Reading and Writing Files
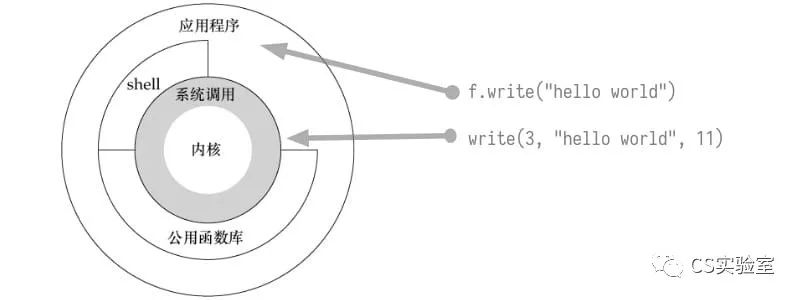
Let’s start by talking about reading and writing files, and what’s going on behind the scenes when we try to write a string of characters to a file, like the following lines of Python code.
1
2
3
|
f = open("file.txt", "w")
f.write("hello world")
f.close()
|
With the strace command, it is easy to see which system calls are used behind this line of command.
1
2
3
4
5
6
7
8
|
$ strace python justwrite.py -e trace=file
···
open("file.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=0, ...}) = 0
...
write(3, "hello world", 11) = 11
close(3) = 0
···
|
The most critical of these is write, where the write system call writes “hello world” to the file descriptor with id 3.
Let’s put aside what’s going on behind these system calls and look at what happens when we read the file, e.g.
1
2
3
4
|
f = open("file.txt", "r")
_ = f.readlines()
f.close()
|
Similarly, let’s look at which system calls are used to read the file.
1
2
3
4
5
6
7
8
9
10
11
|
$ strace python justread.py -e trace=file
...
open("file.txt", O_RDONLY) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=11, ...}) = 0
fstat(3, {st_mode=S_IFREG|0644, st_size=11, ...}) = 0
...
read(3, "hello world", 8192) = 11
read(3, "", 4096) = 0
close(3)
...
|
As you can see, the most important of these is the read system call, which reads the “hello world” string from a file descriptor of 3.
The system call is an api provided by the kernel. As we all know, the operating system hosts all the resources, and in general, programs can only use the system call to let the kernel do the required operations for us (more precisely, the program gets caught up in the kernel to do the operations).
VFS and the File System
To understand what’s going on behind the scenes of system calls, we need to start with VFS.
VFS, known as Virtual File System, is an important interface and infrastructure for IO operations in Linux, and a streamlined Linux IO stack can be drawn to show where VFS is located.
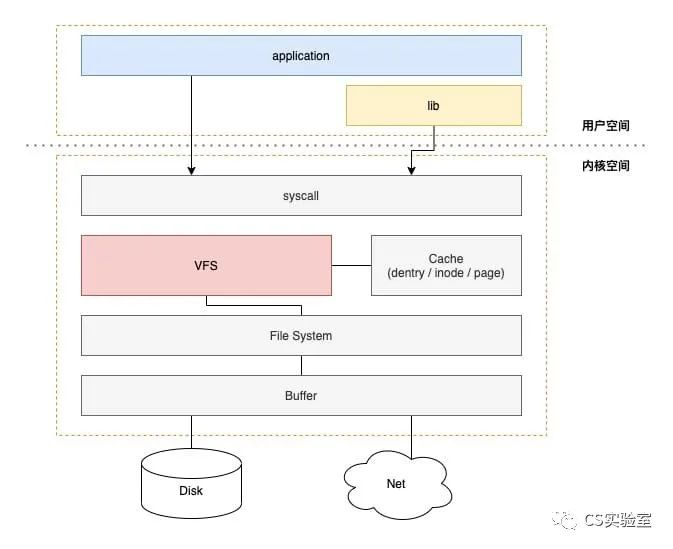
VFS itself can be understood as Linux’s interface to the file system conventions, and Linux uses object-oriented design ideas (and code structure) in order to implement this set of interfaces.
VFS abstracts four main object types.
- super block object: represents an installed file system;
- index node object (inode): represents a specific file;
- directory entry object (dentry): represents a directory entry and a component of a file path;
- file object (file): represents a file opened by the process;
Superblocks
A superblock is a data structure used to store information about a specific file system. It is usually located in a specific sector of the disk. If the inode is the metadata of the file, the superblock is the metadata of the file system.
