1. Matching application architecture with business development and operation and maintenance capabilities
In industry conferences and documentation blogs, we often see various excellent solutions, but if we directly copy them to our own business, we often hit a wall. Because these technical solutions are incubated in specific business scenarios, different business forms, different business scales, and different business development stages will affect the implementation of the technology.
On the other hand, applications need to be maintained by people, and a suitable platform needs to be built to assist in the management of the application life cycle, which requires matching operation and maintenance capabilities. Backward operation and maintenance capabilities will reduce productivity and give competitors the opportunity to take advantage of; too far ahead of the low input-output ratio of operation and maintenance capabilities, easy to drag down the company.
We don’t need to create a microblog for the flow of tens of thousands of QPS and deal with all kinds of hot traffic; nor do we need to recruit a group of cattle to consume capital flow in order to chase new technical hotspots.
The application architecture is matched with the business development and operation and maintenance capabilities. The forward development of business, making money, more users and more demands will lead to the upgrade of architecture; the upgrade of architecture can better serve the users and achieve more users. This is a dynamic and mutually reinforcing process, which also drives the flow of technical staff to find the right position in the market.
2. Upfront, Kubernetes under multiple regions
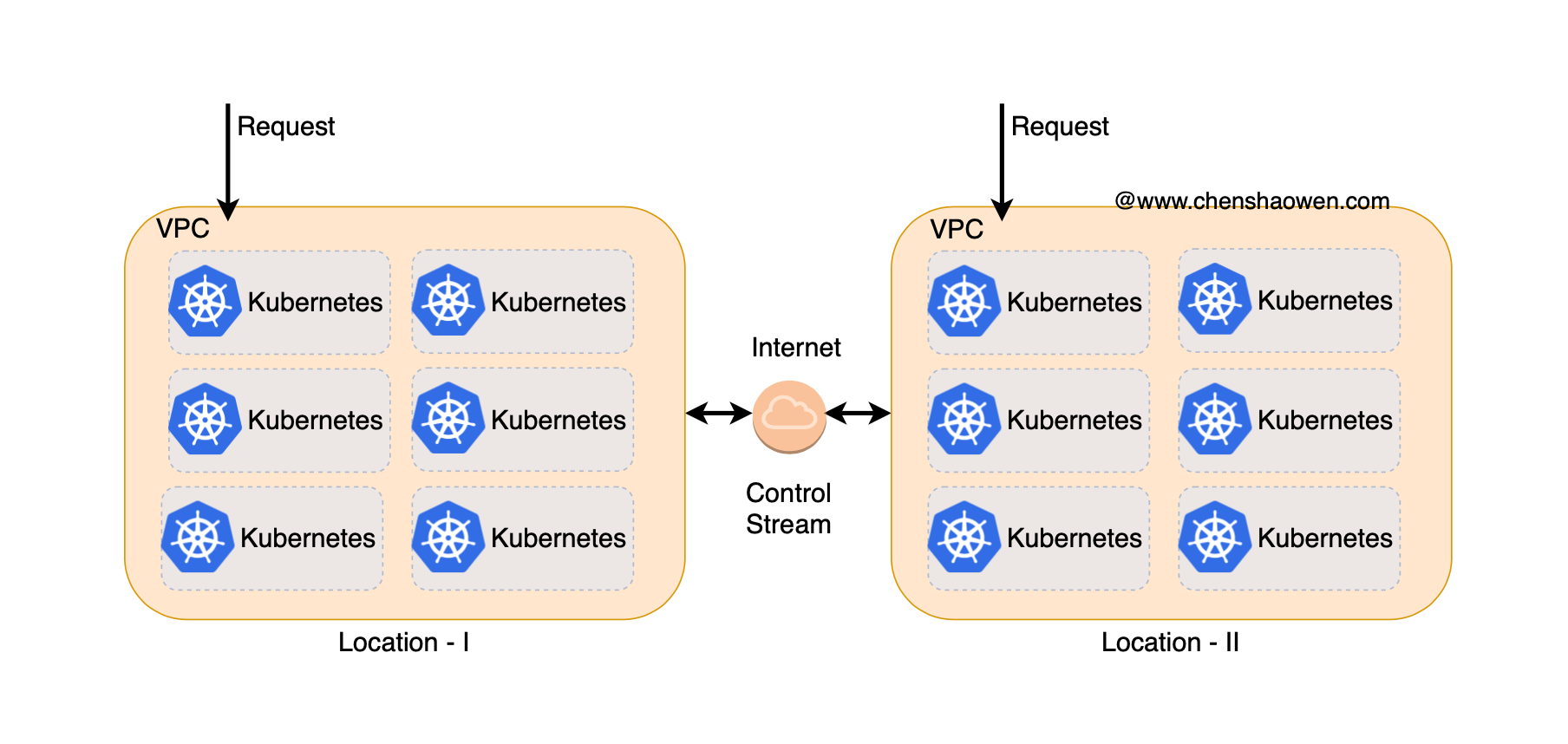
As shown above, in the early stages of business development, we can deploy applications in areas where customers gather to provide services close to each other.
