For unstructured data storage systems, LIST operations are usually very heavyweight, not only consuming a lot of disk IO, network bandwidth and CPU, but also affecting other requests in the same time period (especially the response latency demanding master selection requests), which is a major cluster stability killer.
For example, for Ceph object storage, each LIST bucket request needs to go to multiple disks to retrieve all the data of the bucket; it is not only slow, but also affects other common read and write requests in the same time period, because IO is shared, resulting in increased response latency and even timeout. If there are many objects in the bucket (e.g. as a storage backend for harbor/docker-registry), LIST operations cannot even be completed in regular time (and thus registry GC, which relies on LIST bucket operations, cannot run).
Compared to Ceph, an actual etcd cluster may store a small amount of data (a few ~ tens of gigabytes), even enough to be cached in memory. Unlike Ceph, however, the number of concurrent requests can be several orders of magnitude higher, e.g., it is an etcd for a ~4000 nodes k8s cluster. a single LIST request may only need to return a few tens of MB to a few GB of traffic, but the number of concurrent requests is obviously too much for etcd to handle, so it is better to have a cache layer in front of it, which is what apiserver does (for one). (Most of K8s’ LIST requests should be blocked by the apiserver and served from its local cache, but if not used properly, they can skip the cache and reach etcd directly, with significant stability risks.
This paper delves into the processing logic and performance bottlenecks of LIST operations on k8s apiserver/etcd, and provides some recommendations for LIST stress testing, deployment and tuning of basic services to improve the stability of large-scale K8s clusters.
The kube-apiserver LIST request processing logic is as follows.
The code is based on v1.24.0. However, the basic logic and code path of 1.19~1.24 are the same, so you can cross-reference if you need.
1 Introduction
1.1 K8s Architecture: A Hierarchical View of the Ring
From an architectural hierarchy and component dependency perspective, the analogy between a K8s cluster and a Linux host can be made as follows.

For K8s clusters, several components and functions from the inside out.
- etcd: persistent KV storage, the sole authoritative data (state) source for cluster resources (pods/services/networkpolicies/…).
- apiserver: reads (
ListWatch) the full amount of data from etcd and caches it in memory; stateless service, horizontally scalable. - various basic services (e.g.
kubelet,*-agent,*-operator): connect to apiserver and get (List/ListWatch) the data they each need. - workloads within the cluster: created, managed and reconcile by 3 in case 1 and 2 are normal, e.g. kubelet creates pods, cilium configures network and security policies.
1.2 The apiserver/etcd role
As you can see above, there are two levels of List/ListWatch in the system path (but the data is the same copy).
- apiserver List/ListWatch etcd
- base service List/ListWatch apiserver
So, in its simplest form, the apiserver is a proxy (proxy) in front of etcd.
- in the vast majority of cases, the apiserver serves directly from the local cache (since it caches the full amount of data for the cluster).
- some special cases, such as
- the client explicitly requests to read data from etcd (seeking the highest data accuracy), and
- apiserver local cache is not yet builtapiserver will have to forward the request to etcd – Here you have to pay special attention - - Improperly set LIST parameters on the client side can also lead to this logic.
1.3 apiserver/etcd List overhead
1.3.1 Example of a request
Consider the following LIST operations.
-
LIST apis/cilium.io/v2/ciliumendpoints?limit=500&resourceVersion=0Here both parameters are passed, butresourceVersion=0will cause apiserver ignorelimit=500, so the client gets the full amount of ciliumendpoints data. The full amount of data for a resource can be quite large, and need to think through whether you really need the full amount of data. The quantitative measurement and analysis method will be described later. -
LIST api/v1/pods?filedSelector=spec.nodeName%3Dnode1This request is to fetch all pods onnode1(%3Dis an escape of=). Doing the filtering based on nodename may give the impression that the amount of data is not too large, but it’s actually more complicated behind the scenes than it looks.- First, resourceVersion=0 is not specified here, causing apiserver to skip the cache and go directly to etcd to read the data.