A superblock is metadata and control information that reflects the file system as a whole. When the file system is mounted, the contents of the superblock are read and the superblock structure is built in memory.
The code structure of a superblock is in linux/fs.h.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
|
struct super_block {
struct list_head s_list; /* Keep this first */
dev_t s_dev; /* search index; _not_ kdev_t */
unsigned char s_blocksize_bits;
unsigned long s_blocksize;
loff_t s_maxbytes; /* Max file size */
struct file_system_type *s_type;
const struct super_operations *s_op;
const struct dquot_operations *dq_op;
const struct quotactl_ops *s_qcop;
const struct export_operations *s_export_op;
unsigned long s_flags;
unsigned long s_magic;
struct dentry *s_root;
struct rw_semaphore s_umount;
int s_count;
atomic_t s_active;
#ifdef CONFIG_SECURITY
void *s_security;
#endif
const struct xattr_handler **s_xattr;
struct list_head s_inodes; /* all inodes */
struct hlist_bl_head s_anon; /* anonymous dentries for (nfs) exporting */
struct list_head s_mounts; /* list of mounts; _not_ for fs use */
struct block_device *s_bdev;
struct backing_dev_info *s_bdi;
struct mtd_info *s_mtd;
struct hlist_node s_instances;
struct quota_info s_dquot; /* Diskquota specific options */
struct sb_writers s_writers;
char s_id[32]; /* Informational name */
u8 s_uuid[16]; /* UUID */
void *s_fs_info; /* Filesystem private info */
unsigned int s_max_links;
fmode_t s_mode;
/* Granularity of c/m/atime in ns.
Cannot be worse than a second */
u32 s_time_gran;
/*
* The next field is for VFS *only*. No filesystems have any business
* even looking at it. You had been warned.
*/
struct mutex s_vfs_rename_mutex; /* Kludge */
/*
* Filesystem subtype. If non-empty the filesystem type field
* in /proc/mounts will be "type.subtype"
*/
char *s_subtype;
/*
* Saved mount options for lazy filesystems using
* generic_show_options()
*/
char __rcu *s_options;
const struct dentry_operations *s_d_op; /* default d_op for dentries */
/*
* Saved pool identifier for cleancache (-1 means none)
*/
int cleancache_poolid;
struct shrinker s_shrink; /* per-sb shrinker handle */
/* Number of inodes with nlink == 0 but still referenced */
atomic_long_t s_remove_count;
/* Being remounted read-only */
int s_readonly_remount;
/* AIO completions deferred from interrupt context */
struct workqueue_struct *s_dio_done_wq;
/*
* Keep the lru lists last in the structure so they always sit on their
* own individual cachelines.
*/
struct list_lru s_dentry_lru ____cacheline_aligned_in_smp;
struct list_lru s_inode_lru ____cacheline_aligned_in_smp;
struct rcu_head rcu;
};
|
There are a bit too many fields, but I think they can be grouped into a few broad categories.
- metadata and control bits of the device
- Metadata and control bits of the file system
- Superfast structure of the operation function
One of the very interesting things about the VFS code is the handling of the manipulation functions, and I was surprised to see that object-oriented programming can be done in C.
The operator functions of the superblock are in a separate structure.
1
|
const struct super_operations *s_op;
|
The super_operations structure contains methods for operating on superblocks, which I think can be considered as a superblock-oriented Interface, since this structure does not have a concrete implementation, but rather function pointers that different file systems can implement to make superblocks available.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
void (*destroy_inode)(struct inode *);
void (*dirty_inode) (struct inode *, int flags);
int (*write_inode) (struct inode *, struct writeback_control *wbc);
int (*drop_inode) (struct inode *);
void (*evict_inode) (struct inode *);
void (*put_super) (struct super_block *);
int (*sync_fs)(struct super_block *sb, int wait);
int (*freeze_fs) (struct super_block *);
int (*unfreeze_fs) (struct super_block *);
int (*statfs) (struct dentry *, struct kstatfs *);
int (*remount_fs) (struct super_block *, int *, char *);
void (*umount_begin) (struct super_block *);
int (*show_options)(struct seq_file *, struct dentry *);
int (*show_devname)(struct seq_file *, struct dentry *);
int (*show_path)(struct seq_file *, struct dentry *);
int (*show_stats)(struct seq_file *, struct dentry *);
#ifdef CONFIG_QUOTA
ssize_t (*quota_read)(struct super_block *, int, char *, size_t, loff_t);
ssize_t (*quota_write)(struct super_block *, int, const char *, size_t, loff_t);
#endif
int (*bdev_try_to_free_page)(struct super_block*, struct page*, gfp_t);
long (*nr_cached_objects)(struct super_block *, int);
long (*free_cached_objects)(struct super_block *, long, int);
};
|
These functions are known by name, all without much explanation, and include the underlying operations of the file system and index nodes.
inode
inode is the more common concept. inode contains all the information the kernel needs to manipulate a file or directory.
