What is OpenEBS?
OpenEBS is an open source cloud native storage solution hosted at the CNCF Foundation, which is currently in the sandbox phase of the project.
OpenEBS is a set of storage engines that allow you to choose the right storage solution for stateful workloads (StatefulSet) and Kubernetes platform types. At a high level, OpenEBS supports two main types of volumes - local and replicated volumes.
OpenEBS is a Kubernetes native hyperconverged storage solution that manages the local storage available to nodes and provides locally or highly available distributed persistent volumes for stateful workloads. Another advantage of being a fully Kubernetes-native solution is that administrators and developers can interact and manage OpenEBS using all the great tools available for Kubernetes such as kubectl, Helm, Prometheus, Grafana, Weave Scope, and more.
What can OpenEBS do?
OpenEBS manages storage on k8s nodes and provides local storage volumes or distributed storage volumes for k8s stateful loads (StatefulSet).
-
Local volumes (Local Storage)
- OpenEBS can use host bare block devices or partitions, or use subdirectories on Hostpaths, or use
LVM,ZFSto create persistent volumes - Local volumes are mounted directly to the Stateful Pod without any additional overhead in the datapath from OpenEBS
- OpenEBS provides additional tools for local volumes for monitoring, backup/recovery, disaster recovery, snapshots supported by
ZFSorLVM, etc.
- OpenEBS can use host bare block devices or partitions, or use subdirectories on Hostpaths, or use
-
For distributed volumes (i.e., replicated volumes)
- OpenEBS uses one of the engines (
Mayastor,cStororJiva) to create microservices for each distributed persistent volume. - Stateful Pods write data to the OpenEBS engine, which replicates the data synchronously to multiple nodes in the cluster. the OpenEBS engine itself is deployed as a Pod and orchestrated by Kubernetes. When the node running the Stateful Pod fails, the Pod is rescheduled to another node in the cluster and OpenEBS provides access to the data using a copy of the data available on the other node.
- Stateful Pods use
iSCSI(cStorandJiva) orNVMeoF(Mayastor) to connect to OpenEBS distributed persistent volumes. OpenEBS cStorandJivafocus on ease of use and persistence of storage. They use custom versions ofZFSandLonghorntechnologies to write data to the storage, respectively.OpenEBS Mayastoris the latest development of an engine designed for endurance and performance, efficiently managing compute (large pages, cores) and storage (NVMe Drives) to provide fast distributed block storage.
- OpenEBS uses one of the engines (
Note :
OpenEBSdistributed block volumes are called replicated volumes to avoid confusion with traditional distributed block storage, which tends to distribute data across many nodes in a cluster. Replicated volumes are designed for cloud-native stateful workloads that require a large number of volumes whose capacity can typically be provisioned from a single node, rather than using a single large volume that is sharded across multiple nodes in a cluster.
Compare to traditional distributed storage
A few key ways in which OpenEBS differs from other traditional storage solutions:
- Built using a microservice architecture, just like the applications it serves.
OpenEBSitself is deployed as a set of containers on aKubernetesworker node. UseKubernetesitself to orchestrate and manageOpenEBScomponents. - Built entirely in user space, making it highly portable to run on any OS/platform..
- Fully intent-driven, inheriting the same principles of
Kubernetesease-of-use. OpenEBSsupports a range of storage engines, so developers can deploy storage technologies that fit their application design goals. Distributed applications likeCassandracan use theLocalPVengine for the lowest latency write operations. Monolithic applications likeMySQLandPostgreSQLcan useMayastorbuilt withNVMeandSPDKorcStorbased onZFSto achieve resiliency. Streaming applications likeKafkacan use theNVMeengineMayastorfor optimal performance in an edge environment.
The main reasons that drive users to use OpenEBS are:
- Portability on all
Kubernetesdistributions. - Increased developer and platform
SREproductivity. - Ease of use compared to other solutions.
- Excellent community support.
- Free and open source.
Local Volume Type
Local volumes can only be accessed from a single node in the cluster. Pods that use Local Volume must be scheduled on the node providing the volume. Local volumes are often preferred for distributed workloads such as Cassandra, MongoDB, Elastic, etc. that are inherently distributed and have high availability (sharding) built in.
Depending on the type of storage attached to the Kubernetes worker node, you can choose from different dynamic local PVs - Hostpath, Device, LVM, ZFS or Rawfile.
Replicable volume type
A replicated volume is, as the name implies, a volume that replicates data to multiple nodes synchronously. Volumes can support node failures. Replication can also be set up across availability zones to help applications move across availability zones.
Replicated volumes can also provide enterprise storage features like snapshots, clones, volume expansion, etc. Replicated volumes are preferred for stateful workloads such as Percona/MySQL, Jira, GitLab, etc.
Depending on the type of storage attached to the Kubernetes worker node and application performance requirements, you can choose from Jiva, cStor or Mayastor.
OpenEBS Storage Engine Recommendations
| Application Requirements | Storage Types | OpenEBS Volume Types |
|---|---|---|
| Low Latency, High Availability, Synchronous Replication, Snapshots, Clones, Thin Provisioning | SSD/ Cloud Storage Volumes | OpenEBS Mayastor |
| High Availability, Synchronous Replication, Snapshots, Clones, Thin Provisioning | Machine /SSD/ Cloud Storage Volumes | OpenEBS cStor |
| High Availability, Synchronous Replication, Thin Provisioning | Host Path or External Mounted Storage | OpenEBS Jiva |
| Low Latency, Local PV | Hostpath or External Mounted Storage | Dynamic Local PV - Hostpath, Dynamic Local PV - Rawfile |
| Low Latency, Local PV | Local Mechanical /SSD/ Block Devices such as Cloud Storage Volumes | Dynamic Local PV - Device |
| Low Latency, Local PV, Snapshot, Clone | Local Mechanical /SSD/ Cloud Storage Volumes and other Block Devices | OpenEBS Dynamic Local PV - ZFS , OpenEBS Dynamic Local PV - LVM |
To summarize.
- Multi-computer environment, if there is an additional block device (non-system disk block device) as data disk, choose
OpenEBS Mayastor,OpenEBS cStor. - Multi-computer environment, if there is no additional block device (non-system disk block device) as data disk, only a single system disk block device, use
OpenEBS Jiva. - For standalone environment,
Dynamic Local PV - Hostpath, Dynamic Local PV - Rawfileis recommended for local paths, as standalone is mostly used for test environment with lower data reliability requirements.
It seems that OpenEBS is commonly used in the above three scenarios.
