1. Why do you need secondary scheduling
The role of the Kubernetes scheduler is to bind Pods to a particular best-of-breed node. In order to do this, the scheduler needs to perform a series of filters and scoring.
Kubernetes scheduling is based on Request, but the actual usage values of each Pod are dynamically changing. After a period of time, the load on the nodes is uneven. Some nodes are overloaded, while others are underused.
Therefore, we need a mechanism that allows Pods to be dynamically distributed across the cluster nodes in a healthier and more balanced way, rather than being fixed to a single host after a one-time scheduling.
2. Several ways to run descheduler
descheduler is a subproject under kubernetes-sigs, so clone the code locally and go to the project directory:
If the runtime environment cannot pull the gcr image, you can replace k8s.gcr.io/descheduler/descheduler with k8simage/descheduler.
-
One-time Job
Execute once only.
-
Timed tasks CronJob
Default is
*/2 * * * * *Execute every 2 minutes. -
Permanent assignment Deployment
The default is
-descheduling-interval 5m, which is executed every 5 minutes. -
CLI command line
Generate the policy file locally first, and then execute the
deschedulercommand.1descheduler -v=3 --evict-local-storage-pods --policy-config-file=pod-life-time.yml
descheduler has the --help parameter to see the help documentation.
|
|
3. Testing the effect of scheduling
-
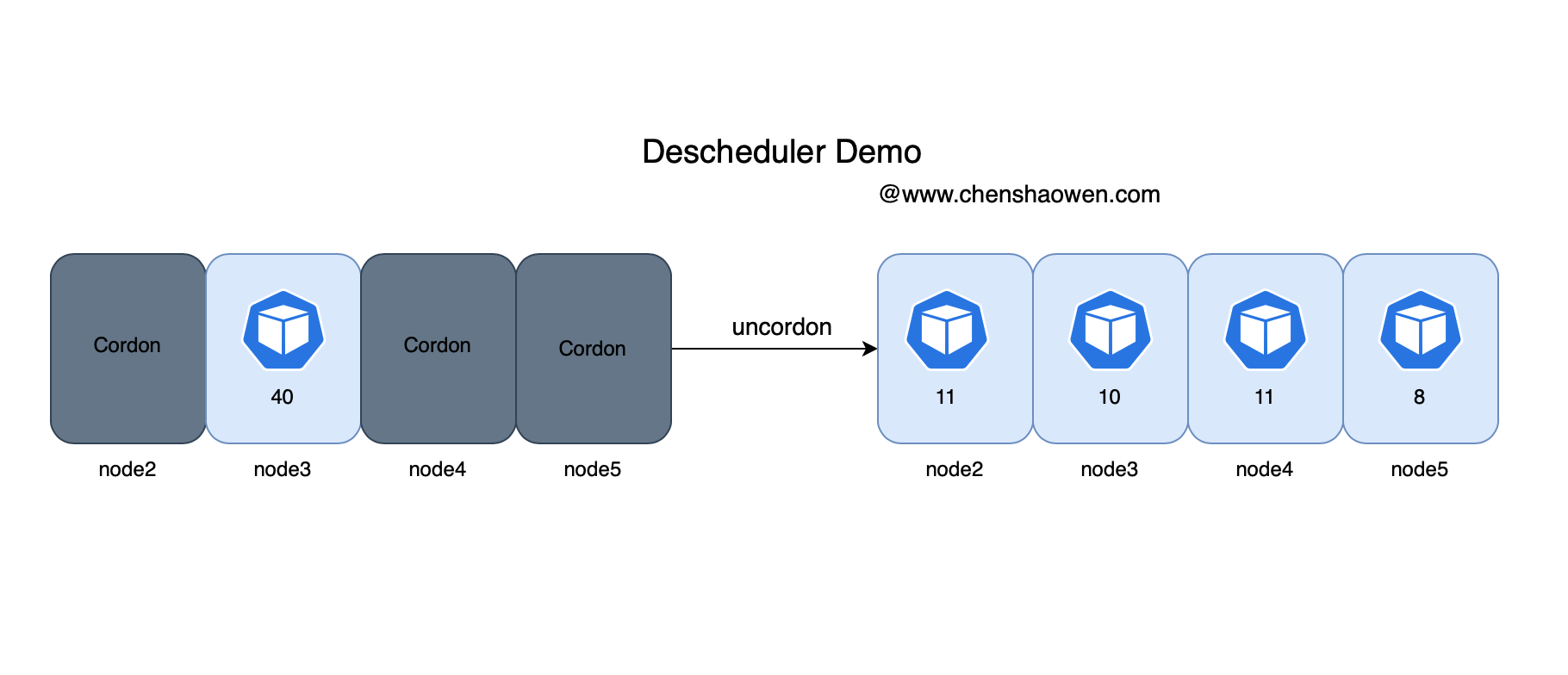
cordon partial nodes, allowing only one node to participate in scheduling.
-
Run a 40-copy-count application
You can observe that the copies of this application are all on the node3 node.
-
Deploying descheduler in a cluster
The Deployment method is used here.
-
Release node scheduling
Before scheduling, all replicas are concentrated in the node3 node.