- Secondly, etcd is just KV storage, with no filtering by label/field (only
limit/continueis handled). - So, apiserver is pulling the full amount of data from etcd and then doing filtering in memory, which is also a lot of overhead, as analyzed in code later. This behavior is to be avoided unless there is an extremely high demand for data accuracy and you purposely want to bypass the apiserver cache.
-
**
LIST api/v1/pods?filedSelector=spec.nodeName%3Dnode1&resourceVersion=0**The difference with 2 is thatresourceVersion=0is added, so apiserver will read data from the cache, and there is an order of magnitude performance improvement. But note that while what is actually returned to the client may only be a few hundred KB to a few hundred MB (depending on the number of pods on the node, the number of labels on the pods, etc.), the amount of data that apiserver needs to process can be several GB. A quantitative analysis will follow later.
As you can see above, the impact of different LIST operations is different, and the client may see only a small fraction of the data processed by apiserver/etcd. If the base service is started or restarted massively, it is very likely to blow up the control plane.
1.3.2 Processing overhead
List requests can be divided into two types.
- list full amount of data: the overhead is spent mainly on data transfer.
- specify filtering by label or field (field), only the data that needs to be matched.
The special note here is the second case, where the list request comes with a filter.
- In most cases, apiserver will use its own cache to do the filtering, which is fast, so ** time spent is mostly on data transfer**.
- The case where the request needs to be forwarded to etcd, as mentioned earlier, etcd is just KV storage and does not understand label/field information, so it cannot handle filtering requests. The actual process is: apiserver pulls the full amount of data from etcd, then does the filtering in memory, and returns it to the client. So in addition to the data transfer overhead (network bandwidth), this case also takes up a lot of apiserver CPU and memory.
1.4 Potential problems with large scale deployments
For another example, the following line of code uses k8s client-go to filter pods based on nodename
|
|
It looks like a very simple operation, let’s actually look at the amount of data behind it. Using a 4000 node, 10w pod cluster as an example, full volume of pod data.
- in etcd: compact unstructured KV storage in the 1GB magnitude.
- in apiserver cache: already structured golang objects, in the 2GB magnitude (TODO: further confirmation required).
- apiserver returns: the client generally chooses the default json format to receive, which is also already structured data. The json for the full pod is also in the 2GB range.
As you can see, some requests may look simple, a matter of a single line of code from the client, but the amount of data behind them is staggering. Specifying a pod filter by nodeName may return only 500KB of data, but apiserver needs to filter 2GB of data – worst case, etcd has to process 1GB of data along with it (the above parameter configuration does hit the worst case (see code analysis below).
When the cluster is small, this problem may not be visible (etcd only starts printing warning logs after the LIST response latency exceeds a certain threshold); when it is large, apiserver/etcd will not be able to handle such requests if there are more of them.
1.5 Purpose of this paper
To deepen the understanding of performance issues by looking at the List/ListWatch implementation of k8s in deeper code, and to provide some reference for optimizing the stability of large-scale K8s clusters.
2 apiserver List() operation source code analysis
With the above theoretical warm-up, you can next look at the code implementation.