OpenEBS Features
container-attached storage
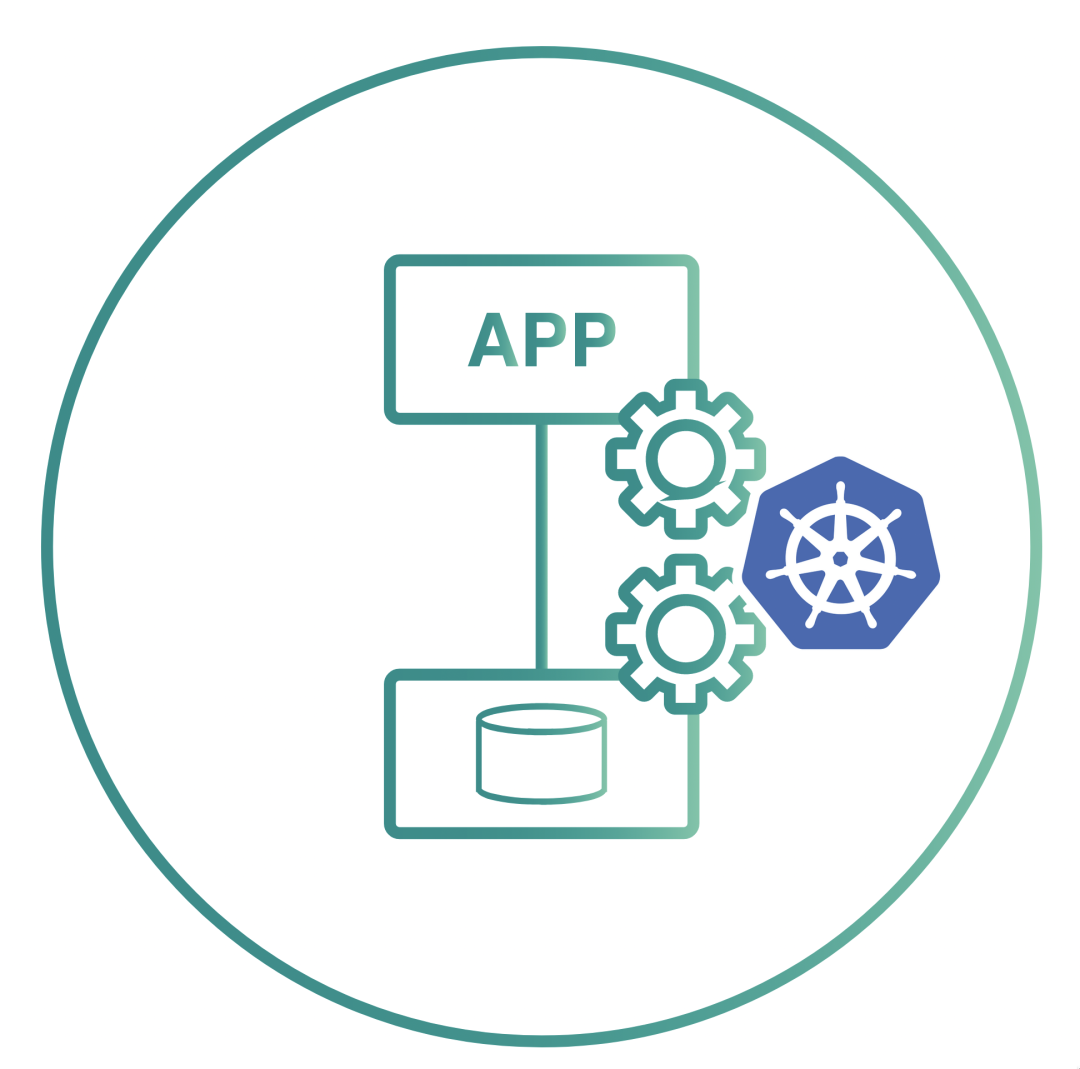
OpenEBS is an example of Container Attached Storage ( Container Attached Storage, CAS). The volumes provided through OpenEBS are always containerized. Each volume has a dedicated storage controller that is used to improve the agility and granularity of persistent storage operations for stateful applications.
Synchronous Replication
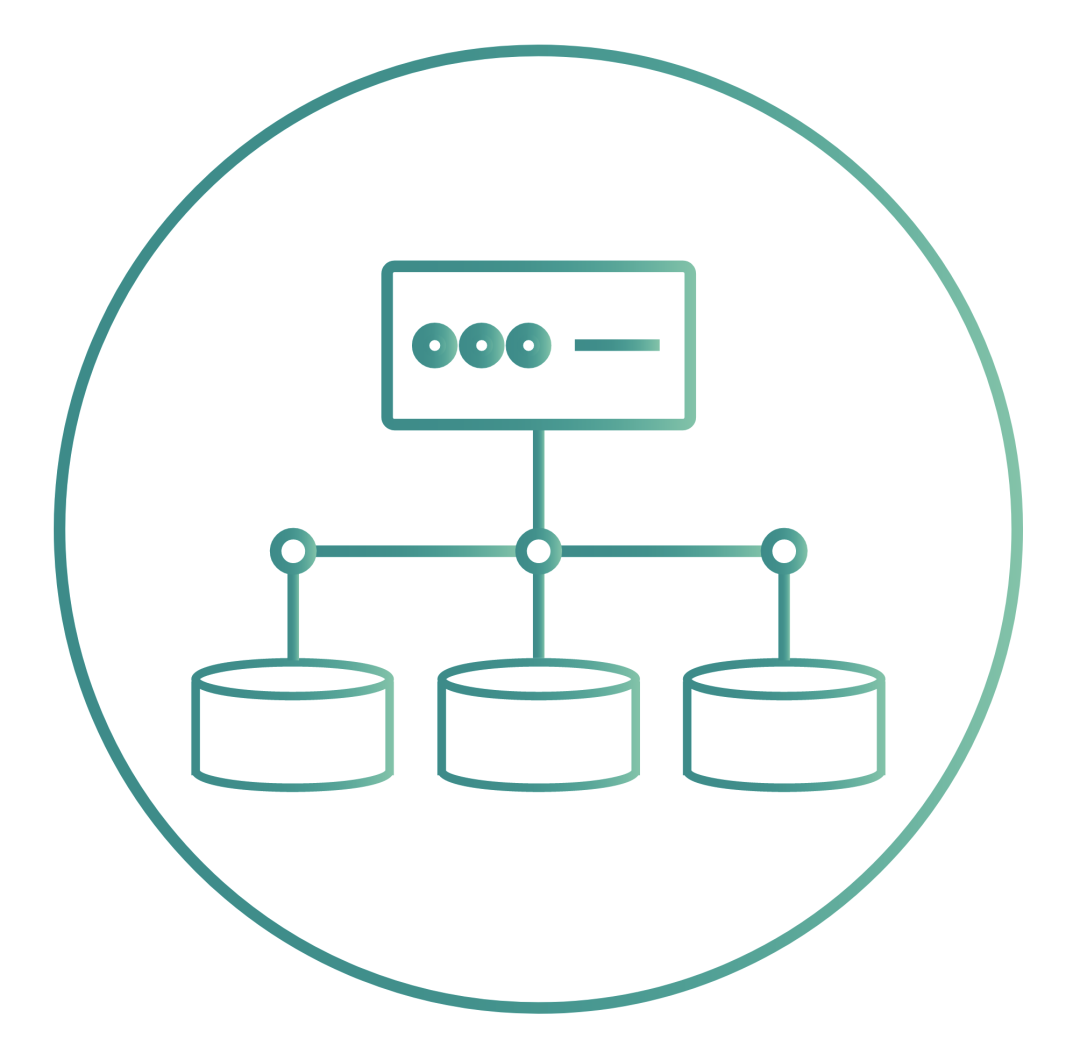
Synchronous replication is an optional and popular feature of OpenEBS. When used with the Jiva, cStor and Mayastor storage engines, OpenEBS can replicate data volumes synchronously for high availability. Replication is performed across Kubernetes regions to provide high availability across AZ settings. This feature is particularly useful for building highly available stateful applications using local disks on cloud provider services such as GKE, EKS and AKS.
