By reusing previously acquired resources, you can significantly improve the performance of your website and applications. Web caching reduces wait times and network traffic. By using HTTP caching, it becomes more responsive.
Typically http caching is divided into strong caching and negotiated caching.
1. Strong caching
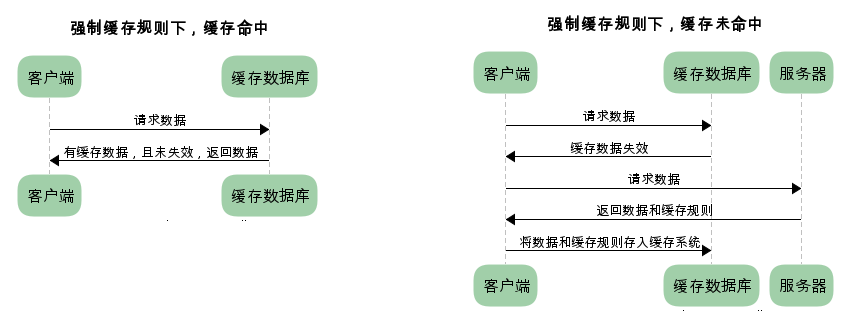
Use browser local cache directly within the agreed fixed time. This approach is suitable for resources that are not updated frequently, such as js,css,image and other static resources; also this is a disadvantage, if the cache time is set too long, the updated content is not timely; if the cache time is set too short, it causes the problem that the content is not updated, but the cache time is up.
There are two general ways to set strong caching.
- setting the expiration point of the current resource through Expires.
- setting the cache time from the first request through cache-control.
1.1 Expires
Set this field on the server side to indicate the expiration time of this resource.
|
|
The browser then takes its local time and compares it to the time in this field, and if it has not yet reached its expiration time, it continues to use the cache, otherwise it generates a new request.
This presents a problem in that the length of that resource cache is related to its local time, e.g. setting the local computer time in 2039 for all resources currently being sent down, cannot be cached.
1.2 cache-control
Expires is a field that existed since HTTP 1.0. To solve the above problem with Expires, the cache-control field was introduced in HTTP 1.1. Instead of using a uniform expiration time, this field tells the browser how long to cache the request, starting from the first time it is received.
If we build a simple http service with nodejs, setting this field is also simple.
If you use express, you can set it up like this.
|
|
When the cache works, the resource is prompted from memory cache or from disk cache and the server no longer receives the request.
In Chrome, when refreshing a page, you will see that cache-control or Expires is disabled. This is because Google Chrome ignores the header Cache-Control or Expires header if the request is made immediately after another request for the same URI in the same tab (by clicking the refresh button, or F5, or something like that). It may have an algorithm to guess what the user really wants to do. One way to test the Cache-Control header is to return an HTML document with a link to itself. When that link is clicked, Chrome drops the document from its cache.
So how can I see the effect? Open a new window, open the console, then request the link again and you’ll see that it’s gone cached, Is Chrome ignoring Cache-Control: max-age?.
1.3 Other uses of cache-control
1.3.1 Components of cache-control
The value of cache-control consists of 3 main parts, any of which can be used individually or in combination (see the document Cache-Control).
-
Cacheability: i.e., how the resource is cached
- public: indicates that the response can be cached by any object (including: the client sending the request, the proxy server, etc.), even if the content is not normally cacheable. (For example: 1. the response does not have a max-age directive or Expires message header; 2. the response corresponds to a request method that is POST.) private: indicates that the response can only be cached.
- private: indicates that the response can only be cached by a single user, not as a shared cache (i.e., the proxy server cannot cache it). A private cache can cache the content of the response, e.g., the local browser of the corresponding user.
- no-cache: forces the cache to submit the request to the original server for validation (negotiated cache validation) before publishing a cached copy.
- no-store: The cache should not store anything about the client request or the server response, i.e., no cache is used. This
no-storeis stricter thanno-cache, where no-cache is a no-go strong cache, but negotiated cache can still be used, but no-store is a no-cache of any content.
-
Expiration time
max-page=<seconds>: Sets the maximum period of cache storage beyond which the cache is considered expired (in seconds). In contrast to Expires, the time is relative to the time of the request.s-maxage=<seconds>: overrides the max-age or Expires header, but only for shared caches (such as individual proxies); private caches will ignore it.