The structure of inode is also in linux/fs.h.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
|
/*
* Keep mostly read-only and often accessed (especially for
* the RCU path lookup and 'stat' data) fields at the beginning
* of the 'struct inode'
*/
struct inode {
umode_t i_mode;
unsigned short i_opflags;
kuid_t i_uid;
kgid_t i_gid;
unsigned int i_flags;
#ifdef CONFIG_FS_POSIX_ACL
struct posix_acl *i_acl;
struct posix_acl *i_default_acl;
#endif
const struct inode_operations *i_op;
struct super_block *i_sb;
struct address_space *i_mapping;
#ifdef CONFIG_SECURITY
void *i_security;
#endif
/* Stat data, not accessed from path walking */
unsigned long i_ino;
/*
* Filesystems may only read i_nlink directly. They shall use the
* following functions for modification:
*
* (set|clear|inc|drop)_nlink
* inode_(inc|dec)_link_count
*/
union {
const unsigned int i_nlink;
unsigned int __i_nlink;
};
dev_t i_rdev;
loff_t i_size;
struct timespec i_atime;
struct timespec i_mtime;
struct timespec i_ctime;
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
unsigned short i_bytes;
unsigned int i_blkbits;
blkcnt_t i_blocks;
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount;
#endif
/* Misc */
unsigned long i_state;
struct mutex i_mutex;
unsigned long dirtied_when; /* jiffies of first dirtying */
struct hlist_node i_hash;
struct list_head i_wb_list; /* backing dev IO list */
struct list_head i_lru; /* inode LRU list */
struct list_head i_sb_list;
union {
struct hlist_head i_dentry;
struct rcu_head i_rcu;
};
u64 i_version;
atomic_t i_count;
atomic_t i_dio_count;
atomic_t i_writecount;
const struct file_operations *i_fop; /* former ->i_op->default_file_ops */
struct file_lock *i_flock;
struct address_space i_data;
#ifdef CONFIG_QUOTA
struct dquot *i_dquot[MAXQUOTAS];
#endif
struct list_head i_devices;
union {
struct pipe_inode_info *i_pipe;
struct block_device *i_bdev;
struct cdev *i_cdev;
};
__u32 i_generation;
#ifdef CONFIG_FSNOTIFY
__u32 i_fsnotify_mask; /* all events this inode cares about */
struct hlist_head i_fsnotify_marks;
#endif
#ifdef CONFIG_IMA
atomic_t i_readcount; /* struct files open RO */
#endif
void *i_private; /* fs or device private pointer */
};
|
Like superblocks, inodes have inode_operations structures that contain operation methods.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
struct inode_operations {
struct dentry * (*lookup) (struct inode *,struct dentry *, unsigned int);
void * (*follow_link) (struct dentry *, struct nameidata *);
int (*permission) (struct inode *, int);
struct posix_acl * (*get_acl)(struct inode *, int);
int (*readlink) (struct dentry *, char __user *,int);
void (*put_link) (struct dentry *, struct nameidata *, void *);
int (*create) (struct inode *,struct dentry *, umode_t, bool);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*symlink) (struct inode *,struct dentry *,const char *);
int (*mkdir) (struct inode *,struct dentry *,umode_t);
int (*rmdir) (struct inode *,struct dentry *);
int (*mknod) (struct inode *,struct dentry *,umode_t,dev_t);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *);
int (*setattr) (struct dentry *, struct iattr *);
int (*getattr) (struct vfsmount *mnt, struct dentry *, struct kstat *);
int (*setxattr) (struct dentry *, const char *,const void *,size_t,int);
ssize_t (*getxattr) (struct dentry *, const char *, void *, size_t);
ssize_t (*listxattr) (struct dentry *, char *, size_t);
int (*removexattr) (struct dentry *, const char *);
int (*fiemap)(struct inode *, struct fiemap_extent_info *, u64 start,
u64 len);
int (*update_time)(struct inode *, struct timespec *, int);
int (*atomic_open)(struct inode *, struct dentry *,
struct file *, unsigned open_flag,
umode_t create_mode, int *opened);
int (*tmpfile) (struct inode *, struct dentry *, umode_t);
} ____cacheline_aligned;
|
The inode_operations structure contains the interface for file-related operations, including
- file and directory creation, deletion and renaming
- management of hard and soft connections
- management of permissions
- management of expansion parameters
As well, the inode_operations structure does not have a concrete implementation, but exists only as an interface through function pointers, and the specific operating system will implement the functions in the structure.