Snapshots and Clones
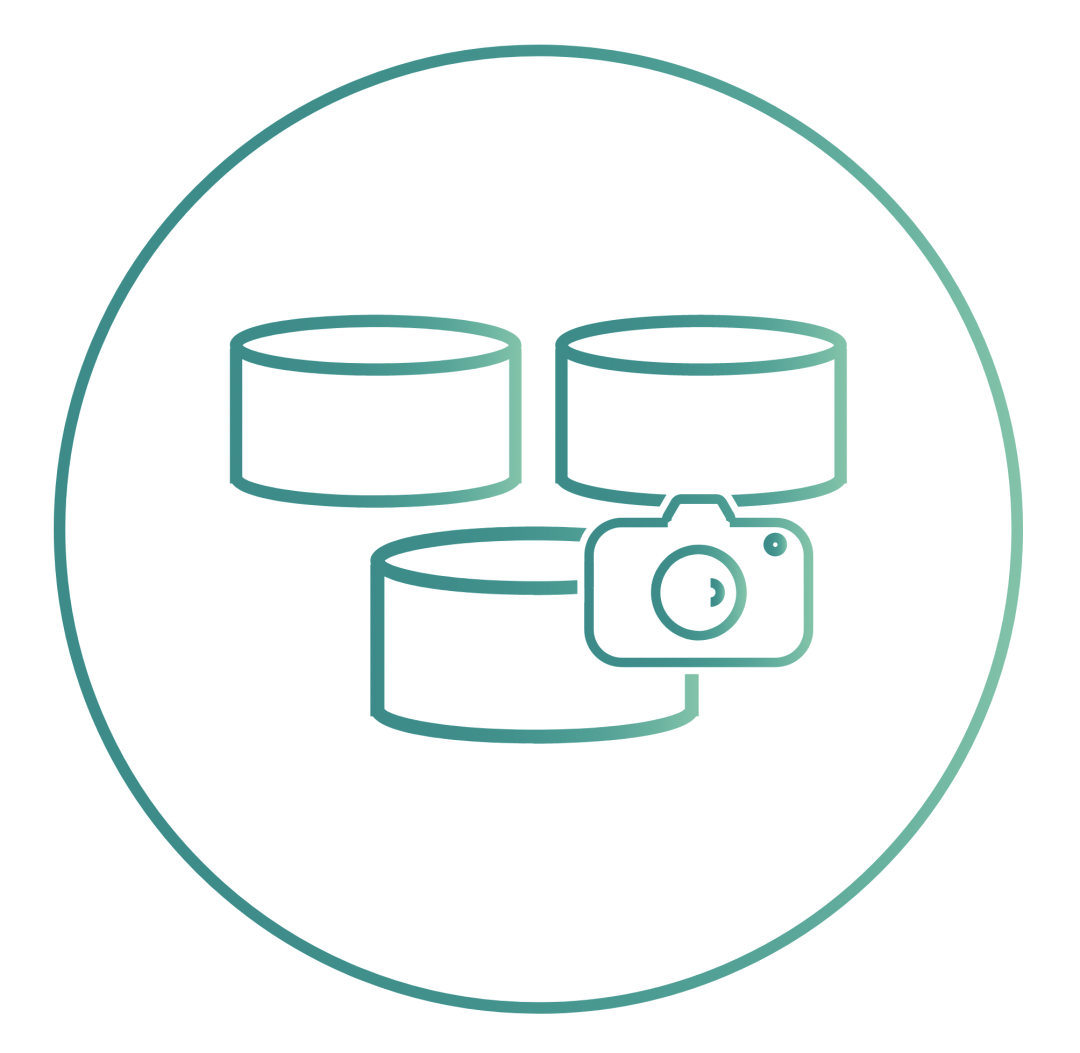
Copy-on-write snapshots are another optional and popular feature of OpenEBS. When using the cStor engine, snapshots are created instantaneously and are not limited in the number of snapshots. Incremental snapshotting enhances data migration and portability across Kubernetes clusters and across different cloud providers or data centers. Snapshot and clone operations are performed entirely in a Kubernetes-native way, using the standard kubectl command. Common use cases include efficient replication for backups and cloning for troubleshooting or developing read-only copies of data.
Backup and Recovery
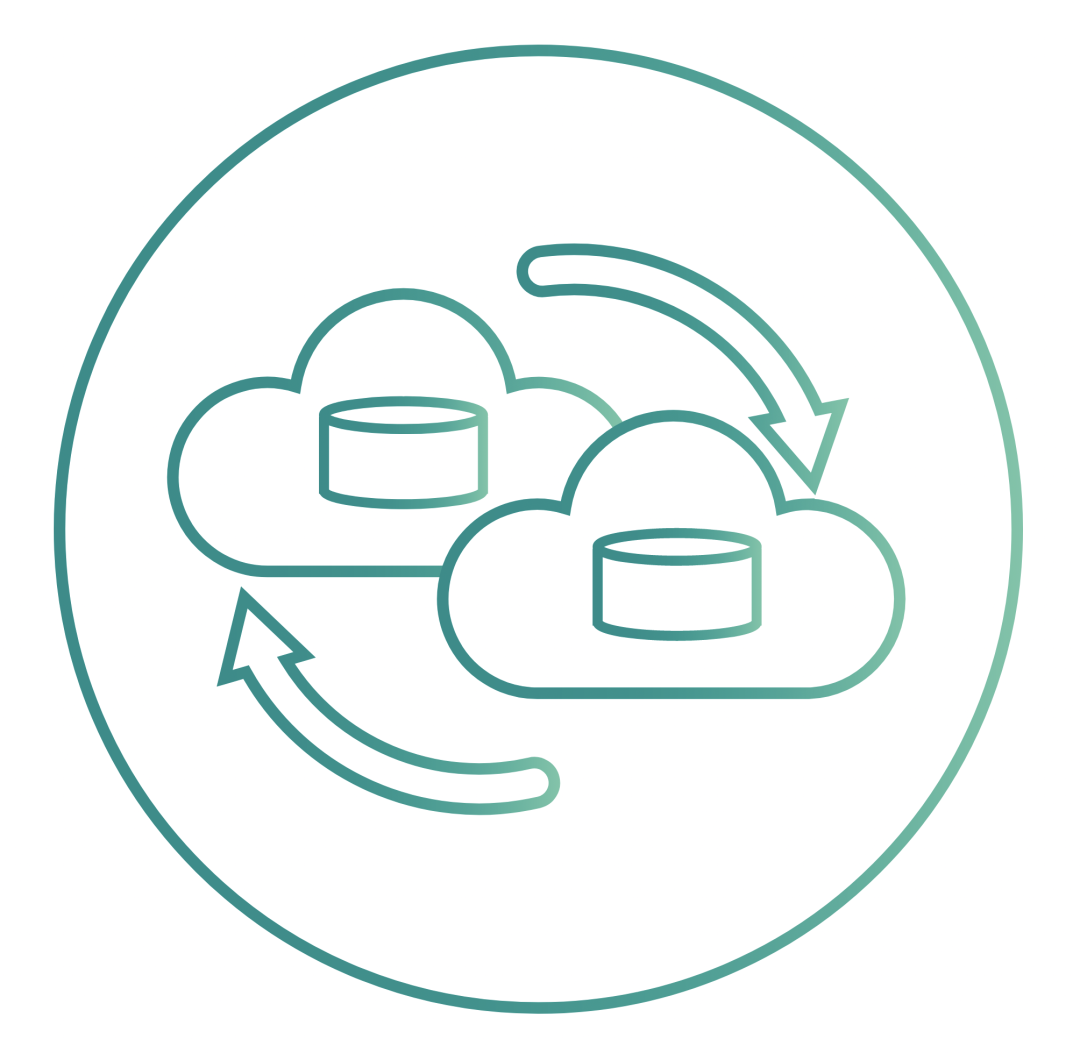
Backup and recovery of OpenEBS volumes can work with Kubernetes backup and recovery solutions such as Velero (formerly Heptio Ark) via the open source OpenEBS Velero plugin. The OpenEBS incremental snapshot feature is often used to back up data to object storage targets such as AWS S3, GCP object storage, MinIO. Such storage-level snapshots and backups use only incremental data for backup, saving a lot of bandwidth and storage space.
True Kubernetes cloud-native storage

OpenEBS is a cloud-native storage for stateful applications on Kubernetes, and cloud-native means following a loosely coupled architecture. Therefore, the general benefits of a cloud-native, loosely coupled architecture are applicable. For example, developers and DevOps architects can use standard Kubernetes skills and utilities to configure, use, and manage persistent storage requirements
reduces storage TCO by up to 50%
On most clouds, block storage is charged based on how much is purchased, not how much is used; capacity is often over-provisioned in order to achieve higher performance and eliminate the risk of outages while fully utilizing it. The thin provisioning capabilities of OpenEBS can share local storage or cloud storage and then increase the amount of data for stateful applications as needed. Storage can be added dynamically without disrupting the volumes exposed to the workload or application. Some users have reported savings of over 60% of resources as a result of using OpenEBS thin provisioning.
High Availability
Because OpenEBS follows the CAS architecture, in the event of a node failure, Kubernetes will redispatch the OpenEBS controller while the underlying data is protected by using one or more copies. More importantly - because each workload can leverage its own OpenEBS - there is no risk of widespread system downtime due to storage loss. For example, the volume’s metadata is not centralized, and it could be subject to catastrophic general-purpose outages, as many shared storage systems are. Instead, metadata remains local to the volume. The loss of any node results in the loss of a copy of the volume that exists only on that node. Since volume data is synchronously replicated on at least two other nodes, it will continue to be available at the same performance level when one node fails.