Each Location can provide independent and complete external services, and the Location can be interconnected with the public network to establish a tunnel for control flow transmission. The control flow here is not just limited to command classes, but can also be user metadata, etc., but should not transmit user-generated data, such as uploaded images, documents, etc.
Due to business isolation, many Kubernetes will be deployed in each Location. the fewer nodes in a single Kubernetes, the easier it is to maintain, the smaller the blast radius, and the more manageable the risk.
But this also means that we will have a lot of clusters, and managing and maintaining these clusters will require human investment. At the same time, cluster version differences can make development adaptation more difficult, affect application technology selection, and weaken the value of accumulated O&M experience.
3. mid-term, Kubernetes under multiple zones
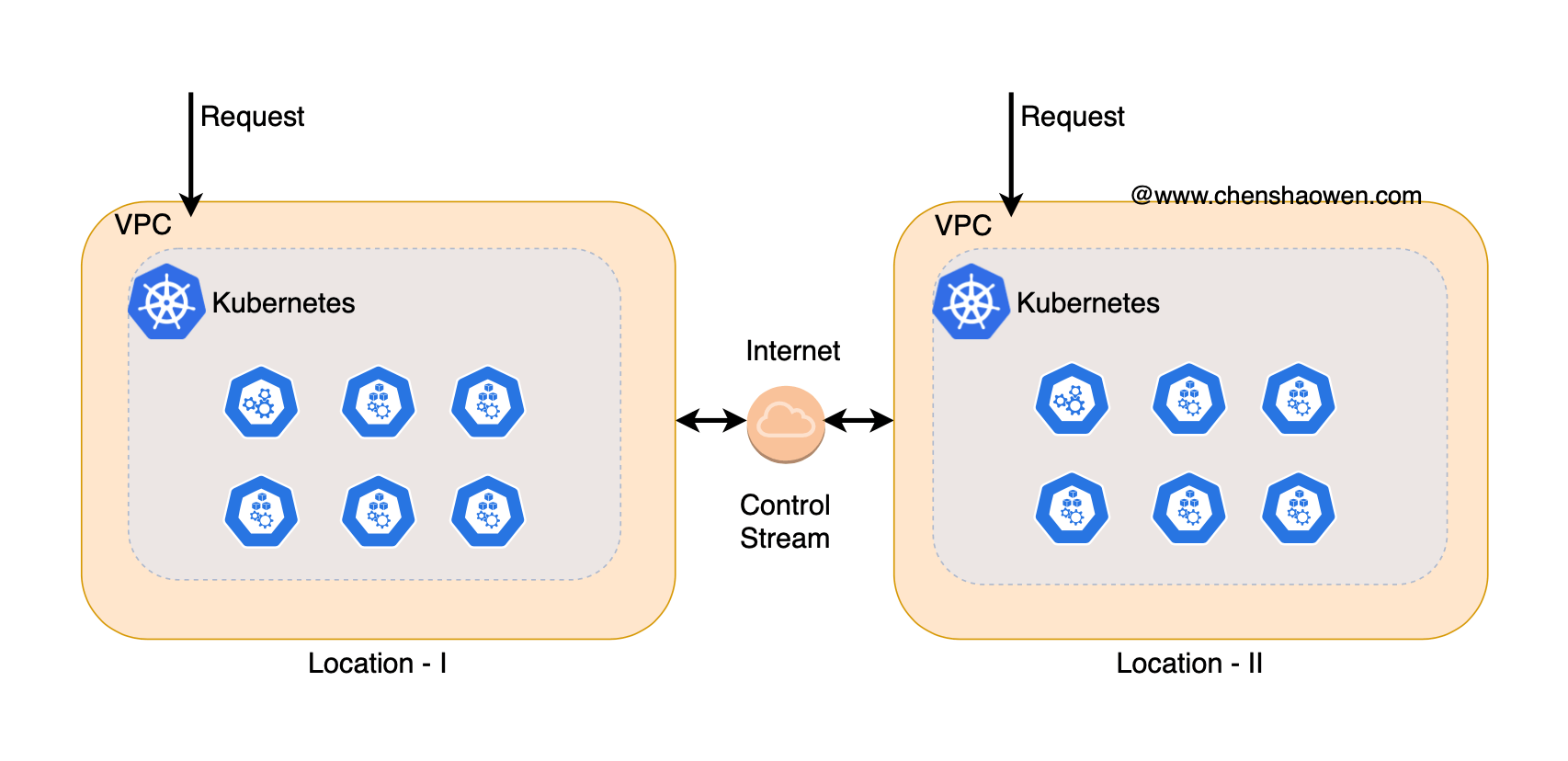
As shown above, when the business has a certain scale, we can merge clusters.
In the early days, in order to avoid risks, the number of clusters will be very large, and hundreds of clusters in one department will bring huge costs to cluster management and maintenance.
