
The hottest Linux kernel technology in the last two years is none other than eBPF!
Since 2019, in addition to the rapid evolution of eBPF technology itself, Observability, Security and Networking projects based on eBPF technology have sprung up. Familiar ones include cilium (bringing eBPF technology to the Kubernetes world), Falco (a de facto standard for Kubernetes threat detection engines when running cloud-native security), Katran (a high-performance four-tier load balancer), pixie (an observability tool for Kubernetes applications), and more.
The eBPF technology is hot, but many people still don’t know what exactly eBPF technology is and what it can do. In this article, I’ll take a brief look at what eBPF kernel technology is and how to develop a Hello World level eBPF program from scratch in C.
Let’s first look at what the hot eBPF technology really is.
I. Introduction to eBPF
eBPF is a technology that I also came across a few years ago from the blog and book of Brendan Gregg, a performance expert and inventor of the flame chart.
The predecessor of eBPF technology is BPF (Berkeley Packet Filter), which started in late 1992 with a paper called “The BSD PacketFilter: A New Architecture for User-Level Packet Capture”. The paper proposed a technical solution for implementing network packet filtering in the Unix kernel, a new technology that was 20 times faster than the most advanced packet filtering technology at the time.
In 1997, BPF technology was incorporated into the linux kernel and later used in tcpdump.
At the beginning of 2014, Alexei Starovoitov implemented eBPF, which extends the classic BPF and opens the door to a wider range of BPF technologies.
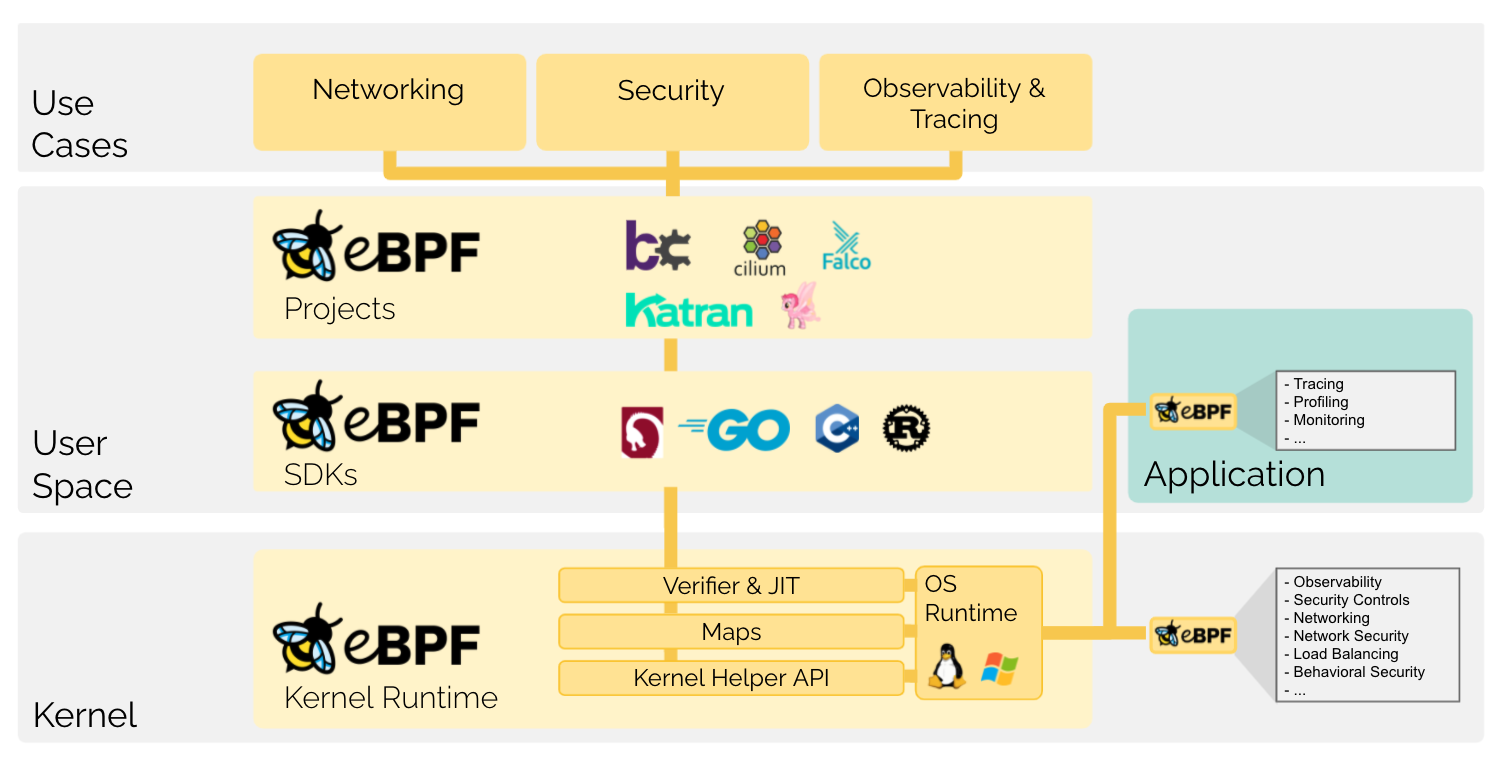
As we can see from the above diagram: eBPF programs run in the kernel state (kernel), there is no need for you to recompile the kernel or compile and mount kernel modules. eBPF can be dynamically injected into the kernel and run and uninstalled at any time. eOnce in the kernel, BPF has a God’s-eye view and can monitor the kernel as well as user-state programs. And eBPF technology provides a series of tools (Verifier) to detect the security of eBPF code and prevent malicious programs from entering the kernel state and executing.
