialization, the ORM framework gorm, xorm, and so on.
1.1.1 Prefer strconv to fmt
For conversions between basic data types and strings, strconv is preferred over fmt because the former has better performance.
The reason why there is more than twice the performance difference is that the fmt implementation uses reflection to achieve the effect of paradigm, and makes dynamic type determination at runtime, so it brings a certain performance loss.
1.1.2 A little repetition is not worse than reflection
Sometimes, we need some tool functions. For example, filtering out specified elements from uint64 slices.
Using reflection, we can implement a slicing filter function with type generalization support extension.
|
|
In many cases, we may only need to manipulate a single type of slice, and the ability to extend type generalization using reflection is simply not useful. If we really need to filter on slices of types other than uint64, what’s the harm in copying the code once? To be sure, in most scenarios, there will be no filtering of all types of slices, so the benefits of reflection are not fully enjoyed, but the performance costs are paid for.
|
|
Here’s a look at the performance comparison between the two.
|
|
The benchmark test results are shown below.
|
|
As you can see, reflection involves additional type judgments and a lot of memory allocation, resulting in a very significant performance impact. As the number of sliced elements increments, each time a judgment is made about whether an element is in a map, because the key of the map is of an indeterminate type, variable escapes occur, triggering the allocation of heap memory. So, predictably the performance difference gets bigger as the number of elements increases.
When using reflection, ask yourself, do I really need it?
1.1.3 Using binary.Read and binary.Write with caution
binary.Read and binary.Write use reflection and are very slow. If there is a need for these functions, we should implement them manually instead of using them directly.
The encoding/binary package implements a simple conversion between numbers and byte sequences as well as encoding and decoding of varints.
varints is a method of representing integers using variable bytes, where the smaller the value itself, the fewer bytes it takes. This is how Protocol Buffers encodes integers.
Where the conversion of numbers to byte sequences can be done with the following three functions.
|
|
Here is an example of the familiar C standard library function ntohl() to see how Go implements it using the binary package.
What if we manually implement an ntohl() for the uint32 type?
This function is also a reference to the encoding/binary package implementation when converting byte sequences to uint32 types for large-ended byte sequences.
Here is a look at the performance difference between the two before and after stripping the reflection.
Run the benchmark test above with the following results.
|
|
It can be seen that the performance of encoding/binary packages implemented using reflection is very different compared to the type-specific versions.
1.2 Avoid repetitive string to byte slice conversions
Do not repeatedly create a byte slice from a fixed string, as repeated slice initialization introduces performance loss. Instead, perform the conversion once and capture the result.
1.3 Specifying the container capacity
Specify the container capacity whenever possible in order to pre-allocate memory for the container. This will reduce the need to resize the container by copying when elements are subsequently added.
1.3.1 Specifying map capacity hints
Whenever possible, provide capacity information when initializing with make().
|
|
Providing a capacity hint to make() will attempt to resize the map at initialization time, which will reduce the need to reallocate memory for the map when elements are added to the map.
Note that unlike slice, the map capacity hint does not guarantee full preemptive allocation, but is used to estimate the number of hashmap buckets needed. Therefore, allocations may still occur when adding elements to a map, even when specifying map capacity.
|
|
1.3.2 Specifying slicing capacity
Whenever possible, provide capacity information when initializing slices with make(), especially when appending slices.
|
|
Unlike map, slice capacity is not a hint: the compiler will allocate enough memory for the capacity of the slice provided to make(), which means that subsequent append() operations will result in zero allocation (until the length of the slice matches the capacity, after which any append may be resized to hold additional elements).
|
|
The benchmark test results are shown below.
1.4 Choice of string splicing methods
1.4.1 The operator + is recommended for splicing strings within lines
The two most commonly used methods for splicing strings within lines are as follows for ease and speed of writing.
- operator
+ fmt.Sprintf()
The main goal of in-line string splicing is to make the code simple and readable. fmt.Sprintf() is very easy to use as it can take different types of input parameters and format the output to complete the string splicing. However, the underlying implementation uses reflection, so there is some performance loss.
The operator + simply splices strings together, and variables of non-string types require separate type conversions. In-line splicing of strings does not result in memory allocation and does not involve dynamic type conversion, so it outperforms fmt.Sprintf().
For performance reasons and ease of readability, if the variables to be spliced do not involve type conversion and the number is small (<=5), the operator + is recommended for in-line splicing of strings, and fmt.Sprintf() is recommended for the opposite.
Here’s a performance comparison between the two.
|
|
The results of performing benchmark tests are shown below.
1.4.2 Recommended strings.Builder for Non-In-Line Splicing Strings
There are other ways of string splicing, such as stringsJ.oin(), strings.Builder, bytes.Buffer and []byte, which are not suitable for in-line use. Consider using them when the number of strings to be spliced is large.
Let’s first look at the comparison of their performance tests.
|
|
The benchmark test results are shown below.
|
|
From the results, we can see that strings.Join(), strings.Builder, bytes.Buffer and []byte have similar performance. If the length of the result string is predictable, the best performance is achieved by using []byte with pre-allocated capacity for splicing.
Therefore, if performance requirements are very strict, or if the number of strings to be stitched is large enough, []byte with pre-allocated capacity is recommended.
For ease of use and performance, strings.Builder is generally recommended for string splicing.
The string.Builder also provides a way to pre-allocate memory Grow.
