Netfilter (in conjunction with iptables) enables user-space applications to register the processing rules applied by the kernel network stack when processing packets, enabling efficient network forwarding and filtering. Many common host firewall applications as well as Kubernetes service forwarding are implemented with iptables.
Most of the introductory articles on netfilter describe only abstract concepts, but the basic implementation of the kernel code is not too complicated. This article mainly refers to the Linux kernel code version 2.6 (earlier versions are simpler), which may differ significantly from the latest version 5.x, but the basic design has not changed much and does not affect the understanding of its principles.
This article assumes that the reader already has a basic understanding of the TCP/IP protocol.
Netfilter Design and Implementation
The definition of netfilter is a network packet processing framework that works in the Linux kernel. In order to thoroughly understand how netfilter works, we first need to establish a basic understanding of the packet processing path in the Linux kernel.
Kernel packet processing flow
The packet processing path in the kernel, i.e. the chain of kernel code calls for processing network packets, can be broadly divided into multiple layers according to the TCP/IP model, taking the reception of an IPv4 tcp packet as an example.
-
At the physical-network device layer, the NIC writes the received packet to a
ring bufferin memory via DMA. After a series of interrupts and scheduling, the OS kernel calls__skb_dequeueto add the packet to the processing queue of the corresponding device and converts it into ask_buffertype (i.e., socket buffer - the__skb_dequeue). The packets can be considered assk_buffer), and finally thenetif_receive_skbfunction is called to sort the packets by protocol type and jump to the corresponding processing function. This is shown in the following figure.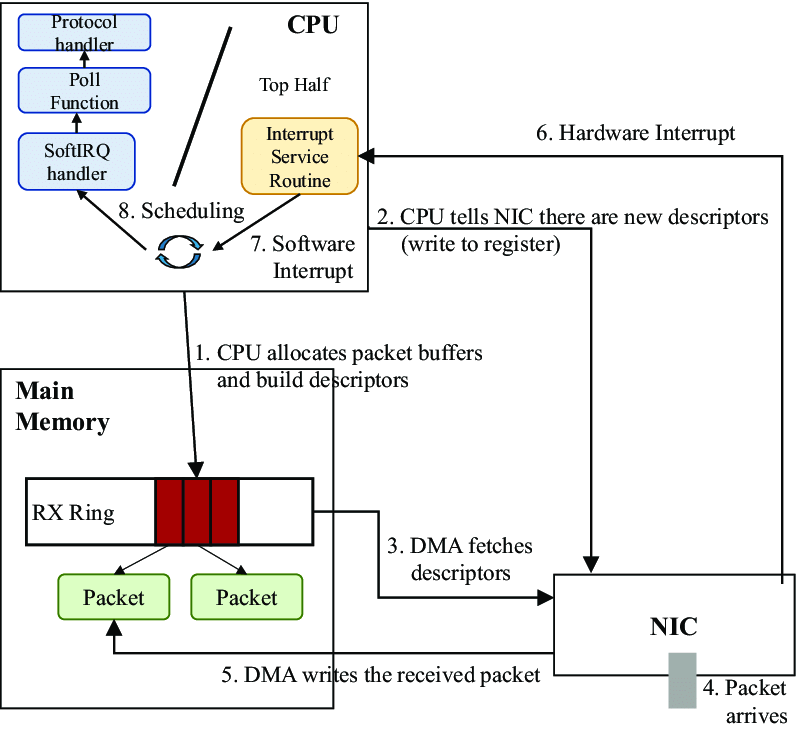
-
Assuming the packet is an IP protocol packet, the corresponding receive packet processing function
ip_rcvis called and the packet processing enters the network (IP) layer.ip_rcvchecks the IP initials of the packet and discards the erroneous packets, and aggregates the sliced IP packets if necessary. Theip_rcv_finishfunction is then executed to route the packet and decide whether to deliver the packet locally or forward it to another host. Assuming the destination of the packet is this host, the nextdst_inputfunction will call theip_local_deliverfunction. Theip_local_deliverfunction will determine the protocol type of the packet based on the protocol number in the IP header, and finally call the packet processing function of the corresponding type. In this example, thetcp_v4_rcvfunction for TCP protocol will be called, and then the packet processing will enter the transport layer. -
The
tcp_v4_rcvfunction also reads the TCP header of the packet and calculates the checksum, and then maintains some necessary state in the TCP control buffer corresponding to the packet, including the TCP sequence number and SACK number. The function next calls__tcp_v4_lookupto look up the socket corresponding to the packet, and if it does not find it or if the socket’s connection status is TCP_TIME_WAIT, the packet is discarded. If the socket is unlocked, the packet will enter theprequeuequeue by calling thetcp_prequeuefunction, after which the packet will be available for processing by the user program in the user state. The processing flow at the transport layer is beyond the scope of this article and is actually much more complex.
netfilter hooks
Let’s get down to business. The primary component of netfilter is netfilter hooks.
hook trigger points
For different protocols (IPv4, IPv6 or ARP, etc.), the Linux kernel network stack triggers the corresponding hooks at predefined locations along the packet processing path of the protocol stack. The locations of the trigger points in the different protocol processing flows and the corresponding hook names (in bold outside the blue rectangle) are listed below, with a focus on the IPv4 protocol.
