Recently, I received a business requirement that I need a batch export image function. It was suggested that the download task should be submitted to the server side, which would complete the packaging and then give the download link. I personally feel that this function can be implemented directly in the browser. So I did some research and found a feasible solution. Today, I will share it with you.
The solution presented in this article uses Chrome’s proprietary API, so it will not work properly with Firefox 😂.
The first thing I thought of was using the File System Access API. I thought I could use the File System Access API to get write access to a local folder, and then create and save the exported images in that folder via JavaScript. But after researching, I found that the File System Access API can only save files via showSaveFilePicker(), and every time I call it, a file selection dialog will pop up for the user to confirm. So it is not possible to achieve the function of batch saving.
Since you can only save one file at a time, you have to package all the images into one file to save them. So I came up with the Zip file format. However, the business side suggested that the total size of the images exported at one time could reach several G’s in size. If we operate purely in memory, then we might run out of system memory. So we must design a streaming solution. So I came up with Streams API.
Before trying to use streams, I also had to find out if the Zip file format supported streams. After a bit of searching, I found the structure of a Zip file.
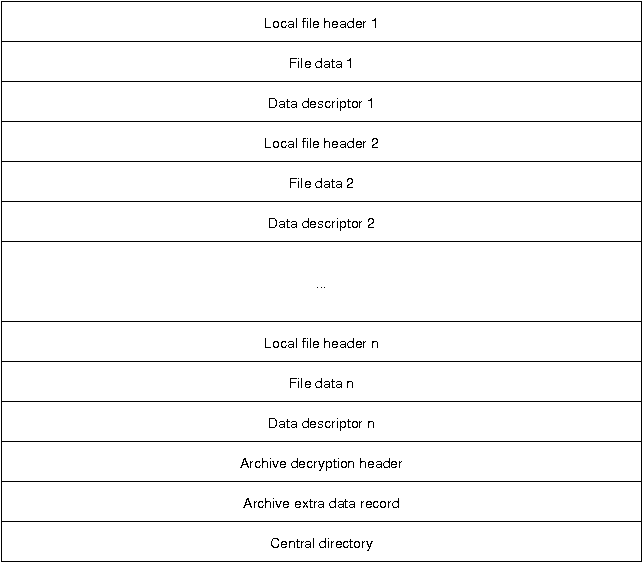
Image from Florian Buchholz’s article The structure of a PKZip file.
Simply put, a Zip is a packing pattern in which each file contains three parts.
- local file header
- File data
- data descriptor
After all the data is saved, there are three additional sections of information at the end of the file:
- Archive description header
- Archive extra data record
- central directory
The last of these is the Central directory, which holds information about the directory of each file. They are referenced as follows.
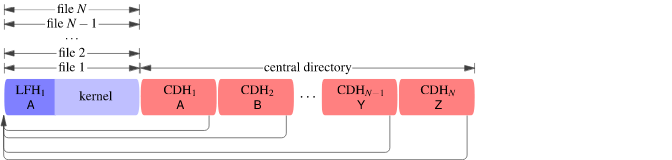
Image from David Fifield’s article A better zip bomb
By this point, I was able to determine that Zip files do support streaming.
Now the idea is clear. First, we create a new file via the showSaveFilePicker interface and get the corresponding WriteStream, then we create a Zip file Stream and bind to it, and finally we download the image using fetch in turn, redirecting the corresponding ReadeStream to the previous Zip Stream.
The operation of creating a file is relatively simple.
Then it’s time to create the Zip file stream. Here I borrowed the implementation from StreamSaver.js.
|
|
Since it is pure front-end code, you can experience the effect of using this solution in Chrome.
Since Firefox does not support the File System Access API, the solution presented in this article will not work within Firefox. If you must support Firefox, you can use the aforementioned StreamSaver.js.
The idea of StreamSaver.js is also very clever. It uses a service worker to intercept the fetch call and write the Zip stream to the file to be downloaded via respondWith. The advantage of this solution is that it supports browsers such as Firefox, but the disadvantage is also obvious: the whole implementation is very complex and needs to deal with logic such as communication with the service worker and worker retention. In comparison, the solution based on the File System Access API is significantly cleaner.
Finally, a reminder that the Zip format does not specify the encoding of the file name. If the exported file name has Chinese characters, it may be garbled. Therefore, for Windows platform, it is recommended to convert to GBK encoding. The zip-stream library used in this article only supports UTF-8 encoding.