The performance test results of the version optimized with Grow are as follows. You can see that the performance is much improved compared to the way of not pre-allocating space.
|
|
1.5 Iterate through []struct{} using indexes instead of range
There are two ways to iterate over slices or arrays in Go, one by subscript and one by range. there is no functional difference between the two, but is there a performance difference?
1.5.1 []int
Let’s first look at the performance difference when traversing slices of basic types, using []int as an example.
|
|
The results of the running tests are as follows.
The genRandomIntSlice() function is used to generate slices of the specified length with elements of type int. As you can see from the final result, there is almost no difference between the subscript and range traversal performance when traversing slices of type []int.
1.5.2 []struct
What about for the slightly more complex []struct type?
|
|
The results of the running tests are as follows.
As you can see, there is no difference in performance between the two types of []struct traversal by index, but range has very poor performance when traversing the elements in []struct.
When range only traverses []struct indexes, the performance is much better than when range traverses []struct values. From this, we should be able to see the reason for the big performance difference between the two.
Item is a structure type , Item consists of two fields, one of type int and one of type [1024]byte, if each iteration of []Item, a copy of the value will be made, so it brings performance loss.
In addition, since the range gets a copy of the value, modifications to the copy will not affect the original slice.
1.5.3 []*struct
What about if the slice contains a pointer to a structure instead of a structure?
|
|
The results of the execution performance tests are as follows.
The performance of for and range is almost the same after replacing the slice element from the structure Item with a pointer *Item. And using a pointer has the added benefit of directly modifying the value of the pointer’s corresponding structure.
1.5.4 Summary
range returns a copy of the element during iteration, while index does not have a copy.
If range iterates over a small element, index and range perform almost identically, as in the case of a sliced []int of a basic type, but if it iterates over a large element, such as a struct containing many attributes, index will perform significantly better than range, sometimes by a factor of a thousand.
For this scenario, it is recommended to use index, but if you use range, it is recommended to iterate over only the index and access the elements through the index, which is no different from index. If you want to use range to iterate over both index and value, you need to change the elements of the slice/array to pointers in order not to affect the performance.
2. RAM Management
2.1 Saving memory with empty structs
2.1.1 Not taking up memory space
In Go, we can use unsafe.Sizeof to calculate the number of bytes an instance of a data type needs to occupy.
The results of the run are as follows.
As you can see, the empty struct struct{} in Go does not occupy memory space, unlike the empty struct in C/C++ which still occupies 1 byte.
2.1.2 Usage of Empty Structs
Because empty structs do not occupy memory space, they are widely used as placeholders in various scenarios. One is to save resources, and the other is that the empty structure itself has strong semantics, i.e., no value is needed here, and it is only used as a placeholder to achieve the effect of the code that is annotated.
Sets
The Go language standard library does not provide an implementation of Set, and maps are usually used instead. In fact, for sets, only the keys of the map are needed, not the values. Even if the value is set to bool, it will take up an extra 1 byte, so assuming there are a million items in the map, that’s 1MB of wasted space.
Therefore, when using map as a set, you can define the value type as an empty structure and use it only as a placeholder.
|
|
If you want to use the full functionality of Set, such as initialization (building a Set by slicing it), Add, Del, Clear, Contains and other operations, you can use the open source library golang-set.
Channels that do not send data
Sometimes a channel is used without sending any data, only to notify a sub-goroutine of a task, or only to control the concurrency of a goroutine. In this case, it is very appropriate to use an empty structure as a placeholder.
Structs that contain only methods
In some scenarios, the structure contains only methods and not any fields. For example the Door in the above example, in this case the Door can be replaced by virtually any data structure.
Either int or bool will waste extra memory, so in this case, it is best to declare it as an empty structure.
2.2 struct layout with memory alignment in mind
2.2.1 Why memory alignment is needed
The CPU does not access memory byte by byte, but by word size. For example, if a 32-bit CPU has a word size of 4 bytes, then the CPU accesses memory in units of 4 bytes.
The purpose of this design is to reduce the number of CPU accesses to memory and increase the throughput of CPU accesses to memory. For example, if the same 8 bytes of data is read, 4 bytes are read at a time, then only 2 times are needed.
The CPU always accesses memory at word length and without memory alignment, it is likely to increase the number of CPU accesses to memory, for example.
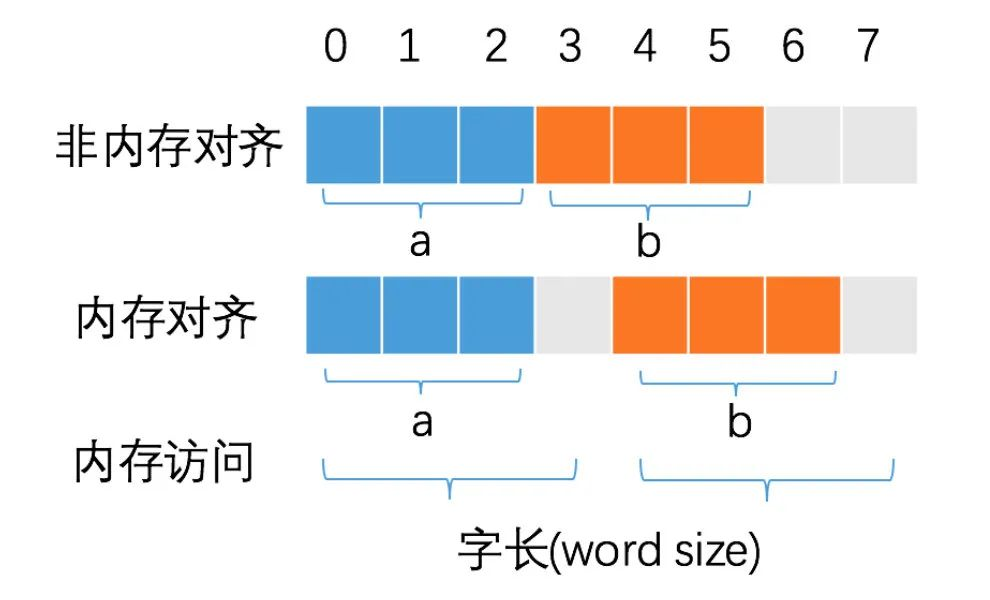
Variables a and b each occupy 3 bytes of space. After memory alignment, a and b occupy 4 bytes of space, and the CPU only needs to make one memory access to read the value of variable b. If memory alignment is not performed, the CPU needs to perform 2 memory accesses to read the value of the b variable. The first access gives the first byte of the b variable and the second access gives the last two bytes of the b variable.