Introduction to CAS
In a CAS or Container Attached Storage architecture, storage runs in a container and is closely related to the application to which the storage is bound. Storage runs as a microservice with no kernel module dependencies. An orchestration system like Kubernetes orchestrates storage volumes, just like any other microservice or container.CAS has the benefits of DAS and NAS.
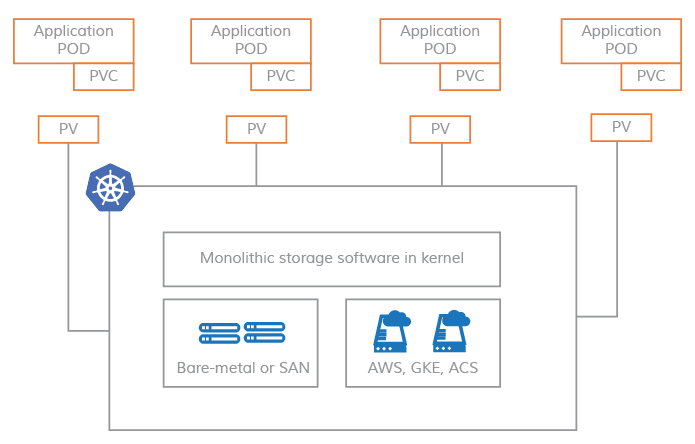
PV on non-CAS systems
In the non-CAS model, Kubernetes persistent volumes remain tightly coupled to the kernel module, making the storage software on the Kubernetes node inherently monolithic.
PV on CAS-based systems
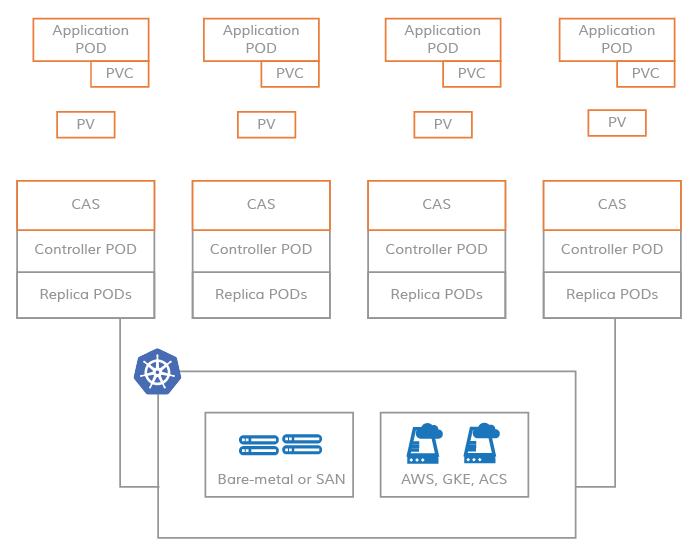
Instead, CAS enables you to leverage the flexibility and scalability of cloud-native applications. The storage software that defines Kubernetes PV (Persistent Volume) is based on a microservices architecture. The control plane (storage controller) and data plane (storage replica) of the storage software run as Kubernetes Pods, thus enabling you to apply all the benefits of cloud-native to CAS.
CAS Benefits
-
Agile
Each storage volume in
CAShas a containerized storage controller and a corresponding containerized copy. As a result, maintenance and tuning of resources around these components is truly agile. TheKubernetesrolling upgrade feature allows for seamless upgrades of storage controllers and storage replicas. Resource quotas such asCPUand memory can be tuned using containercGroups. -
Storage Policy Granularity
Containerizing the storage software and dedicating the storage controller to each volume allows for maximum storage policy granularity. In the
CASarchitecture, all storage policies can be configured on a per-volume basis. In addition, you can monitor the storage parameters for each volume and dynamically update the storage policy to achieve the desired results for each workload. As this additional level of granularity is added to the volume storage policy, the control of storage throughput,IOPS, and latency also increases. -
Cloud Native
CASloads storage software into containers and usesKubernetesCustom Resource Definitions (CRDs) to declare low-level storage resources, such as disks and storage pools. This model allows storage to be seamlessly integrated into other cloud-native tools. Cloud native tools such asPrometheus, Grafana, Fluentd, Weavescope, Jaegercan be used to provision, monitor, and manage storage resources. -
PVis a microservice inCASAs shown above, in the
CASarchitecture, the software for storage controllers and replicas is entirely microservices-based, so there are no kernel components involved. Typically, the storage controllerPODis scheduled on the same nodes as the persistent volumes for efficiency, and the replicaPODcan be scheduled anywhere on the cluster nodes. Each replica is provisioned completely independently of the other replicas using any combination of local disks,SANdisks, and cloud disks. This provides tremendous flexibility in the allocation of storage for large-scale workloads. -
Hyperconverged Non-Distributed
The
CASarchitecture does not follow typical distributed storage architectures. Storage becomes highly available through synchronous replication from storage controllers to storage replicas. Metadata for volume replicas is not shared between nodes, but managed independently on each local node. If one node fails, the storage controller (in this case a stateless container) rotates on a node that has a second or third copy running and the data is still available.Similar to hyperconverged systems, the storage and performance of the volumes in
CASis scalable. Since each volume has its own storage controller, storage can scale as far as a node’s storage capacity allows. In a givenKubernetescluster, as the number of container applications increases, more nodes are added, thereby increasing the overall availability of storage capacity and performance, and thus making storage available to new application containers. This process is very similar to successful hyperconverged systems such asNutanix.
Introduction to the OpenESB architecture
OpenESB follows the Container Attached Storage (CAS) model, where each volume has a dedicated controller POD and a set of replica PODs. The benefits of the CAS architecture are discussed on the CNCF blog. OpenEBS is simple to operate and use, as it looks and feels like other cloud-native and Kubernetes-friendly projects.
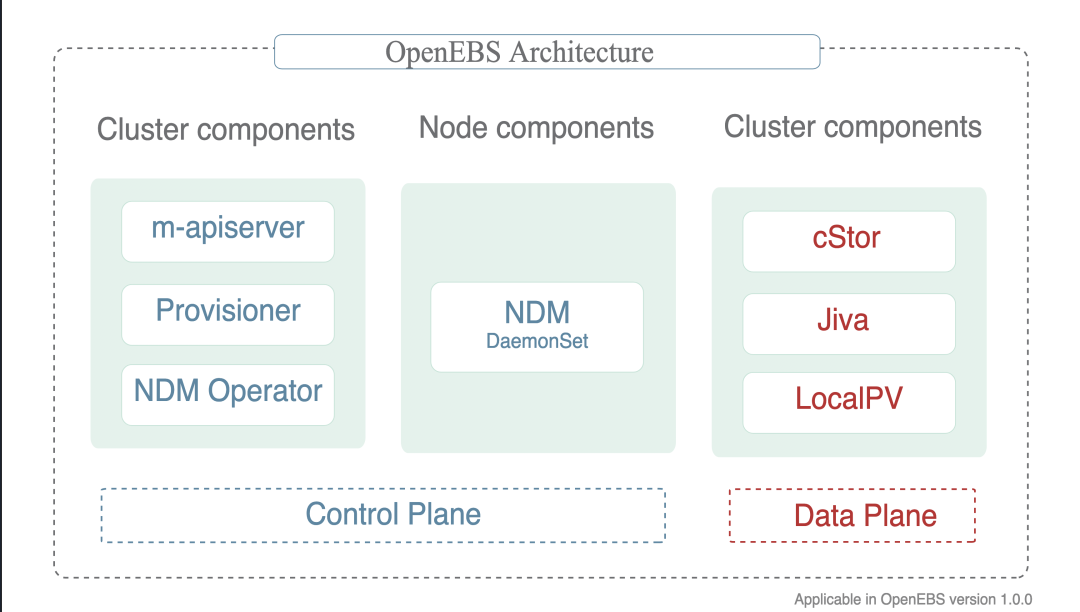
OpenEBS has many components that can be divided into the following categories :
- Control plane components -
Provisioner,API Server,volume exports,volume sidecars. - Data plane components -
Jiva,cStor. - Node disk manager -
Discover,monitor, manages the media for connecting tok8s. - Integration with cloud native tools - already integrated with
Prometheus,Grafana,Fluentd,Jaeger.
