0. Preface
For databases where the storage medium is disk or SSD, the mainstream has long used B+ trees as an index structure to achieve fast data lookup. When the data volume is not too large, B+ tree read and write performance is very good. But in the case of massive data, the B+ tree is getting taller and taller, and because the B+ tree needs to split and merge pages along the B+ tree layer by layer when updating and deleting data, it seriously affects data writing performance. To cope with this situation, google introduced a new data organization structure LSM Tree (Log-Structured Merge Tree) in the paper “Bigtable: A Distributed Storage System for Structured Data”, and subsequently, Bigtable Jeffrey Dean and Sanjay Ghemawat, the main authors of Bigtable, open-sourced LevelDB, a database based on LSM Tree, which allows everyone to understand the idea and implementation of LSM Tree more thoroughly and deeply. Currently, the more popular NoSQL databases, such as Cassandra, RocksDB, HBase, LevelDB, etc., and newSQL databases, such as TiDB, all use LSM Tree to organize disk data. Even traditional relational databases like SQLite and traditional document-based databases like MongoDB provide LSM Tree-based storage engines as optional storage engines.
1. Brief description of the basic principle
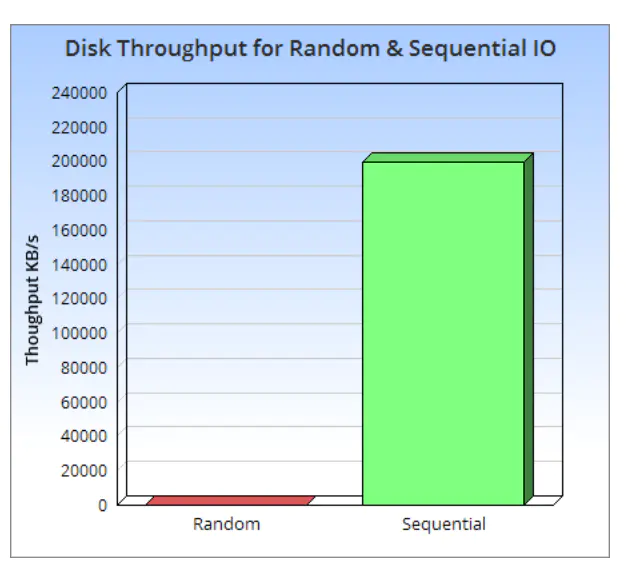
The full name of LSM Tree is Log-Structured Merge Tree, which is a hierarchical, ordered data storage structure designed for the characteristics of block storage devices (mechanical hard disks and SSDs). Its core theoretical basis is still the sequential write speed of disks is very much faster than random write speed, even for SSDs, due to block erasure and garbage collection, sequential write speed is still much faster than random write speed.
The LSM Tree slices the stored data into a series of SSTables (Sorted String Table), where the data in an SSTable is an ordered arbitrary byte group (i.e., an arbitrary byte string, not a String as in programming languages). Once written to disk, the SSTable cannot be modified like a log (this is the origin of the word Log-Structured in the name of the Log-Structured Merge Tree). When modifying existing data, the LSM Tree does not modify the old data directly, but writes the new data directly to the new SSTable. Similarly, when deleting data, LSM Tree does not delete the old data directly, but writes a record with the deletion mark of the corresponding data to a new SSTable. In this way, LSM Tree writes data to disk with sequential block write operations and no random write operations.