In essence, the BPF technology is actually a kernel opening for the user state (the kernel has already made the burial point)! By injecting eBPF programs and registering events to watch, event triggering (kernel callbacks to your injected eBPF programs), and data exchange between kernel and user state to achieve the logic you want.
Today’s eBPF is no longer limited to classic BPF (cBPF) applications in networking. eBPF technology has been given a new definition: a New Generation of Networking, Security, and Observability Tools, i.e., a new generation of networking, security, and observability technologies. This definition comes from the Chief Open Source Officer of isovalent: liz rice, the parent company of the Cilium project, a technology startup driving cloud-native networking, security, and observability with eBPF technology.
eBPF has become the top subsystem of the kernel, and subsequently, if not specifically referred to, the BPF we mention refers to the new generation of eBPF technology.
BPF technology is so awesome, so how do we develop BPF programs?
II. How to develop BPF programs
1. The form of BPF programs
A project aimed at developing BPF programs usually consists of two types of source files, one is the source code file of the BPF program running in the kernel state (e.g., bpf_program.bpf.c in the figure below). The other is the source code file of the user state program used to load the BPF program to the kernel, unload the BPF program from the kernel, interact with the kernel state, and present the logic of the user state program (e.g., bpf_loader.c in the figure below).
Currently, BPF programs running in the kernel state can only be developed in C (corresponding to the first type of source code file, bpf_program.bpf.c in the figure below), or more precisely in restricted C syntax, and the only one that can perfectly compile C source code into BPF target files is the clang compiler (clang is a compiler front-end for C, C++, Objective-C and other programming languages, using LLVM as the back-end).
The following is a diagram of the compilation and loading process of the BPF program into the kernel.
