As we all know, javascript has been a single-threaded, non-blocking scripting language since its inception. This was dictated by its original purpose: to interact with browsers.
Single-threaded means that javascript code has only one main thread to handle all tasks at any given time of execution.
Non-blocking means that when the code needs to perform an asynchronous task (a task that does not return a result immediately and takes some time to return, such as an I/O event), the main thread suspends (pends) the task and then executes the corresponding callback when the asynchronous task returns a result, according to certain rules.
Single-threading is necessary and is a cornerstone of the javascript language, one reason being that we need to perform a variety of dom operations in the browser, which is the primary execution environment. Imagine if javascript was multi-threaded, what happens when two threads perform an operation on a dom at the same time, such as one adding an event to it and the other deleting it? So, to ensure that nothing like this example happens, javascript chooses to use only one main thread to execute the code, which ensures consistent program execution.
Of course, it is now recognized that single threads limit the efficiency of javascript while maintaining the order of execution, and so web worker technology has been developed, which purports to make javascript a multi-threaded language.
However, multithreading using web worker technology has a number of limitations, such as the fact that all new threads are under the full control of the main thread and cannot execute independently. This means that these “threads” should actually be sub-threads of the main thread. In addition, these sub-threads do not have access to perform I/O operations and can only share tasks such as computation with the main thread. So strictly speaking these threads do not have full functionality, and therefore this technology does not change the single-threaded nature of the javascript language.
It is foreseeable that javascript will remain a single-threaded language in the future.
That said, another feature of javascript mentioned earlier is that it is “non-blocking”, so how exactly does the javascript engine achieve this? The answer is the event loop that is the subject of today’s article.
Although there is a similar event loop in nodejs as in the traditional browser environment, However, there are many differences between the two, so they are explained separately.
Browser event loop
Execution Stack and Event Queue
When javascript code is executed, it is distinguished by storing different variables in different locations in memory: the heap and the stack. The heap holds objects, while the stack holds base type variables and pointers to objects, but the execution stack is a little different than the stack above.
As we know, when we call a method, js generates an execution environment (context) corresponding to the method, also called execution context. This execution context contains the private scope of the method, the pointers to the upper scope, the parameters of the method, the variables defined in this scope, and the this object of this scope. And when a series of methods are called in sequence, because js is single-threaded and only one method can be executed at a time, these methods are queued up in a separate place called the execution stack.
When a script is executed for the first time, the js engine parses this code and adds the synchronized code from it to the execution stack in the order of execution, and then starts execution from the beginning. If the current execution is a method, then js adds the method’s execution environment to the execution stack and then enters that execution environment to continue executing the code in it. When the code in this execution environment is finished and the result is returned, js will exit this execution environment and destroy it, returning to the execution environment of the previous method. This process is repeated until all the code in the execution stack has been executed.
This process is illustrated visually in the following image, where the global is the code that is added to the execution stack when the script is first run.
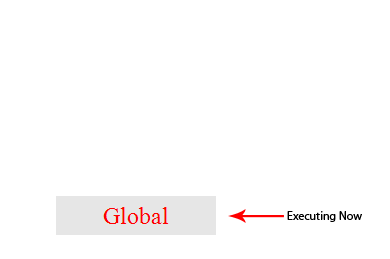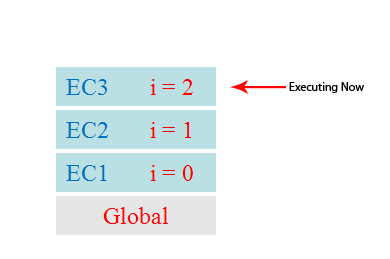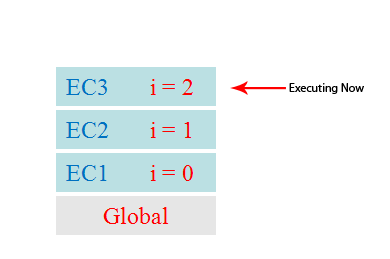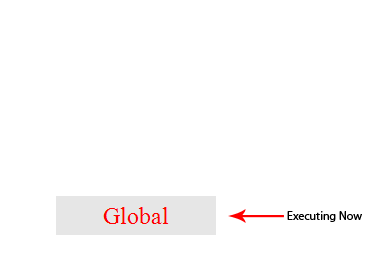
As you can see from the picture, the execution of a method adds the execution environment of that method to the execution stack, and other methods can be called in that execution environment, even by itself, which results in nothing more than adding another execution environment to the execution stack. This process can go on indefinitely unless a stack overflow occurs, i.e., the maximum amount of memory that can be used is exceeded.
