1 Background
Query Understanding (QU, Query Understanding) is a core module of our company’s search business, and its main responsibility is to understand user queries and generate basic signals such as query intent, composition, and rewriting, which are applied to many aspects of search such as recall, sorting, and display, and are crucial to the basic search experience. The online main program of the service is developed based on C++ language, and the service will be loaded with a large amount of word list data, prediction models, etc. The offline production process of these data and models has many text parsing capabilities that need to be consistent with the online service so as to ensure consistency at the effect level, such as text normalization, word separation, etc.
These offline production processes are usually implemented in Python and Java. If online and offline are developed separately in different languages, it is difficult to maintain the unity of strategy and effect. Also these capabilities will have constant iterations, and in this dynamic scenario, the constant maintenance of multiple language versions to level the effect brings great cost to our daily iterations. Therefore, we try to solve this problem through the technique of calling dynamic link libraries across languages, i.e., developing a C++-based so once, encapsulating it into component libraries of different languages through link layers of different languages, and putting it into the corresponding generation process. The advantages of this solution are very obvious, the main business logic only needs to be developed once, the encapsulation layer only needs a very small amount of code, the main business iteration upgrade, other languages almost do not need to change, only need to include the latest dynamic link library, release the latest version can be. At the same time C++, as a more underlying language, brings us some performance advantages in many scenarios where it is more computationally efficient and has higher hardware resource utilization.
This article gives a complete overview of the problems and some practical experiences we encountered when trying this technical solution in actual production, and we hope to provide some reference or help for you.
2 Solution Overview
In order to achieve the purpose of out-of-the-box use on the business side, taking into account the usage habits of C++, Python and Java users, we designed the following collaboration structure.
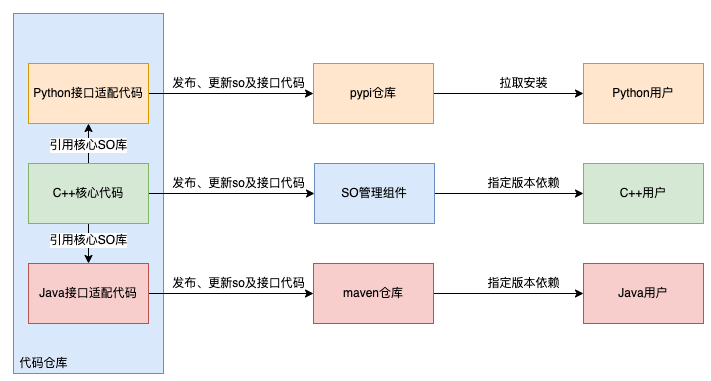
3 Implementation details
Python and Java support calling C interfaces, but not C++ interfaces, so for interfaces implemented in C++, they must be converted to C implementation. In order not to modify the original C++ code, the C++ interface is wrapped once in C. This part of the code is often called “Glue Code”.
The specific program is shown in the following figure.
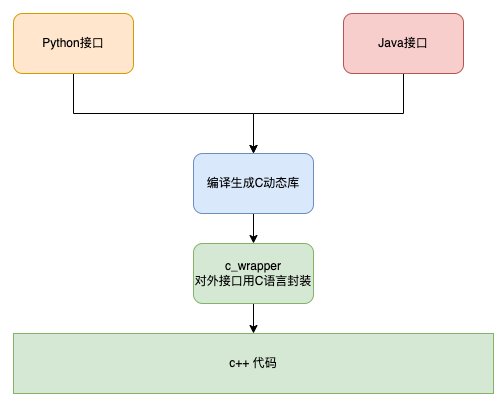
The sections of this chapter are as follows.
- Functional code section, which describes the coding work of each language section through the example of printing strings.
- Packaging and publishing section, which introduces how to package the generated dynamic libraries as resource files together with Python and Java code and publish them to the repository to reduce the access cost for the user.
- Business usage section, introducing out-of-the-box usage examples.
- Ease of Use Optimization section describes how to deal with Python version compatibility and dynamic library dependency issues, taking into account the problems encountered in actual use.
3.1 Function Code
3.1.1 C++ code
As an example, a function to print a string is implemented. To simulate a real industrial scenario, the following code is compiled to generate the dynamic library libstr_print_cpp.so, and the static library libstr_print_cpp.a respectively.
str_print.h
str_print.cpp
3.1.2 c_wrapper code
As mentioned above, the C++ library needs to be wrapped and transformed to provide an interface in C format to the outside world.
c_wrapper.cpp
3.1.3 Generating Dynamic Libraries
In order to support cross-language calls between Python and Java, we need to generate dynamic libraries for the encapsulated interfaces, and there are three ways to generate dynamic libraries.
