Kubernetes provides a Pod graceful exit mechanism that allows Pods to complete some cleanup before exiting. But if something goes wrong while performing cleanup, will the Pod exit properly? How long does it take to exit? Can the exit time be specified? Does the system have default parameters? There are several details that we should pay attention to, and this article will start from these details to sort out the behavior of Kubernetes components and their parameters in each case.
Pod normal exit
Pod normal exit is a non-eviction exit, including artificial deletion, deletion by execution error, etc.
When a pod exits, the kubelet executes a pod’s preStop before deleting the container, allowing the pod to execute a script to clear necessary resources, etc. before exiting. However, preStop can also fail or hang, in which case preStop will not prevent the pod from exiting and the kubelet will not repeat the execution, but will wait for a period of time beyond which the container will be deleted to ensure the stability of the entire system.
The whole process is in the function killContainer. What we need to clarify when the pod exits gracefully is that the waiting time of the kubelet is determined by those factors, and how the fields that the user can set and the parameters of the system components work together.
gracePeriod
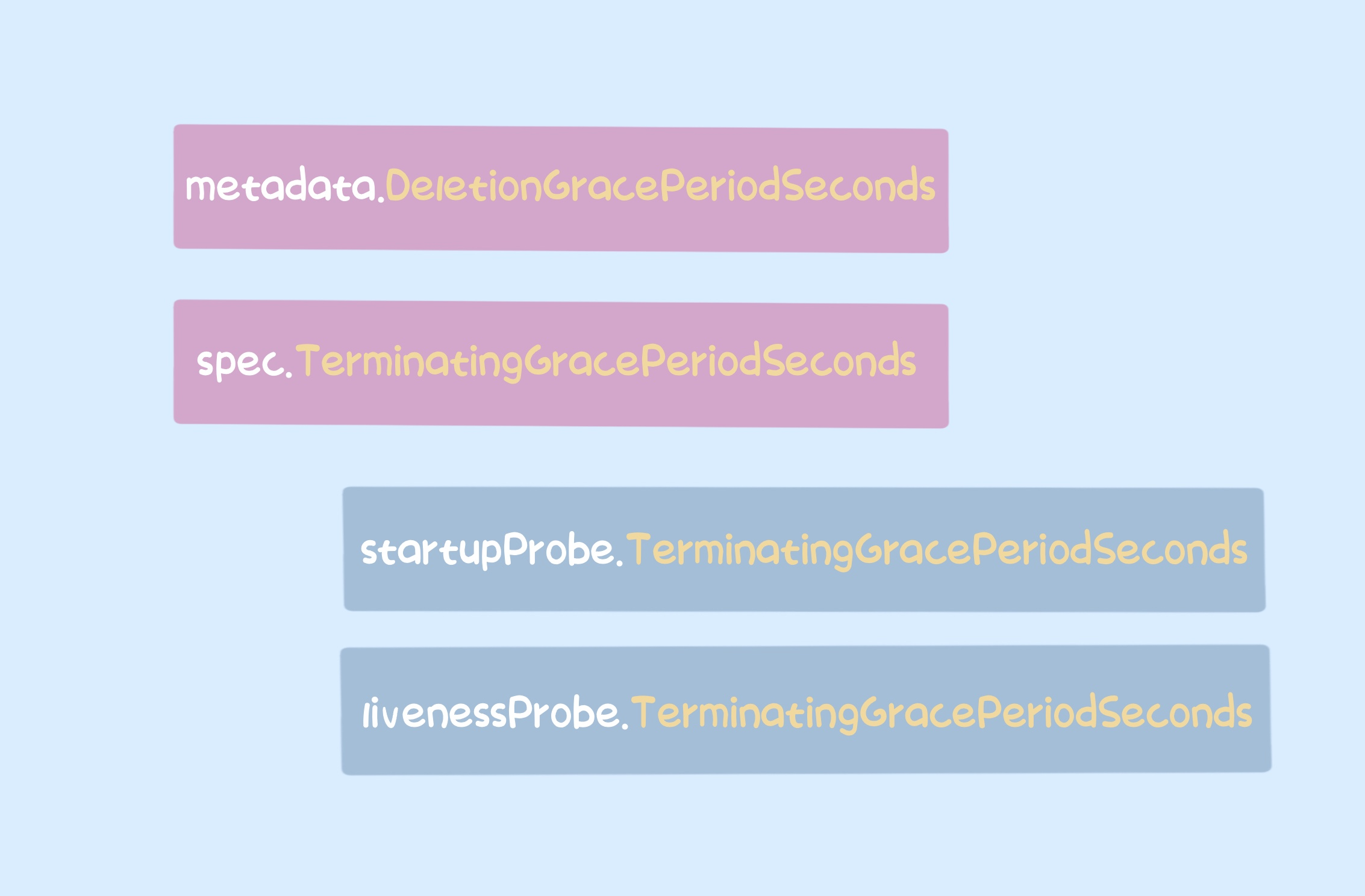
The process of kubelet calculating gracePeriod is as follows
- if the pod’s
DeletionGracePeriodSeconds is not nil, meaning it was deleted by the ApiServer, gracePeriod takes the value directly.
- if the pod’s
Spec.TerminationGracePeriodSeconds is not nil, then see what the reason for the pod deletion is.
- if the reason for deletion is the failure of executing
startupProbe, gracePeriod takes the value of TerminationGracePeriodSeconds set in startupProbe.
- If the reason for deletion is failure to execute
livenessProbe, gracePeriod takes the value of TerminationGracePeriodSeconds set in livenessProbe.