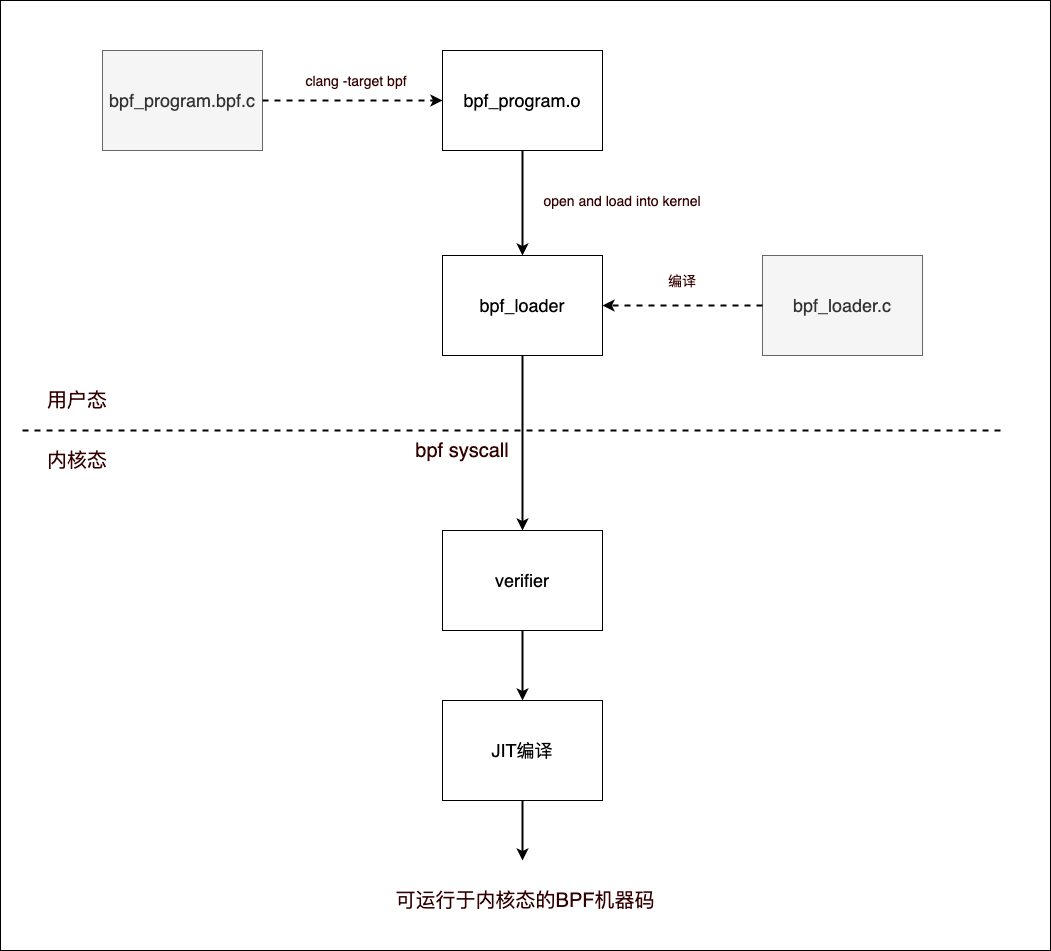
The BPF target file (bpf_program.o) is essentially an ELF file, and we can read the contents of the BPF target file by using the readelf command line tool, here is an example
|
|
In the Symbol table output by readelf above, we see a symbol bpf_prog of type FUNC, which is the entry of the BPF program we wrote. The symbol bpf_prog corresponds to the Ndx value of 3. Then we can find the section entries with the serial number of 3 in the Section Header in front: tracepoint/syscal…, they are corresponding.
From the readelf output, we can see: bpf_prog (i.e. the section with serial number 3) has a Size of 112, but what is its content? We use another tool, llvm-objdump, to expand the contents of bpf_prog.
|
|
The content of bpf_prog output by llvm-objdump is actually the byte code of BPF. When it comes to byte code, the first thing that comes to our mind is the jvm virtual machine. Yes, the BPF program is not loaded into the kernel as a machine instruction, but as byte code, which is obviously a barrier added to the BPF virtual machine for security purposes. As the BPF program is loaded into the kernel, the BPF VM verifies the BPF bytecode and runs a JIT compilation to compile the bytecode into machine code.
The user state programs used to load and unload BPF programs can be developed in multiple languages, either C or Python, Go, Rust, etc.
2. How BPF programs are developed
BPF has evolved over the years, and although efforts have been made to improve it, the experience of developing and building BPF programs is still not ideal. For this reason the community has also created frameworks and library collections like BPF Compiler Collection (BCC) to simplify BPF development, and libraries like bpftrace that provide an advanced BPF development language (understandably a DSL language for developing BPF).
Many times we don’t need to develop our own BPF programs, open source projects like bcc and bpftrace provide us with a lot of high quality BPF programs. But once we have to develop them ourselves, the threshold for developing based on bcc and bpftrace is actually not low. You need to understand the structure of the bcc framework, and you need to learn the scripting language provided by bpftrace, which inevitably adds to the burden of developing BPF on your own.
As BPF becomes more widely used, the issue of portability of BPF gradually emerges. The Linux kernel is evolving rapidly, and the types and data structures in the kernel are constantly changing. Fields of the same structure type in different kernel versions may be rearranged, may be renamed or deleted, may be changed to completely different fields, etc. For BPF programs that do not need to look at the kernel’s internal data structures, there may be no portability issues. However, for those BPF programs that need to rely on certain fields in the kernel data structure, it is important to consider the problems caused to the BPF program by changes in the internal data structure of different Kernel versions.
