C++11 includes multithreading as a standard. Once multi-threading is involved, there are issues such as concurrency, data race, thread synchronization, etc. C++ provides standard libraries such as std::mutex and std::atomic for this purpose. One important concept for manipulating atomic variables is memory order, which involves many concepts and can be difficult to understand. In this article, we will talk about this topic.
This article may be a bit long and involve a lot of concepts. Sections 3.4 and 3.5 are marked with an asterisk, but they have few practical applications and can be skipped if you are not interested.
1. Atomic variables
We cannot access and modify a variable in two threads at the same time, which can lead to data competition problems. The result of the program is undefined. Implementation-wise, we cannot guarantee that read and write operations are atomic, e.g. on a 32-bit machine, it may take two instructions to modify a 64-bit variable; or the variable may be in a register, and changes to it will not be written to memory until later. The solution to data contention is to use atomic variables in addition to locking with std::mutex.
The above example shows the simplest use of an atomic variable. You don’t have to worry about data contention with atomic variables, and all operations on them are atomic. In addition, the operation of atomic variables can specify memory order, which helps us to synchronize threads, which is the focus of this article. In the above code, thread 1 writes the value to the atomic variable a, and thread 2 reads the value in a. These are the two most basic operations on atomic variables.
1.1 Operations on atomic variables
The operations on atomic variables can be divided into three types
- store. Saves a value into an atomic variable.
- load. Reads the value from an atomic variable.
- read-modify-write (RMW). Reads, modifies and writes atomically. Examples include
fetch_add,exchange(returns the current value of a variable and writes the specified value), etc.
Each atomic operation needs to specify a memory order). Different memory orders have different semantics, implement different order models, and have different performance. There are six types of memory order in C++.
These six memory orders can be combined with each other to achieve three ordering models
- Sequencial consistent ordering. A model that achieves synchronization and guarantees a single total order. It is the most consistent model, and the default ordering model.
- Acquire-release ordering. A model that implements synchronization, but does not guarantee global order consistency.
- Relaxed ordering. A model that does not implement synchronization, but only guarantees atomicity.
We will discuss these six types of memory ordering in more detail later. The atomic::store and atomic::load functions both have a memory order argument, which defaults to memory_order_seq_cst. They are declared as follows
In addition, std::atomic overloads the operators so that we can read and write atomic variables as if they were normal variables. For example, in the above code, the two threads are calling std::atomic<int>::operator=(int) and std::atomic<int>::operator int() respectively. This uses the default memory order, which is memory_order_seq_cst.
2. Basic Concepts
Before we start talking about the six types of memory orders, it is important to understand a few basic concepts.
2.1 Modification orders
There is always a certain order in which all modifications to an atomic variable are performed, and this order is agreed upon by all threads, even if the modifications are performed in different threads. This order, which all threads agree on, is called the modification order. This means that
- two modifications cannot be performed at the same time, there must be an order of precedence. This is easy to understand, because it is a requirement for atomic operations, otherwise there would be data contention.
- Even though the order of modifications may be different for each run, all threads always see the same order of modifications. If thread a sees the atomic variable x change from 1 to 2, then thread b cannot see x change from 2 to 1.
Regardless of the memory order used, atomic variable operations will always satisfy the consistency of the modification order, even in the loosest memory_order_relaxed. Let’s look at an example.
|
|
The above code creates 4 threads. thread1 and thread2 write even and odd numbers to the atomic variable a, respectively, and thread3 and thread4 read them in turn. Finally, the values of thread3 and thread4 are output each time they are read. The program may look like this.
Although the order of changes varies from run to run, and it is unlikely that each thread will see the results of each change, they will see the same order of changes. For example, if thread3 sees 8 before 9, thread4 will also see 8 before 9, and vice versa.
2.2 Happens-before
Happens-before is a very important concept. If operation a “happens-before” operation b, then the result of operation a is visible to operation b. The happens-before relationship can be established between two operations using one thread, or between two operations in different threads.
2.2.1 The single-threaded case: sequenced-before
The single-threaded case is easy to understand. The statements of a function are executed sequentially, with the previous statements executed first and the later ones executed later. Formally, the preceding statement is always “sequenced-before “ the following statement. Clearly, by definition, sequenced-before is transitive:
- If operation a “sequenced-before” operates on k, and operation k “sequenced-before” operates on b, then operation a “sequenced-before” operates on b.