-
Way 1 : Source dependency method, compile c_wrapper and C++ code together to generate
libstr_print.so. This way the business side only needs to depend on one so, which is less expensive to use, but requires access to the source code. For some dynamic libraries that are readily available, it may not work.1g++ -o libstr_print.so str_print.cpp c_wrapper.cpp -fPIC -shared -
Way 2: Dynamic linking, which generates
libstr_print.soand distributes it with its dependencylibstr_print_cpp.so. In this way, the business side needs to rely on both so’s, and the cost of using them is relatively high, but it is not necessary to provide the source code of the original dynamic library.1g++ -o libstr_print.so c_wrapper.cpp -fPIC -shared -L. -lstr_print_cpp -
Method 3 : Static linking method, this method generates
libstr_print.soand does not need to carry onlibstr_print_cpp.sowhen publishing. In this way, the business side only needs to depend on a so, not on the source code, but the static library needs to be provided.1g++ c_wrapper.cpp libstr_print_cpp.a -fPIC -shared -o libstr_print.so
Each of the above three approaches has its own application scenarios and advantages and disadvantages. In our current business scenario, since the tool and wrapper libraries are developed by ourselves and we have access to the source code, we choose the first approach, which is simpler for the business side to rely on.
3.1.4 Python Access Code
The Python standard library comes with ctypes that enables loading dynamic libraries for C. It is used as follows.
str_print.py
LoadLibrary returns an instance pointing to a dynamic library through which functions in that library can be called directly in Python. argtypes and restype are the argument properties of functions in a dynamic library, the former being a list or tuple of ctypes to specify the argument types of the function interface in the dynamic library, the latter being the return type of the function (the default is c_int, which can be left unspecified, and needs to be shown specified for non-c_int types). The mapping of parameter types involved in this section, and how to pass advanced types such as structs and pointers to functions, can be found in the documentation in the appendix.
3.1.5 Java Access Code
There are two ways to call C lib in Java, JNI and JNA. From the point of view of ease of use, the JNA way is more recommended.
3.1.5.1 JNI Access
Java has supported the JNI interface protocol since version 1.1 for implementing Java language calls to C/C++ dynamic libraries. c_wrapper module mentioned before is no longer applicable under the JNI approach, and the JNI protocol itself provides the interface definition of the adaptation layer, which needs to be implemented in accordance with this definition.
The specific access steps of the JNI approach are as follows.
In the Java code, add the native keyword to the method that needs to be called across languages to declare that it is a native method.
With the javah command, the native methods in the code are generated into the corresponding C header file. This header file is similar to the c_wrapper role mentioned earlier.
|
|
The resulting header file is as follows (some comments and macros have been simplified here to save space).
jni.h is provided in the JDK, which defines the relevant implementations necessary for Java and C calls.
JNIEXPORT and JNICALL are two macros defined in JNI. JNIEXPORT identifies the methods in this dynamic library that are supported to be called in external program code, and JNICALL defines the stack-in/stack-out convention for parameters during function calls.
Java_JniDemo_print is an automatically generated function name, which has a fixed format consisting of Java_{className}_{methodName}, and JNI will follow this convention to register the mapping of Java methods to C functions.
The first two of the three parameters are fixed. jNIEnv encapsulates some tool methods in jni.h. jobject points to the calling class in Java, i.e. JniDemo, through which a copy of the member variables of the class in Java can be found in the C stack. jstring points to the incoming parameter text, which is a mapping to the String type in Java. The details of the type mapping will be expanded later.
Write a method that implements Java_JniDemo_print.
JniDemo.cpp
Compile to generate dynamic libraries.
|
|
Compile and run.
|
|
The JNI mechanism implements a cross-language calling protocol through a layer of C/C++ bridging. This function has a lot of applications under some Java programs related to graphics computing in Android system. On the one hand, it can call a lot of OS underlying libraries through Java, which greatly reduces the workload of driver development on JDK, and on the other hand, it can make full use of hardware performance. However, the description in 3.1.5.1 can also see that the JNI implementation itself is still relatively expensive to implement. In particular, the writing of C/C++ code for the bridge layer is more expensive to develop when dealing with complex types of parameter passing. To optimize this process, Sun led the work on the JNA (Java Native Access) open source project.
3.1.5.2 JNA Access
JNA is a programming framework implemented on top of JNI, which provides a C dynamic transponder for automatic conversion of Java types to C types. Therefore, Java developers only need to describe the functions and structure of the target native library in a Java interface, and no longer need to write any Native/JNI code, which greatly reduces the development difficulty of Java calling native shared libraries.
JNA is used as follows.
Introduce the JNA library in the Java project .
Declare the Java interface class corresponding to the dynamic library.
Load the dynamic link library and implement the interface methods.