Initially, the way to solve this problem was to compile the BPF program locally on the target machine where the BPF program was deployed to ensure that the kernel type field layout accessed by the BPF program was consistent with the target host kernel. But this is obviously cumbersome: the various development packages that BPF depends on, the compilers used need to be installed on the target machine, and the compilation process can be time-consuming, making the testing and distribution process of BPF programs very painful, especially if you use bcc and bpftrace to develop BPF programs.
To solve the BPF portability problem, the kernel introduced two new technologies, BTF (BPF Type Format) and CO-RE (Compile Once - Run Everywhere). BTF provides structural information to avoid dependency on Clang and kernel headers, and CO-RE makes the compiled BPF bytecode relocatable, avoiding the need for LLVM recompilation.
BPF programs built using these new techniques work across different linux kernel versions without the need to recompile it for a specific kernel on the target machine. There is also no need to install hundreds of megabytes of LLVM, Clang and kernel header dependencies on the target machine as was previously the case.
Note: The principle of BTF and Co-RE technology is not the focus of this article, so it will not be repeated here, you can check the information yourself.
Of course these new technologies are transparent to the BPF program itself. The libbpf user API provided by the Linux kernel source code encapsulates all of the above new technologies, and as long as the user-state loader is developed based on libbpf, then libbpf will quietly help the BPF program relocate to the corresponding fields of the kernel structure it needs in the target host kernel, making libbpf the preferred choice for developing BPF loaders.
3. libbpf-based way to develop BPF programs
The kernel BPF developer Andrii Nakryiko has open sourced a bootstrap project libbpf-bootstrap for developing BPF programs and loaders directly based on libbpf on github /libbpf-bootstrap). This project contains examples of developing BPF programs and user state programs using c and rust. This is also the best experience I’ve seen so far with the development of C-based BPF programs and loaders.
Let’s take a hello world level BPF program and its user state loader as an example to see the “way” of implementing a BPF program based on the structure suggested by libbpf-bootstrap, here is a diagram.
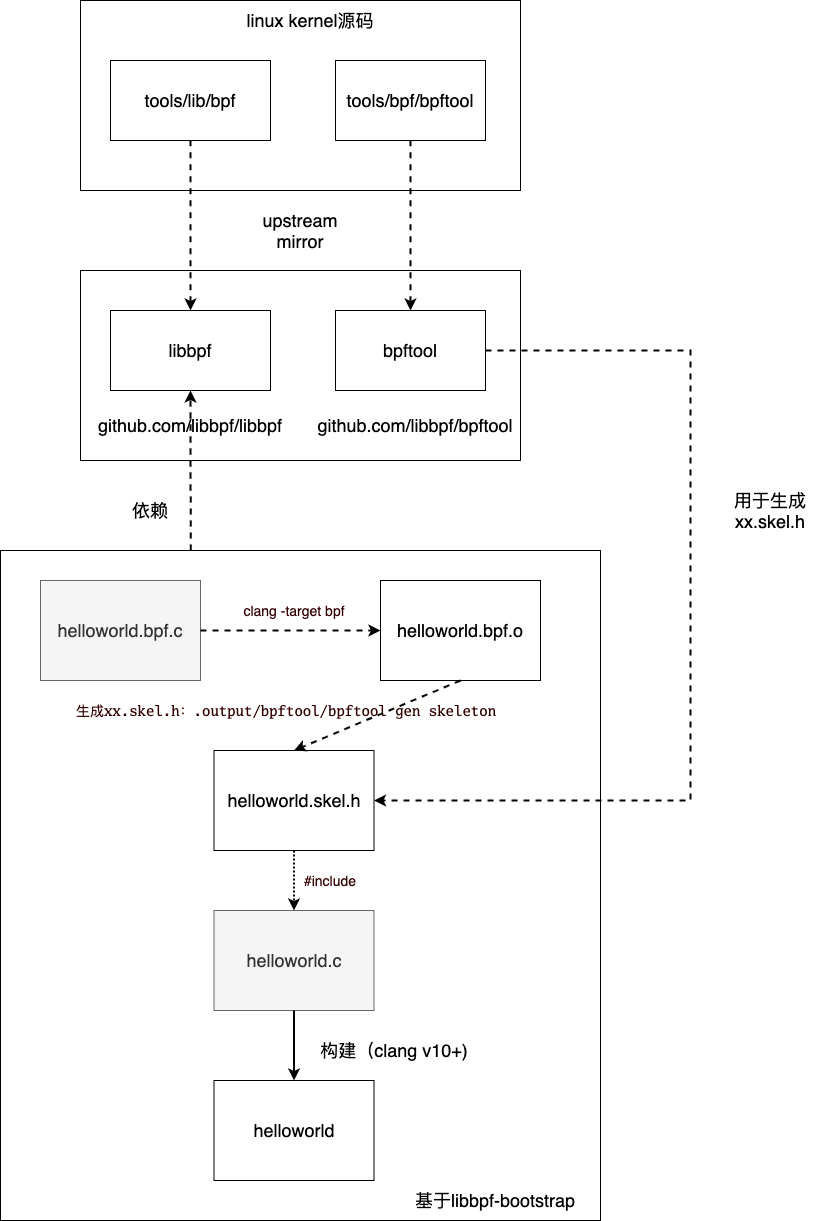
Here is a brief explanation of the above schematic.