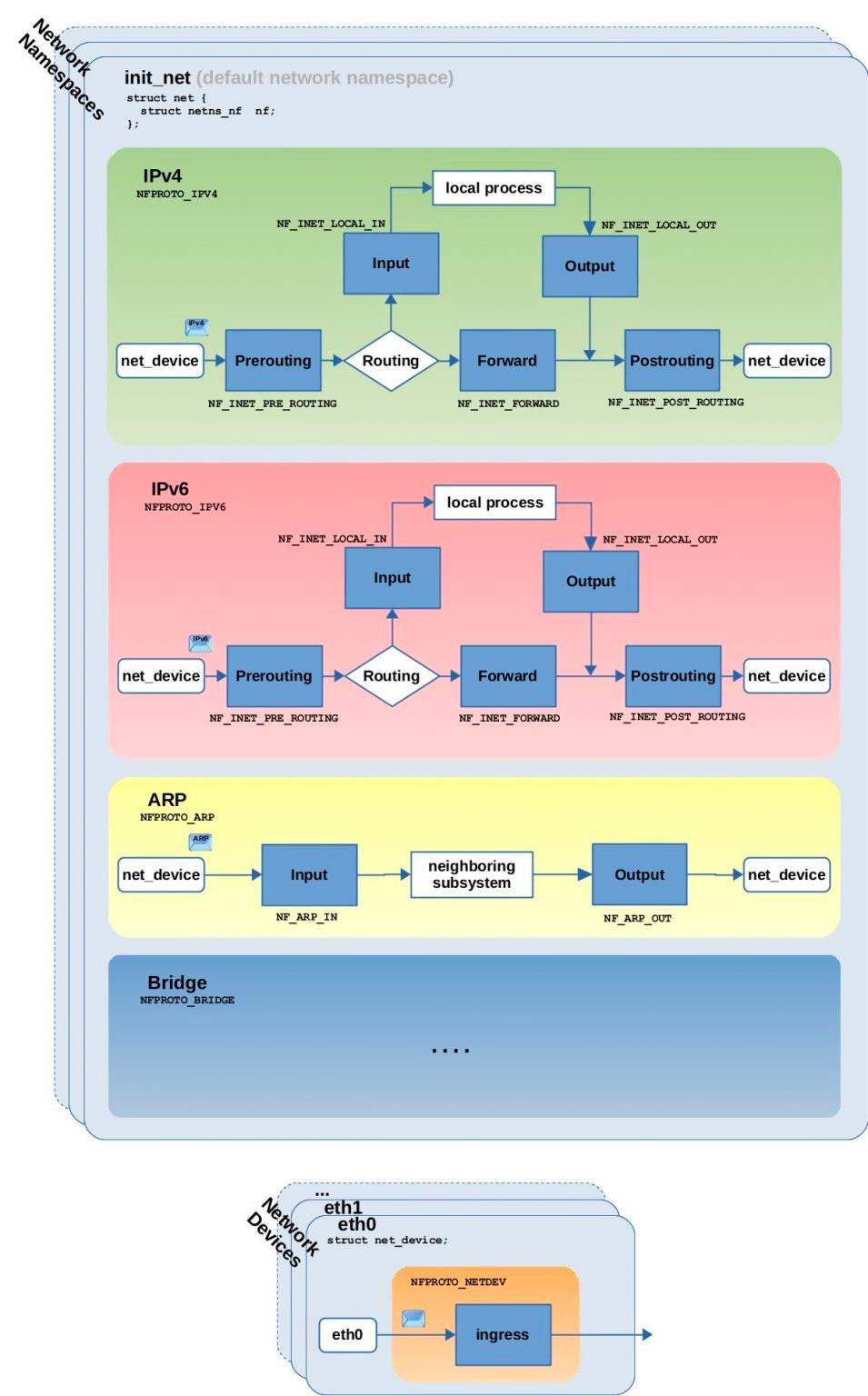
The so-called hooks are essentially enumerated objects in the code (integers with values incrementing from 0).
Each hook corresponds to a specific trigger point location in the kernel network stack, for example, the IPv4 stack has the following netfilter hooks definition.