-
Revalidate and reload
- must-revalidate: Once a resource has expired (e.g. has exceeded max-age), the cache cannot respond to subsequent requests with that resource until it has successfully validated with the original server.
- proxy-revalidate: Works the same as must-revalidate, but it only applies to shared caches (such as proxies) and is ignored by private caches.
- immutable Experimental: Indicates that the response body does not change over time. The resource (if not expired) does not change on the server, so the client should not send a revalidation request header (such as If-None-Match or If-Modified-Since) to check for updates, even if the user explicitly refreshes the page. In Firefox, immutable can only be used for
https://transactions.
1.3.2 Example of use
These values can be used in any combination, e.g.
Files that are generally not too altered can be cached in all segments for 600s (↓).
|
|
Close the cache, no storage anywhere (↓).
|
|
Clients can cache resources, but must re-validate them each time (↓), e.g. by specifying no-cache or max-age=0 , must-revalidate, etc.
|
|
|
|
1.4 Priority of cache-control and Expires
Both of these fields determine the expiration time of a resource, so if both are present, which one will the browser choose?
As defined in RFC2616.
If a response includes both an Expires header and a max-age directive, the max-age directive overrides the Expires header, even if the Expires header is more restrictive. This rule allows an origin server to provide, for a given response, a longer expiration time to an HTTP/1.1 (or later) cache than to an HTTP/1.0 cache. This might be useful if certain HTTP/1.0 caches improperly calculate ages or expiration times, perhaps due to desynchronized clocks.
When both are present, max-age has higher priority.
1.5 Difference between memory cache and disk cache
Memory cache is the cache in memory, which mainly contains the resources that have been crawled in the current page, such as styles, scripts, images, etc. that have been downloaded from the page. Although the memory cache is efficient for reading, the cache is short-lived and will be released with the release of the process. Once we close the Tab page, the in-memory cache is also released.
So since the in-memory cache is so efficient, can’t we just keep all the data in memory?
This is not possible. The memory in a computer must be much smaller than the hard disk, and the operating system needs to be careful about how much memory it uses, so we must not have much memory to use.
When we refresh the page again after visiting it, we can find that much of the data comes from the memory cache.
An important cached resource in the memory cache is the resource downloaded by the preloader directive (for example). The preloader directive is known to be a common means of page optimization, parsing js/css files while the next resource is requested on the network.
One thing to note is that memory cache does not care about the value of the HTTP cache header Cache-Control of the returned resource when caching it, and the matching of resources is not just for URLs, but may also be for other features such as Content-Type, CORS, etc..
Disk Cache is also a cache stored in the hard disk, the read speed is slower, but everything can be stored to disk, compared to Memory Cache wins in capacity and storage timeliness.
Of all browser caches, Disk Cache has basically the largest coverage. It determines which resources need to be cached based on fields in HTTP Herder, which resources can be used directly without requesting them, and which resources have expired and need to be re-requested. And even in the case of cross-site, once a resource at the same address is cached by the drive, it will not be requested again. The vast majority of caching comes from Disk Cache, which is described in more detail below in the protocol header field for HTTP.
What files does the browser throw into memory? What goes to the hard drive?
There are different opinions on this, but the following are more reliable.
- For large files, the probability is that they are not stored in memory, and the reverse takes precedence.
- files are stored into the hard disk first if the current system memory usage is high.
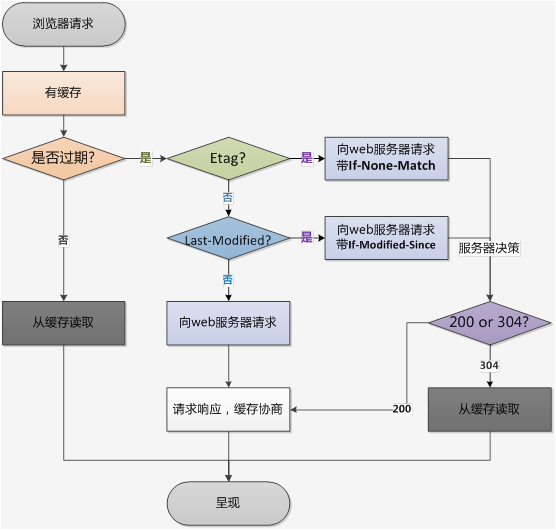
The process of requesting data under strong cache.