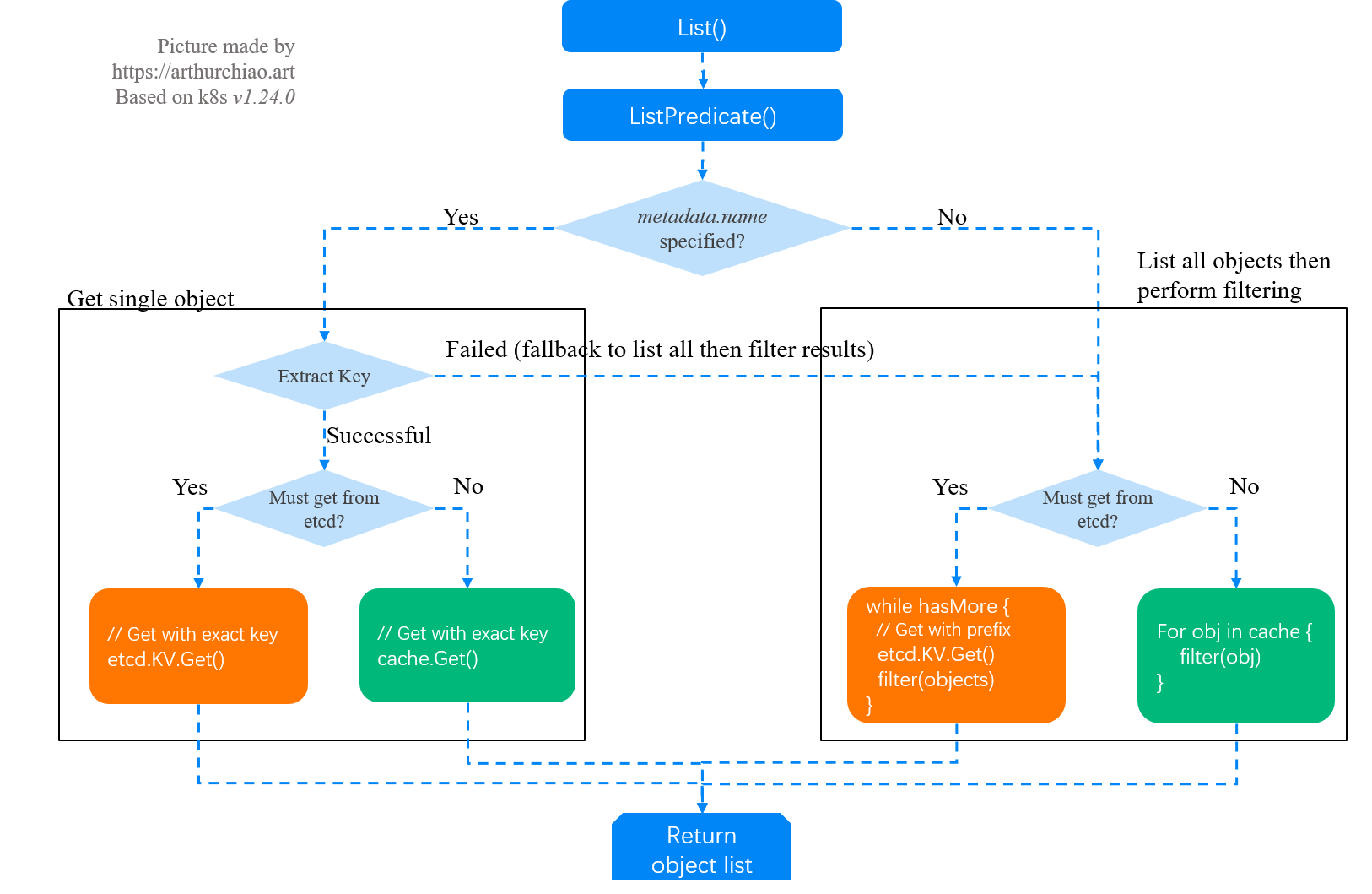
2.1 Call stack and flowchart
|
|
Corresponding flow chart.