As you can also see from this example, memory alignment is also beneficial for achieving atomic operation of variables. Each memory access is atomic, and if the size of the variable does not exceed the word length, then the access to the variable is atomic after memory alignment, a feature that is crucial in concurrency scenarios.
In short: reasonable memory alignment improves the performance of memory reads and writes, and facilitates the atomicity of variable operations.
2.2.2 Go Memory Alignment Rules
Compilers generally align variables in memory in order to reduce CPU access instruction cycles and improve memory access efficiency. Go is a high-performance backend programming language, so it is no exception.
The size and alignment guarantees in the Go Language Specification describe the memory alignment rules.
- For a variable x of any type:
unsafe.Alignof(x)is at least 1. - For a variable x of struct type:
unsafe.Alignof(x)is the largest of all the values unsafe.Alignof(x.f) for each field f of x, but at least 1. - For a variable x of array type:
unsafe.Alignof(x)is the same as the alignment of a variable of the array’s element type.
The function unsafe.Alignof is used to get the alignment factor of a variable. The alignment factor determines the offset of the field and the size of the variable, both of which must be integer multiples of the alignment factor.
2.2.3 Reasonable struct layout
Because of memory alignment, a reasonable struct layout can reduce memory usage and improve program performance.
As you can see, the same fields end up with different structure sizes depending on the order in which the fields are aligned.
Each field determines its offset in memory according to its own alignment factor, and the size of a field wasted due to the offset varies.
This is analyzed next, one by one. First is demo1: a is the first field, which is aligned by default, and occupies 1 byte from position 0. b is the second field, with an alignment factor of 2, so it must be left empty by 1 byte for the offset to be a multiple of 2, and occupies 2 bytes from position 2. c is the third field, with an alignment factor of 4, at which point the memory is already aligned, and occupies 4 bytes from position 4. This is the third field with an alignment multiple of 4.
So demo1’s memory footprint is 8 bytes.
For demo2: a is the first field, which is aligned by default and occupies 1 byte starting at position 0. c is the second field, which is aligned by a factor of 4. Therefore, 3 bytes must be left blank for the offset to be a multiple of 4 and occupy 4 bytes starting at position 4. b is the third field, which is aligned by a factor of 2 and occupies 2 bytes starting at position 8.
The alignment factor of demo2 is determined by the alignment factor of c, which is also 4. Therefore, demo2 occupies 12 bytes of memory.
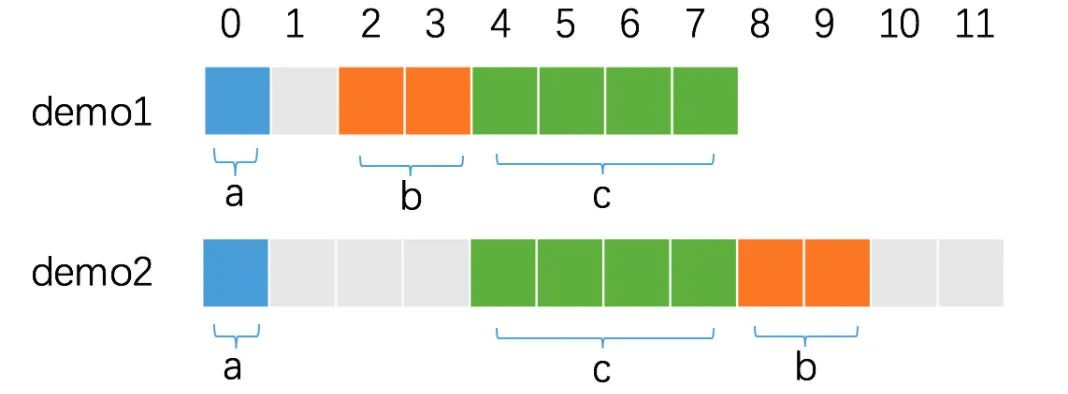
Therefore, in the design of structures that are particularly memory-sensitive, we can reduce the memory footprint by adjusting the order of the fields in the structure, arranging the field widths from smallest to largest from top to bottom.
2.2.4 Effects of Empty Structs and Arrays on Memory Alignment
Empty structures and arrays are special in Go. An empty struct{} without any fields and an array without any elements occupies a memory space of size 0.
Because of this, memory alignment is generally not required when the empty struct{} or empty array is used as a field in another struct. There is one exception: when struct{} or an empty array is the last field of a struct, memory alignment is required. This is because if there is a pointer to this field, the returned address will be outside the struct, and if this pointer stays alive without freeing the corresponding memory, there will be a memory leak (the memory is not freed by the structure release).