This unique way of writing LSM Tree leads to the fact that when looking up data, LSM Tree cannot look up in a unified index table like B+ tree, but looks up from the newest SSTable to the oldest SSTable in order. If the data to be found in the new SSTable or the corresponding deletion mark is found, the result is returned directly; if not, the search is performed in the old SSTable again until the oldest SSTable is found. In order to improve the efficiency of searching, LSM Tree organizes SSTable into layers, that is, SSTable is organized into multiple layers, and there can be multiple SSTables in the same layer, and the same data can not be repeated in multiple SSTables in the same layer, and the data can be ordered in the same layer, that is, the data in each SSTable is ordered The maximum data value of the previous SSTable is smaller than the minimum data value of the next SSTable (the actual situation is more complicated than this, which will be described later). This can speed up the data query in the same SSTable layer. At the same time, LSM Tree will merge (Compact) multiple SSTables into a new SSTable, which can reduce the number of SSTables, and at the same time remove the modified data or deleted data from the SSTable, reducing the size of the SSTable (this is Log-Structured Merge). Tree name from the word Merge), and is extremely important for improving lookup performance (the SSTable merge (Compact) process is so important for LSM Tree lookups that it was made part of the name).
2. Detailed description of the read/write process
2.1 LSM Tree framework diagram
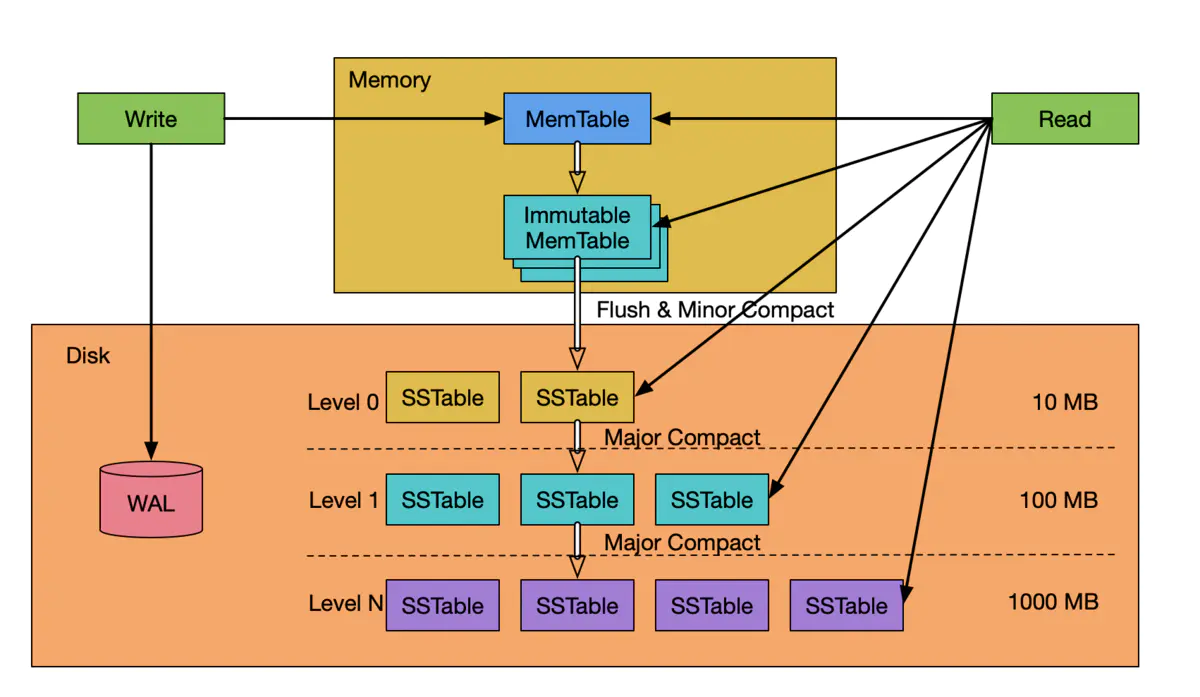
In the above figure, WAL (Write Ahead LOG) is not strictly speaking a part of the LSM Tree data structure itself, but in the actual system, WAL is an integral part of the database, and it is important to include WAL in order to understand LSM Tree more accurately.