The above process is all about synchronous code execution, but what happens when an asynchronous code (such as sending an ajax request for data) is executed? As mentioned before, another major feature of js is non-blocking, and the key to achieving this lies in the following mechanism - the event queue (Task Queue).
Instead of waiting for an asynchronous event to return a result, the js engine hangs the event and continues executing other tasks in the execution stack. When an asynchronous event returns a result, js adds the event to a different queue than the current execution stack, which we call the Event Queue. The event queue does not immediately execute its callback, but waits until all tasks in the current execution stack have been executed and the main thread is idle, then the main thread will look to see if there are any tasks in the event queue. If there is, the main thread will take out the first event from it and put the callback corresponding to this event into the execution stack, then execute the synchronization code in it, and so on, thus forming an infinite loop.
Here is another diagram to show the process.
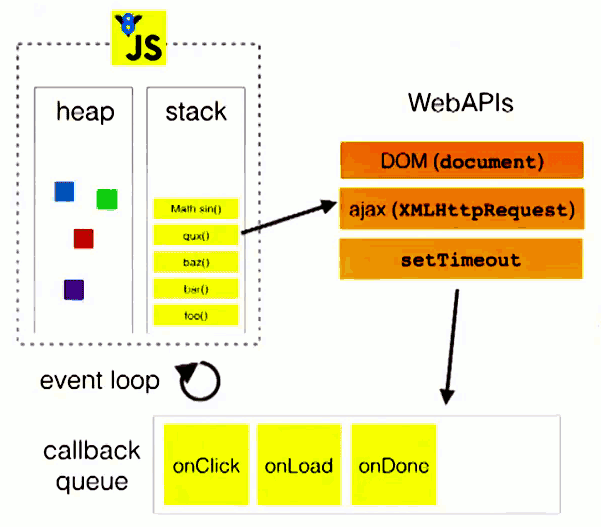
The stack in the figure represents what we call the execution stack, the web apis represent some asynchronous events, and the callback queue is the event queue.
macro task vs. micro task
The above event loop process is a macro representation, but in fact, because asynchronous tasks are not the same as each other, their execution priority is also different. The different asynchronous tasks are divided into two categories: micro task and macro task.
The following events belong to macro tasks.
- setInterval()
- setTimeout()
The following events are micro tasks
- new Promise()
- new MutationObserver()
As we described earlier, in an event loop, an asynchronous event returns a result and is placed in a task queue. However, depending on the type of the asynchronous event, the event will actually go to the corresponding macro task queue or micro task queue. And when the current execution stack is empty, the main thread checks to see if the event exists in the micro-task queue. If there is no event, then go to the macro task queue and take out an event and add the corresponding one to the current execution stack; if there is, it will execute the callbacks corresponding to the events in the queue in turn until the micro task queue is empty, then go to the macro task queue and take out the top event and add the corresponding callback to the current execution stack, and so on, and enter the loop.
We just need to remember that when the current execution stack is finished, all the events in the microtask queue will be processed first, and then we will go to the macro task queue to retrieve an event. In the same event loop, the micro-task is always executed before the macro-task.
This would explain the result of the following code.
Output results.
node event loop
Differences from the browser environment
In node, the event loop exhibits much the same state as in the browser. The difference is that node has its own model. node’s implementation of the event loop relies on the libuv engine. We know that node chooses the chrome v8 engine as its js interpreter, and that the v8 engine parses the js code to call the corresponding node api, which is driven by the libuv engine, executes the corresponding tasks, and puts the different events in different queues waiting to be executed by the main thread. So the event loop in node actually exists in the libuv engine.
Event Loop Model
The following is a model of an event loop in the libuv engine.
|
|
Note: Each square in the model represents a phase of the event cycle
This model is given in an article on the official node web site, and the following explanations are taken from that article.
Event Loop Stages Explained
From the above model, we can roughly analyze the sequence of the event loop in node.
external input data -> polling phase (poll) -> check phase (check) -> close event callback phase (close callback) -> timer detection phase (timer) -> I/O callbacks -> idle, prepare -> poll.
The names of the above phases are translated according to my personal understanding, in order to avoid errors and ambiguities, the following explanation will be used in English to indicate these phases.
The general functions of these phases are as follows.
