This technique is used for IO operations, which consume a lot of CPU performance. Why IO operations can easily become a performance bottleneck? Every IO operation involves a conversion between the kernel space and user space of the operating system, and the real IO operations are actually performed in the kernel space of the operating system. Whether it is file IO, or network IO, in the end it can be unified as an exchange of user-space and kernel-space data. Memory and CPU are very scarce resources in a computer, and they should be used as efficiently as possible. IO operations often require interaction with the disk, so IO operations are several orders of magnitude slower than CPUs. By taking advantage of the speed difference between the two, it is possible to implement different kinds of IO methods, which are commonly known as IO models.
Common IO Models
Common IO models are also synchronous and asynchronous
Synchronous IO model
- Blocking BIO
- Non-blocking NIO
- IO multiplexing: poll, epoll, select
- Signal-driven IO
Asynchronous IO model
- Linux AIO
To clarify, although some IO models claim to be non-blocking, they are non-blocking while waiting for data to be ready, but they are still blocking when receiving data. AIO is one of these IO models that is truly non-blocking. AIO returns directly after being called, and even the data reception phase is non-blocking, and the kernel will return a notification only when the data reception is complete. In other words, when the user process receives the notification, the data has already been received. There are implementations of AIO in Linux, but not many of them are actually used, and most of them use standalone asynchronous IO libraries such as libevent, libev, libuv.
What is the general file operation?
Scenario: copying a file to another file.
|
|
We can write the above code normally, but what actions does this code perform on the OS? It is impossible to find out the optimization points without knowing the principle, so we need to explore the mechanism of copy implementation.
Copy implementation mechanism analysis
First, you need to understand User Space and Kernel Space, which are basic concepts at the operating system level. The operating system kernel, hardware drivers, etc. run in kernel space, which has relatively high privileges, while user space is for ordinary applications and services.
When we use input and output streams for reading and writing, we are actually making multiple context switches. For example, when an application reads data, it first reads the data from disk to the kernel cache in the kernel state, and then switches to the user state to read the data from the kernel cache to the user cache.
The write operation is similar, only the steps are reversed, as you can see in this diagram below.
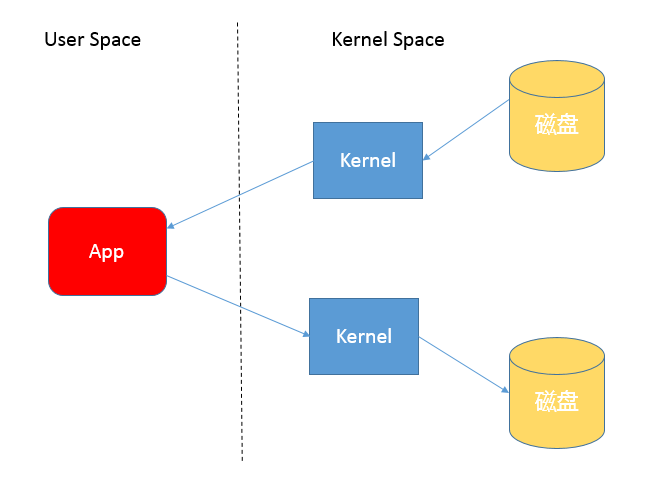
Process.
- The data to be copied is copied into kernel space, resulting in a user-space to kernel-space context switch
- The data is read and returned, resulting in a context switch from kernel space to user space (these two steps complete the read operation)
- To write the read data to the IO device, perform a write operation to switch the user space to the kernel space context and write the data to the kernel space
- Write the kernel data to the target IO device, and then return the result of the write operation from the kernel space to the user space context (these two steps complete the write operation)
There are 4 data copies and 4 user-kernel context switches in this process (each system call is two context switches: user->kernel->user).
Therefore, this approach introduces some additional overhead and may reduce IO efficiency.
The NIO transferTo-based implementation, on Linux and Unix, uses a zero-copy technique where the user state is not involved in the data transfer, eliminating the overhead of context switching and unnecessary memory copies, which in turn may improve application copy performance. Note that transferTo can be used not only for file copying, but also for similar purposes, such as reading a disk file and then sending it over the socket, to enjoy the performance and scalability gains of this mechanism.
The transferTo transfer process is.
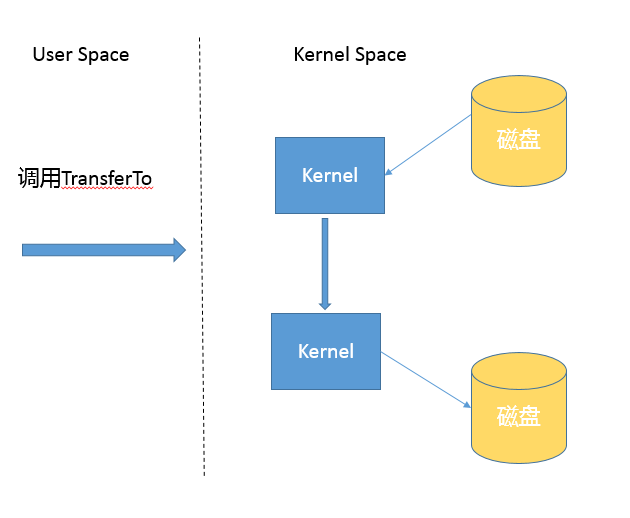
Upon closer inspection of the previous flow, the second and third copies are actually unnecessary (that is, returning data in kernel space to user space and writing user space data to kernel space)
The flow changes to
- Switching from user to kernel state The
transferTo()call causes the file contents to be copied into kernel space by way ofDMA. TheDMAengine copies data directly from kernel space to the targetIO device. - After the task is complete, it switches back.
This can be interpreted as a data transfer between kernel state space and disk without going through user state space again, requiring only 2 switches and 2 copies.