As we can see from the figure, the data of LSM Tree consists of two parts: the in-memory part and the part that persists to disk. The in-memory part consists of a MemTable and one or more Immutable MemTables. The part on disk consists of SSTables distributed at multiple levels. a smaller level (level 0) means that the SSTable at that level is newer, and a larger level (level 1…level N) means that the SSTable at that level is newer. . level N) means that the SSTable at that level is older, and the maximum level (level N) size is set by the system. In this figure, the smallest level in disk is level 0. There are also systems that define the Immutable MemTable in memory as level 0, while the data in disk starts from Level 1. This is just a difference in the definition of level, and does not affect the workflow of the system or the understanding of the system.
The structure and role of WAL, like other databases, is a log structure file that can only append records at the end in an Append Only manner. It is used to replay operations when the system crashes and restarts so that data in MemTable and Immutable MemTable that is not persisted to disk is not lost.
A MemTable is often an ordered data structure organized as a Skip List (or, of course, an ordered array or a binary search tree such as a red-black tree), which supports both efficient dynamic insertion of data, sorting of data, and efficient exact and range lookup of data.
SSTable generally consists of a set of data blocks and a set of metadata blocks. The metadata block stores the descriptive information of the SSTable data block, such as index, BloomFilter, compression, statistics, and other information. Because the SSTable is immutable and ordered, the index is often used in a dichotomous array structure on it. In order to save storage space and improve the efficiency of reading and writing data block, the data block can be compressed. the structure of SSTable (sstfile) of RocksDB is shown below.
|
|
The paper BigTable describes SSTable more clearly, I think, and the following excerpt is for your reference.
An SSTable provides a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte strings. Operations are provided to look up the value associated with a specified key, and to iterate over all key/value pairs in a specified key range. Internally, each SSTable contains a sequence of blocks (typically each block is 64KB in size, but this is configurable). A block index (stored at the end of the SSTable) is used to locate blocks; the index is loaded into memory when the SSTable is opened. A lookup can be performed with a single disk seek: we first find the appropriate block by performing a binary search in the in-memory index, and then reading the appropriate block from disk. Optionally, an SSTable can be completely mapped into memory, which allows us to perform lookups and scans without touching disk.
2.2 Data writing process
As shown above, when LSM Tree writes data, it first writes a record to WAL and then writes the data to MemTable in memory, so the write operation is completed.
When writing MemTable, writing new data is almost the same as modifying some fields of the existing data and modifying all fields of the existing data. The writing operation process is almost the same as writing the incoming data (merge) to the MemTable. When deleting data, a delete mark is written to the MemTable. When the size of MemTable reaches the set size (typically 64KB), LSM Tree will freeze the current MemTable as an unmodifiable Immutable MemTable, and then create a new MemTable for new data writing. At the same time, LSM Tree generally has some background threads (or processes) separate from the write threads (or processes) that are responsible for flushing the Immutable MemTable to disk and persisting the data. The WAL corresponding to the Immutable MemTable that has been flushed to disk can then be deleted from disk. The number of Immutable MemTables in memory is determined by the difference between the speed of Immutable MemTable flush and the speed of Immutable MemTable generation (data writing speed).
As we can see from the LSM Tree data writing process, the LSM Tree data writing operation is very simple and minimal, just write the WAL and the MemTable in memory. The WAL is written sequentially by appending records at the end of the file without manipulating any data structure, and the writing speed is very fast. Although writing MemTable also requires inserting and sorting operations of jumping tables, MemTable is an in-memory data structure, and the size of MemTable is controlled in a very, very small size (e.g. 64KB), so writing MemTable is also a very, very fast process.
Also, we can see that the speed of writing data is not related to the amount of total data in the database. Moreover, there is little difference in the write speed of LSM Tree regardless of whether new data is written, existing data is fully or partially modified, or existing data is deleted. In other words, the write speed of LSM Tree is stable and has no relationship with data size or data update type.
2.3 Data lookup process
We know from the writing characteristics of LSM Tree that if a piece of data is updated many times, it may be stored in several different SSTables, or even the latest data content of different parts of a piece of data is stored in different SSTables (a scenario where parts of the data are updated). LSM Tree calls this phenomenon space amplification, because a piece of data is stored in multiple copies on disk, and the older copies are obsolete and unneeded, and the data actually takes up more storage space than the valid data needs.