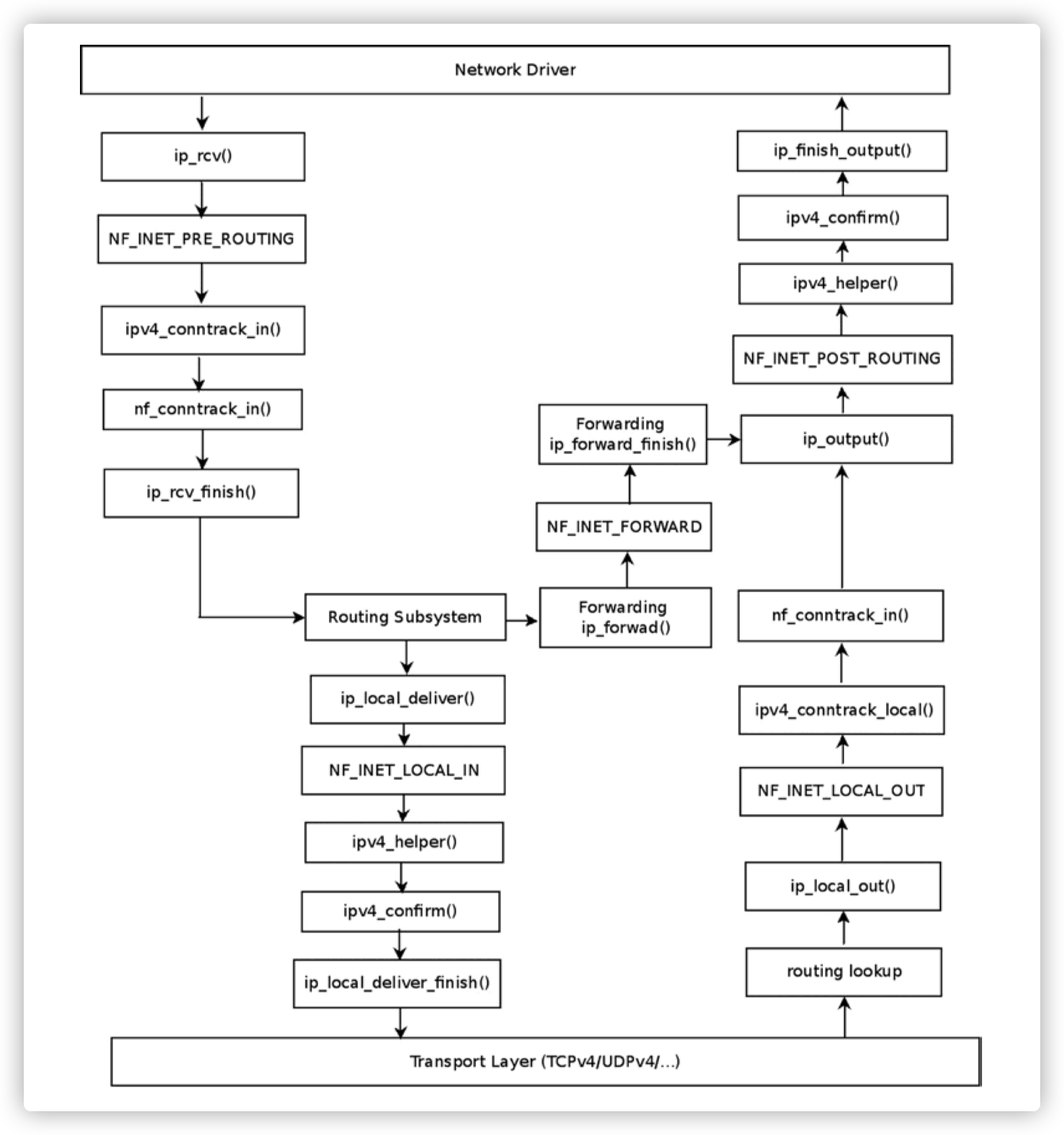
- NF_INET_PRE_ROUTING: This hook is executed in the
ip_rcvfunction of the IPv4 stack or theipv6_rcvfunction of the IPv6 stack. The first hook trigger point for all incoming packets (in fact, newer versions of Linux add the INGRESS hook as the earliest trigger point) is executed before the routing determination is made. - NF_INET_LOCAL_IN: This hook is executed in the
ip_local_deliver()function of the IPv4 stack or theip6_input()function of the IPv6 stack. After routing judgment, all incoming packets whose destination address is local arrive at this hook trigger point. - NF_INET_FORWARD: This hook is executed in the
ip_forward()function of the IPv4 protocol stack or theip6_forward()function of the IPv6 protocol stack. After routing, all incoming packets whose destination address is not local arrive at this hook trigger point. - NF_INET_LOCAL_OUT: This hook is executed in the
__ip_local_out()function of the IPv4 stack or the__ip6_local_out()function of the IPv6 stack. All locally generated packets ready to be sent first reach this hook trigger point after entering the network stack. - NF_INET_POST_ROUTING: This hook is executed in the
ip_output()function of the IPv4 protocol stack or theip6_finish_output2()function of the IPv6 protocol stack. Locally generated packets that are ready to be sent or forwarded will reach this hook trigger point after routing determination.