As you can see, demo3{} is 4 bytes in size, which is the same as the space occupied by field b, while demo4{} is 8 bytes in size, which means an additional 4 bytes of space is filled.
2.3 Reducing escapes and limiting variables to the stack
Variable escapes generally occur in the following cases.
- Variables are large
- Variables of uncertain size
- Uncertain variable type
- Returning a pointer
- Returning a reference
- Closures
After knowing the causes of variable escape, we can consciously control variables from escaping by keeping them on the stack, reducing the allocation of heap variables, reducing GC costs, and improving program performance.
2.3.1 Smaller copies are better than references
A small copy is better than a reference, and what that means is to try to use stack variables instead of heap variables. Here’s a counterintuitive example to demonstrate that a small copy is better than creating a reference variable on the heap.
We all know that Array is passed as pass-by-value in Go, and with its unscalable length, we generally use it sparingly for performance reasons. In reality, there are no absolutes. Sometimes it’s better to use an array for copy-passing than to use slices.
|
|
See below for a performance comparison.
Running the benchmark test above will give you the following results.
As you can see from the test results, the performance of copying to arrays is nevertheless better than using slices. Why is this so?
The local variable slice allocated in the sliceFibonacci() function escapes and needs to request memory space on the heap because it has to be returned outside the function. It is also clear from the test that the arrayFibonacci() function has no memory allocation and completes the creation of the array entirely on the stack. Here it shows that for some short objects, the cost of copying on the stack is much less than allocating and recycling operations on the heap.
Note that when running the above benchmark, the compile option “-l” which disables inlining is passed, if inlining occurs, then there will be no variable escape, there will be no memory allocation and recycling operations on the heap, and no performance difference will be visible between the two.
The compiler’s optimization decisions for the above two functions can be viewed at compile time with the help of the option -gcflags=-m.
You can see that both arrayFibonacci() and sliceFibonacci() functions can be inlined. sliceFibonacci() function defines a local variable slice that escapes to the heap.
So how big is a variable considered small? For the Go compiler, local variables over a certain size will escape to the heap, and the size limit may be different for different Go versions. The general limit is <64KB, and local variables will not escape to the heap.
2.3.2 Returning a value vs. returning a pointer
Value passing copies the entire object, while pointer passing only copies the address, pointing to the same object. Return pointers reduce value copying, but can cause memory allocations to escape to the heap, increasing the burden on garbage collection (GC). In scenarios where objects are frequently created and deleted, the GC overhead caused by passing pointers can have a serious performance impact.
In general, for structures that need to modify the original object value, or have a relatively large memory footprint, choose to return a pointer. For read-only structures with a smaller memory footprint, returning the value directly can yield better performance.
2.3.3 Return value using a deterministic type
If the variable type is not determined, then it will escape to the heap. Therefore, if the return value of a function can be of a definite type, do not use interface{}.
Let’s use the Fibonacci series function above as an example to see the performance difference between a deterministic return value and interface{}.
|
|
The results of running the benchmark test above are as follows.
As can be seen, when a function return value is returned using interface{}, the compiler cannot determine the specific type of the return value, resulting in the return value escaping to the heap. The performance is a little worse when the request and recovery of memory on the heap occurs.
2.4 sync.Pool reuse object
2.4.1 Introduction
sync.Pool is a component of the sync package that acts as a “pool” to hold temporarily retrieved objects. Personally, I think the name is misleading, as the objects contained in the pool can be reclaimed without notice, and syncCache is probably a more appropriate name.
The sync.Pool is scalable and concurrency-safe, and its capacity is limited only by the size of its memory. Objects stored in the pool are automatically cleaned up if they become inactive.
2.4.2 Role
For many places where memory needs to be repeatedly allocated and reclaimed, sync.Pool is a good choice. Frequent memory allocation and recovery will put a certain burden on the GC, and in severe cases will cause CPU burrs. sync.Pool can cache temporarily unused objects and use them directly when they are needed next time, without having to go through memory allocation again, reusing the memory of the objects, reducing the pressure on the GC and improving the system performance.
In a nutshell: it is used to save and reuse temporary objects, reduce memory allocation, and reduce GC pressure.
2.4.3 Usage
The sync.Pool is very simple to use, it just needs to implement the New function. When there is no object in the pool, the New function will be called to create it.
Suppose we have a “student” structure and reuse the structure object.
Then call the Pool’s Get() and Put() methods to get and put back into the pool.
Get() is used to get an object from the object pool, because the return value is interface{}, so it requires type conversion.
Put() is used to put the object back into the object pool when it is finished being used.
2.4.4 Performance Differences
Let’s take bytes.Buffer as an example and use sync.Pool to reuse bytes.Buffer objects to avoid duplicate memory creation and recycling to see the performance improvement.
|
|
The test results are as follows.
This example creates a pool of bytes.Buffer objects and performs only Write operations and one data copy at a time, which takes almost negligible time. The time spent on memory allocation and recycling is more significant and therefore has a greater impact on the overall performance of the program. The test results also show that with the Pool multiplexed object, there is no more memory allocation for each operation.
2.4.5 Applications in the standard library
The Go standard library also makes extensive use of sync.Pool, such as fmt and encoding/json. fmt package is an example of how it uses sync.Pool.
We can take a look at the most commonly used standard formatting output function, the Printf() function.