Sequenced-before can directly form the happens-before relation. If operation a “sequenced-before” operates on b, then operation a “happens-before” operates on b. For example
Statement (1) precedes statement (2), so statement (1) “sequenced-before” statement (2), which is also (1) “happens-before” statement (2). So (2) prints the result of the assignment of (1).
2.2.2 The multi-threaded case: synchronizes-with and inter-thread happens-before
The multithreaded case is a little more complicated. Generally, multiple threads are executed concurrently, and without proper synchronization, there is no guarantee that there is a happens-before relationship between the two operations. If we synchronize two operations in different threads by some means, we say that the two operations have a synchronizes-with relationship. Later we will discuss in detail how to combine the 6 memory orders to make a synchronizes-with relationship between two operations.
If operation a in thread 1 “synchronizes-with” operation b in thread 2, then operation a “inter-thread happens-before “ operation b. In addition, synchronizes-with can be “followed” by a sequenced-before relationship as inter-thread happens-before relationship:
- If operation a “synchronizes-with” operation k, and operation k “sequenced-before” operation b, then operation a “inter-thread happens-before” operation b.
The inter-thread happens-before relation can then be “prepended” to a sequenced-before relation to extend its scope; and the inter-thread happens-before relation is transitive:
- If operation a “sequenced-before” operates on k, and operation k “inter-thread happens-before” operates on b, then operation a “inter-thread happens-before” operates on b. * If operation a “inter-thread happens-before” operates on k, then operation a “inter-thread happens-before” operates on b.
- If operation a “inter-thread happens-before” operation k, and operation k “inter-thread happens-before” operation b, then operation a “inter-thread happens-before” operation b.
As its name implies, if operation a “inter-thread happens-before” operation b, then operation a “happens-before” operation b. The following diagram illustrates the relationship between these concepts:
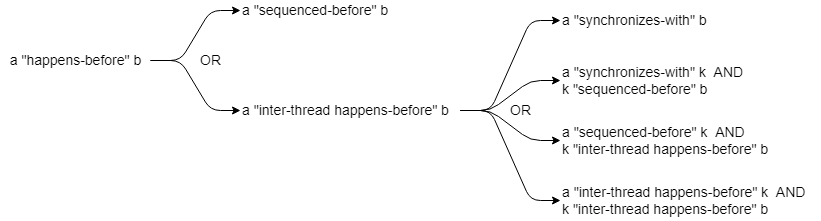
Note that while sequenced-before and inter-thread happens-before are both transferable, happens-before is not. We will see the importance of this property later in Section 3.5, and why C++ defines so many concepts.
Now let’s look at an example. Suppose the following code has the unlock() operation “synchronizes-with” the lock() operation.
Assume that thread2 blocks in lock() at (3) until thread1 reaches (2). Then we can deduce:
- Depending on the order of the statements, there are (1) “sequenced-before” (2) and (3) “sequenced-before” (4);
- Because (2) “synchronizes-with” (3) and (3) “sequenced-before” (4), so (2) “inter-thread happens-before” (4);
- because (1) “sequenced-before” (2) and (2) “inter-thread happens-before” (4), so (1) “inter-thread happens-before” (4); so (1) “happens-before” (4).
Therefore (4) can read the changes made by (1) to the variable a.
2.3 Happens-before does not represent the actual order of execution of instructions
It is important to note that happens-before is a C++ semantic concept and does not represent the actual order of execution of instructions in the CPU. To optimize performance, the compiler will reorder instructions without breaking the semantics. For example
Although there is a++; “happens-before” b++; , the actual instructions generated by the compiler may load a and b variables into registers, then perform “plus one” operations, then perform a + b, and finally write the result of the self-increment to memory.
The above shows one possible compilation result under x86-64. You can see that a C++ statement can generate multiple instructions, all of which are interleaved. In fact, the compiler may even increment b and then a. This rearrangement does not affect the semantics, and the result of the two self-increment operations is still visible for return a + b;.
3. Memory order
We mentioned earlier that C++’s six memory orders can be combined with each other to implement three sequential models. Now let’s look at how these six memory orders are used, and how they can be combined to achieve a synchronizes-with relationship.