We keep talking about libbpf, what exactly is libbpf? Actually, libbpf refers to tools/lib/bpf in the linux kernel code base, which is a C library provided by the kernel to external developers for creating BPF user-state programs. bpf kernel developers have created a mirror repository for libbpf on github.com for the convenience of developers using the libbpf library: https://github.com/libbpf/libbpf so that BPF developers do not have to download the full amount of Linux Kernel code. Of course, the mirror repository also contains some of the kernel headers that tools/lib/bpf depends on, which are mapped to the linux kernel source paths as shown in the following code (the left side of the equal sign is the source path in the linux kernel, the right side of the equal sign is the source path in github.com/libbpf/libbpf).
|
|
The bpftool in the figure corresponds to tools/bpf/bpftool in the linux kernel code repository, which is also the corresponding mirror repository created on github, a bpf helper program used in libbpf-bootstrap to generate xx.skel.h. The mirror repository also contains tools/bpf/ The mapping between bpftool and linux kernel source paths is shown in the following code (the left side of the equal sign is the source path in linux kernel, the right side of the equal sign is the source path in github.com/libbpf/bpftool)
|
|
helloworld.bpf.c is the source code of the bpf program, which is compiled into the BPF bytecode ELF file helloworld.bpf.o by clang -target=bpf . libbpf-bootstrap does not use the user state loader to load helloworld.bpf.o directly, but Instead, it generates the helloworld.skel.h file based on helloworld.bpf.o via the bpftool gen command. The generated helloworld.skel.h file contains the bytecode of the BPF program and the functions to load and unload the corresponding BPF program, which we can call directly from the user state program.
helloworld.c is the BPF user-state program, it just needs to include helloworld.skel.h and load and hook the BPF program to the corresponding buried point in the kernel layer as per the set. Since the BPF program is embedded in the user state program, we only need to distribute the user state program when we distribute the BPF program!
Above, we briefly understand the development idea based on libbpf-bootstrap, below we develop a hello world level BPF program and its user state loader program based on libbpf-bootstrap and libbpf in C language.
III. Example of developing hello world level eBPF application based on libbpf-bootstrap
Note: My experimental environment is ubuntu 20.04 (kernel version: 5.4.0-109-generic).
1. Installing dependencies
Installing the dependencies for developing the BPF application on the development machine is an essential first step. First of all, we need to install clang, the compiler for BPF programs. It is recommended to install clang 10 and above, here is an example of clang-10.
2. Download libbpf-bootstrap
libbpf-bootstrap is a simple development framework for developing BPF applications based on libbpf, we need to download it.
|
|
3. Initialize and update libbpf-bootstrap’s dependencies
libbpf-bootstrap has its dependencies libbpf, bpftool configured in its project as a git submodule.
blazesys is a project related to rust, so I won’t explain too much here.
Therefore, we need to initialize these git submodules and update them to the latest version before we can apply the libbpf-bootstrap project to develop our BPF application. We execute the following command under the libbpf-bootstrap project path.
|
|
The git command above will automatically pull the latest source code from both libbpf and bpftool repositories.