NF_HOOK macro and netfilter vector
The macro NF_HOOK is called uniformly for all trigger point locations to trigger the hook.
The parameters received by NF-HOOK are as follows.
- pf: The protocol family of the packet,
NFPROTO_IPV4for IPv4. - hook: The netfilter hook enumeration object shown in the above figure, such as NF_INET_PRE_ROUTING or NF_INET_LOCAL_OUT.
- skb: SKB object indicating the packet being processed.
- in: The input network device for the packet.
- out: The output network device for the packet.
- okfn: A pointer to a function that will be called when this hook is about to terminate, usually passed to the next processing function on the packet processing path.
The return value of NF-HOOK is one of the following netfilter vectors with a specific meaning.
- NF_ACCEPT: Continue normally on the processing path (actually the last incoming
okfnis executed inNF-HOOK). - NF_DROP: Discard the packet and terminate processing.
- NF_STOLEN: Packet forwarded, terminate processing. 4.
- NF_QUEUE: Queue the packet for other processing.
- NF_REPEAT: Re-call the current hook.
Going back to the source code, the IPv4 kernel network stack calls NF_HOOK() in the following code module.
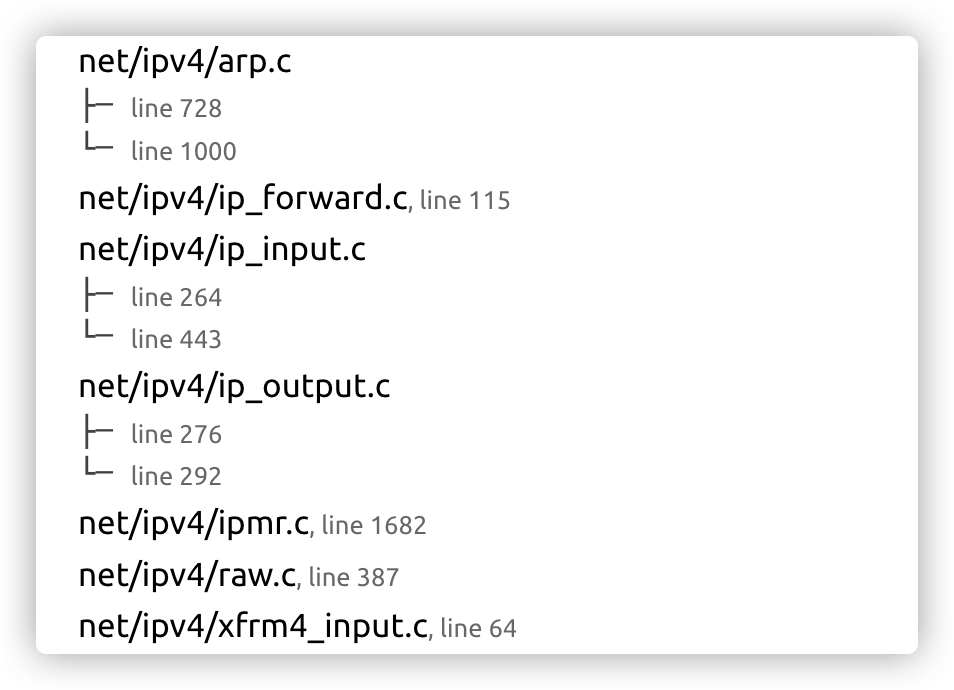
The actual call is based on the source code of net/ipv4/ip_forward.c for packet forwarding, where the NF_HOOK macro is called at the end of the ip_forward function on line 115 with the NF_INET_FORWARD hook as an input. The next function in the network stack, ip_forward_finish, is passed in as an okfn argument.
|
|
Callback functions and priorities
Another component of netfilter is the hook callback function. The kernel network stack uses both hooks to represent specific trigger locations and hooks (of integer values) as data indexes to access callback functions corresponding to trigger points.
Other modules of the kernel can register callback functions with the specified hook through the api provided by netfilter. The same hook can register multiple callback functions, and the priority parameter specified during registration can specify the priority of the callback function when it is executed.
To register a callback function for a hook, first define a nf_hook_ops structure (or an array of such structures), which is defined as follows.
There are 3 important members in the definition.