Cluster maintainers, on a daily basis, are concerned about insufficient resources, memory leaks, failure to pull mirrors, adding and deleting nodes, insufficient permissions, configuration differences, etc. The other side of the coin is seeing some new clusters with very low load, high kernel versions, and no user feedback issues. This is the downside of a large number of small clusters with high maintenance costs and limited room for HPA scaling.
By consolidating clusters, the overall load factor of the cluster can be effectively improved. But with this comes various problems associated with mega clusters.
- Scheduling efficiency
- Network management
- Service forwarding
- Metering and billing
- …
Solving these problems will bring a series of benefits:
- Improved resource utilization
- Extra room for scaling
- Better cluster management
As we dig deeper into Kubernetes and the surrounding technology stack, we will develop a group of technical people with more insight into cloud-native.
4. Later, Kubernetes under multiple zones
The first thing to agree on is that a large cluster is better than a large number of small clusters, as much as O&M capacity allows.
The second is to not cross clusters when you can do things within clusters. In the early stages, with services spread across small clusters, frequent cross-cluster service calls were not only low performance, but also extremely expensive to maintain forwarding rules.
Although these problems can be solved by merging clusters, in the late stage, a single large cluster is unable to meet the heavy traffic impact of a single Location. Therefore, the following diagram will be shown.