JnaDemo.java
|
|
Comparison can be found that, compared to JNI, JNA no longer need to specify the native keyword, no longer need to generate JNI part of the C code, and no longer need to show to do the parameter type conversion, greatly improving the efficiency of calling dynamic libraries.
3.2 Package release
In order to be ready to use out of the box, we package dynamic libraries together with the corresponding language code and prepare the corresponding dependency environment automatically. This way, the user only needs to install the corresponding library and introduce it into the project, and can start calling it directly. The reason is that the tool code we develop may be used by different business and non-C++ teams, and we cannot guarantee that all business teams use a uniform and standardized runtime environment. It is not possible to release and update so uniformly.
3.2.1 Python Package Distribution
Python can package tool libraries and publish them to the pypi public repository via setuptools. This is done as follows.
Create a directory.
Write __init.py__ to wrap the above code into a method.
|
|
Write setup.py.
Write MANIFEST.in.
|
|
Packaged for release.
|
|
3.2.2 Java interfaces
For the Java interface, package it as a JAR package and publish it to the Maven repository.
Write the wrapper interface code JnaDemo.java .
|
|
Create the resources directory and put the dependent dynamic libraries into it.
Package the dependent libraries together in a JAR package via the packaging plugin.
|
|
3.3 Operational Use
3.3.1 Python usage
Install the strprint package.
|
|
Usage examples.
3.3.2 Java Usage
pom introduces the JAR package.
Usage examples.
3.4 Ease of Use Optimization
3.4.1 Python version compatibility
Python2 and Python3 versions are a constant source of criticism for Python development users. Since the tools are for different business teams, there is no way to enforce the use of a unified Python version, but we can achieve compatibility between the two versions by doing some simple processing of the tool library.
There are two aspects of Python version compatibility that need attention.
- syntax compatibility
- Data encoding
Python code encapsulation basically does not involve syntax compatibility, and our work is focused on data encoding issues. Since Python 3’s str type uses unicode encoding, and in C, we need char* to be in utf8 encoding, we need to do utf8 encoding for the incoming string, and do utf8 decoding for the returned string in C. So for the above example, we did utf8 to unicode decoding. So for the above example, we did the following transformation.
|
|
3.4.2 Dependency Management
In many cases, we call dynamic libraries that depend on other dynamic libraries, for example, when the version of gcc/g++ we depend on does not match the one on the runtime environment, we often encounter the problem glibc_X.XX not found, which requires us to provide the specified versions of libstdc.so and libstdc++.so.6.
To achieve the goal of out-of-the-box use, we package these dependencies in the distribution package along with the toolkit when the dependencies are not too complex. For these indirect dependencies, there is no need to explicitly load them in the wrapper code, because in Python and Java implementations, the final call to load a dynamic library is the system function dlopen, which automatically loads its indirect dependencies when the target dynamic library is loaded. So all we need to do is to place these dependencies under the paths that dlopen can find.
The order in which dlopen looks for dependencies is as follows.
- look from the directory specified by DT_RPATH of dlopen caller ELF (Executable and Linkable Format), ELF is the file format of so, here DT_RPATH is written in the dynamic library file, we can’t modify this part by conventional means.
- Search from the directory specified by environment variable LD_LIBRARY_PATH. This is the most common way to specify the dynamic library path.
- search from the directory specified by DT_RUNPATH of ELF of dlopen caller, which is also the path specified in the so file.
- look from /etc/ld.so.cache, which requires modifying the target cache built from the /etc/ld.so.conf file, which is rarely modified in actual production because it requires root privileges.
- look from /lib, the system directory that usually holds the dynamic libraries that the system depends on.
- From /usr/lib, the dynamic libraries installed by root, which are also rarely used in production because they require root privileges.
As you can see from the above lookup sequence, the best way to manage dependencies is to specify the LD_LIBRARY_PATH variable to include the paths to the dynamic library resources in our toolkit. Alternatively, for Java programs, we can specify the location of dynamic libraries by specifying the java.library.path runtime parameter, which will be passed to dlopen as an absolute path along with the dynamic library filename, in the order in which it is loaded before the above.
Finally, there is one more detail to note in Java. The toolkit we publish is provided as a JAR package, which is essentially a compressed package. In the Java program, we are able to directly load the so located in the project resources directory through the Native.load() method, and these resource files are packaged and placed in the root directory of the JAR These resource files are packaged and placed in the root directory of the JAR package.
But dlopen cannot load this directory. For this problem, the best solution is to refer to the packaging method in section [2.1.3 Generating Dynamic Libraries] and combine the dependent dynamic libraries into one so, so that no environment configuration is needed and it works out of the box. However, for libraries such as libstdc++.so.6 that cannot be packaged in a single so, a more general approach is to copy the so files from the JAR package to a local directory during service initialization and specify LD_LIBRARY_PATH to contain the directory.