Directory entries
VFS treats a directory as a special kind of file, so for a file path, e.g. /dir1/file1, /, dri1 and file1 are all directory entries.
Each component of the above path, whether it is a directory or a file, is represented by a directory entry structure, which makes it easier to perform directory operations in VFS, such as pathname lookup.
The data structure of directory entries is in linux/dcache.h.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
/*
* Try to keep struct dentry aligned on 64 byte cachelines (this will
* give reasonable cacheline footprint with larger lines without the
* large memory footprint increase).
*/
#ifdef CONFIG_64BIT
# define DNAME_INLINE_LEN 32 /* 192 bytes */
#else
# ifdef CONFIG_SMP
# define DNAME_INLINE_LEN 36 /* 128 bytes */
# else
# define DNAME_INLINE_LEN 40 /* 128 bytes */
# endif
#endif
#define d_lock d_lockref.lock
struct dentry {
/* RCU lookup touched fields */
unsigned int d_flags; /* protected by d_lock */
seqcount_t d_seq; /* per dentry seqlock */
struct hlist_bl_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */
/* Ref lookup also touches following */
struct lockref d_lockref; /* per-dentry lock and refcount */
const struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
unsigned long d_time; /* used by d_revalidate */
void *d_fsdata; /* fs-specific data */
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* our children */
struct hlist_node d_alias; /* inode alias list */
};
|
Unlike the previous structure, the fields of the directory entry are simpler and do not have disk-related attributes. This is because directory entries are created as they are used, and are parsed by VFS based on path strings. Therefore, it is clear that directory entries are not data stored on disk, but are structures that serve as caches in memory.
The cache of directory entries can be viewed via slabinfo.
1
2
3
|
$ slabinfo | awk 'NR==1 || $1=="dentry" {print}'
Name Objects Objsize Space Slabs/Part/Cpu O/S O %Fr %Ef Flg
dentry 608813 192 139.5M 33924/16606/142 21 0 48 83 a
|
Since directory entries are in-memory caches of the file system, the management of directory entries is very similar to the management of ordinary cache. For example, determining whether a cache is valid or not, releasing the cache structure, and so on. These operations are included in the operation structure of a directory entry.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
struct dentry_operations {
int (*d_revalidate)(struct dentry *, unsigned int);
int (*d_weak_revalidate)(struct dentry *, unsigned int);
int (*d_hash)(const struct dentry *, struct qstr *);
int (*d_compare)(const struct dentry *, const struct dentry *,
unsigned int, const char *, const struct qstr *);
int (*d_delete)(const struct dentry *);
void (*d_release)(struct dentry *);
void (*d_prune)(struct dentry *);
void (*d_iput)(struct dentry *, struct inode *);
char *(*d_dname)(struct dentry *, char *, int);
struct vfsmount *(*d_automount)(struct path *);
int (*d_manage)(struct dentry *, bool);
} ____cacheline_aligned;
|
File
The file structure is used to represent the files that have been opened by the process and is the data structure of the current file’s memory. This structure is created at the open system call and released at the close system call, and all operations on files revolve around this structure.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
#define f_dentry f_path.dentry
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
/*
* Protects f_ep_links, f_flags, f_pos vs i_size in lseek SEEK_CUR.
* Must not be taken from IRQ context.
*/
spinlock_t f_lock;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
loff_t f_pos;
struct fown_struct f_owner;
const struct cred *f_cred;
struct file_ra_state f_ra;
u64 f_version;
#ifdef CONFIG_SECURITY
void *f_security;
#endif
/* needed for tty driver, and maybe others */
void *private_data;
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct list_head f_ep_links;
struct list_head f_tfile_llink;
#endif /* #ifdef CONFIG_EPOLL */
struct address_space *f_mapping;
#ifdef CONFIG_DEBUG_WRITECOUNT
unsigned long f_mnt_write_state;
#endif
};
|
For a file structure, it is used to represent a file that has been opened, but it should be known that when a program opens a file, it gets a file descriptor, and there is still a difference between a file descriptor and a file, which will be mentioned later. As you can see, the file structure has a reference count field named f_count. When the reference count is cleared, the release method in the file operation structure is called, and what effect this method will have is determined by the implementation of the file system.