- hook: the callback function to be registered, the function parameters are defined similar to
NF_HOOKand can be nested with other functions via theokfnparameter. - hooknum: The enumeration value of the target hook to be registered.
- priority: the priority of the callback function, the smaller value is executed first.
After defining the structure, one or more callback functions can be registered by int nf_register_hook(struct nf_hook_ops *reg) or int nf_register_hooks(struct nf_hook_ops *reg, unsigned int n); respectively. All the nf_hook_ops under the same netfilter hook are registered to form a Linked list structure in order of priority, and the registration process will find the appropriate position from the Linked list according to the priority, and then perform the Linked list insertion operation.
When the NF-HOOK macro is executed to trigger the specified hook, the nf_iterate function will be called to iterate over the nf_hook_ops Linked list corresponding to this hook, and each nf_hook_ops will be called in turn with the registered function member hookfn. The diagram is as follows.
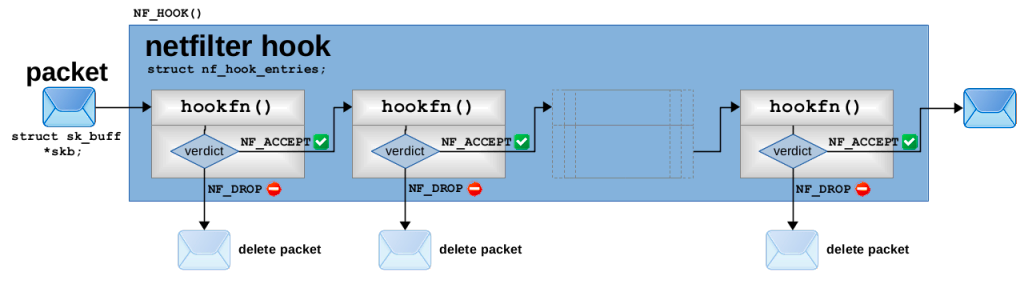
This chaining of callback functions works in a way that has also led to the netfilter hook being called Chain, a connection that is particularly reflected in the iptables introduction below.
Each callback function must also return a netfilter vector; if the vector is NF_ACCEPT, nf_iterate will continue to call the next nf_hook_ops callback function until all callbacks are called and NF_ACCEPT is returned; if the vector is NF_DROP, it will break the traversal and return directly to NF_DROP; if the vector is NF_REPEAT, the callback function will be re-executed. The return value of nf_iterate will also be used as the return value of NF-HOOK, and the network stack will determine whether to continue to execute the processing function based on the value of this vector. The schematic diagram is as follows.
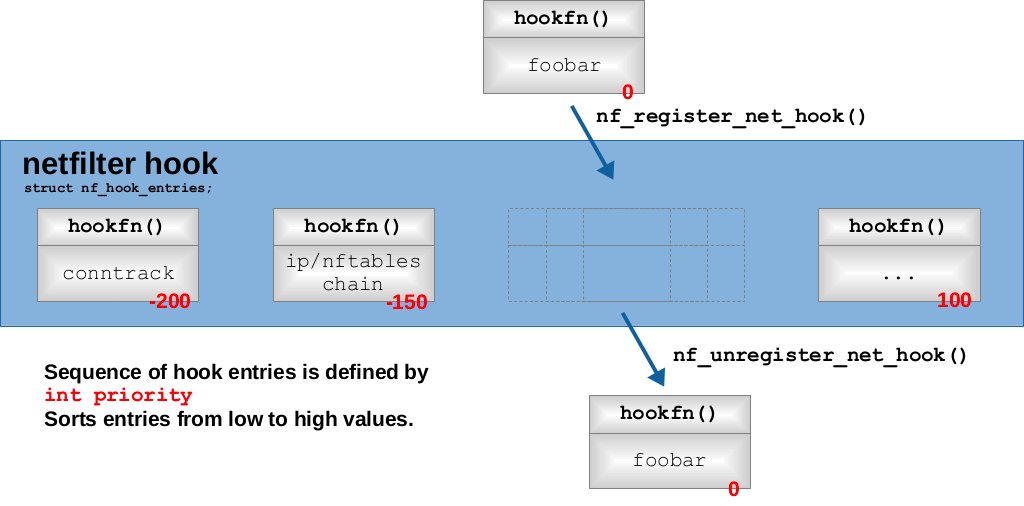
The callback function mechanism of netfilter hook has the following features.
- Callback functions are executed in order of priority, and only the previous callback function returns NF_ACCEPT before continuing to the next callback function.
- Any callback function can interrupt the execution chain of the hook’s callback functions and require the entire network stack to suspend packet processing.
iptables
Based on the hook callback function mechanism provided by the kernel netfilter, netfilter author Rusty Russell also developed iptables to manage custom rules applied to packets in user space.
iptbles is divided into two parts.