Control plane
The control plane of an OpenEBS cluster is often referred to as Maya.
The OpenEBS control plane is responsible for providing volumes, associated volume operations such as snapshots, cloning, creating storage policies, enforcing storage policies, exporting volume metrics used by Prometheus/grafana, and so on.
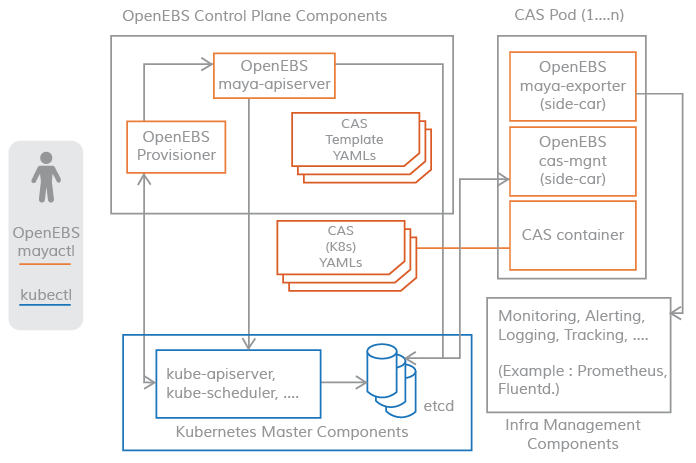
OpenEBS provides a dynamic provisioner, which is the standard external storage plugin for Kubernetes. The main task of the OpenEBS PV provider is to initiate volume provisioning to application PODS and to implement the Kubernetes specification for PV.
The m-apiserver opens up the REST API for storage and takes care of a lot of volume policy processing and management.
Connectivity between the control plane and the data plane uses the Kubernetes sidecar pattern. The scenarios where the control plane needs to communicate with the data plane are shown below.
- For volume statistics such as
IOPS, throughput, latency, etc. - implemented viasidecarfor volume bursts. - Enforcement of volume policies using volume controller
pod, disk/pool management using volume replicapod- implemented via volume managementsidecar.
OpenEBS PV Provisioner
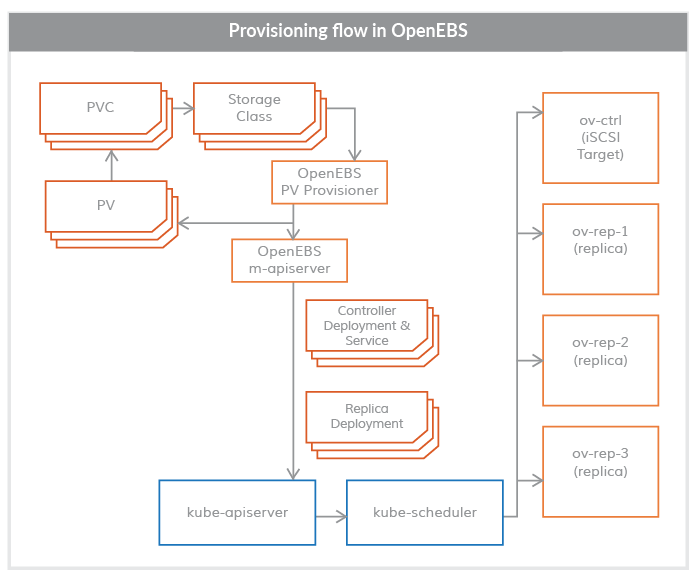
This component runs as a POD and makes configuration decisions , it is used in the following way:
The developer constructs a declaration with the required volume parameters, selects the appropriate storage class, and invokes the kubelet on the YAML specification. The OpenEBS PV dynamic provider interacts with the maya-apiserver to create deployment specifications for the volume controller pod and the volume copy pod on the appropriate node. Scheduling of volume Pod (controllers/copies) can be controlled using annotations in the PVC specification.
Currently, OpenEBS Provisioner supports only one binding type, iSCSI.
Maya-ApiServer
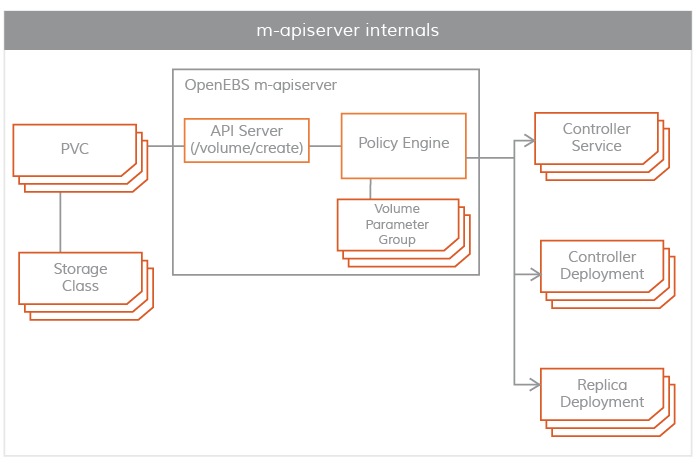
m-apiserver runs as a POD. As the name implies, m-apiserver exposes the OpenEBS REST api.
The m-apiserver is also responsible for creating the deployment specification files needed to create the volume pod. After generating these spec files, it calls kube-apiserver to schedule these pods accordingly. openEBS PV provider creates a PV object and mounts it to the application pod at the end of volume distribution. the PV is hosted by a controller pod, which is supported by a set of replica pods in different nodes. The controller pod and replica pods are part of the data plane and are described in more detail in the Storage Engine section.
Another important task of m-apiserver is volume policy management. OpenEBS provides very fine-grained specifications for representing policies. m-apiserver interprets these YAML specifications, translates them into executable components, and executes them via the capacity management sidecar.
Maya Volume Exporter
The Maya volume exporter is a sidecar for each storage controller pod.
These sidecars connect the control plane to the data plane for statistical information. The granularity of statistical information is at the volume level. Some example statistics are as follows.
- Volume read latency.
- Volume write latency.
- Volume read speed per second.
- Volume write speed per second.
- Read block size.
- Write block size.
- Capacity statistics.
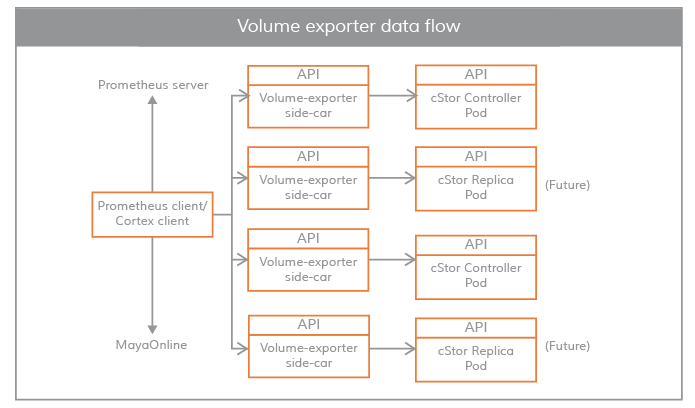
These statistics are typically pulled by the Prometheus client, which is installed and configured during the OpenBS installation.
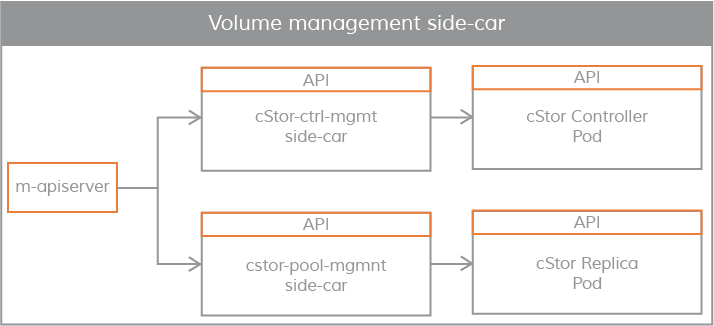
volume management sidecar
Sidecars are also used to pass controller configuration parameters and volume policies to volume controller pod (volume controller pod is a data plane), and to pass replica configuration parameters and replica data protection parameters to volume replica pod.