For the file operations structure, that is, file_operations, the names of the operations functions and system calls/library functions are basically the same, so we won’t go over them here.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
int (*iterate) (struct file *, struct dir_context *);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, loff_t, loff_t, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **);
long (*fallocate)(struct file *file, int mode, loff_t offset,
loff_t len);
int (*show_fdinfo)(struct seq_file *m, struct file *f);
};
|
The four structures and related operations of VFS are described above, but they only provide a set of interface definitions, or a standard for interfacing to a file system, a static concept.
But for users to be able to use and perceive a file system, they need to mount into the current directory tree, and they need to programmatically open the files in the file system. For these operations, some additional data structures are required.
The kernel also uses some data structures to manage the file system and related data, such as file_system_type to describe a particular file system type.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
struct file_system_type {
const char *name;
int fs_flags;
#define FS_REQUIRES_DEV 1
#define FS_BINARY_MOUNTDATA 2
#define FS_HAS_SUBTYPE 4
#define FS_USERNS_MOUNT 8 /* Can be mounted by userns root */
#define FS_USERNS_DEV_MOUNT 16 /* A userns mount does not imply MNT_NODEV */
#define FS_RENAME_DOES_D_MOVE 32768 /* FS will handle d_move() during rename() internally. */
struct dentry *(*mount) (struct file_system_type *, int,
const char *, void *);
void (*kill_sb) (struct super_block *);
struct module *owner;
struct file_system_type * next;
struct hlist_head fs_supers;
struct lock_class_key s_lock_key;
struct lock_class_key s_umount_key;
struct lock_class_key s_vfs_rename_key;
struct lock_class_key s_writers_key[SB_FREEZE_LEVELS];
struct lock_class_key i_lock_key;
struct lock_class_key i_mutex_key;
struct lock_class_key i_mutex_dir_key;
};
|
Every filesystem mounted to a system, before it is mounted, is just a file_system_type object, which contains the superblock mount and unmount methods to implement mount.
The mount operation not only completes the mount, but also creates a vfsmount structure to represent a mount point. The code for vfsmount is in linux/mount.h.
1
2
3
4
5
|
struct vfsmount {
struct dentry *mnt_root; /* root of the mounted tree */
struct super_block *mnt_sb; /* pointer to superblock */
int mnt_flags;
};
|
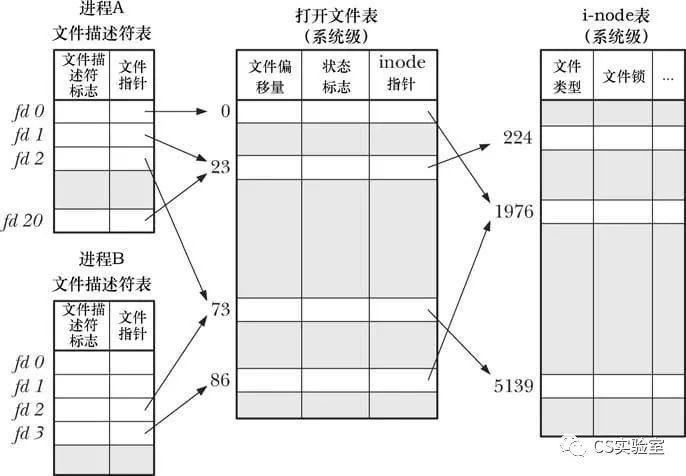
File Descriptors
In the system, each process has its own set of “open files”, and each program has a different file descriptor and read/write offset for each file. Therefore, there are several other data structures related to it that are closely related to the VFS data structure mentioned above.
Here is files_struct, which is related to the file descriptor, and is confusingly similar to the file name mentioned earlier. The biggest difference between the two is that the latter is used to maintain all open files on the system, while the former maintains all files opened by the current process, and the former will eventually point to the latter.