- The user-space iptables command provides the user with an administrative interface to access the kernel iptables module.
- The kernel-space iptables module maintains the rules table in memory, enabling table creation and registration.
Kernel space module
Initialization of xt_table
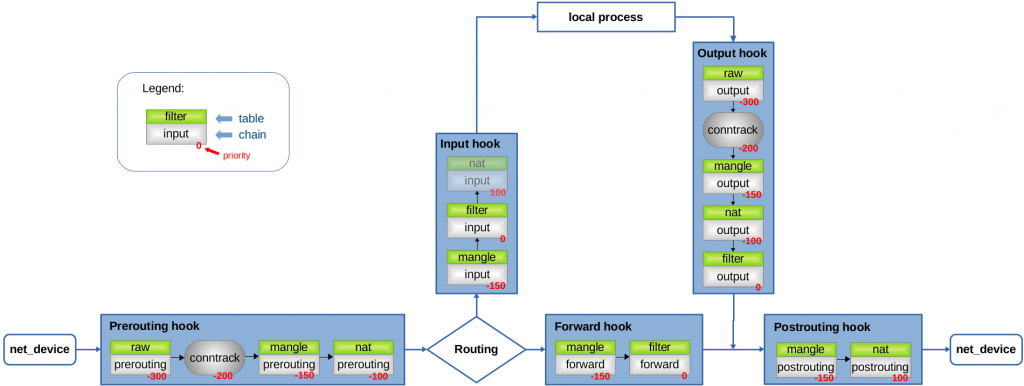
In the kernel network stack, iptables manages a large number of packet processing rules in an orderly manner through the xt_table structure. A xt_table corresponds to a rule table, which corresponds to the user space concept of table.
- Works for different netfilter hooks.
- Different priorities for checking different rule tables in the same hook.
Based on the final purpose of the rules, iptables initializes four different rule tables by default, namely raw, filter, nat, and mangle. the following example describes the initialization and invocation process of xt_table for filter.
The definition of filter table is as follows.
|
|
The initialization function iptable_filter.c of the iptable_ filter_init, call xt_hook_link on the xt_table structure packet_filter to perform the the following initialization procedure.
- Iterate through the
.valid_hooksattribute for each hook thatxt_tablewill take effect for, for the filter, the 3 hooks NF_INET_LOCAL_IN, NF_INET_FORWARD and NF_INET_LOCAL_OUT. - For each hook, register a callback function to the hook using the priority property of
xt_table.
The priority values for different tables are as follows.
When a packet reaches a hook trigger point, all callback functions registered on that hook by different tables are executed sequentially, always in a fixed relative order according to the priority value above.
ipt_do_table()
The filter registered hook callback function iptable_filter_hook will execute the public rule checking function ipt_do_table on the xt_table structure. ipt_do_table receives skb, hook and xt_table as arguments, and executes the rule set determined by the latter two arguments against skb, returning the netfilter vector as the return value of the callback function.
Before diving into the rule execution process, it is important to understand how the ruleset is represented in memory. Each rule consists of 3 parts.
- an
ipt_entrystructure. A.next_offsetpointing to the memory offset address of the nextipt_entry. - 0 or more
ipt_entry_matchstructures, each of which can dynamically add additional data. - 1
ipt_entry_targetstructure, each of which can be dynamically populated with additional data.
The ipt_entry structure is defined as follows.
|
|
ipt_do_table first jumps to the corresponding ruleset memory area based on the hook type and the xt_table.private.entries property, and performs the following procedure.