Data plane
The OpenEBS data plane is responsible for the actual volume IO path. Storage engines implement the actual IO path in the data plane. Currently, OpenEBS provides two storage engines that can be easily plugged in. They are called Jiva and cStor. Both storage engines run entirely in the Linux user space and are based on a microservices architecture.
Jiva
The Jiva storage engine is based on Rancher's LongHorn and gotgt development implementations, developed in the go language, and runs under the user namespace. The LongHorn controller synchronizes the input IO copy to the LongHorn replica. This copy treats Linux sparse files as the basis for building storage features such as thin provisioning, snapshots, rebuilds, etc.
cStor
The cStor data engine is written in the C language and features a high-performance iSCSI target and Copy-On-Write block system that provides data integrity, data resiliency, and point-in-time snapshots and clones. cStor has a pooling feature that aggregates disks on a node in striped, mirrored, or RAIDZ mode to provide larger capacity and performance units. cStor can also synchronize data replication to multiple nodes across regions, thus avoiding data unavailability due to node loss or node reboot.
LocalPV
For applications that do not require storage-level replication, LocalPV may be a good choice because it provides higher performance. OpenEBS LocalPV is similar to Kubernetes LocalPV, except that it is dynamically provisioned by the OpenEBS control plane, just like any other regular PV. There are two types of OpenEBS LocalPV: hostpath LocalPV and device LocalPV. hostpath LocalPV refers to a subdirectory on the host, and LocalPV refers to a disk found on a node (either directly connected or network connected). OpenEBS introduces a LocalPV provider for selecting matching disk or host paths based on PVC and some criteria in the storage class specification.
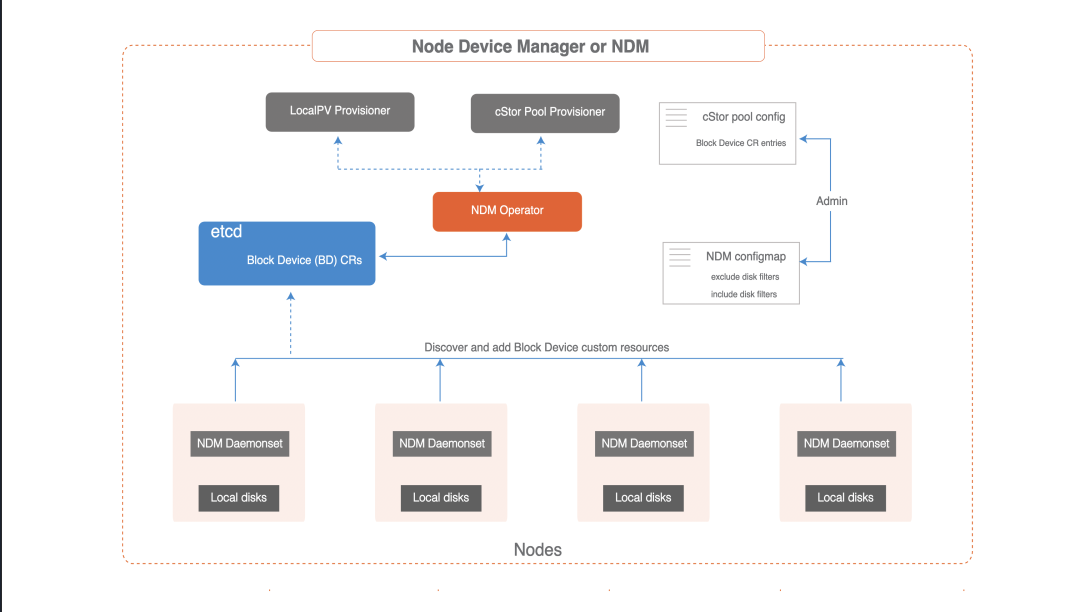
Node Disk Manager
The Node Disk Manager ( NDM) fills a gap in the toolchain needed to manage persistent storage for stateful applications using Kubernetes. DevOps architects in the container era must meet the infrastructure needs of applications and application developers in an automated way that provides resiliency and consistency across environments. These requirements mean that the storage stack itself must be flexible enough that it can be easily used by Kubernetes and other software in the cloud-native ecosystem. NDM plays a foundational role in Kubernetes storage stack by unifying the different disks and providing the ability to aggregate them by identifying them as Kubernetes objects. In addition, NDM discovers, provision, monitors, and manages the underlying disks in a way that allows Kubernetes PV providers (such as OpenEBS and other storage systems) and Prometheus to manage disk subsystems.
CAS Engine
Storage Engine Overview
The storage engine is the data plane component of the persistent volume IO path. In the CAS architecture, users can select different data planes for different application workloads based on different configuration policies. The storage engine can be optimized for a given workload by feature set or performance.
Operators or administrators typically select a storage engine with a specific software version and build optimized volume templates that are fine-tuned based on the type of underlying disks, resiliency, number of replicas, and set of nodes participating in the Kubernetes cluster. Users can select the optimal volume template when issuing volumes, providing maximum flexibility to run the optimal combination of software and storage for all storage volumes on a given Kubernetes cluster.
Storage engine types
OpenEBS provides three types of storage engines.
-
Jiva
Jivais the first storage engine released inOpenEBS version 0.1and is the easiest to use. It is based onGoLangand uses theLongHornandgotgtstacks internally.Jivaruns entirely in user space and provides standard block storage features such as synchronous replication.Jivais typically suitable for smaller capacity workloads and is not suitable for situations where large numbers of snapshots and cloning features are the primary requirement. -
cStor
cStoris the latest storage engine released inOpenEBS version 0.7.cStoris very robust, provides data consistency, and supports enterprise storage features such as snapshots and clones very well. It also provides a robust storage pooling feature for comprehensive storage management in terms of capacity and performance. Together withNDM(Node Disk Manager),cStorprovides complete persistent storage features for stateful applications onKubernetes. -
OpenEBS Local PV
OpenEBS Local PVis a new storage engine that can create persistent volumes orPVs from local disks or host paths on working nodes. TheCASengine is available from version1.0.0ofOpenEBS. WithOpenEBS Local PV, the performance will be equivalent to the local disk or file system (host path) where the volume is created. Many cloud-native applications may not require advanced storage features such as replication, snapshots, or cloning, as they provide these features themselves. Such applications require access to managed disks in the form of persistent volumes.
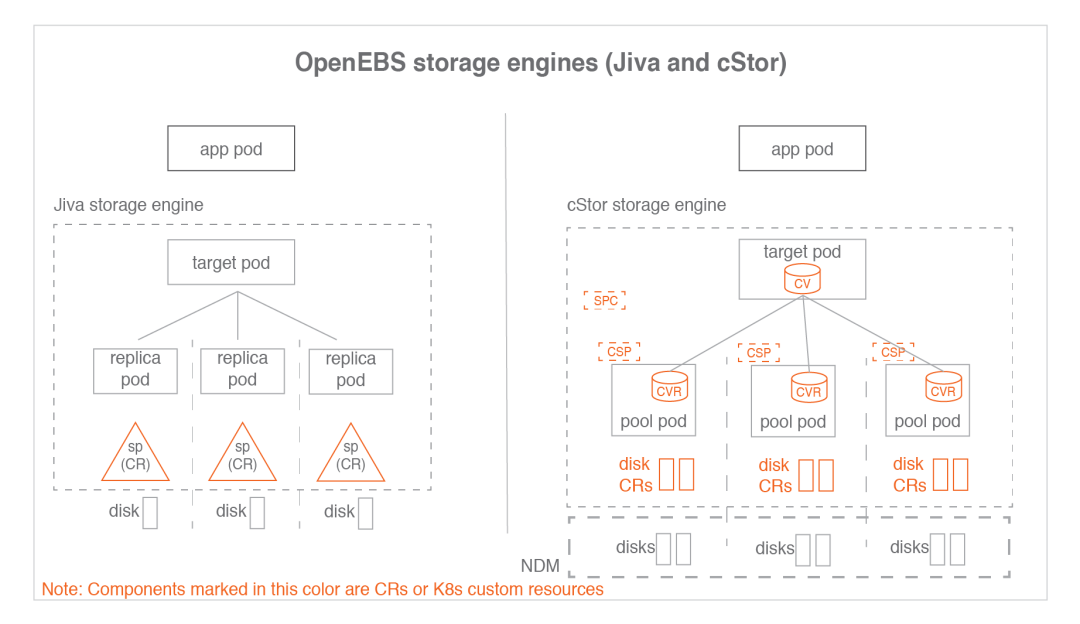
SPstorage pools, representingJivacustom storage resources.CVcStorvolume, representing acStorvolume custom resource.CVRcStorvolume copy.SPCStorage pool declaration, representingcStorpool aggregated custom resources.CSPcStorstorage pool, representing the custom resources on each node of thecStor Pool.