4. Introduction to the Principle
4.1 Why a c_wrapper is needed
As mentioned in the implementation plan section, Python/Java cannot call C++ interfaces directly, and must first encapsulate the interfaces provided by C++ in C. The fundamental reason here is that before using interfaces in dynamic libraries, you need to find the address of the interface in memory based on the function name. The fundamental reason here is that before using the interface in the dynamic library, you need to find the address of the interface in memory according to the function name, and the addressing of the function in the dynamic library is realized through the system function dlsym, which is addressed strictly according to the function name passed in.
In C, the function signature is the name of the code function, while in C++, because of the need to support function overloading, there may be multiple functions with the same name. To ensure that the signature is unique, C++ generates different signatures for functions with different implementations of the same name through the name mangling mechanism, and the generated signature will be a string like __Z4funcPN4printE, which cannot be recognized by dlsym (Note: executable programs or dynamic libraries under Linux are mostly organized in ELF format for binary data. All non-static functions (non-static) are uniquely identified by a “symbol”, which is used to distinguish between different functions during linking and execution, and is mapped to a specific instruction address during execution, the “symbol “(we usually call it a function signature).
To solve this problem, we need to specify that the function is compiled using the C signature by extern “C”. So when the dependent dynamic library is a C++ library, it needs to be bridged by a c_wrapper module. And when the dependent library is a dynamic library compiled in C, this module is not needed and can be called directly.
4.2 How cross-language calls implement parameter passing
The standard procedure for a C/C++ function call is as follows.
- allocate a stack frame in the stack space of memory for the called function to hold the formal reference, local variables and return address of the called function.
- Copy the value of the real reference to the corresponding formal reference variable (can be a pointer, reference, value copy).
- The control flow is transferred to the starting position of the called function and executed.
- The control flow returns to the function call point and gives the return value to the caller, while the stack frame is released.
As we can see from the above process, function calls involve memory requests, copy of real parameters to formal parameters, etc. Programs like Python/Java, which run on virtual machines, also follow the above process inside their virtual machines, but when it comes to calling dynamic library programs implemented in non-native languages, what is the calling process?
Since the calling process of Python/Java is basically the same, we will take the calling process of Java as an example to explain, and we will not go into the calling process of Python.
4.2.1 Memory Management
In the world of Java, memory is managed by the JVM, which consists of a stack, heap, and method area. Under Linux, for example, the JVM is nominally a virtual machine, but it is essentially a process running on the operating system, so the memory of this process will be divided as shown in the figure below. The JVM’s memory management is essentially a re-division of the process’s heap, which itself “virtualizes” the stack in the Java world. As shown in the figure on the right, the stack area of the native is the stack area of the JVM process, and part of the process heap is used for JVM management, while the rest can be allocated for native methods.
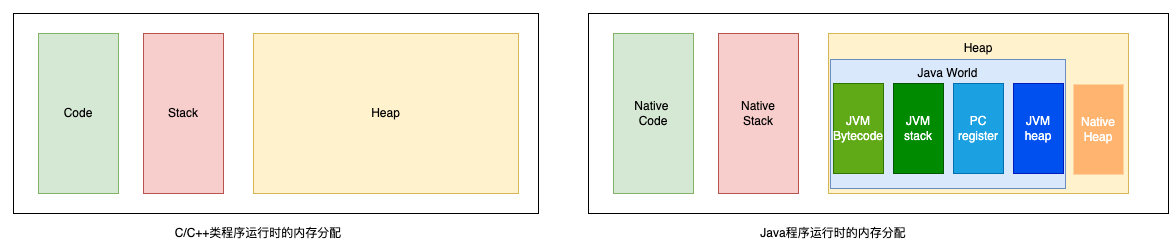
4.2.2 Calling process
As mentioned earlier, before a native method is called, the dynamic library it is in needs to be loaded into memory, a process that is implemented using Linux dlopen.
The JVM will put the code snippet from the dynamic library into the Native Code area and save a map of the native method name to the memory address of the Native Code in the JVM Bytecode area.
The steps of a native method call are divided into four steps.
- Get the address of the native method from the JVM Bytecode.
- prepare the required parameters for the method.
- switch to the native stack and execute the native method.
- After the native method comes out of the stack, switch back to the JVM method, and the JVM copies the result to the JVM stack or heap.