The structure of files_struct is located in linux/fdtable.h.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
/*
* Open file table structure
*/
struct files_struct {
/*
* read mostly part
*/
atomic_t count;
struct fdtable __rcu *fdt;
struct fdtable fdtab;
/*
* written part on a separate cache line in SMP
*/
spinlock_t file_lock ____cacheline_aligned_in_smp;
int next_fd;
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
|
The pointer to the fd_array array is a pointer to all the files opened by the process, and the process uses this field to find the corresponding file and thus the corresponding inode.
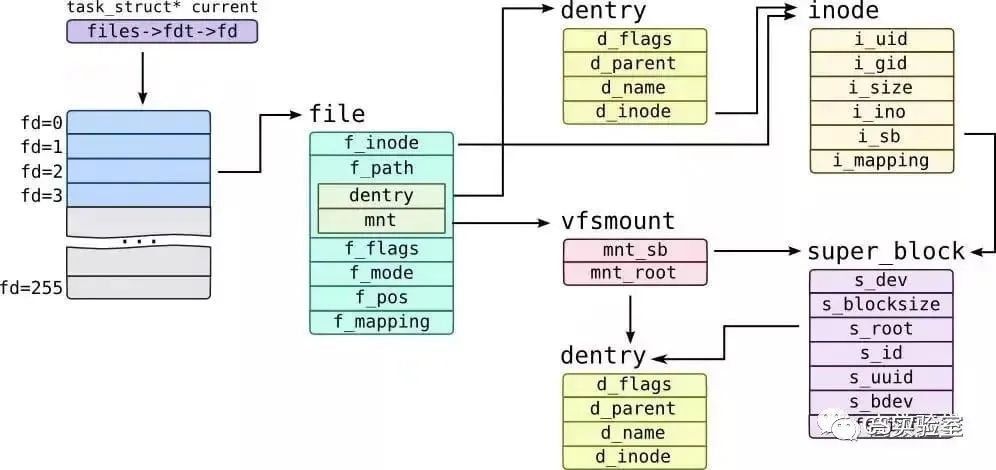
File System
By combing through the data structures in the Linux kernel, we can basically understand the direct relationship between the data structures from the process of opening a file to the process of VFS processing, because these structures adopt “object-oriented programming around data”, and the structures themselves carry “methods”, so we can basically sort out the execution flow of IO requests. The following diagram.
Finally, let’s talk about how the file system works with VFS by introducing two very typical file systems.
Legacy file system: ext2
ext2 was once an excellent filesystem, the most widely used on Linux, and the successor to the original Linux filesystem ext. Although ext2 is no longer used, it is a good introduction to how file systems work because of the simplicity of its design.
As mentioned earlier, the ext2 filesystem consists of the following parts.
The boot block: always used as the first block of the filesystem. The boot block is not used by the file system, but only contains the information used to boot the operating system. The operating system only needs a boot block, but all file systems have a boot block, and the vast majority of them are unused.
Superblock: A separate block immediately following the boot block that contains information about the parameters related to the file system, including
- inode table capacity.
- The size of the logical blocks in the file system.
- The size of the file system in terms of logical blocks.
inode table: Each file or directory in the file system corresponds to a unique record in the inode table. This record registers various information about the file, such as
- File type (for example, regular files, directories, symbolic links, and character devices, etc.)
- File owner (also known as user ID or UID)
- File belongs to a group (also known as Group ID or GID)
- Access rights for 3 types of users: attribute owners, attribute groups, and other users
- 3 timestamps: last access time, last modification time, last change of file status
- Number of hard links to the file
- The size of the file, in bytes
- The actual number of blocks allocated to the file
- Pointer to the file data block
Data blocks: Most of the space in the file system is used to hold the data that makes up the files and directories that reside on top of the file system.
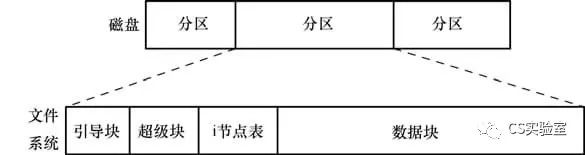
The ext2 file system stores files in blocks that are not necessarily contiguous or even sequential. To locate the file data blocks, the kernel maintains a set of pointers within the inode.