Release node scheduling
-
View descheduler related logs
When the timing requirements are met, the descheduler will start evicting Pods based on the policy.
1 2 3 4 5 6 7 8 9 10 11 12kubectl -n kube-system logs descheduler-8446895b76-7vq4q -f I0610 10:00:26.673573 1 event.go:294] "Event occurred" object="default/nginx-645dcf64c8-z9n8k" fieldPath="" kind="Pod" apiVersion="v1" type="Normal" reason="Descheduled" message="pod evicted by sigs.k8s.io/deschedulerLowNodeUtilization" I0610 10:00:26.798506 1 evictions.go:163] "Evicted pod" pod="default/nginx-645dcf64c8-2qm5c" reason="RemoveDuplicatePods" strategy="RemoveDuplicatePods" node="node3" I0610 10:00:26.799245 1 event.go:294] "Event occurred" object="default/nginx-645dcf64c8-2qm5c" fieldPath="" kind="Pod" apiVersion="v1" type="Normal" reason="Descheduled" message="pod evicted by sigs.k8s.io/deschedulerRemoveDuplicatePods" I0610 10:00:26.893932 1 evictions.go:163] "Evicted pod" pod="default/nginx-645dcf64c8-9ps2g" reason="RemoveDuplicatePods" strategy="RemoveDuplicatePods" node="node3" I0610 10:00:26.894540 1 event.go:294] "Event occurred" object="default/nginx-645dcf64c8-9ps2g" fieldPath="" kind="Pod" apiVersion="v1" type="Normal" reason="Descheduled" message="pod evicted by sigs.k8s.io/deschedulerRemoveDuplicatePods" I0610 10:00:26.992410 1 evictions.go:163] "Evicted pod" pod="default/nginx-645dcf64c8-kt7zt" reason="RemoveDuplicatePods" strategy="RemoveDuplicatePods" node="node3" I0610 10:00:26.993064 1 event.go:294] "Event occurred" object="default/nginx-645dcf64c8-kt7zt" fieldPath="" kind="Pod" apiVersion="v1" type="Normal" reason="Descheduled" message="pod evicted by sigs.k8s.io/deschedulerRemoveDuplicatePods" I0610 10:00:27.122106 1 evictions.go:163] "Evicted pod" pod="default/nginx-645dcf64c8-lk9pd" reason="RemoveDuplicatePods" strategy="RemoveDuplicatePods" node="node3" I0610 10:00:27.122776 1 event.go:294] "Event occurred" object="default/nginx-645dcf64c8-lk9pd" fieldPath="" kind="Pod" apiVersion="v1" type="Normal" reason="Descheduled" message="pod evicted by sigs.k8s.io/deschedulerRemoveDuplicatePods" I0610 10:00:27.225304 1 evictions.go:163] "Evicted pod" pod="default/nginx-645dcf64c8-mztjb" reason="RemoveDuplicatePods" strategy="RemoveDuplicatePods" node="node3" -
Pod distribution after secondary scheduling
The load on the nodes, node3 is down and all other nodes are up a bit.
Pod distribution on nodes, this is in the scenario where no affinity, anti-affinity is configured.
Nodes Number of Pods (40 copies in total) node2 11 node3 10 node4 11 node5 8
The number of Pods is very evenly distributed, with node2-4 VMs having the same configuration and node5 having a lower configuration. The following diagram illustrates the entire process.
4. descheduler Scheduling Policy
Check the default policy configuration recommended by the official repository.
|
|
RemoveDuplicates, RemovePodsViolatingInterPodAntiAffinity, and LowNodeUtilization policies are enabled by default. We can configure them according to the actual scenario.
The descheduler currently provides the following scheduling policies:
-
RemoveDuplicates
Remove multiple Pods on the same node
-
LowNodeUtilization
Find low-load nodes and evict Pods from other nodes
-
HighNodeUtilization Find high-load nodes and evict the Pods on them
-
RemovePodsViolatingInterPodAntiAffinity
Expel Pods that violate Pod anti-affinity
-
RemovePodsViolatingNodeAffinity
Evicts Pods violating Node AntiAffinity
-
RemovePodsViolatingNodeTaints
Pods that violate the NoSchedule taint
-
RemovePodsViolatingTopologySpreadConstraint
Evict Pods that violate topology domains
-
RemovePodsHavingTooManyRestarts
Evicts Pods with too many restarts
-
PodLifeTime
Evict Pods that have been running for more than the specified amount of time
-
RemoveFailedPods
Evict Pods with failed status
5. What are the scenarios for descheduler
The perspective of descheduler is dynamic, which includes two aspects: Node and Pod. descheduler is dynamic in the sense that when the label, taint, configuration, number, etc. of Node changes, Pod is dynamic in the sense that the actual resource usage, distribution on Node, etc. of Pod is not constant.
Based on these dynamic characteristics, the following scenarios can be summarized as applicable.
- A new node is added
- After a node restart
- After modifying the node topology domain and taint, we hope the stock Pods can also meet the topology domain and taint.
- Pods are not evenly distributed among different nodes
If the actual usage of Pods far exceeds the Reqeust value, a better approach is to adjust the Request value instead of re-scheduling Pods.