4. hello world level BPF application based on libbpf-bootstrap framework
With the libbpf-bootstrap framework, it is very simple to add a new BPF application to it. We go to the libbpf-bootstrap/examples/c directory and create two C source files helloworld.bpf.c and helloworld.c in that directory (minimal.bpf.c and minimal.c are referenced), obviously the former is the source code for the BPF program running in the kernel state, while the latter is a user-state program used to load BPF into the kernel, and their source code is as follows.
|
|
The logic of the bpf program in helloworld.bpf.c is simple: inject bpf_prog at the buried point of the execve call (set by the SEC macro), so that every time the execve call is executed, bpf_prog will be called back. bpf_prog’s logic is also very simple: it outputs a line of kernel debug logs! We can see the log output via /sys/kernel/debug/tracing/trace_pipe.
Since the bpf bytecode is encapsulated in helloworld.skel.h, helloworld.c, which includes helloworld.skel.h, is written in a more “formulaic” logic: open -> load -> attach -> destroy. For a simple BPF program like helloworld, helloworld.c can even be made into a template. But for user-state programs that interact with kernel-state BPF data, it may not be so “set in stone”.
Compiling the new helloworld program above is also very simple, mainly because the libbpf_bootstrap project has a very extended Makefile, we just need to add a helloworld entry after the APP variable in the Makefile.
Then execute the make command to compile helloworld.
We need to execute helloworld with root privileges.
|
|
Execute the following command in another window to view the output of the bpf program (when an execve system call occurs).
|
|
IV. Developing a hello world BPF application based on libbpf
After understanding the set of libbpf-bootstrap, we found that it is not difficult to develop a hello world level BPF application based on libbpf. Can we build a standalone BPF project without the libbpf-bootstrap framework? Apparently we can, so let’s try it below.
In this way, our only dependency is libbpf/libbpf. Of course we still need the libbpf/bpftool utility to generate the xx.skel.h file. So first we need to download libbpf/libbpf and libbpf/bpftool locally and compile and install them.
1. Compiling libbpf and bpftool
Let’s first download and compile libbpf.
|
|
Next, download and compile libbpf/bpftool.
2. Install libbpf library and bpftool tool
We will install the compiled libbpf library under /usr/local/bpf for subsequent shared dependencies of all libbpf-based programs.
|
|
After installation, the structure under /usr/local/bpf is as follows.
|
|
Let’s install bpftool again.
By default, bpftool is installed to /usr/local/sbin, make sure /usr/local/sbin is in your PATH path.
3. Write the helloworld BPF program
We create a helloworld directory in any path and copy the previous helloworld.bpf.c and helloworld.c to that helloworld directory.
All we are missing is a Makefile, and here is the complete contents of the Makefile.
|
|
Our Makefile is obviously “borrowed” from libbpf-bootstrap, but the Makefile here is obviously simpler to understand. The main thing we have to do in the Makefile is to tell the compiler where the header and library files (libbpf.a) that helloworld.bpf.c and helloworld.c depend on are located.
The only thing to note here is that when installing libbpf/libbpf, the header files under the repository libbpf/include are not installed under /usr/local/bpf, but then helloworld.bpf.c depends on linux/bpf.h, which is essentially libbpf/include/uapi/linux/bpf.h, so in the Makefile, we add LIBBPF_UAPI_INCLUDES for the bpf-related headers in uapi.
The whole process of building the Makefile is the same as the Makefile in libbpf-bootstrap, which also compiles the bpf bytecode first and then generates it into helloworld.skel.h. Finally, we compile the helloworld program that depends on helloworld.skel.h. Note that here we are statically linking the libbpf library (we installed only libbpf.a when we installed it).
The built helloworld is no different from the one built based on libbpf-bootstrap, so the process of starting and running it is not described here.
Note: The above is only a simplest helloworld level example and does not yet support BTF and CO-RE technologies.
V. Summary
In this article, I briefly/very briefly introduced BPF technology, focusing mainly on how to develop a hello world level eBPF program in C. Two approaches are given in the article, one is based on libbpf-bootstrap framework and the other is a standalone bpf program project that relies only on libbpf.
With the above foundation, we are in a good position to get started, and the subsequent article will expand on how to play with eBPF programs. And it will also explain how to use Go to develop user-state programs for BPF and implement loading, hooking, unloading, and interacting with data from the mind and user state of BPF programs.
The code for this article can be downloaded at here.