Once the gracePeriod is obtained, the kubelet executes the pod’s preStop and the function executePreStopHook starts a goroutine and calculates its execution time. gracePeriod is subtracted from this time to give the final timeout passed to the runtime for deleting the container. timeout time passed to runtime. So, if we set pod preStop, we need to take into account both the execution time of preStop and the time of container exit, we can set TerminationGracePeriodSeconds to be greater than preStop + the time of container exit.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
func (m *kubeGenericRuntimeManager) killContainer(pod *v1.Pod, containerID kubecontainer.ContainerID, containerName string, message string, reason containerKillReason, gracePeriodOverride *int64) error {
...
// From this point, pod and container must be non-nil.
gracePeriod := int64(minimumGracePeriodInSeconds)
switch {
case pod.DeletionGracePeriodSeconds != nil:
gracePeriod = *pod.DeletionGracePeriodSeconds
case pod.Spec.TerminationGracePeriodSeconds != nil:
gracePeriod = *pod.Spec.TerminationGracePeriodSeconds
switch reason {
case reasonStartupProbe:
if containerSpec.StartupProbe != nil && containerSpec.StartupProbe.TerminationGracePeriodSeconds != nil {
gracePeriod = *containerSpec.StartupProbe.TerminationGracePeriodSeconds
}
case reasonLivenessProbe:
if containerSpec.LivenessProbe != nil && containerSpec.LivenessProbe.TerminationGracePeriodSeconds != nil {
gracePeriod = *containerSpec.LivenessProbe.TerminationGracePeriodSeconds
}
}
}
// Run internal pre-stop lifecycle hook
if err := m.internalLifecycle.PreStopContainer(containerID.ID); err != nil {
return err
}
// Run the pre-stop lifecycle hooks if applicable and if there is enough time to run it
if containerSpec.Lifecycle != nil && containerSpec.Lifecycle.PreStop != nil && gracePeriod > 0 {
gracePeriod = gracePeriod - m.executePreStopHook(pod, containerID, containerSpec, gracePeriod)
}
// always give containers a minimal shutdown window to avoid unnecessary SIGKILLs
if gracePeriod < minimumGracePeriodInSeconds {
gracePeriod = minimumGracePeriodInSeconds
}
if gracePeriodOverride != nil {
gracePeriod = *gracePeriodOverride
}
err := m.runtimeService.StopContainer(containerID.ID, gracePeriod)
...
return nil
}
|
gracePeriodOverride
In the above analysis, before the kubelet calls the runtime interface, it will determine another step gracePeriodOverride and if the value passed in is not null, it will directly override the previous gracePeriod with that value.