This phenomenon of space amplification causes the lookup process of LSM Tree to be like this: the SSTable is looked up in the order of newest to oldest, until the required data is found in one (or some) SSTable, or the oldest SSTable is not found even after the lookup. The specific lookup order is: first lookup in memory MemTable, then lookup in memory Immutable MemTable, then lookup in level 0 SSTable, and finally lookup in level N SSTable.
When finding a specific SSTable, we generally read the metadata block of the SSTable into memory first, and according to BloomFilter, we can quickly determine whether the data exists in the current SSTable, and if it exists, we use the dichotomy method to determine which data block the data is in, and then read the corresponding data block into memory for accurate finding.
From the LSM Tree data lookup process, we can see that in order to find the target data, we need to read and look up SSTables that do not contain the target data, and if the target data is in the bottom level N SSTable, we need to read and look up all the SSTables! LSM Tree calls this phenomenon of reading and looking up unrelated SSTables as read amplification.
The read amplification phenomenon severely affects LSM Tree data lookup performance, even catastrophically (data is not even present or in the oldest SSTable), and the paper “BigTable” mentions several ways to improve data lookup performance.
-
Compression
As mentioned in the introduction of SSTable, compression of data blocks reduces the data block disk space occupation and read/write time by increasing the occupied CPU compression and decompression resources.
-
BloomFilter
As already mentioned when describing the lookup process, BloomFilter can quickly determine that the data is not in the SSTable without having to read the contents of the data block.
-
Cache
Because SSTable is immutable, it is ideal for caching into memory so that hot data does not have to be accessed on disk.
-
SSTable Merge (Compaction)
Combine multiple SSTables into one SSTable, delete old data or physically delete the data that has been deleted to reduce space amplification; and reduce the number of SSTables to reduce read amplification.
In fact, these optimization measures, except for SSTable merging is unique to LSM Tree, the first three are common database measures, and even SSTable merging is not unique to LSM Tree, it is actually similar to the earlier emergence of lucene’s segment merge (Segment Merge) principles and goals (of course, their writing and searching process is still fundamentally different). The following is a detailed description of SSTable merging.
3. SSTable merging
As we can see from the above description of the read and write process, LSM Tree has the phenomena of space amplification and read amplification although the data writing speed is very fast, and these phenomena, if not suppressed, may lead to extreme deterioration of read performance and excessive space occupation, which eventually leads to LSM Tree being unavailable in the actual production environment.SSTable merging is used to alleviate this phenomenon.LSM Tree supports merging multiple SSTables into a new SSTable. The merging process removes the old overlapping data and actually physically deletes the deleted data, also reducing the number of SSTables, which eliminates space amplification and improves data lookup performance at the same time. However, merging requires reading the SSTable involved in the merge into memory and writing the new SSTable generated after the merge to disk, which will increase the disk IO and CPU consumption, and this phenomenon of writing more data to disk than the actual data volume becomes write amplification, and of course merging also implies read amplification. As you can see, SSTable merging is a double-edged sword, with both advantages and disadvantages, and needs to be used wisely.
SSTable merging is divided into minor compaction and major compaction. minor compaction is the process of data processing when the contents of Immutable MemTable in memory are flushed to disk to form SSTable. major compaction is the process of The process of merging the SSTable of a small level (e.g. level 0) into the SSTable of a large level (e.g. level 1) by two adjacent levels.
SSTable merging is actually seeking a balance between several mutually constraining factors, such as space amplification, write amplification, and read amplification, and different application scenarios need to focus on optimizing to solve a certain problem, thus forming several typical SSTable merging strategies.
3.1 leveled compaction
leveled compaction sets a threshold value for the total data size of SSTable in each level, the larger the level number, the larger the threshold value is set, for example, level0 threshold value is 10MB, level1 threshold value is set to 100MB, level2 threshold value is set to 1000MB. when the total data size of a level layer When the total data size of a level exceeds the set threshold, one SSTable is selected and merged into one or more SSTables of the higher level. The selection of SSTable in the higher level is based on the distribution of data, and all the SSTable data in the merged higher level are ordered as a whole (one sorted run), that is, there is no overlap of data in the same level.