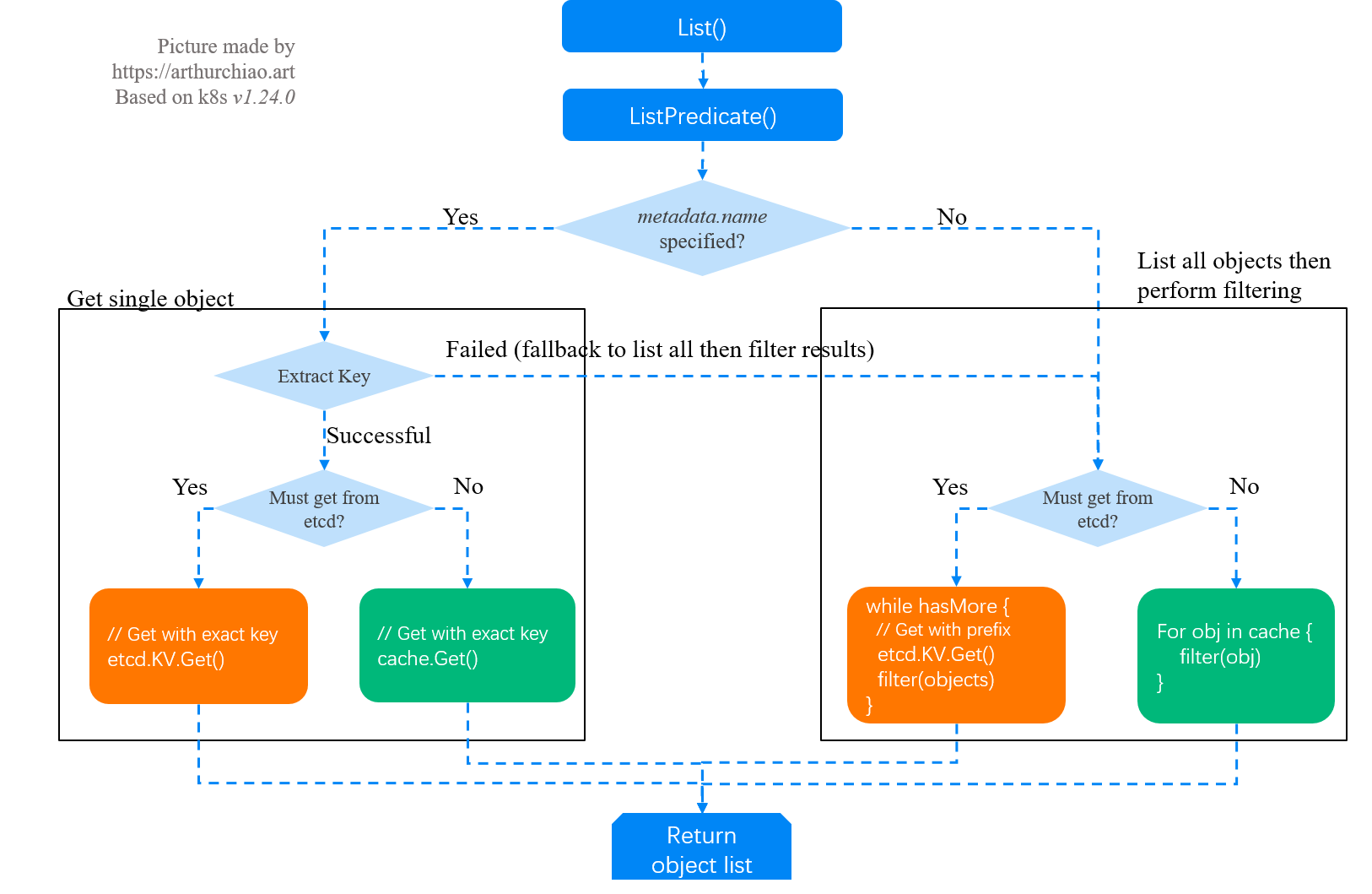
2.2 Request processing entry: List()
|
|
2.3 ListPredicate()
|
|
GetList()` in cases 1 & 2 in 1.24.0, previous versions are a bit different: * e.Storage.
- GetToList in Case 1
- List in Case 1
But the basic process is the same.