3.1 memory_order_seq_cst
memory_order_seq_cst can be used for store, load and read-modify-write operations to implement a sequencial consistent sequential model. In this model, all operations seen by all threads have a consistent order, even though the operations may target different variables and run in different threads. In Section 2.1 we introduced the modification order, where the modification order of a single variable is consistent across all threads. Sequencial consistency extends this consistency to all variables. For example
thread1 and thread2 modify the atomic variables x and y, respectively. During the run, it is possible to execute (1) first and then (2), or to execute (2) first and then (1). But in any case, the order seen in all threads is the same. So if we test this code like this:
|
|
The assertion at (7) never fails. Since the modification order of x and y is globally consistent, if (1) is executed first and then (2), then when loop (5) in read_y_then_x exits, y is guaranteed to be true, so x must also be true, and therefore (6) will be executed; similarly, if (2) is executed first and then (1), then y must also be true when loop (3) exits, so (4) will be executed. will be executed. In any case, z will not end up equal to 0.
Sequencial consistency allows for a synchronizes-with relationship. If a memory_order_seq_cst load operation reads the value written to an atomic variable by a memory_order_seq_cst store operation on that atomic variable, the store operation “synchronizes-with” the load operation. In the above example, there are (1) “synchronizes-with” (3) and (2) “synchronizes-with” (5).
There is some overhead in implementing a sequencial consistent model. Modern CPUs usually have multiple cores, each with its own cache. To achieve global sequential consistency, each write operation must be synchronized to the other cores. To reduce the performance overhead, if global sequential consistency is not needed, we should consider using a more relaxed sequential model.
3.2 memory_order_relaxed
memory_order_relaxed can be used for store, load and read-modify-write operations to implement the relaxed order model. In this model, only atomicity and modification order of operations are guaranteed, and no synchronizes-with relationship can be achieved. For example
thread1 performs store operations on different variables. Then, in some threads, it may look like x first becomes true and y later becomes true; in other threads, it may look like y first becomes true and x later becomes true. If you test this code like this.
The assertion at (4) is likely to fail. Since there is no synchronizes-with relationship between (2) and (3), it is not guaranteed that (1) “happens-before” (4). Therefore (4) may read false. An example of the consistency of the modification order guaranteed by the relaxed sequential model was discussed in Section 2.1, and will not be repeated here.
The overhead of the relaxed sequential model is small. On the x86 architecture, the memory_order_relaxed operation does not generate any other instructions, and only affects compiler optimizations to ensure that operations are atomic. The Relaxed model can be used in scenarios where thread synchronization is not required, but care should be taken when using it. For example, std::shared_ptr is used to increase the reference count because it does not need to be synchronized; but it cannot be used to reduce the application count because it needs to be synchronized with the destructor operation.
3.3 Acquire-release
In the acquire-release model, the three memory orders memory_order_acquire, memory_order_release and memory_order_acq_rel are used. Here’s how they are used:
- The
memory_order_acquirememory order can be used for loads of atomic variables. This is called the acquire operation. - Store of atomic variables can use
memory_order_releasememory order. This is called the release operation. - The read-modify-write operation is both read (load) and write (store), and it can use
memory_order_acquire,memory_order_releaseandmemory_order_acq_rel:- If
memory_order_acquireis used, it acts as an acquire operation; - If
memory_order_releaseis used, it is a release operation; - If
memory_order_acq_relis used, then both.
- If
Acquire-release can implement a synchronizes-with relationship. If an acquire operation reads the value written by a release operation on the same atomic variable, the release operation “synchronizes-with” the acquire operation. Let’s look at an example:
In the above example, statement (2) uses memory_order_release to write true to y, and statement (3) uses memory_order_acquire to read the value from y. When loop (3) exits, it has already read the value of y as true, i.e., it has read the value written in operation (2). Therefore, it has (2) “synchronizes-with” (3). We can deduce this according to the rules described in Section 2.2:
- Because (2) “synchronizes-with” (3) and (3) “sequenced-before” (4), so (2) “inter-thread happens-before” (4);
- Because (1) “sequenced-before” (2) and (2) “inter-thread happens-before” (4), therefore (1) “inter-thread happens-before” (4);
so (1) “happens-before” (4). Therefore (4) can read the value written in (1), and the assertion will never fail. Even though (1) and (4) use memory_order_relaxed.