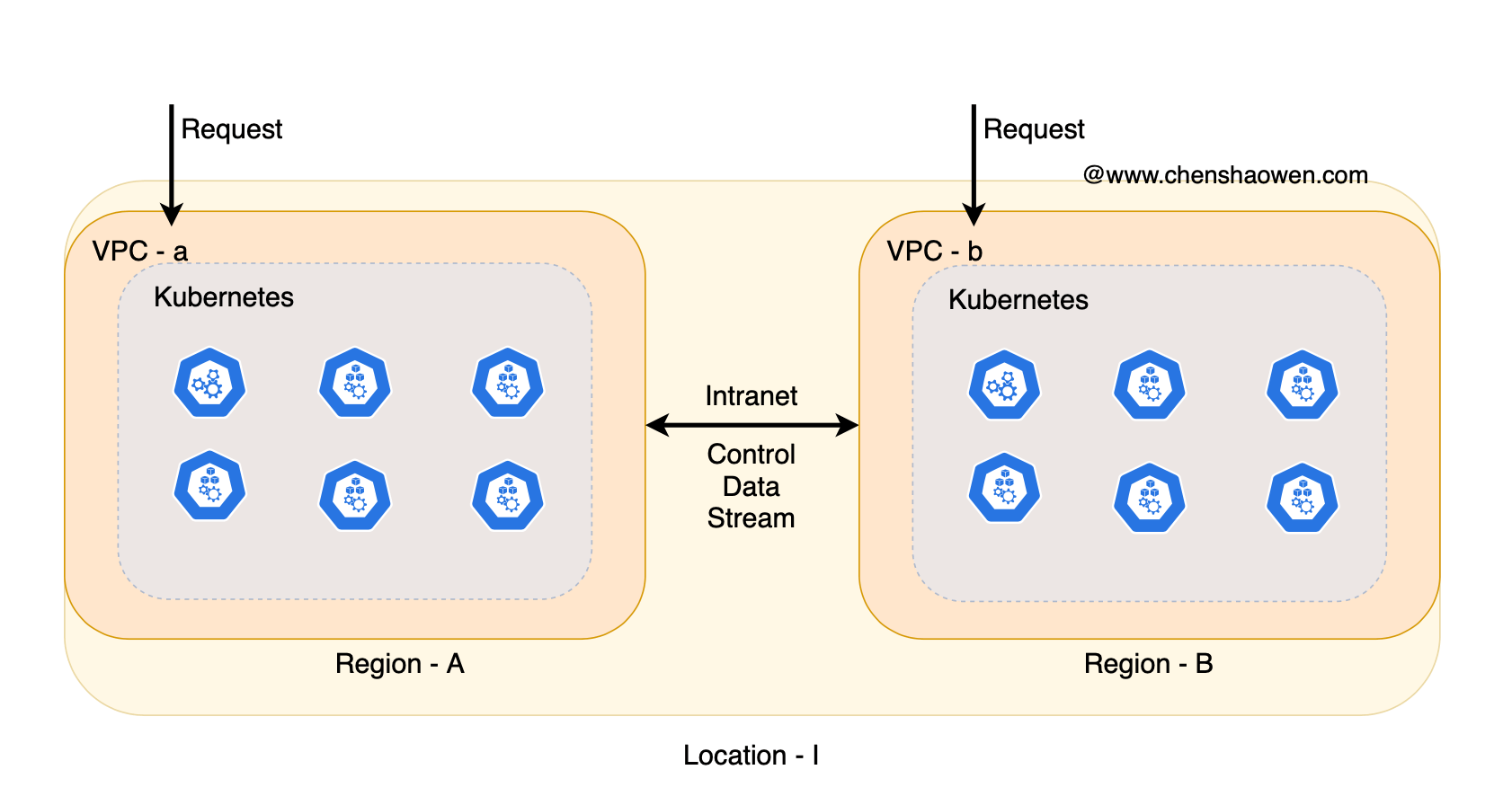
In a Location, we divide a number of Regions, each Region is a large cluster, and the Regions are interconnected with the Regions through intranet lines, which can transmit both control flow and user data.
Of course, if the business architecture is unitized, then each cluster is a Unit. This is not only clearer for developers, but also allows operations staff to quickly understand the architecture and integrate into the team, regardless of whether they are familiar with Kubernetes or not.