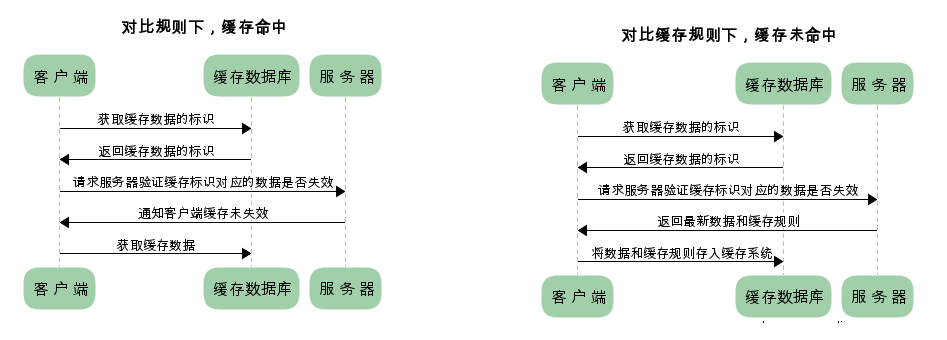
2. Negotiating the cache
Based on the content’s last-modified time (Last-Modified), or identifier (ETag), to determine if the content has changed, and if not, tell the browser to just use the cache, otherwise return the latest content.
Negotiating the cache is done each time the server is requested, and then the server verifies whether to go to the cache, or to send down new content. When the client-side cache can be used, it simply returns the 304 status code.
2.1 last-modified
last-modified is a response header that indicates when a resource was last modified and is used to determine if the received or stored resources are consistent with each other.
2.1.1 Using last-modified to implement caching
If the last response has a last-modified field, then later requests for resources will automatically have an If-Modified-Since field in the header with the value returned by the last-modified. Our server can compare this If-Modified-Since field with the modification time of the resource, and if there is no change, it will return 304 directly, and if there is a change, it will send the new content and the new last-modified field.
Let’s take express framework as an example to implement this caching logic.
|
|
This allows you to determine whether to use caching by the modification time of a resource.
2.1.2 Defects of last-modified
However, this field is not very accurate when determining consistency for the following reasons.
- last-modified is only accurate to the second level at most, so if there are multiple modifications within 1 second, it will be considered as no changes.
- if there are duplicate uploads of the file, or if the document is opened and then saved, this may result in a modification of the time, but the content does not actually change.
In response to these problems, another etag response field has appeared in the http protocol.
2.2 etag
An etag is an identifier, such as hash value, for the content of a resource. This makes caching more efficient and saves bandwidth, since the web server does not need to send a full response if the content has not changed. And if the content changes, using an ETag helps prevent simultaneous updates to resources from overwriting each other (“collisions in the air”).
If the content of a resource in a given URL changes, a new Etag value must be generated. Etags are therefore similar to fingerprints and may also be used by some servers for tracking purposes. Comparing etags can quickly determine if this resource has changed, but it may also be permanently retained by the tracking server.
2.2.1 Caching with etags
If the last response had an etag field, then subsequent requests for resources will automatically have an If-None-Match field in the header with the value returned by the last etag. Our server can compare this If-None-Match field with the tag of the resource, and if there is no change, it will return 304 directly, and if there is a change, it will send the new content and the new etag field.
Let’s take express framework as an example to implement this caching logic.
|
|
2.2.2 etag and last-modified
When both etag and last-modified are present, etag has higher priority; similarly, if-none-match has higher priority than if-modified-since.
Also, etag has better granularity of control over resource updates than last-modified, so no matter how the source file is modified, as long as the content remains the same, etag remains the same and the cache can be used forever.
The request flow under negotiated caching.
3. Summary
We have explained the mechanism and implementation of mandatory caching and negotiated caching, and you can decide which caching method to use and how long to cache based on the caching characteristics of your resources.
In general, mandatory caching has a higher priority than negotiated caching, giving priority to determining whether mandatory caching exists.