In Section 3.1 we mentioned that the sequencial consistent model can implement the synchronizes-with relationship. In fact, a load operation and a store operation with memory order memory_order_seq_cst can be considered as an acquire operation and a release operation, respectively. Therefore, for two store and load operations with memory_order_seq_cst specified, if the latter reads the value written by the former, the former “synchronizes-with” the latter.
To implement the synchronizes-with relationship, the acquire and release operations should appear in pairs. If the load of memory_order_acquire reads the value written by the store of memory_order_relaxed, or the load of memory_order_relaxed reads the value written by the store of memory_order_release, Neither can achieve a synchronizes-with relationship.
While the sequencial consistent model can synchronize as well as acquire-release, the acquire-release model does not provide global sequential consistency as well as sequencial consistent. If we replace memory_order_seq_cst with memory_order_acquire and memory_order_release in the example in Section 3.1, we will be able to achieve synchronization in the same way as sequencial release.
|
|
In the same run, read_x_then_y may see (1) before (2), while read_y_then_x may see (2) before (1). It is possible that the result of both (4) and (6) loads will be false, resulting in z remaining at 0.
Acquire-release has less overhead than sequencial consistent. In the x86 architecture, the memory_order_acquire and memory_order_release operations do not generate any other instructions, but only affect the compiler’s optimization: no instruction can be reordered before an acquire operation and no instruction can be reordered after a release operation; otherwise, the semantics of otherwise the semantics of acquire-release would be violated. Therefore, many scenarios that require a synchronizes-with relationship will use acquire-release.
3.4* Release sequences
As we have seen so far, for either sequencial consistent or acquire-release to have a synchronizes-with relationship, the acquire operation must read the value written by the release operation on the same atomic variable. If the acquire operation does not read the value written by the release operation, then there is usually no synchronizes-with relationship between the two. For example
|
|
In the above example, loop (4) exits as soon as the value of y is not 0. When it exits, it may read the value written in (2), or it may read the value written in (3). In the latter case, it is only guaranteed that (3) “synchronizes-with” (4), not that there is a synchronization relationship between (2) and (4). Therefore, the assertion at (5) may fail.
However, the synchronizes-with relationship is not only formed when the acquire operation reads the value written by the release operation. To account for this, we need to introduce the concept of release sequence.
After a release operation A on an atomic variable M completes, a sequence of other operations on M may follow. If this sequence of operations is performed by
- a write operation on the same thread, or
- read-modify-write operations on any thread
on any thread, then the sequence is called a release sequence headed by release operation A. The write and read-modify-write operations can use any memory order.
If an acquire operation reads a value written by a release operation on the same atomic variable, or reads a value written by a release sequence headed by this release operation, then the release operation “synchronizes-with” the acquire operation. Let’s look at an example
|
|
In the above example, compare_exchange_strong at (3) is a read-modify-write operation that determines whether the value of the atomic variable is equal to the expected value (first argument), and if so, sets the atomic variable to the target value (second argument) and returns true, otherwise it sets the first argument (reference passed) is set to the current value of the atomic variable and false is returned. Operation (3) keeps looping through it, replacing flag with 2 when the value is 1. So (3) is part of the release sequence of (2). And when loop (4) exits, it has already read the value written by (3), which is the value written by the release sequence headed by release operation (2). So we have (2) “synchronizes-with” (4). So (1) “happens-before” (5), and the assertion at (5) does not fail.
Note that the memory order of compare_exchange_strong in (3) is memory_order_relaxed, so (2) and (3) do not form a synchronizes-with relationship. That is, when loop (3) exits, there is no guarantee that thread2 will read data.at(0) as 42. But (3) belongs to the release sequence of (2), and when (4) reads the value written to the release sequence of (2) in the memory order of `memory_order_acquire can form a synchronizes-with relationship with (2).
3.5* memory_order_consume
memory_order_consume is actually part of the acquire-release model, but it is special in that it involves interdependencies between data. For this reason, we will introduce two new concepts: carries dependency and dependency-ordered before.