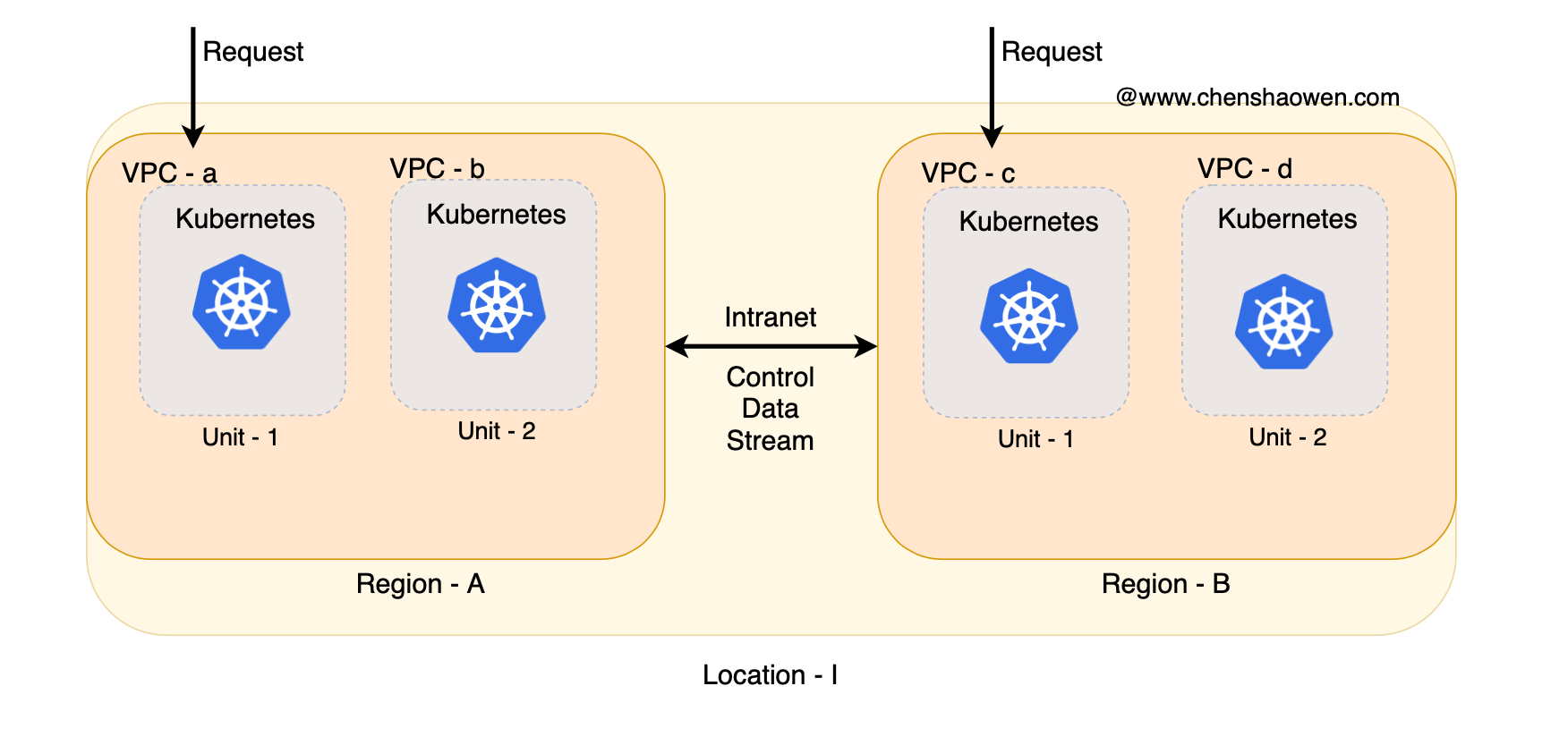
As shown in the figure above, a Region contains several units. These units belong to different environments and different businesses, but they are architecturally equivalent, and through the unified platform software, we can manage these units without any differences.
5. Summary
This article has mainly covered some thoughts on deploying Kubernetes in multiple regions. They originated from an application architecture overhaul that I was going through at work. I put the overseas and domestic business and application architectures together and found that they were just at different business stages and were consistent in terms of architectural evolution.
Initially, the business volume was small, and many small Kubernetes clusters were quickly deployed to bring the business online; as the operation and maintenance capabilities improved, the cluster size became larger and larger; however, it was impossible to go on indefinitely, and eventually it would return to a scalable unitized cluster solution.