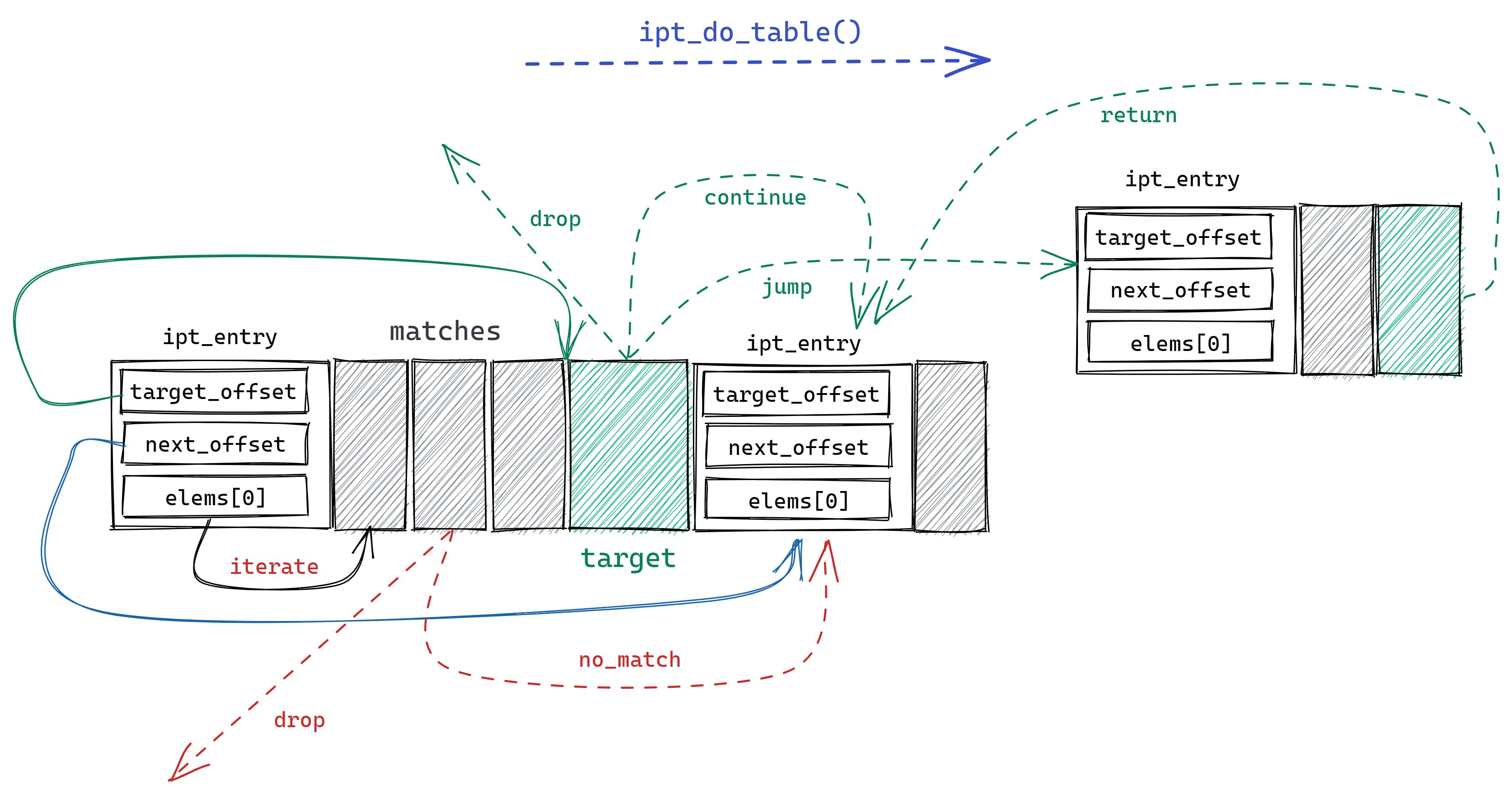
- first check whether the IP initial of the packet matches the
.ipt_ipattribute of the first ruleipt_entry, if it does not match according to thenext_offsetattribute jump to the next rule. - If the IP initial matches, all
ipt_entry_matchobjects defined by the rule are checked in turn, and the match function associated with the object is called, with the result of returning to the callback function (and whether to drop the packet), jumping to the next rule, or continuing the check, depending on the return value of the call. ipt_entry_targetis read after all checks are passed, and according to its properties returns the netfilter vector to the callback function, continues to the next rule or jumps to another rule at the specified memory address. non-standardipt_entry_targetwill also call the bound function, but can only return the vector value and cannot jump to another rule.
Flexibility and update latency
The above data structure and execution provides iptables with the power to scale, allowing us to flexibly customize the matching criteria for each rule and perform different behaviors based on the results, and even stack-hop between additional rulesets.
Because each rule is of varying length, has a complex internal structure, and the same ruleset is located in contiguous memory space, iptables uses full replacement to update rules, which allows us to add/remove rules from user space with atomic operations, but non-incremental rule updates can cause serious performance problems when the rules are orders of magnitude larger: if a large If you use the iptables approach to implementing services in a large Kubernetes cluster, when the number of services is large, updating even one service will modify the iptables rule table as a whole. The full commit process is protected by kernel lock, so there is a significant update latency.
User-space tables, chains and rules
The iptables command line in user space can read data from a given table and render it to the terminal, add new rules (actually replacing the entire table’s rules table), etc.
iptables mainly operates on the following objects.
- table: corresponds to the
xt_tablestructure in kernel space. All operations of iptable are performed on the specified table, which defaults to filter. - chain: The set of rules that the specified table calls through a specific netfilter hook, and you can also customize the rule set and jump from the hook rule set.
- rule: corresponds to
ipt_entry,ipt_entry_matchandipt_entry_targetabove, defining the rules for matching packets and the behavior to be performed after the match. - match: A highly scalable custom match rule.