The main process for kubelet to calculate gracePeriodOverride is as follows.
- fetch the pod’s
DeletionGracePeriodSeconds.
- if the kubelet is evicting the pod, override the pod exit time with the evicted settings.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
func calculateEffectiveGracePeriod(status *podSyncStatus, pod *v1.Pod, options *KillPodOptions) (int64, bool) {
gracePeriod := status.gracePeriod
// this value is bedrock truth - the apiserver owns telling us this value calculated by apiserver
if override := pod.DeletionGracePeriodSeconds; override != nil {
if gracePeriod == 0 || *override < gracePeriod {
gracePeriod = *override
}
}
// we allow other parts of the kubelet (namely eviction) to request this pod be terminated faster
if options != nil {
if override := options.PodTerminationGracePeriodSecondsOverride; override != nil {
if gracePeriod == 0 || *override < gracePeriod {
gracePeriod = *override
}
}
}
// make a best effort to default this value to the pod's desired intent, in the event
// the kubelet provided no requested value (graceful termination?)
if gracePeriod == 0 && pod.Spec.TerminationGracePeriodSeconds != nil {
gracePeriod = *pod.Spec.TerminationGracePeriodSeconds
}
// no matter what, we always supply a grace period of 1
if gracePeriod < 1 {
gracePeriod = 1
}
return gracePeriod, status.gracePeriod != 0 && status.gracePeriod != gracePeriod
}
|
ApiServer’s behavior
When analyzing the exit time of a pod handled by kubelet above, we see that kubelet first uses the pod’s DeletionGracePeriodSeconds, which is the value written by ApiServer when it deletes a pod. In this section, we analyze the behavior of ApiServer when it deletes a pod.
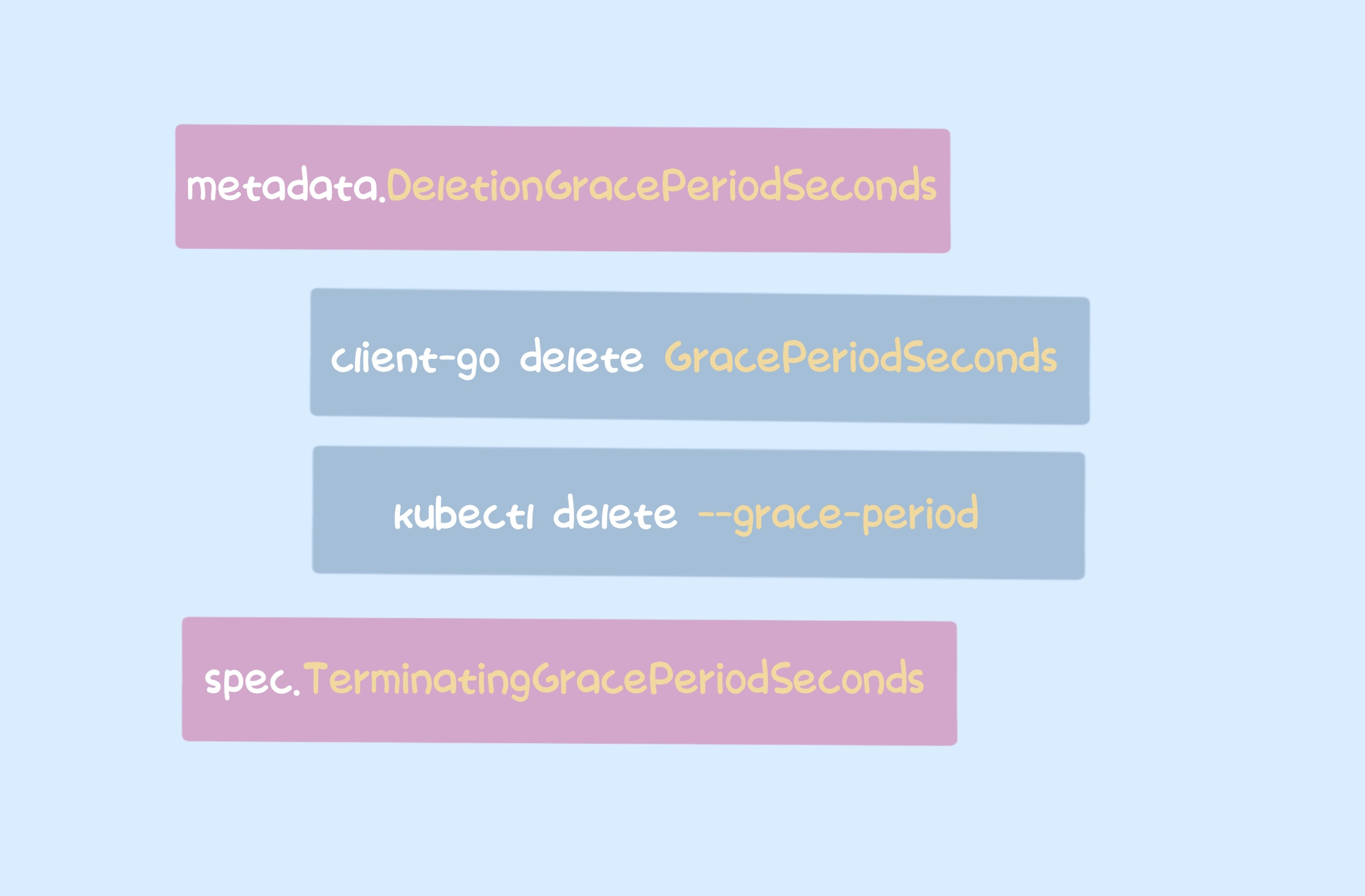