If operation a “sequenced-before” b, and b depends on data from a, then a “carries a dependency into” b. In general, b is said to depend on a if the value of a is used as an operand of b, or if b reads the value written by a. For example
has (1) “sequenced-before” (2) “sequenced-before” (3); the values of (1) and (2) are used as operands of the subscript operator [] in (3), so there are (1) “carries a dependency into” (3) and (2) “carries a dependency into” (3). But (1) and (2) do not depend on each other, they do not carry a dependency into each other. Similar to sequenced-before, the carries dependency relationship is transitive.
memory_order_consume can be used for load operations. A load using memory_order_consume is called a consume operation. A consume operation is “dependent-ordered before” a consume operation if it reads a value written by a release operation on the same atomic variable, or a value written by a release sequence headed by it.
Dependency-ordered before can be “followed” by a relation that carries dependency to extend its scope: if a “depends-ordered before” k and k “carries a dependency into” b, then a " dependency-ordered before” b. Dependency-ordered before can directly form the inter-thread happens-before relation: if a “dependency-ordered before” b then a “inter-thread happens-before” b. If a “dependency-ordered before” b then a “inter-thread happens-before” b. thread happens-before” b.
The concept is complex, but the basic idea is:
- synchronizes-with, which is a release and acquire operation, can be followed by sequenced-before to form an inter-thread happens-before relationship;
- The dependency-ordered before of the release and consume operations can only be followed by the carries dependency to form the inter-thread happens-before relationship.
- Regardless of how inter-thread happens-before is constructed, it can be preceded by sequenced-before to extend its scope.
Let’s look at an example:
|
|
When the loop exits at (4), the consume operation (4) reads the value written by the release operation (3), so (3) is “dependent-ordered before” (4). This leads to the derivation:
- The value of
p2is the operand of (5), so (4) “carries a dependency into” (5); - Because (3) “depends-ordered before” (4) and (4) “carries a dependency into” (5), so (3) “inter-thread happens-before” (5);
- Because (1) “sequenced-before” (3) and (3) “inter-thread happens-before” (5), so (1) “inter-thread happens-before” (5);
so (1) “happens-before” (5). So (5) can read the value written by (1), asserting that (5) will not fail. But operation (6) does not depend on (4), so there is no inter-thread happens-before relationship between (3) and (6), so assertion (6) may fail. Recall from Section 2.2 that happens-before has no transferability. So it cannot be said that because (3) “happens-before” (4) and (4) “happens-before” (6) that (2) “happens-before” (6).
Similar to acquire-release, the use of memory_order_consume under x86 does not generate any other directives, but only affects compiler optimizations. Instructions that have dependencies on the consume operation are not reordered ahead of the consume operation. The restrictions on reordering are more relaxed than for acquire, which requires that all instructions not be reordered before it, while consume requires that only dependent instructions not be reordered before it. Therefore, in some cases, consume may have higher performance.
4. Some examples
Having covered a lot of concepts and theory, let’s now look at two practical examples to deepen our understanding.
4.1 Spin locks
In some scenarios, if the lock is occupied for a short time, we choose a spinlock to reduce the overhead of context switching. Locks are generally used to protect critical data from being read or written, and we want only one thread to have access to the lock at the same time, and the data protected by the lock to be always up-to-date when the lock is acquired. The former is guaranteed by atomic operations, while the latter requires consideration of memory order.
|
|
Two threads are running concurrently, thread1 writes data to the queue and thread2 reads data from the queue. The in-queue operation (2) may require copying data, moving pointers, or even resizing the queue, so we need to ensure that the results of these operations are fully visible when the lock is acquired. The same goes for the out-queue operations. So the spinlock has to ensure that the unlock operation “synchronizes-with” the lock operation, and that the data protected by the lock is complete.
We can use the acquire-release model to implement spin locks. Here is a simple implementation:
In the above implementation, the exchange used for locking at (1) is a read-modify-write operation that writes the target value (the first argument) to an atomic variable and returns the value before it was written. In this implementation, flag is true when the lock is occupied. If the lock is occupied, the exchange operation at (1) keeps returning true and the thread blocks in the loop; until the lock is released, flag is false and the exchange operation resets flag to true to seize the lock and returns its original value of false, the loop exits, and locking is successful. Unlocking is as simple as setting flag to false.