Continue with the definition of Fprintf().
|
|
The argument to the Fprintf() function is an io.Writer, and the argument passed to Fprintf() by Printf() is os.Stdout, which is equivalent to direct output to standard output. The newPrinter here uses the sync.Pool.
|
|
The calls to fmt.Printf() are very frequent, and using sync.Pool to reuse pp objects can greatly improve performance, reduce memory usage, and reduce GC pressure.
3. Concurrent Programming
3.1 About locks
3.1.1 Lock-free
Locking is to avoid security issues arising from simultaneous access to shared resources in a concurrent environment. So, is it necessary to add locks in a concurrent environment? The answer is no. Not all concurrency requires locking. Appropriately reducing the granularity of locks, or even adopting a lock-free design, is more likely to improve concurrency.
There are two main implementations of locklessness, lock-free data structures and serial lock-free.
Lock-free data structure
Lock-free data structures can be implemented using hardware-supported atomic operations, which are lock-free, concurrency-safe, and whose performance scales linearly with the number of CPUs. Many languages provide CAS atomic operations (e.g., the atomic package in Go and the atomic library in C++11) that can be used to implement lock-free data structures, such as lock-free linked lists.
Let’s take a simple, thread-safe Singly linked list insert operation to see the difference between lock-free programming and normal locking.
|
|
There are a few points to note about the implementation of Singly linked list.
- lock-free Singly linked list implementation requires a CAS operation when inserting, i.e., call the CompareAndSwap() method to insert, and if the insertion fails, a for loop is performed to try several times until success.
- To facilitate the printing of linked list contents, implement a String() method to traverse the linked list.
Let’s do a concurrent write operation on each of the two linked lists to verify their functionality.
|
|
Note that the results of running the main() function above multiple times may not be the same, because concurrency is out of order.
Here’s another look at the benchmarking of linked list Push operations to compare the performance difference between locked and unlocked.
|
|
You can see that the unlocked version has a higher performance than the locked version.
Serial lock-free
Serial lock-free is an idea that avoids the use of locks by avoiding concurrent access to shared resources and instead each concurrent operation accesses its own exclusive resource to achieve the effect of serial access to resources. There are different implementations for different scenarios. For example, a single Reactor multi-threaded model is replaced by a master-slave Reactor multi-threaded model in a network I/O scenario to avoid locking reads on the same message queue.
Here I present a situation that is often encountered in backend microservice development. We often need to concurrently pull information from multiple sources and aggregate it to a single variable. Then there is a situation where the same variable is written to mutually exclusive. For example, if we write to a map, we can write the result of each goroutine to a temporary object, so that the concurrent goroutines are unbound from the same variable, and then aggregated together without using locks. That is, they are processed independently and then merged.

To simulate the above situation, simply write a sample program to compare the performance.
|
|
Look at the performance differences between the two.
|
|
3.1.2 Reducing lock contention
If locking is unavoidable, you can use slicing to reduce the number of locks on resources, which can also improve the overall performance.
For example, Golang’s excellent local cache components bigcache, go-cache, and freecache all implement sharding, with one lock per shard, to reduce the number of locking sessions and improve overall performance.
As a simple example, let’s compare the concurrent writes of map[uint64]struct{} before and after slicing to see the performance improvement from reducing lock contention.
|
|
Look at the performance differences between the two.
|
|
As you can see, by slicing the sub-shared resources, lock contention is reduced and the concurrent performance of the program is significantly improved. Predictably, as the granularity of slicing gets smaller, the performance gap will get bigger and bigger. Of course, the smaller the slice granularity, the better. Because each slice has to be assigned a lock, it will bring a lot of extra unnecessary overhead. You can choose a value that is not too large to find a balance between performance and cost.
2.1.3 Prefer shared locks to mutually exclusive locks
If concurrency is not lock-free, give preference to shared locks over mutually exclusive locks.
A mutually exclusive lock is a lock that can only be acquired by one Goroutine. Shared locks are locks that can be acquired by multiple Goroutines at the same time.
The Go standard library sync provides two types of locks, mutex locks (sync.Mutex) and read-write locks (sync.RWMutex), and read-write locks are a concrete implementation of shared locks.
sync.Mutex
Mutex locks are used to ensure that a shared resource can only be occupied by one Goroutine at a time, and that if one Goroutine is occupied, the other Goroutines block and wait.
sync.Mutex provides two export methods to use locks.
We can lock a shared resource by using the Lock method before accessing it and release the lock by calling the Unlock method after accessing the shared resource, or we can use the defer statement to ensure that the mutually exclusive lock will be unlocked. After a Goroutine has called the Lock method to obtain a lock, all other Goroutines requesting the lock will block on the Lock method until the lock is released.
sync.RWMutex
A read-write lock is a shared lock, also called multiple readers, single writer lock. When using the lock, a distinction is made between the operations for which the lock is obtained, one for reading and one for writing. Since multiple Gorouines are allowed to acquire a read lock at the same time, it is a shared lock. However, write locks are mutually exclusive.
In general, there are several cases as follows.
- The read locks are not mutually exclusive with each other, there are no write locks, and multiple goroutines can obtain read locks at the same time.
- The write locks are mutually exclusive with each other, and there exist write locks and other write locks blocking.
- Write locks and read locks are mutually exclusive. If a read lock exists, the write lock blocks, and if a write lock exists, the read lock blocks.