The process of calculating the pod’s GracePeriodSeconds in ApiServer is as follows
- set to
options.GracePeriodSeconds if it is not empty, otherwise set to Spec.TerminationGracePeriodSeconds specified by the user in the spec (default is 30s).
- set to 0 if the pod is not scheduled or has been exited, i.e., deleted immediately.
where -options.GracePeriodSeconds is the parameter -grace-period that can be specified when kubectl deletes a pod, or when the ApiServer interface is called in the program, such as DeleteOptions.GracePeriodSeconds in client-go.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
func (podStrategy) CheckGracefulDelete(ctx context.Context, obj runtime.Object, options *metav1.DeleteOptions) bool {
if options == nil {
return false
}
pod := obj.(*api.Pod)
period := int64(0)
// user has specified a value
if options.GracePeriodSeconds != nil {
period = *options.GracePeriodSeconds
} else {
// use the default value if set, or deletes the pod immediately (0)
if pod.Spec.TerminationGracePeriodSeconds != nil {
period = *pod.Spec.TerminationGracePeriodSeconds
}
}
// if the pod is not scheduled, delete immediately
if len(pod.Spec.NodeName) == 0 {
period = 0
}
// if the pod is already terminated, delete immediately
if pod.Status.Phase == api.PodFailed || pod.Status.Phase == api.PodSucceeded {
period = 0
}
if period < 0 {
period = 1
}
// ensure the options and the pod are in sync
options.GracePeriodSeconds = &period
return true
}
|
kubelet eviction of pods
In addition, the pod’s graceful exit time is overridden when the pod is evicted by the kubelet.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func (m *managerImpl) synchronize(diskInfoProvider DiskInfoProvider, podFunc ActivePodsFunc) []*v1.Pod {
...