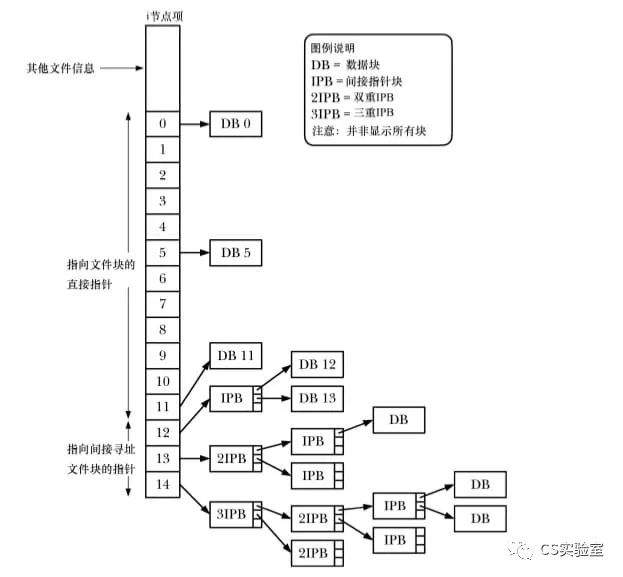
An inode structure contains 15 pointers (0-14), the first 11 of which are used to point to data blocks so that they can be referenced directly in small file scenarios, and the later pointers to indirect pointer blocks to point to subsequent data blocks.
Thus it can also be seen that for blocks of 4096 bytes in size, the maximum single file is theoretically equal to approximately 1024 x 1024 x 1024 x 4096 bytes, or 4TB (4096 GB).
Log file system: XFS
The second example is a look at the common modern file system xfs, developed by Silicon Graphics for their IRIX operating system, which has a good performance for large file handling and transfer performance.
The point of this article is not to talk about how xfs works, but to look at xfs from a Linux perspective. xfs, unlike ext, is not designed for Linux, so it does not follow the VFS design for file system processing.
In VFS, file operations are divided into two layers: file (file read/write, etc.) and inode (file creation/deletion, etc.), whereas in xfs there is only one layer, vnode, which provides all operations. So during the porting of XFS to Linux, a conversion intermediate layer linvfs was introduced to adapt VFS, mapping operations on file and inode to vnode.
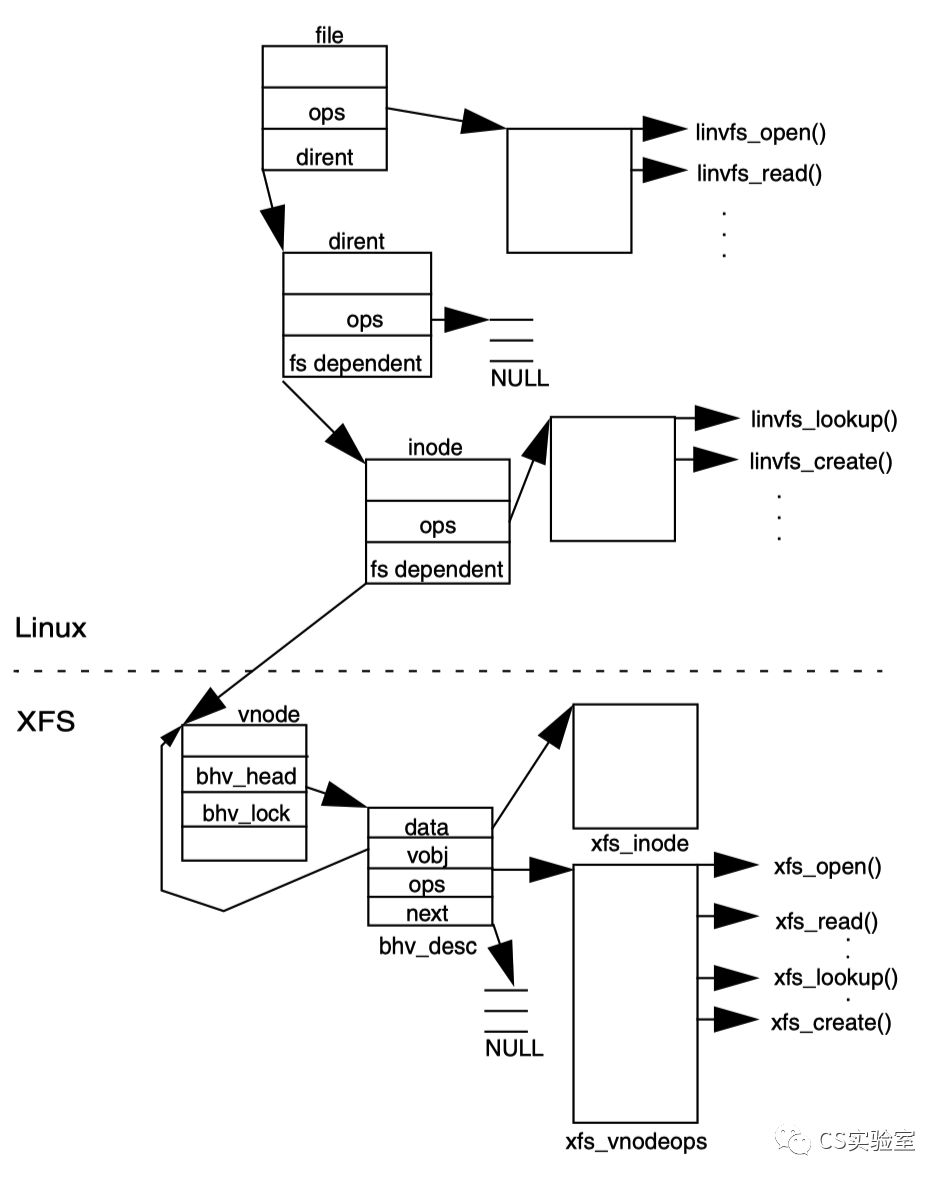
Finally
This article has sorted out the core VFS data structures and the relationships between them, but understanding what VFS is useful for. I think it is useful in two ways.