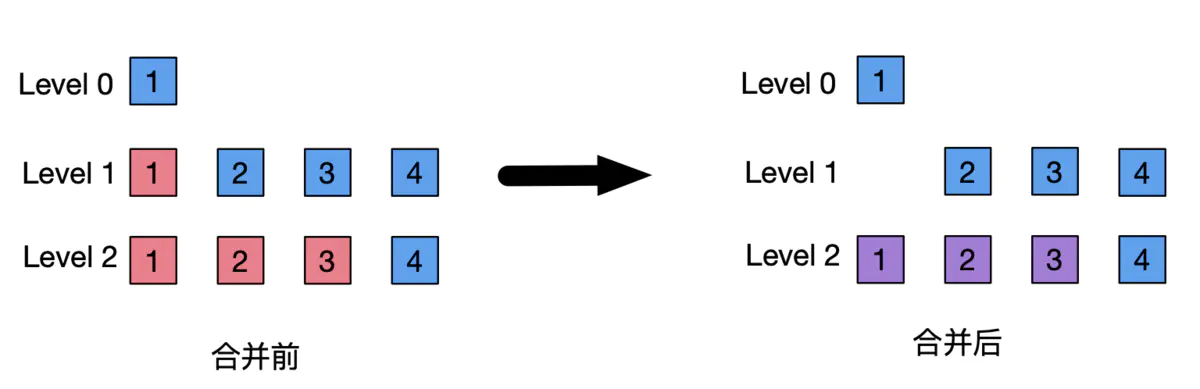
Leveled compaction is a strategy to minimize space enlargement because it merges SSTables into multiple SSTables and ensures that data in SSTables at the same level do not overlap. However, merging requires reading multiple SSTables and then writing multiple updated SSTables, resulting in greater write amplification and read amplification. But in the data lookup process, it reduces the read amplification during data lookup and improves the performance of data lookup because it reduces the number of SSTables that need to be looked up. Therefore, leveled compaction is suitable for scenarios that are more concerned about data lookup speed and controlling disk space occupation. For example, data is written once, but will be queried frequently and repeatedly; data is frequently modified, but need to control the disk space size and ensure the data query speed.
Cassandra’s LCS (Leveled Compaction Strategy) and RocksDB’s Classic Leveled Compaction use the leveled compaction strategy.
3.2 tiered compaction
tiered compaction when the number of SSTable in a level reaches a set threshold, then multiple SSTable in that level are merged into a new SSTable and put into a higher level.
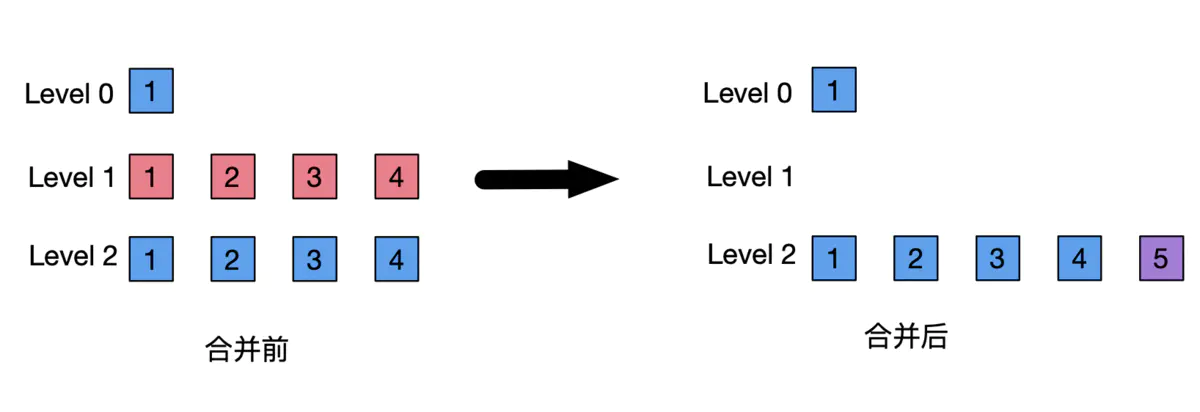
The tiered compaction is more favorable to control the write amplification to reduce the space amplification and improve the data query performance under a certain degree. Especially, as the number of levels gets larger, the amount of data in a single SSTable gets larger, and the merge trigger condition gets harder, the space occupied by the overlapped data and deleted data in these giant SSTables becomes more and more difficult to be released. The tiered compaction is more suitable for scenarios where the data is not frequently modified, and the query frequency of recently written data is high.