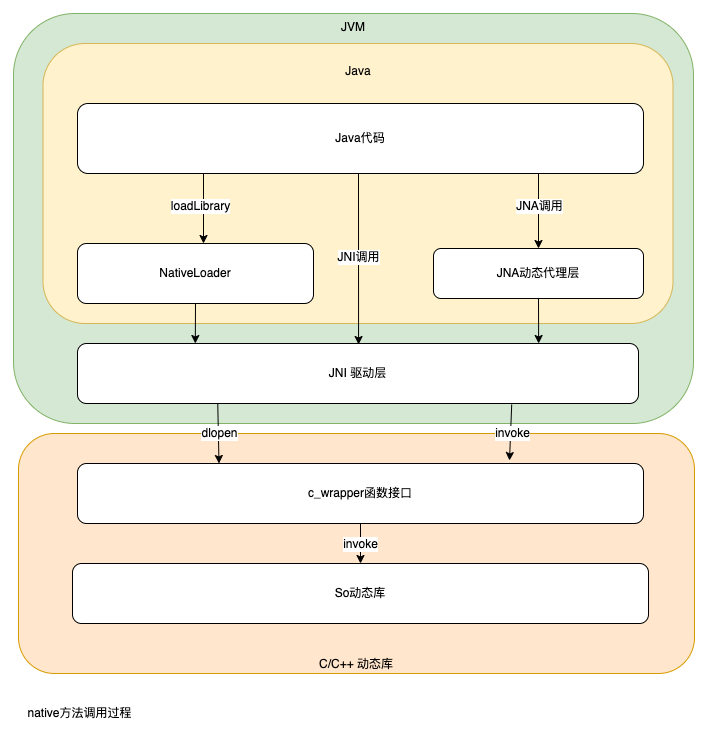
As you can see from the above steps, the native method calls also involve a copy of the parameters and the copy is built between the JVM stack and the native stack.
For native data types, the arguments are copied onto the stack with the native method address by means of a value copy. For complex data types, on the other hand, a set of protocols is needed to map objects in Java to data bytes that are recognized in C/C++. The reason is that the memory arrangement in JVM and C are different enough that direct memory copy is not possible, and these differences mainly include.
- The type length is different, for example char is 16 bits in Java, but 8 bits in C.
- The byte order (Big Endian or Little Endian) of the JVM and the operating system may not match.
- JVM objects will contain some meta information, while struct in C is just a side-by-side arrangement of base types. Similarly there is no pointer in Java, which also needs to be encapsulated and mapped.
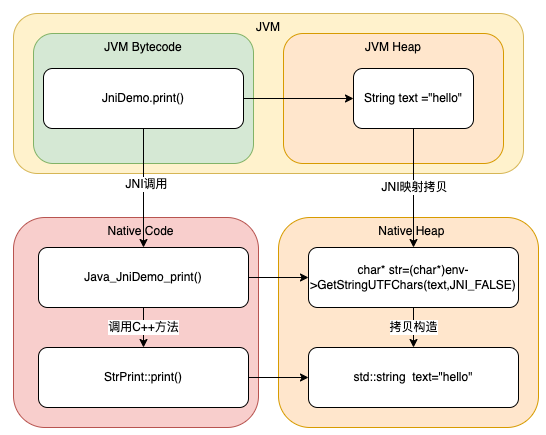
The above diagram shows the process of parameter passing during native method calls, where the mapping copy is implemented in JNI by the glue code in the C/C++ linking section, and the type mapping is defined in jni.h.
Mapping of Java basic types to C basic types (via value passing.) Copying the value of a Java object in JVM memory to the location of the form reference in the stack frame).
Mapping of Java complex types to C complex types (via pointer passing. The address of the assembled new object is first copied to the location of the form reference in the stack frame according to the basic type mapping one by one).
Note : In Java, non-native types are all derived classes of Object, and the array of multiple objects is itself an object, and the type of each object is a class, while the class itself is also an object.
For example, GetStringUTFChars in the previous example can copy the text content of the string in the JVM to the native heap in utf8 encoding format and pass the char* pointer to the native method for use.
The entire call process, the resulting memory copy, the object in Java is cleaned up by the JVM’s GC, the object in the native heap if it is generated by the JNI framework allocation, such as the parameters in the JNI example above, are unified by the framework for release. The newly allocated objects in C/C++ need to be released manually by user code in C/C++. In short, Native Heap is consistent with ordinary C/C++ processes, without the existence of a GC mechanism, and follows the memory governance principle of who allocates and who releases.
4.3 Extended Reading (JNA Direct Mapping)
Compared to JNI, JNA uses its function call base framework, where the memory mapping part is automated by tool classes in the JNA tool library to do most of the type mapping and memory copy work, thus avoiding a lot of glue code writing and being more user-friendly, but accordingly this part of the work incurs some performance loss.
JNA additionally provides a “DirectMapping” invocation to make up for this shortcoming. However, direct mapping has strict restrictions on parameters, only native types, corresponding arrays and Native reference types can be passed, and does not support indefinite parameters, the method return type can only be native types.