- If the client does not pass
ListOption, a default value is initialized whereResourceVersionis set to the empty string, which will cause the apiserver *to pull data from etcd to return to the client without using the local cache (unless the local cache is not yet built) (unless the local cache is not yet built); for example, when the client setsListOption{Limit: 5000, ResourceVersion: 0}list ciliumendpoints, the request sent will be/apis/cilium.io/v2/ ciliumendpoints?limit=500&resourceVersion=0.ResourceVersionis the behavior of the empty string, which you will see parsed later. - initialize the limit/continue fields of the filter (SelectionPredicate) with the fields in listoptions respectively.
- initialize the returned result,
list := e.NewListFunc(). - convert the API-side ListOptions to the underlying stored ListOptions, see
metainternalversion.ListOptionsbelow for field differences. is the API-side structure containing the
|
|
storage.ListOptions is the structure passed to the underlying storage , with a few differences in the fields.
|
|
2.4 The request specifies a resource name: Get a single object
Next, depending on whether meta.Name is specified in the request, there are two cases.
- if specified, it is a query for a single object, since
Nameis unique, and the next logical step is to query for a single object. - if it is not specified, you need to get the full amount of data, and then filter it in apiserver memory according to the filter conditions in SelectionPredicate, and return the final result to the client.
The code is as follows.
|
|
e.Storage is an Interface.
|
|
e.Storage.GetList() will execute to the cacher code.
Whether fetching a single object or the full amount of data, it goes through a similar process.
- fetching from the apiserver local cache first (determinants include ResourceVersion, etc.), and
- go to etcd as a last resort.
The logic of getting individual objects is relatively simple, so we won’t look at it here. The next step is to look at the logic of filtering the full amount of data in the list.
2.5 Request unspecified resource name, get full amount of data to do filtering
2.5.1 apiserver cache layer: GetList() processing logic
|
|
2.5.2 Determining whether data must be read from etcd: shouldDelegateList()
|
|
Very important here.
-
Q: Does the fact that the
ResourceVersionfield in ListOption{} is not set by the client correspond toresourceVersion == ""here?A: Yes, so Section 1 of example will result in pulling the full amount of data from etcd.
-
Q: Will the client set
limit=500&resourceVersion=0causehasContinuation==truenext time?A: No, resourceVersion=0 will cause the limit to be ignored (the
hasLimitline of code), meaning that the request will return the full amount of data, even though limit=500 is specified. -
Q: What is the purpose of ResourceVersionMatch?
A: It’s used to tell apiserver how to interpret ResourceVersion, and there’s a complicated official table that you can look at if you’re interested.
Next, we return to cacher’s GetList() logic and look at the specific cases of processing.
2.5.3 Case 1: ListOption asks to read data from etcd
In this case, apiserver will read all objects directly from etcd and filter them, and then return them to the client, for scenarios where data consistency is extremely important. Of course, it is also easy to mistake into this scenario and overstress etcd, for example Section 1 of example.
|
|
client.KV.Get()It goes into the etcd client library, so keep digging down if you’re interested.appendListItem()will * filter the data it gets, which is the apiserver memory filtering operation we mentioned in section 1.
2.5.4 Case 2: The local cache is not yet built, so you can only read data from etcd
The procedure is the same as in case 1.
2.5.5 Case 3: Using local cache
|
|
3 LIST test
To avoid client-side libraries (such as client-go) automatically setting some parameters for us, we test directly with curl, specifying the credentials.
Usage.
3.1 Specify limit=2: the response will return paging information (continue)
3.1.1 curl test
As you can see, the
- does return two pod messages, in the
items[]field. - Also returns a
continuefield inmetadata. The next time the client takes this parameter, apiserver will continue to return the rest until apiserver no longer returnscontinue.
3.1.2 kubectl testing
Cranking up the logging level of kubectl also shows that it uses continue behind the scenes to get the full amount of pods.
|
|
The first request got 500 pods, and the second request took the continue return with it: GET http://localhost:8080/api/v1/pods?continue=eyJ2Ijoib&limit=500 , which is a token. The continue is a token and is a bit long, so it is truncated here for better presentation.