Since the unlock operation uses memory_order_release and the lock operation uses memory_order_acquire, it is guaranteed that the unlock operation is “synchronizes-with” the previous unlock operation, i.e. the unlock operation “synchronizes- with” lock operation.
The exchange operation during locking is a read-modify-write operation, which reads and writes at the same time. When it uses memory_order_acquire, only the part it reads is guaranteed to be an acquire operation. If there are two threads acquiring the same lock.
There is no synchronization between (1) and (2), and assuming that operation (1) is executed before operation (2), the result of the operation before (1) in thread1 is not necessarily visible to thread2. What is certain is that only one thread will get the lock, which is guaranteed by the modification order of the atomic variables. Either thread1 will set flag to true first, or thread2 will set flag to true first, and this order is globally consistent.
4.2 Thread-safe singleton pattern
The singleton pattern is a very common design pattern. We usually use a static member pointer to store a unique instance of the class, and then use a static member function to get it, or create it if the pointer is empty.
But this approach has concurrency problems with multiple threads. The easiest way to solve this problem is to add a lock. However, it is not necessary to lock the entire function, because the concurrency problem only arises when the object is initially created, and later when only the pointer is returned, which causes an unnecessary performance burden. A better approach would be to add locks only when the object is to be created, which we can do.
In the above implementation, if the instance pointer is found to be empty, a lock is added and the object is created. After the lock is acquired, it is necessary to determine if instance is empty, in case another thread creates the object after (1) and before the lock is acquired. But this is problematic: (1) is not protected by a lock, and it may be concurrent with (2), leading to data contention.
We can solve this problem by using atomic variables, changing the instance pointer to the atomic type std::atomic<App*>. What memory order should be used when reading and writing instance, and will memory_order_relaxed work?
|
|
Suppose thread 1 calls get_instance, finds that the object is not created, then successfully obtains a lock and creates the object, then executes (3) to write the pointer to the new object into instance; then thread 2 also calls get_instance and executes (1) to read the value written by thread 1 in operation (3), can we guarantee that the pointer we get p is valid?
Note that thread 1 needs to call the constructor to initialize the members of App when it executes p = new App. Since (1) and (3) are both memory_order_relaxed memory orders, there is no synchronizes-with relationship between them. So when thread 2 reads the pointer written by thread 1 during operation (1), there is no guarantee that the initialization of the App member will be visible to thread 2. This results in thread 2 getting incomplete object data, which can lead to very unexpected results.
The correct approach is to use the acquire-release model:
|
|
So when thread 2 reads the pointer written by thread 1 in operation (1), it has (3) “synchronizes-with” (1). So the result of thread 1 initializing the App member is visible to thread 2, which returns p without any problems.
Operation (2) still uses memory_order_relaxed, because it is protected by a lock, which guarantees thread synchronization, so there is no problem.
5. Summary
To summarize these memory order models:
memory_order_release: the most relaxed memory order, guaranteeing only atomicity and modification order of operations.memory_order_acquire,memory_order_releaseandmemory_order_acq_rel: implements acquire operations and release operations, if the acquire operation reads the value written by the release operation, or its If the acquire operation reads the value written by the release operation, or the value written by its release sequence, then it constitutes a synchronizes-with relationship, which leads to a happens-before relationship.memory_order_consume: implements the consume operation, which enables data-dependent synchronization relationships. If the consume operation reads the value written by the release operation, or the value written by its release sequence, it constitutes a dependency-ordered before relationship, which can be derived from the happens-before relationship for operations that have data dependencies.memory_order_seq_cst: an enhanced version of the acquire-release model, which not only implements synchronizes-with relationships, but also guarantees global order consistency.
6. Extended Reading
For some concepts, such as sequenced-before and carries dependency, this article only describes a few simple cases, and does not give a strict definition. In practice we don’t usually need to consider their strict definitions, but if you need to understand them or are interested in them, you can refer to cppreference.com.
C++ also has some features regarding memory order that are not mentioned in this article, such as memory fences. C++’s atomic variables also provide many operations, but only some of them are mentioned in this article. For those who are interested or need to know more about them, see C++ Concurrency in Action and cppreference.com. For lack of space, some parts of this article may not be sufficiently detailed or well-defined. For a strict definition of the concept, see cppreference.com; for a more detailed explanation, see C++ Concurrency in Action.