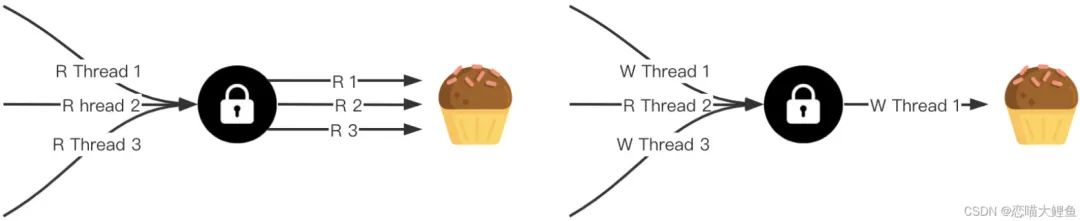
sync.RWMutex provides five export methods to use locks.
Read-write locks exist to solve performance problems when there are more reads and fewer writes. Read-write locks are effective in reducing lock blocking time when there are more read scenarios.
Performance comparison.
Most business scenarios are read more and write less, so using read-write locks can effectively improve the efficiency of access to shared data. In the worst case, if there are only write requests, then the read/write locks degrade to mutually exclusive locks at best. So prioritizing read-write locks over mutually exclusive locks can improve the concurrency performance of the program.
Next, we test the performance difference between mutually exclusive locks and read-write locks in three scenarios.
- Read more than write (80% of read)
- Read and write together (50% each)
- Read less write more (read 20%)
First, concurrent reads and writes to the shared map are implemented according to the mutex lock and read-write lock, respectively.
|
|
The input rpct is used to adjust the percentage of read operations to simulate scenarios with different percentages of reads and writes. rpct set to 80 means more reads and less writes (80% reads), rpct set to 50 means the same reads and writes (50% each), rpct set to 20 means less reads and more writes (20% reads).
|
|
Execute all benchmark tests under the current package with the following results.
|
|
It can be seen that the use of read-write lock concurrency performance will be better in scenarios where there are more reads and fewer writes. It can be expected that if the write ratio is lower, then the concurrency with read-write locking will be even better.
It should be noted here that since each read/write map operation takes a very short time, it is necessary to sleep one microsecond (one millionth of a second) each time to increase the time consumed, otherwise the time consumed for accessing shared resources is less than the time consumed for lock processing itself, then the performance optimization effect brought by using read/write locks will become less obvious or even degrade the performance.
3.2 Limiting the number of Goroutines
3.2.1 Problems with too many Goroutines
Program crashes.
Goroutine is a lightweight thread managed by the Go runtime. It allows us to easily implement concurrent programming. But when we open an unlimited number of Goroutines, we run into a fatal problem.
This example implements the concurrency of math.MaxInt32 Goroutines, 2^31 - 1 is about 2 billion, and each Goroutine does almost nothing internally. Under normal circumstances, the program would output 0 to 2^31-1 numbers in random order.
Will the program run as smoothly as expected?
|
|
The result of the run is that the program crashes straight away, with the following key error message.
|
|
The number of concurrent operations on a single file/socket exceeds the system limit. This error is caused by the fmt.Printf function, which prints the formatted string to the screen, i.e., the standard output. In Linux, standard output can also be considered a file, and the Kernel uses File Descriptor to access files, with a file descriptor of 1 for standard output, 2 for error output, and 0 for standard input.
In short, the system is running out of resources.
So what if we remove the fmt.Printf line of code? Then the program will probably crash due to lack of memory. This is better understood as each Goroutine needs to consume at least 2KB of space, so assuming the computer has 4GB of memory, then at most 4GB/2KB = 1M Goroutines are allowed to exist at the same time. Then if there are other operations in the Goroutine that require memory allocation, the number of Goroutines allowed to execute concurrently will decrease by an order of magnitude.
Cost of Goroutine.
The previous example is too extreme, and in general programs do not open Goroutines indefinitely, aiming to show that there is a limit to the number of Goroutines and that they cannot be opened indefinitely.
What if we open a lot of Goroutines, but do not cause the program to crash? If we really want to do that, we should be clear that Goroutines are lightweight but still have overhead.
Go’s overhead is mainly in three areas: creation (taking up memory), scheduling (adding to the scheduler load), and deletion (adding to GC pressure).
-
Memory overhead
In terms of space, a Goroutine takes up about 2K of memory. In the source
src/runtime/runtime2.go, we can find the structure definition type g struct of the goroutine. -
Scheduling overhead
In time, Goroutine scheduling also has a CPU overhead. We can use
runntime.Gosched()to let the current concurrent process actively give up the CPU to execute another Goroutine, here is a look at the time consumption of switching between concurrent processes.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19const NUM = 10000 func cal() { for i := 0; i < NUM; i++ { runtime.Gosched() } } func main() { // 只设置一个 Processor runtime.GOMAXPROCS(1) start := time.Now().UnixNano() go cal() for i := 0; i < NUM; i++ { runtime.Gosched() } end := time.Now().UnixNano() fmt.Printf("total %vns per %vns", end-start, (end-start)/NUM) }The output is as follows.
1total 997200ns per 99nsIt can be seen that a Goroutine switch takes about 100ns, which is a very good performance compared to microsecond switches of threads, but still has an overhead.