- timers: This stage executes callbacks from the timer queue such as setTimeout() and setInterval().
- I/O callbacks: This stage executes almost all callbacks, but excludes the close event, timer, and setImmediate() callbacks.
- idle, prepare: This stage is only used internally and can be ignored.
- poll: Wait for new I/O events, node blocks here in some special cases.
- check: setImmediate() callbacks are executed at this stage.
- close callbacks: Callbacks for close events like socket.on(‘close’, …).
Let’s explain these phases in detail in the order in which the code enters the libuv engine for the first time.
poll phase
When the v8 engine parses the js code into the libuv engine, the loop first enters the poll phase. the poll phase has the following execution logic: it first checks if there are events in the poll queue, and then executes the callbacks in first-in-first-out order if there are tasks. When the queue is empty, it checks whether there are setImmediate() callbacks, and if so, it enters the check phase to execute these callbacks, but it also checks whether there are expired timers, and if so, it puts the callbacks of these expired timers into the timer queue in the order they are called. The order of the two is not fixed and is influenced by the environment in which the code is running. If both queues are empty, then the loop stays in the poll phase until an i/o event returns, and the loop enters the i/o callback phase and executes the callback for that event immediately.
It is worth noting that the poll phase does not actually execute the callbacks in the poll queue indefinitely, and that the poll phase terminates the execution of the next callback in the poll queue in two cases.
- All callbacks are executed.
- the number of executions exceeds the node limit.
check phase
The check phase is dedicated to executing the callback of the setImmediate() method. The event loop enters this phase when the poll phase goes idle and there is a callback in the setImmediate queue.
close phase
When a socket connection or a handle is abruptly closed (e.g. when the socket.destroy() method is called), the close event is sent to this stage to execute the callback, otherwise the event is sent out using the process.nextTick() method.
timer phase
This phase executes all callbacks due to the timer queue on a first-in-first-out basis. A timer callback is a callback function set by the setTimeout or setInterval function.
I/O callback phase
As mentioned above, this phase performs callbacks for most I/O events, including some for the operating system. For example, if there is a TCP connection error, the system needs to execute a callback to get a report of this error.
process.nextTick()
Although not mentioned, there is actually a special queue in the node, the nextTick queue, where callbacks are executed without being represented as a phase, but the events are prioritized when each phase is ready to move to the next phase. When the event loop is ready to move to the next stage, it checks if there is a task in the nextTick queue, and if so, clears the queue first. Unlike the execution of tasks in the poll queue, this operation does not stop until the queue is emptied. This means that using process.nextTick() incorrectly will cause the node to enter a dead loop until a memory leak occurs.
So what is the best way to use this method? Here is an example.
In this example, when the listen method is called, it is immediately bound to the corresponding port unless the port is occupied. This means that this port can immediately trigger the listening event and execute its callback. However, at this point on('listening') does not have the callback set up yet, so naturally there is no callback to execute. To avoid this, node uses the process.nextTick() method in the listen event to ensure that the event is triggered after the callback function is bound.
setTimeout() and setImmediate()
Of the three methods, these two are the most easily confused. In fact, they behave very similarly in some cases. In reality, however, the two methods have very different meanings.
The setTimeout() method defines a callback and expects it to be executed first after the time interval we specify. Note the “first execution”, which means that the callback will not be executed exactly after the interval we expect, due to the many influences of the operating system and the current execution task. There is an inevitable delay and error in the execution time. node will execute the task you set at the first time the timer callback can be executed.
The setImmediate() method is meant to be executed immediately, but it actually executes the callback at a fixed stage, after the poll stage. Interestingly, this name is the best match for the previously mentioned process.nextTick() method. node developers are aware of the confusion over the naming of the two methods, and have said that they will not switch the names of the two methods - since there are a large number of node programs that use them, the benefit of switching the names is not worth the impact it would have. The benefit of swapping the names is not worth mentioning compared to its impact.
setTimeout() and setImmediate(), which does not set the time interval, behave very similarly. Guess what the result of the following code is?
Actually, the answer is not necessarily. That’s right, even the node developers can’t tell exactly who comes before and who goes after. It depends on the environment in which the code is running. Various complexities in the runtime environment can cause the order of the two methods in the synchronization queue to be randomly determined. However, there is one case where the order of execution of two method callbacks can be accurately determined, and that is in the case of an I/O event callback. The order of the following code is always fixed.
The answer will always be:
Because in the I/O event callbacks, the setImmediate method callback is always executed before the timer callback.