3.2 Specify limit=2&resourceVersion=0: limit=2 will be ignored and the full amount of data will be returned
items[] contains the full amount of pod information.
3.3 Specify spec.nodeName=node1&resourceVersion=0 vs. specnode.Name=node1"
Same result
|
|
The result is the same, unless there is an inconsistency between apiserver cache and etcd data, which is extremely unlikely and we won’t discuss here.
Speed varies greatly
Using time to measure the elapsed time in the above two cases, you will find that for larger clusters, there is a significant difference in response time between the two types of requests.
|
|
For a cluster size of 4K nodes, 100K pods, the following data is provided for reference.
- without
resourceVersion=0(read etcd and filter at apiserver): time consumed10s - with
resourceVersion=0(read apiserver cache): time consumed0.05s
200x worse.
The total size of the full pod is calculated at 2GB, averaging 20KB each.
4 LIST Request to Control Plane Pressure: Quantitative Analysis
This section presents an example of the cilium-agent to quantify the pressure on the control plane when it starts.
4.1 Collecting LIST requests
The first step is to obtain which resources are LISTed to k8s when the agent starts. There are several ways to collect them.
- in the k8s access log, filtered by ServiceAccount, verb, request_uri, etc.
- through agent logs.
- by further code analysis, etc.
Suppose we collect the following LIST requests.
api/v1/namespaces?resourceVersion=0api/v1/pods?filedSelector=spec.nodeName%3Dnode1&resourceVersion=0api/v1/nodes?fieldSelector=metadata.name%3Dnode1&resourceVersion=0api/v1/services?labelSelector=%21service.kubernetes.io%2Fheadless%2C%21service.kubernetes.io%2Fservice-proxy-nameapis/discovery.k8s.io/v1beta1/endpointslices?resourceVersion=0apis/networking.k8s.io/networkpolicies?resourceVersion=0apis/cilium.io/v2/ciliumnodes?resourceVersion=0apis/cilium.io/v2/ciliumnetworkpolicies?resourceVersion=0apis/cilium.io/v2/ciliumclusterwidenetworkpolicies?resourceVersion=0
2.2 Testing the amount of data and time consumed by LIST requests
With the list of LIST requests, you can then manually execute these requests and get the following data.
-
request time consumption
-
the amount of data processed by the request, which is divided into two types.
- the amount of data processed by apiserver (full amount of data), the evaluation of the performance impact on apiserver/etcd should be based on this
- the amount of data that the agent finally gets (filtered by selector)
The following script (put on the real environment k8s master) can be used to execute the test once.
|
|
The execution effect is as follows.
|
|
Note: For LIST with selector, e.g. LIST pods?spec.nodeName=node1, this script will execute the request without selector first, in order to measure the amount of data apiserver needs to process, e.g. the list pods above: 1.
- the agent really executes
pods?resourceVersion=0&fieldSelector=spec.nodeName%3Dnode1, so the request time consumption should be based on this - the extra execution of
pods?resourceVersion=0is to test how much data the apiserver needs to process for a request of 1
Note: List all pods will generate 2GB files, so use this benchmark tool with caution, first understand what you are testing with the script you wrote, and especially don’t automate or run concurrently, you may blow up apiserver/etcd.
4.3 Analysis of test results
The above output has the following key information.
- the type of resources in the LIST, e.g. pods/endpoints/services
- the time consumed by the LIST operation
- the amount of data involved in the LIST operation
- the amount of data (in json format) to be processed by apiserver: the above list pods, for example, corresponds to the
listed-podsfile, totaling 2GB. - the amount of data received by the agent (since the agent may have specified label/field filters): in the case of the list pods above, corresponding to the
listed-pods-filteredfile, totaling526K
- the amount of data (in json format) to be processed by apiserver: the above list pods, for example, corresponds to the
By collecting and sorting all LIST requests in the above way, we know how much pressure the agent puts on apiserver/etcd for one startup operation.