-
GC Overhead
The memory resources occupied by a Goroutine from its creation to the end of its operation need to be reclaimed by the GC, and if a large number of Goroutines are created endlessly, it will inevitably put pressure on the GC.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47package main import ( "fmt" "runtime" "runtime/debug" "sync" "time" ) func createLargeNumGoroutine(num int, wg *sync.WaitGroup) { wg.Add(num) for i := 0; i < num; i++ { go func() { defer wg.Done() }() } } func main() { // 只设置一个 Processor 保证 Go 程串行执行 runtime.GOMAXPROCS(1) // 关闭GC改为手动执行 debug.SetGCPercent(-1) var wg sync.WaitGroup createLargeNumGoroutine(1000, &wg) wg.Wait() t := time.Now() runtime.GC() // 手动GC cost := time.Since(t) fmt.Printf("GC cost %v when goroutine num is %v\n", cost, 1000) createLargeNumGoroutine(10000, &wg) wg.Wait() t = time.Now() runtime.GC() // 手动GC cost = time.Since(t) fmt.Printf("GC cost %v when goroutine num is %v\n", cost, 10000) createLargeNumGoroutine(100000, &wg) wg.Wait() t = time.Now() runtime.GC() // 手动GC cost = time.Since(t) fmt.Printf("GC cost %v when goroutine num is %v\n", cost, 100000) }The output is as follows.
As the number of Goroutines created increases, the GC time consumption increases.
The purpose of the above analysis is to quantify the overhead of Goroutines as much as possible. Although it is officially claimed that there is no pressure to create thousands of Goroutines when writing concurrent programs in Golang, the light overhead of Goroutines will be magnified when we create 100,000, 1,000,000 or even 10,000,000 Goroutines.
3.2.2 Limiting the number of Goroutines
To protect the program and improve performance, we should actively limit the number of concurrent Goroutines.
This can be done by using the buffer size of the channel.
The above example creates a channel with a buffer size of 3. If no messages are received, up to 3 messages are sent and blocked. Before starting Goroutine, call ch <-struct{}{} and block if the buffer is full. ch <-ch is called at the end of the Goroutine task to free the buffer.
sync.WaitGroup is not required, e.g. for Http services, where each request is naturally concurrent, sync.WaitGroup is not needed when using channels to control the number of concurrently processed tasks.
The results of the run are as follows.
It is easy to see from the logs that only 3 tasks are executed concurrently per second, achieving Goroutine’s concurrency control purpose.
3.2.3 Goroutine pooling
The above example simply limits the number of Goroutines that can be opened. On top of that, based on the idea of object reuse, we can reuse the opened Goroutines to avoid repeated creation and destruction of Goroutines and achieve the effect of pooling.
Goroutine pooling, we could write a Goroutine pool ourselves, but it is not recommended to do so. Because there are already mature open-source libraries available, there is no need to build tools over and over again. There are many third-party libraries that implement Goroutine pools and can be easily used to control the number of concurrent Goroutines, some of the more popular ones are as follows.
The following is a brief introduction to its use, using panjf2000/ants as an example.
ants is an easy-to-use high-performance Goroutine pool that enables scheduling management and reuse of large-scale Goroutines, allowing users to limit the number of Goroutines while developing concurrent programs and reuse Goroutines to achieve more efficient task execution.
With ants, we simply use its default Goroutine pool to submit tasks for concurrent execution directly. The default Goroutine pool has a default capacity of math.MaxInt32.
If you customize the Goroutine pool size, you can call the NewPool method to instantiate a pool with the given capacity, as follows.
3.2.4 Summary
Golang is built for concurrency, and Goroutines are lightweight threads managed by the Go runtime that make it easy to program concurrently; although Goroutines are lightweight, there is no such thing as a free lunch, and opening an endless number of Goroutines is bound to have performance implications and even crash programs. Therefore, we should control the number of Goroutines as much as possible, and reuse it if necessary.
3.3 Using sync.Once to avoid repeated executions
3.3.1 Introduction
sync.Once is an implementation of the Go standard library that allows functions to be executed only once, often in singleton mode, for example to initialize a configuration, keep a database connection, etc. It is similar to the init function, but with some differences.
- The init function is executed when the package is first loaded, which wastes memory and extends program load time if it is not used later.
sync.Oncecan be initialized and called anywhere in the code, so it can be delayed until it is used and is thread-safe in concurrency scenarios.
In most cases, sync.Once is used to control the initialization of a variable, which is read or written to satisfy the following three conditions.
- initialization (writing) is performed when and only when a variable is accessed for the first time.
- all reads are blocked during the initialization of the variable until the initialization is complete.
- The variable is initialized only once and resides in memory after initialization is complete.
3.3.2 Principle
sync.Once is used to ensure that a function is executed only once. To achieve this, two things need to be done.
- A counter, which counts the number of times the function has been executed.
- Thread safety, guaranteeing that the function is still executed only once in case of multiple goroutines, such as locks.
Source code.
Here’s a look at the sync.Once structure, which has two variables. It uses done to count the number of function executions and m to make it thread-safe. As it turns out, it is the same as the above guess.
|
|
sync.Once provides only one export method, Do(), and the argument f is a function that will only be executed once, usually as an object initialization function.
|
|
Leaving aside the large comments, you can see that the sync.Once implementation is very clean. The Do() function determines whether to execute the incoming task function by judging the member variable done. Before executing the task function, a lock ensures that the execution of the task function and the modification of done is a mutually exclusive operation. Before executing the task function, a secondary judgment is made on done to ensure that the task function will only be executed once and done will only be modified once.
Why done is the first field.
A comment precedes the done field, explaining why done is the first field.
done is placed first in the hot path to reduce the number of CPU instructions, i.e., to improve performance.
The hot path is a series of instructions that the program executes very frequently. sync.Once accesses o.done in most scenarios, which is better understood on the hot path. If the hot path is compiled with fewer and more direct machine code instructions, it is bound to improve performance.