The Java code for direct mapping needs to add the native keyword, which is consistent with the way JNI is written.
Example of DirectMapping.
DoubleByReference is the implementation of the Native reference type for double-precision floating-point numbers, and its JNA source code is defined as follows (only the relevant code is intercepted)
|
|
The Memory type is Java’s version of shared_ptr implementation, which encapsulates the details related to memory allocation, referencing, and freeing by means of reference citations. This type of data memory is actually allocated in the native heap, and Java code can only get a reference to that memory. jna allocates new memory in the heap by calling malloc when constructing a Memory object, and records a pointer to that memory.
When the ByReference object is freed, free is called, and the finalize method of the ByReference base class in JNA’s source code is called at GC time, when the corresponding requested memory is freed. Therefore, in the JNA implementation, the memory allocated in the dynamic library is managed by the code of the dynamic library, and the memory allocated by the JNA framework is shown to be freed by the code in JNA, but the timing of its triggering is triggered by the GC mechanism in the JVM when the JNA object is freed to run. This is consistent with the aforementioned principle that there is no GC mechanism in Native Heap and follows the principle of who allocates and who releases.
|
|
4.4 Performance Analysis
Improving computing efficiency is an important purpose of Native calls, but after the above analysis, it is easy to see that there is still a lot of cross-language work to be done during a cross-language localization call, and these processes also require spending the corresponding computing power. Therefore, not all Native calls are computationally efficient. For this reason, we need to understand the performance differences between languages and the amount of computing power required for cross-language calls.
The performance differences between languages are in three main areas.
- Python and Java languages are both interpreted execution class languages, which need to translate scripts or bytecodes into binary machine instructions before handing them over to the CPU for execution during runtime. C/C++ compiled execution class languages, on the other hand, are compiled directly into machine instructions for execution. Despite runtime optimization mechanisms such as JIT, this gap can only be closed to a certain extent.
- The upper-layer languages have more operations that are themselves implemented by the operating system floor through cross-language calls, and this part is obviously less efficient than direct calls.
- The memory management mechanisms of Python and Java languages introduce garbage collection mechanisms for simplifying memory management, and GC work takes up a certain amount of system overhead at runtime. This part of the efficiency difference usually appears in the form of runtime burrs, i.e., it does not have a significant impact on the average runtime, but has a large impact on the runtime efficiency of individual moments.