One SPC corresponds to multiple CSPs and correspondingly one CV corresponds to multiple CVRs.
Storage engine declaration
Select a storage engine by specifying the annotation openebs. io/cas-type in the StorageClass specification. The StorageClass defines the details of the provisioner. A separate provisioner is specified for each CAS engine.
cStor Storage Class Specification File Contents
Jiva Storage Class Specification File Contents
When cas is of type Jiva, the default value of StoragePool has a special meaning. When pool is the default value, the Jiva engine will open up data storage for the replica pod from the container’s (replica pod) own storage space. When the required volume size is small (e.g. 5G to 10G), StoragePool default works well because it can fit inside the container itself.
Local PV Storage Class Specification File Contents - Host Path
|
|
Local PV Storage Class Specification Document Content - Host Device
Comparison of cStor, Jiva, LocalPV characteristics.
| Features | Jiva | cStor | Local PV |
|---|---|---|---|
| Lightweight Runs in User Space | Yes | Yes | Yes |
| Synchronous Replication | Yes | Yes | No |
| Synchronous Replication | Yes | Yes | No |
| Supports snapshots, clones | Basic | Advanced | No |
| Data consistency | Yes | Yes | NA |
| Restore backups with Velero | Yes | Yes | Yes |
| Suitable for high volume workloads | No | Yes | Yes |
| Automatic thin provisioning | Yes | No | |
| Disk pooling or aggregation support | Yes | No | |
| Dynamic Scaling | Yes | Yes | |
| Data Resiliency (RAID support) | Yes | No | |
| Near-native disk performance | No | No | Yes |
cStor is recommended for most scenarios as it offers powerful features including snapshots/clones, storage pooling capabilities such as streamlined resource provisioning, on-demand scaling, etc.
Jiva is suitable for workload scenarios with low capacity requirements, such as 5 to 50G. Although there is no space limit for using Jiva, it is recommended for low-volume workloads. Jiva is very easy to use and provides enterprise-class container local storage without the need for dedicated hard drives. In scenarios where snapshot and cloning capabilities are required, cStor is preferred over Jiva.
CAS Engine Usage Scenarios
As shown in the table above, each storage engine has its own advantages. The choice of engine depends entirely on the workload of the application and its current and future capacity and/or performance growth. The following guidelines provide some assistance in choosing a specific engine when defining storage classes.
Ideal conditions for selecting cStor
- When you need to synchronize replicated data and have multiple disks on a node.
- When you manage storage for multiple applications from local disks on each node or from a network disk pool. Storage tier management through features such as thin provisioning, on-demand scaling of storage pools and volumes, and on-demand scaling of storage pool performance.
cStorfor running locally .Kuberneteslocal storage service built on aKubernetescluster, similar toAWS EBSor GooglePD. - When you need storage-level snapshot and cloning capabilities
- When you need enterprise-class storage protection features such as data consistency, resiliency (
RAIDprotection). - If your application does not require storage-level replication, then using
OpenEBShost pathLocalPVorOpenEBSdeviceLocalPVmay be a better choice.
Ideal conditions for choosing Jiva
-
When you want synchronous replication of data and have a single local disk or a single managed disk (such as a cloud disk (
EBS,GPD)) and do not need snapshot or cloning features. -
Jivais the easiest to manage because disk management or pool management is out of the scope of this engine.Jivapools are mount paths for local disks, network disks, virtual disks, or cloud disks. -
Jiva is preferable to cStor for the following scenarios :
- When the program does not need the storage level snapshot, clone feature.
- When there are no free disks on the node.
Jivacan be used on the host directory and still enable replication. - When there is no need to dynamically scale storage on local disks. Adding more disks to the
Jivapool is not possible, so the size of theJivapool is fixed if it is on physical disks. However, if the underlying disk is a virtual disk, a network disk, or a cloud disk, the size of theJivapool can be changed dynamically. - Smaller capacity requirements. Large capacity applications often require dynamic capacity increases, and
cStoris better suited to this need.
Ideal conditions for selecting OpenEBS host path LocalPV
- When the application itself has the ability to manage replication (e.g.,
es), replication at the storage level is not required. In most such cases, the application is deployed as astatefulset. - Higher than the read/write performance requirements of
JivaandcStor. Hostpathis recommended when a specific application does not have a dedicated local disk or when a specific application does not need dedicated storage. If you want to share a local disk across multiple applications, hostpathLocalPVis the right way to go.
Ideal conditions for selecting an OpenEBS host device LocalPV
- When the application manages the replication itself and does not require replication at the storage layer. In most of these cases, the application is deployed as a stateful set.
- Higher than the read and write performance requirements of
JivaandcStor. - Higher than the read and write performance requirements of the
OpenEBShost pathLocalPV. - When close disk performance is required. This volume is dedicated to writing to a single
SSDorNVMeinterface for maximum performance.
Summary
LocalPVis preferred if the application is in production and does not require storage-level replication.- Prefer
cStorif your application is in production and requires storage-level replication. - Prefer
Jivaif your application is small and needs storage-level replication but does not require snapshots or clones.
Node Disk Manager (NDM)
The Node Disk Manager ( NDM) is an important component of the OpenEBS architecture. The NDM treats block devices as resources to be monitored and managed, just like other resources such as CPU, memory and network. It is a daemon that runs on each node and detects additional block devices based on filters and loads them into Kubernetes as block device custom resources. These custom resources are intended to provide easy access to Kubernetes by providing something like the following:
- Easy access to the list of block devices available in the
Kubernetescluster. - Predicting disk failures to help take preventative action.
- Allow dynamic mounting/unmounting of disks to storage
Podswithout restarting the correspondingNDM Podrunning on the node where the disk is mounted/unmounted.
Despite all of the above, NDM helps provide overall simplification of persistent volumes.
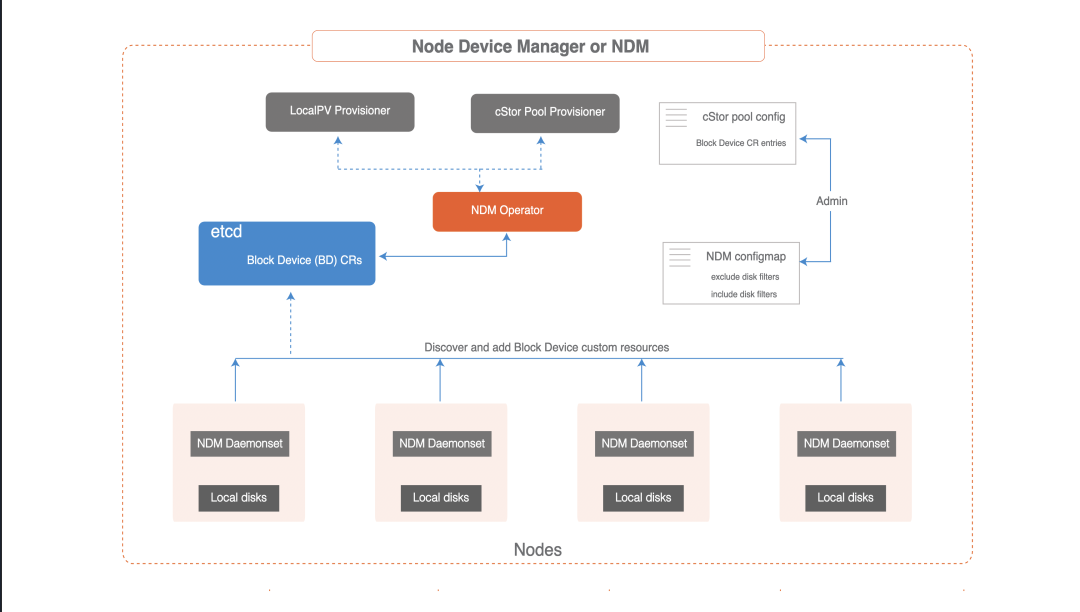
NDM is deployed as a daemon during the OpenEBS installation. NDM daemonset discovers the disks on each node and creates a custom resource called Block Device or BD.