The first is to understand how the Linux file system works, which is useful to understand what happens in an IO.
The second is to help understand the IO cache in Linux. VFS is related to many caches, including page cache, directory cache, inode cache.
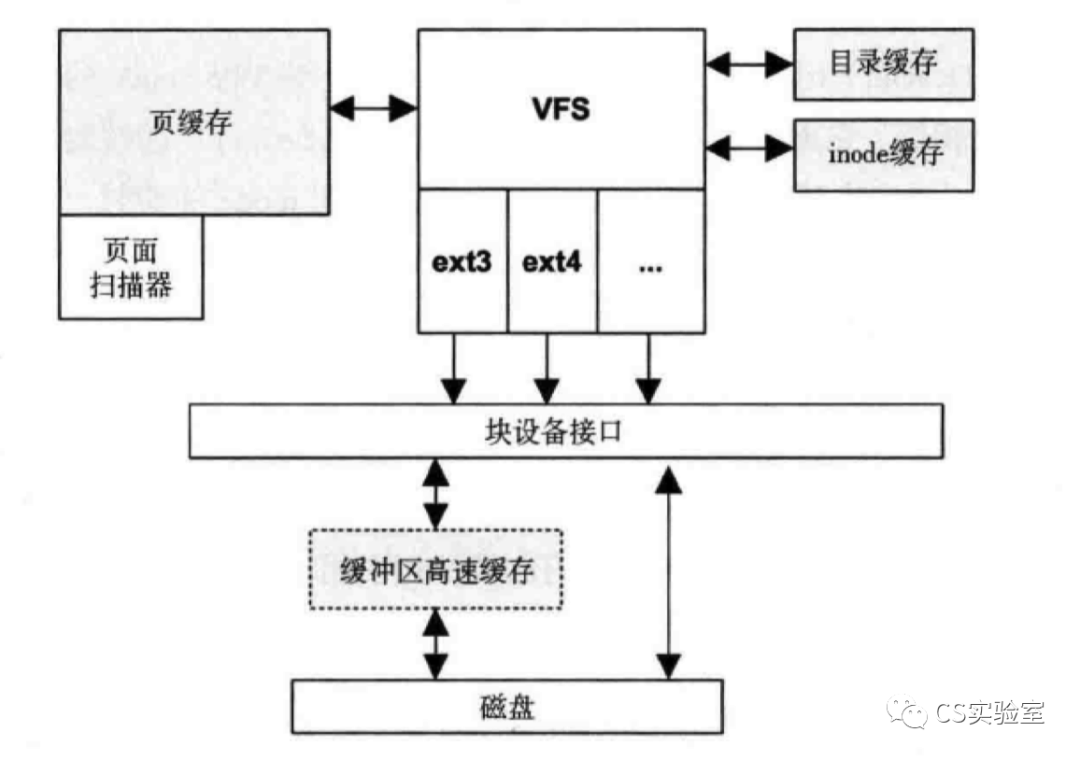
In addition to the inode and directory entry structure in memory, the page cache, for example, is used to cache the most recently read and written blocks of file data, where the file.address_space field is used to manage the page cache.