The overhead of cross-language calls, on the other hand, consists of three main parts.
- For cross-language calls like JNA implemented by dynamic proxy, there is work of stack switching, proxy routing, etc. during the call.
- Addressing and constructing the local method stack, i.e., corresponding native methods in Java to function addresses in dynamic libraries, and constructing the call site work.
- Memory mapping, especially when there is a lot of data copied from JVM Heap to Native Heap, this part of the overhead is the main time consuming part of cross-language calls.
We have done a simple performance comparison with the following experiments. We have performed 1 million to 10 million cosine calculations using C, Java, JNI, JNA and JNA direct mapping in five ways to get the time consumption comparison. In the 6-core 16G machine, we get the following results.
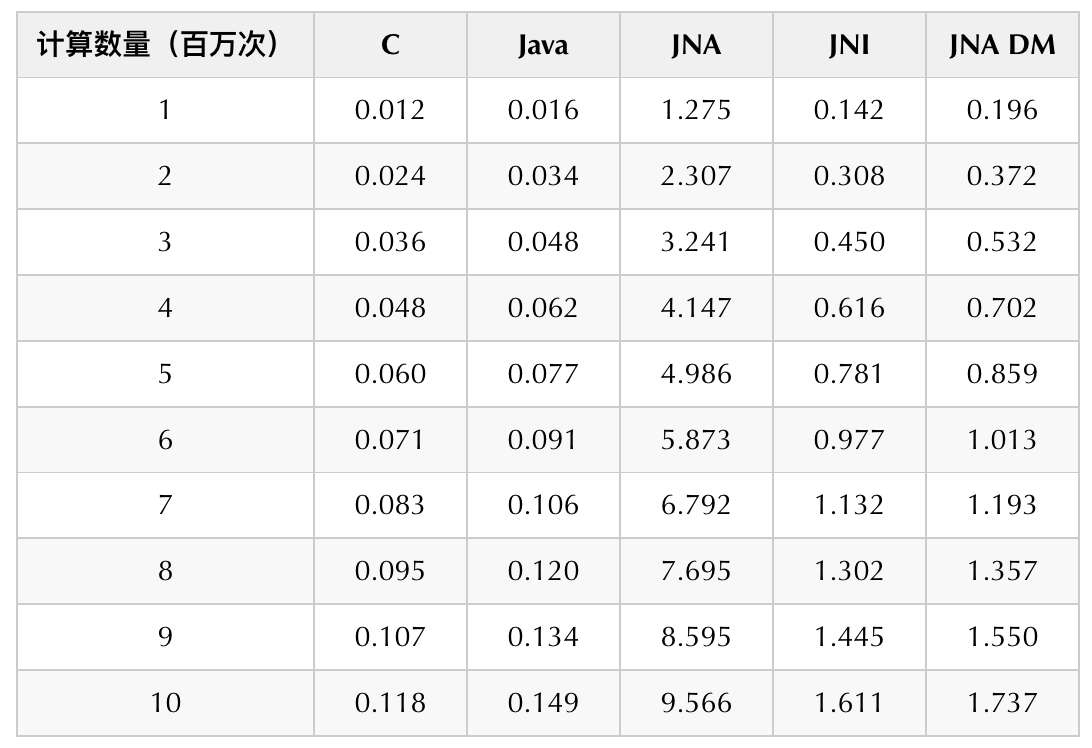
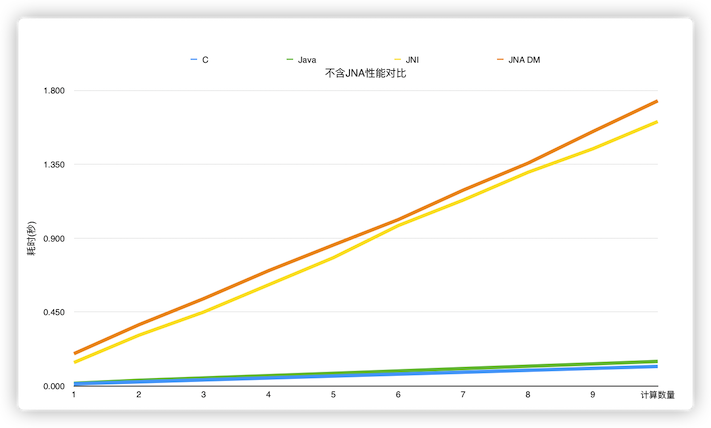
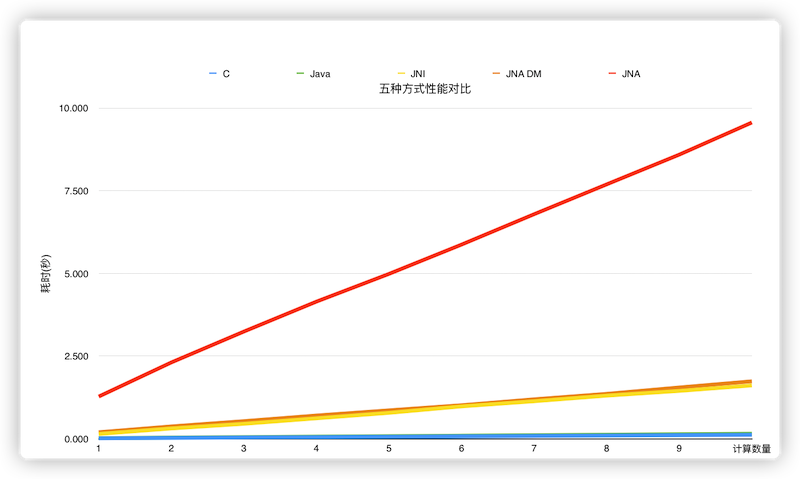
From the experimental data, we can see that the running efficiency is C > Java > JNI > JNA DirectMapping > JNA in order. C is more efficient than Java, but the two are very close. JNI and JNA DirectMapping have basically the same performance, but will be much slower than the native language implementation. JNA in normal mode is the slowest, and will be 5 to 6 times slower than JNI.
In summary, localized calls across languages do not always improve computational performance and require a comprehensive trade-off between the complexity of the computational task and the time consuming cross-language calls. The scenarios we have concluded so far that are suitable for cross-language calls are.
- Offline Data Analysis : Offline tasks may involve multiple language development and are not sensitive to time consumption. The core point is that the results are equal under multiple languages and cross-language calls can save the development cost of multi-language versions.
- Cross-language RPC calls converted to cross-language localization calls : For computational requests where computational time consumption is of microsecond and smaller magnitude, the time used for network transfer is at least milliseconds, much larger than the computational overhead, if the results are obtained via RPC calls. In the case of simple dependencies, converting to localized calls will significantly reduce the processing time of a single request.
- For some complex model calculations, Python/Java cross-language calls to C++ can improve computational efficiency.
5 Use Cases
As mentioned above, the solution through localized invocation can bring some benefits in terms of performance and development cost. We have made some attempts to combine these techniques in offline task computing with real-time service invocation, and have achieved relatively satisfactory results.