|
|
Again using cilium as an example, there is roughly this sort (amount of data processed by apiserver, json format)
| List Resource Type | Amount of data processed by apiserver (json) | Time consuming |
|---|---|---|
| CiliumEndpoints (Full volume) | 193MB | 11s |
| CiliumNodes (Full volume) | 70MB | 0.5s |
| … | … | … |
5 Large Scale Foundation Services: Deployment and Tuning Recommendations
5.1 List request default setting ResourceVersion=0
As described earlier, not setting this parameter will cause apiserver to pull the full amount of data from etcd and then filter it, resulting in
- very slow
- too large for etcd to handle
Therefore, unless you have to pull data from etcd because of high data accuracy requirements, you should set the ResourceVersion=0 parameter on LIST requests and let apiserver serve it with cache.
If you are using client-go’s ListWatch/informer interface, then it already has ResourceVersion=0 set by default.
5.2 Preferring the namespaced API
If the resources to be LISTed are in a single or a few namespaces, consider using the namespaced API.
- Namespaced API:
/api/v1/namespaces/<ns>/pods?query=xxx - Un-namespaced API:
/api/v1/pods?query=xxx
5.3 Restart backoff
For per-node deployed base services, such as kubelet, cilium-agent, daemonsets, the stress on the control plane during large restarts needs to be reduced by an effective restart backoff.
For example, the number of agents restarted per minute after a simultaneous hang should not exceed 10% of the cluster size (configurable, or can be calculated automatically). api/v1/pods?query=xxx`
5.4 Prioritize filtering on the server side via label/field selector
If you need to cache some resources and listen for changes, you need to use the ListWatch mechanism to pull the data locally and the business logic filters it from the local cache itself as needed. This is client-go’s ListWatch/informer mechanism.
But if it’s just a one-time LIST operation with filtering criteria, like the nodename filtering pod example mentioned earlier, then obviously we should let apiserver filter out the data for us by setting label or field filters. LIST 10w pods takes a few tens of seconds (most of the time is spent on data transfer and also takes up a lot of CPU/BW/IO on apiserver), while if only the pods on the local machine are needed, LIST may only take 0.05s to return the results after setting nodeName=node1. It is also very important not to forget to include resourceVersion=0 in the request.
5.4.1 Label selector
In-memory filtering in apiserver.
5.4.2 Field selector
In-memory filtering in apiserver.
5.4.3 Namespace selector
Namespace is part of the prefix in etcd, so it is possible to specify namespace to filter resources much faster than selectors that are not prefixed.
5.5 Supporting infrastructure (monitoring, alerting, etc.)
The above analysis shows that a single request from a client may only return a few hundred KB of data, but an apiserver (or worse, etcd) needs to handle GBs of data. Therefore, mass restart of basic services should be avoided, and for this reason monitoring and alerting should be done as well as possible.
5.5.1 Use independent ServiceAccount
Each basic service (e.g. kubelet, cilium-agent, etc.) and various operators that have a lot of LIST operations on the apiserver use their own independent SAs, which makes it easy for the apiserver to distinguish the source of requests and is useful for monitoring, troubleshooting, and server-side flow limitation.
5.5.2 Liveness Monitoring Alerts
The base service must be covered by liveness monitoring.
There must be P1 level liveness alerts to detect mass hang scenarios first. Then reduce the pressure on the control plane by restart backoff.
5.5.3 Monitoring and tuning etcd
The key performance-related indicators need to be monitored and alerted.
-
memory
-
bandwidth
-
number of large LIST requests and response times such as the following
LIST all podslogs.
Deployment and configuration tuning.
- K8s events split to a separate etcd cluster
- other.
6 Other
6.1 Get requests: GetOptions{}
The basic principle is the same as ListOption{}, not setting ResourceVersion=0 will cause the apiserver to go to etcd to get the data, so you should try to avoid it.