// we kill at most a single pod during each eviction interval
for i := range activePods {
pod := activePods[i]
gracePeriodOverride := int64(0)
if !isHardEvictionThreshold(thresholdToReclaim) {
gracePeriodOverride = m.config.MaxPodGracePeriodSeconds
}
message, annotations := evictionMessage(resourceToReclaim, pod, statsFunc)
if m.evictPod(pod, gracePeriodOverride, message, annotations) {
metrics.Evictions.WithLabelValues(string(thresholdToReclaim.Signal)).Inc()
return []*v1.Pod{pod}
}
}
...
}
|
The override value is EvictionMaxPodGracePeriod and is only valid for soft eviction, which is the kubelet’s eviction-related configuration parameter.
1
2
3
4
5
6
7
8
9
10
|
// Map of signal names to quantities that defines hard eviction thresholds. For example: {"memory.available": "300Mi"}.
EvictionHard map[string]string
// Map of signal names to quantities that defines soft eviction thresholds. For example: {"memory.available": "300Mi"}.
EvictionSoft map[string]string
// Map of signal names to quantities that defines grace periods for each soft eviction signal. For example: {"memory.available": "30s"}.
EvictionSoftGracePeriod map[string]string
// Duration for which the kubelet has to wait before transitioning out of an eviction pressure condition.
EvictionPressureTransitionPeriod metav1.Duration
// Maximum allowed grace period (in seconds) to use when terminating pods in response to a soft eviction threshold being met.
EvictionMaxPodGracePeriod int32
|
The function to evict a pod from a kubelet is injected at startup with the following function.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
func killPodNow(podWorkers PodWorkers, recorder record.EventRecorder) eviction.KillPodFunc {
return func(pod *v1.Pod, isEvicted bool, gracePeriodOverride *int64, statusFn func(*v1.PodStatus)) error {
// determine the grace period to use when killing the pod
gracePeriod := int64(0)
if gracePeriodOverride != nil {
gracePeriod = *gracePeriodOverride
} else if pod.Spec.TerminationGracePeriodSeconds != nil {
gracePeriod = *pod.Spec.TerminationGracePeriodSeconds
}
// we timeout and return an error if we don't get a callback within a reasonable time.
// the default timeout is relative to the grace period (we settle on 10s to wait for kubelet->runtime traffic to complete in sigkill)
timeout := int64(gracePeriod + (gracePeriod / 2))
minTimeout := int64(10)
if timeout < minTimeout {
timeout = minTimeout
}
timeoutDuration := time.Duration(timeout) * time.Second
// open a channel we block against until we get a result
ch := make(chan struct{}, 1)
podWorkers.UpdatePod(UpdatePodOptions{
Pod: pod,
UpdateType: kubetypes.SyncPodKill,
KillPodOptions: &KillPodOptions{
CompletedCh: ch,
Evict: isEvicted,
PodStatusFunc: statusFn,
PodTerminationGracePeriodSecondsOverride: gracePeriodOverride,
},
})
// wait for either a response, or a timeout
select {
case <-ch:
return nil
case <-time.After(timeoutDuration):
recorder.Eventf(pod, v1.EventTypeWarning, events.ExceededGracePeriod, "Container runtime did not kill the pod within specified grace period.")
return fmt.Errorf("timeout waiting to kill pod")
}
}
}
|
The killPodNow function is the function called by the kubelet when evicting a pod, gracePeriodOverride is the parameter set during soft eviction, when it is not set, gracePeriod still takes the value of pod. TerminationGracePeriodSeconds. This function then calls podWorkers.UpdatePod, passes in the appropriate parameters, sets a timeout associated with gracePeriod, and waits for it to return.
Summary
The graceful exit of a Pod is achieved by preStop. This article provides a brief analysis of what factors affect the exit time of a Pod when it exits normally and when it is evicted, and how each parameter interacts with each other. After understanding these details, we have a more comprehensive knowledge of the Pod exit process.