Access Rights Description
The NDM daemon runs in a container and must access the underlying storage device and run in privileged mode. NDM requires privileged mode because it needs access to the /dev, /proc and /sys directories to monitor the attached devices, and also needs to use various probes to get detailed information about the attached devices. NDM is responsible for discovering block devices and filtering out devices that should not be used by OpenEBS; for example, detecting disks with OS file systems. The NDM pod by default mounts the host’s /proc directory in the container and then loads /proc/1/mounts to find the disks used by the OS.
NDM daemon features
- Discover block devices on
Kubernetesnodes.- Discover block devices at boot time - create and/or update status.
- Maintain cluster-wide unique
idfor disks :Hashcalculation forWWN / PartitionUUUID / FileSystemUUID / DeviceMapperUUUID.
- Detects the addition/removal of a block device in a node and updates the block device status.
- Add a block device as a
Kubernetescustom resource with the following properties.spec: if available, will update the following- device path
- device link
- Vendor and model information
WWNand serial number- Capacity
- Sector and block sizes
labels:- Host name (
kubernetes.io/hostname) - blockdevice type (
ndm.io/blockdevice-type) - Managed (
ndm.io/managed)
- Host name (
status: The status can have the following valuesActive: block device present on the nodeInactive: Block device does not exist on the given nodeUnknown:NDMstopped/unable to determine status on the node where the block device was last detected
filters
-
Configure filters for the block device type for which the block device
CRis to be created. Filters can be configured by vendor type, device path mode, or mount point. -
Filters can be either inclusion filters or exclusion filters. They are configured as
configmap. Admin users can configure these filters atOpenEBSinstallation time by changing theNDM configmapin theOpenEBSoperatoryamlfile orhelmvalues.yamlfile. If these filters need to be updated after installation, then one of the following methods can be followed :- Install
OpenEBSusing theoperatormethod. In theyamlfile, update the filters in theconfigmapand applyoperator.yaml. - If
OpenEBSwas installed usinghelm, updateconfigmapinvalues.yamland upgrade usinghelm. - Or, use
kubectlto editNDM configmapand update the filters.
- Install
Practice
The cStor and Jiva engines of OpenEBS are not recommended for production environments due to the number of components and the cumbersome configuration compared to other storage solutions, so we will only discuss the Local PV engine here.
The Local PV engine does not have storage-level replication capabilities and is suitable for back-end storage of k8s stateful services (e.g., es, redis, etc.).
Local PV Hostpath Practices
The OpenEBS local PV Hostpath volume has the following advantages over the Kubernetes Hostpath volume :
- The
OpenEBSlocalPV Hostpathallows your application to access theHostpathviaStorageClass,PVCandPV. This gives you the flexibility to change thePVprovider without having to redesign the applicationYAML. - Data protection with
Velerobackup and recovery. - Protect against hostpath security vulnerabilities by completely masking the hostpath to application
YAMLandpod.
Environmental Dependencies :
k8s 1.12or higherOpenEBS 1.0or higher
Practical environment :
docker 19.03.8k8s 1.18.6CentOS7
Create a data directory
Set up a directory on the node where Local PV Hostpaths will be created. This directory will be called BasePath. The default location is /var/openebs/local.
Nodes node1, node2, node3 create the /data/openebs/local directory (/data can be pre-mounted with a data disk, if no additional data disk is mounted, the OS ‘/’ mount point storage is used).
|
|
Download the application description file
Release the openebs application
Based on the above configuration file, ensure that the following mirrors are accessible to the k8s cluster (it is recommended to import a local private mirror repository, e.g. : harbor).
Update the mirror tag in openebs-operator.yaml to the actual tag.
apply
|
|
View applying Status.
|
|
Creating Storage Classes
Change the contents of the configuration file.
|
|
Publish Create Storage Classes.
|
|
Create PVC Verify Availability
|
|
Check the pvc status.
The output shows STATUS as Pending. This means that PVC is not yet used by the application.
Create Pd
|
|
Publish Create.
|
|
Verify that data is written to the volume
Verify that the container is using the Local PV Hostpath volume
|
|
View PVC Status
View the data storage directory for this PV volume
And pv is configured with an affinity that sets the scheduling node to node2.
|
|
The result proves that the data exists only under node2.
Clean up Pod
|
|
Benchmarking
Download the benchmarking Job declaration file
Adjust the following.
Release Run.
|
|
Check the running status.
View Benchmarking Results.
|
|
cleanup
Local PV Device Practices
Compared to Kubernetes local persistent volumes, OpenEBS local PV device volumes have the following advantages :
OpenEBSlocalPVdevice volumeprovideris dynamic,Kubernetesdevice volumeprovideris static.OpenEBS NDMbetter manages the block devices used to create localpvs.NDMprovides the ability to discover block device properties, set device filters, metric collections, and detect if a block device has moved across nodes.
Environmental Dependencies :
k8s 1.12or higherOpenEBS 1.0or higher
Practical environment :
docker 19.03.8k8s 1.18.6CentOS7
/dev/sdb on three nodes are stored as block devices.
|
|
Create a data directory
Set up a directory on the node where Local PV Hostpaths will be created. This directory will be called BasePath. The default location is /var/openebs/local.
Nodes node1, node2, node3 create the /data/openebs/local directory (/data can be pre-mounted with a data disk, if no additional data disk is mounted, the OS ‘/’ mount point storage is used).
|
|
Download the application description file
Release the openebs application
Based on the above configuration file, ensure that the following mirrors are accessible to the k8s cluster (it is recommended to import a local private mirror repository, e.g. : harbor).
Update the mirror tag in openebs-operator.yaml to the actual tag.
Release.
|
|
View Release Status.
|
|
Create Storage Classes
|
|
Creating Pods and PVCs
|
|
Release.
|
|
View pod status.
Verify that pod is associated with pvc as local-device-pvc.
|
|
Observe that the scheduled node is node2 and confirm that the node2 node /dev/sdb is in use.
|
|
It does get used, and therein lies the power of OpenEBS, in its ultimate simplicity. As we discussed above, NDM is responsible for discovering block devices and filtering out devices that should not be used by OpenEBS, for example, detecting disks with OS file systems.
Benchmarking
Create a benchmark test pvc.
Download the Benchmark Job declaration file.
Adjust the following content.
|
|
Release Run.
Check the running status.
|
|
View Benchmarking Results.
|
|
From the results, the performance is doubled compared to Local PV HostPath mode.
Summary
Throughout the testing and validation process, I got the impression that OpenEBS is very simple to use, especially with the deployment of the Local PV engine.
However, there are some shortcomings in OpenEBS at this stage.
cStorandJivahave more components on the data surface, and the configuration is more cumbersome (the first feeling is that there are too many conceptual components).- Some components of
cStorandJivarely on internally defined imagetagfor creation, which cannot be adjusted to private librarytagin offline environment, resulting in components not running successfully. - Single storage type, multiple engines only support block storage type, does not support native multi-node read and write (need to combine with
NFSimplementation), compared withcephand other slightly inferior.
We recommend using OpenEBS as backend storage for the following scenarios.
- Single-computer test environments.
- Multi-computer experimental/demo environments.