5.1 Applications in offline tasks
There will be a lot of offline computing tasks such as word list mining, data processing, index building, etc. in the search business. This process will use more text processing and recognition capabilities in query understanding, such as word separation and name body recognition. Because of the difference in development languages, it is cost unacceptable to redevelop these capabilities locally. Therefore, in the previous task, online services were called via RPC during offline computing. This solution poses the following problems.
- The volume of offline computing tasks is usually larger, and the requests are more intensive during execution, which will take up occupied online resources, affect online user requests, and have lower security.
- The time consumed for a single RPC is at least milliseconds, while the actual computation time is often very short, so most of the time is actually wasted on network communication, which seriously affects the task execution efficiency.
- RPC services cannot reach 100% success rate of invocation because of network jitter and other reasons, which affects the task execution effect.
- Offline tasks need to introduce RPC call-related code, and in lightweight computing tasks such as Python scripts, this part of the code often leads to higher access costs due to the imperfection of some basic components.
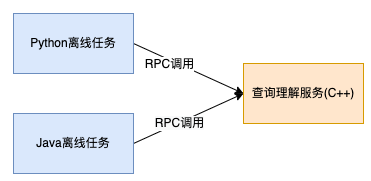
After transforming RPC calls into cross-language localized calls, the above problems are solved and the benefits are obvious.
- No more calls to online services, traffic isolation, and no impact on online security.
- Cumulative savings of at least 10+ hours of network overhead time for offline tasks with 10 million or more entries.
- Eliminate the problem of request failures due to network jitter.
- The work in the above sections provides out-of-the-box localization tools that greatly simplify the cost of use.
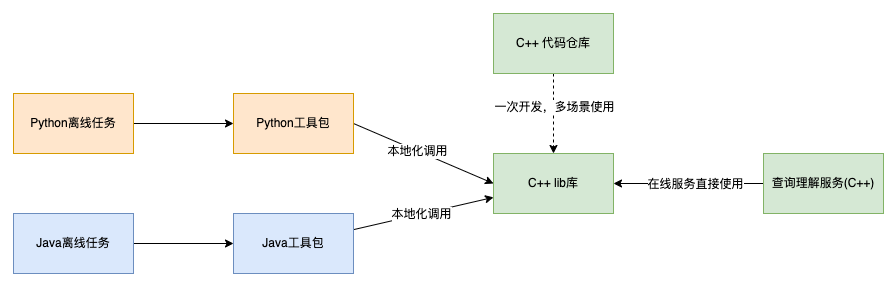
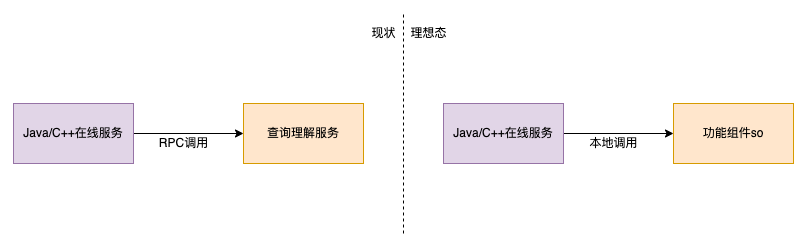
5.2 Applications in online services
Query comprehension, as the company’s internal basic service platform, provides text analysis such as lexical separation, query error correction, query rewriting, landmark recognition, foreign place recognition, intent recognition, entity recognition, entity linking, etc. It is a larger CPU-intensive service that undertakes very many business scenarios of this paper analysis within the company, some of which only require individual signals, or even only the basic query comprehension service in function components, for most of the business services developed through Java, it is not possible to directly refer to the C++ dynamic library of query understanding, which was previously generally used to obtain results through RPC calls. Through the above work, RPC calls can be transformed into cross-language localized calls in non-C++ language caller services, which can significantly improve the performance as well as the success rate of the caller side, and also effectively reduce the resource overhead of the server side.
6 Summary
The development of technologies such as microservices makes it easier and easier to create, publish and access services, but in real industrial production, not all scenarios are suitable for computing through RPC services. Especially in computation-intensive and time-sensitive business scenarios, the network overhead caused by remote invocation becomes an unbearable pain for business when performance becomes a bottleneck. In this paper, we summarize the techniques of language localization calls and give some practical experiences, hoping to provide some help to solve similar problems.
Of course, there are still many shortcomings in this work, for example, because of the requirements of the actual production environment, our work is basically focused on the Linux system, if it is in the form of an open library, so that the user can freely use it, it may also need to consider the compatibility of DLL under Windows, dylib under Mac OS, and so on. There may be other shortcomings in this article, welcome to leave comments to correct and discuss.
The source code of this article can be found at GitHub.
Reference https://tech.meituan.com/2022/04/21/cross-language-call.html