Cassandra’s STCS (Size Tiered Compaction Strategy) and RocksDB’s universal compaction use the tiered compaction strategy.
3.3 leveled-tiered mixed compaction
Combining the advantages of leveled compaction and tiered compaction, tiered compaction is used between some levels and leveled compaction is used between some other levels.
RocksDB’s leveled compaction uses the leveled-tiered mixed compaction strategy. The data from Immutable MemTable flush to level 0 uses tiered compaction, which means there is overlapping data in level 0. level0 to levelN uses leveld compaction strategy.
3.4 FIFO compaction
FIFO compaction has only one level hierarchy in disk, SSTable is arranged in the chronological order of generation, and the SSTable generated too early is deleted.
FIFO compaction is suitable for time series data, once the data is generated, it will not be modified.
Cassandra’s TWCS (Time Window Compaction Strategy), DTCS (Date Tiered Compaction Strategy) and RocksDB’s FIFO compaction use a FIFO type of merge strategy.
4. A few insights into system read and write performance improvement through the LSM Tree principle
-
Write data in bulk whenever possible. LSM Tree data writing performance is already high, but network transfer RTT time can be saved when operating in bulk.
-
Slice the data. This allows multiple slices to be written in parallel, and can also improve data query speed if data routing is handled properly. However, it increases the complexity of maintaining multiple slices of data for reading and writing.
-
Choose the appropriate primary key. Two more popular choices are 1) using incremental numbers as primary keys, and 2) using the business itself identifiers as primary keys. Numbers as primary keys can reduce the time for comparison and sorting operations when writing and querying, and also improve the efficiency of index caching; incremental numbers are often guaranteed to be written sequentially, which can reduce the sorting time. However, incremental numbers often do not have business semantics, and business actual queries need to check the secondary index first and then perform primary key lookup. The business identifier is often the actual identity distinguishing symbol for the business, and the business also tends to query the data through the business identifier. But the business identifier is often a string, which may be longer, so that the comparison, sorting, and caching efficiency aspects are not as good as the numbers. In general, I recommend that LSM Tree databases use business identifiers as primary keys. Because the cost of building indexes for business identifiers and maintaining them is unavoidable, instead of building secondary indexes, it is better to build primary key indexes directly.
-
Design reasonable secondary indexes and do not create unneeded secondary indexes. Secondary indexes can improve the query speed of the corresponding data, and each additional secondary index requires additional maintenance of the corresponding secondary index file, which seriously affects the performance of written data.
-
Use the appropriate SSTable merge strategy according to the specific scenario. Single write, frequent read scenarios choose leveled compaction strategy.
-
Turn off automatic SSTable merging when allowed, and force SSTable merging during low business volume periods.
-
It is reasonable to choose the full update (overwrite write) method or partial update (incremental write) method when updating data. The full update method increases the amount of data to be transferred and written, but it can improve the speed of data query. Partial update method will make the data distributed in multiple SSTables, and you need to query and merge the data in multiple SSTables to get the complete data, which will reduce the data query speed. If the data is modified more frequently and higher query speed is needed, it is recommended to use the full update method.