- target: A highly scalable custom post-match behavior.
Based on the flow of the code invocation process described above, the chain and rule are executed as shown in the following diagram.
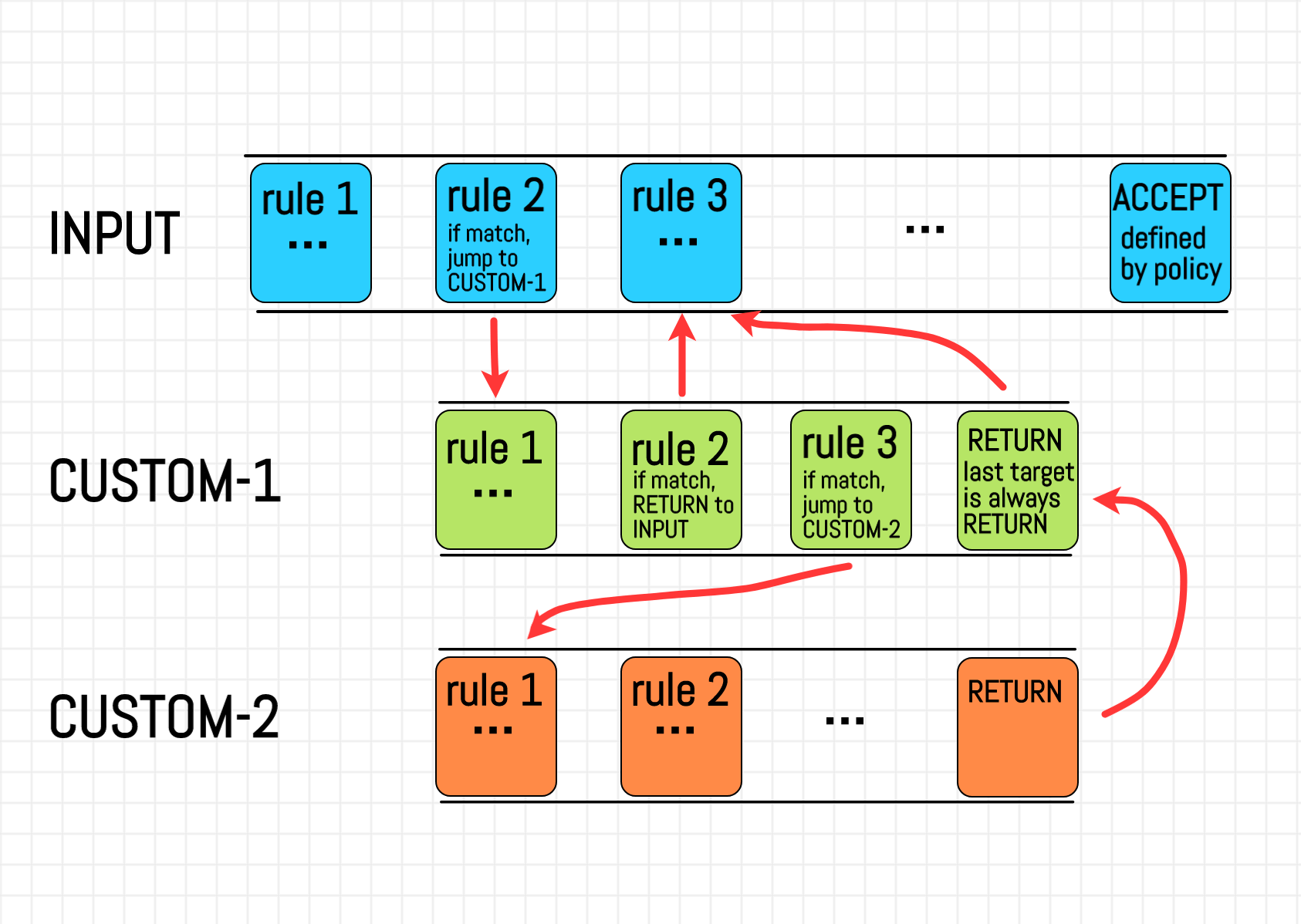
For the specific usage and commands of iptables, you can refer to Iptables Essentials: Common Firewall Rules and Commands | DigitalOcean.
conntrack
It is not enough to filter packets by the first part of the layer 3 or 4 information, sometimes it is necessary to further consider the state of the connection. netfilter performs connection tracking with another built-in module conntrack to provide more advanced network filtering functions such as filtering by connection, address translation (NAT), etc. Because of the need to determine the connection status, conntrack has a separate implementation for protocol characteristics, while the overall mechanism is the same.
I was going to continue with conntrack and NAT, but I decided against it because of its length. I will write another article explaining the principles, applications and Linux kernel implementation of conntrack when I have time.