Why is it possible to reduce instructions by putting them in the first field? Because the address of the first field of the structure and the pointer to the structure are the same, if it is the first field, directly to the structure of the pointer dereference can be. If it is the other field, in addition to the pointer to the structure, the offset from the first value (calculate offset) needs to be calculated. In machine code, the offset is an additional value passed with the instruction, and the CPU needs to do an addition operation of the offset value to the pointer to get the address of the value to be accessed. Because of this, the machine code to access the first field is more compact and faster.
https://stackoverflow.com/questions/59174176/what-does-hot-path-mean-in-the-context-of-sync-once
3.3.3 Performance Differences
Let’s take a simple example to illustrate the performance difference between using sync.Once to guarantee that a function will be executed only once and multiple times.
Consider a simple scenario where the function ReadConfig needs to read the environment variables and convert them to the corresponding configuration. ReadConfig may be called concurrently by multiple Goroutines, and to improve performance (reduce execution time and memory usage), using sync.Once is a better way.
|
|
Let’s look at the performance differences between the two.
The results of the execution tests are as follows.
sync.Once ensures that the Config initialization function is executed only once, avoiding repeated initializations, which is useful in concurrent environments.
3.4 Notifying Goroutine with sync.Cond
3.4.1 Introduction
sync.Cond is a conditional variable based on a mutex/read/write lock implementation to coordinate those Goroutines that want to access a shared resource. sync.Cond can be used to notify Goroutines that are blocking while waiting for the condition to occur when the state of the shared resource changes.
sync.Cond is based on a mutex/read-write lock, what is the difference between it and a mutex lock?
The mutex lock sync.Mutex is usually used to protect shared critical resources, and the conditional variable sync.Cond is used to coordinate Goroutines that want to access the shared resources. sync.Cond can be used to notify Goroutines that are blocked when the state of a shared resource changes.
3.4.2 Usage Scenarios
sync.Cond is often used in scenarios where multiple Goroutines are waiting and one Goroutine is notified (event occurs). If it’s one notification and one wait, using a mutex lock or channel will do the trick.
Let’s imagine a very simple scenario.
One Goroutine is receiving data asynchronously, and the remaining Goroutines must wait for this concurrent process to finish receiving data before they can read the correct data. In this case, if we simply use chan or mutex locks, only one Goroutine can wait and read the data, and there is no way to notify the other Goroutines to read the data as well.
At this point, it is necessary to have a global variable to mark whether the first Goroutine has finished accepting data, and the remaining Goroutines will check the value of this variable repeatedly until the requirement is met. Or create multiple channels, each Goroutine blocks on one channel, and the Goroutine receiving the data is notified one by one when the data is received. In short, extra complexity is needed to get this done.
Go has a built-in sync.Cond in the standard library sync to solve this kind of problem.
3.4.3 Principle
The sync.Cond maintains an internal wait queue of all goroutines waiting for the sync.Cond, i.e. a list of notifications. sync.Cond can be used to wake up one or all goroutines that are blocked by a wait condition variable, thus synchronizing multiple Goroutines.
The definition of sync.Cond is as follows.
|
|
Each Cond instance is associated with a lock L (mutex lock *Mutex, or read/write lock *RWMutex) that must be locked when modifying conditions or calling the Wait method.
The four member functions of sync.Cond are defined as follows.
When NewCond creates a Cond instance, a lock needs to be associated with it.
|
|
Wait is used to block the caller and wait for notification. Calling Wait automatically releases the lock c.L and hangs the goroutine where the caller is located. if another goroutine calls Signal or Broadcast to wake up the goroutine, then the Wait method will reapply the lock to c.L when it ends blocking and continue executing the code after Wait.
The reason for !condition() is used instead of if is that the condition may not be met when the current goroutine is woken up, so we need to wait again for the next wakeup. To be on the safe side, using for ensures that the condition is met before executing subsequent code.
|
|
Signal wakes up only the goroutine of any 1 waiting condition variable c, without lock protection. broadcast wakes up the goroutine of all waiting condition variables c, without lock protection.
3.4.4 Usage Example
We implement a simple example where three goroutines call Wait() to wait and another goroutine calls Broadcast() to wake up all waiting goroutines.
|
|
- done is the condition for multiple Goroutine blocking waits.
- read() calls Wait() to wait for notification until done is true.
- write() receives the data, and when it is done, sets done to true and calls Broadcast() to notify all waiting goroutines.
- write() pauses for 1s to simulate time consumption on the one hand, and to make sure that the previous 3 read goroutines have all reached Wait() and are in the waiting state on the other. main function pauses for 3s at the end to make sure that all operations have been executed.
Output.
More discussion of sync.Cond can be found at: https://stackoverflow.com/questions/36857167/how-to-correctly-use-sync-cond
3.4.5 Caution
-
sync.Condcannot be copiedThe reason why
sync.Condcannot be copied is not because it has a Locker nested inside it, because the Mutex/RWMutex pointer passed in when NewCond is created is not a problem for Mutex pointer copying.The main reason is that
sync.Condmaintains an internal Goroutine notification queue, notifyList, and if this queue is copied, then in a concurrency scenario, thenotifyList.waitandnotifyList.notifyare not the same for different Goroutines, which can lead to This can lead to some Goroutines blocking all the time. -
Wakeup order
Wake up from the waiting queue in order, first enter the waiting queue, first be woken up.
-
Lock before calling Wait()
Before calling Wait() function, you need to get the member lock of the condition variable first, because you need to change the wait queue of the condition variable mutually exclusive. The lock will be reapplied before Wait() returns.