Why use cluster federation
Kubernetes has claimed to support up to 5,000 nodes and 150,000 Pods in a single cluster since version 1.8, and few companies actually deploy such a large single cluster. In many cases, we may deploy multiple clusters for a variety of reasons, but want to manage them in a unified manner, so we can use cluster federation.
Some typical application scenarios for cluster federation.
- High availability: Deploying applications on multiple clusters minimizes the impact of cluster failures.
- Avoid vendor lock-in: Distribute application load across multiple vendor clusters and migrate directly to other vendors when needed
- Fault isolation: Having multiple small clusters may be more conducive to fault isolation than a single large cluster
Federation v1
The earliest multi-cluster project, proposed and maintained by the K8s community.
Federation v1 was started around K8s v1.3 (Design Proposal), and related components and command line tools (kubefed) were released in later versions to help users quickly build federation clusters, and entered the Beta phase at v1.6; however, Federation v1 entered After the Beta, there was no further development, and it was officially abandoned around K8s v1.11 due to flexibility and API maturity issues.
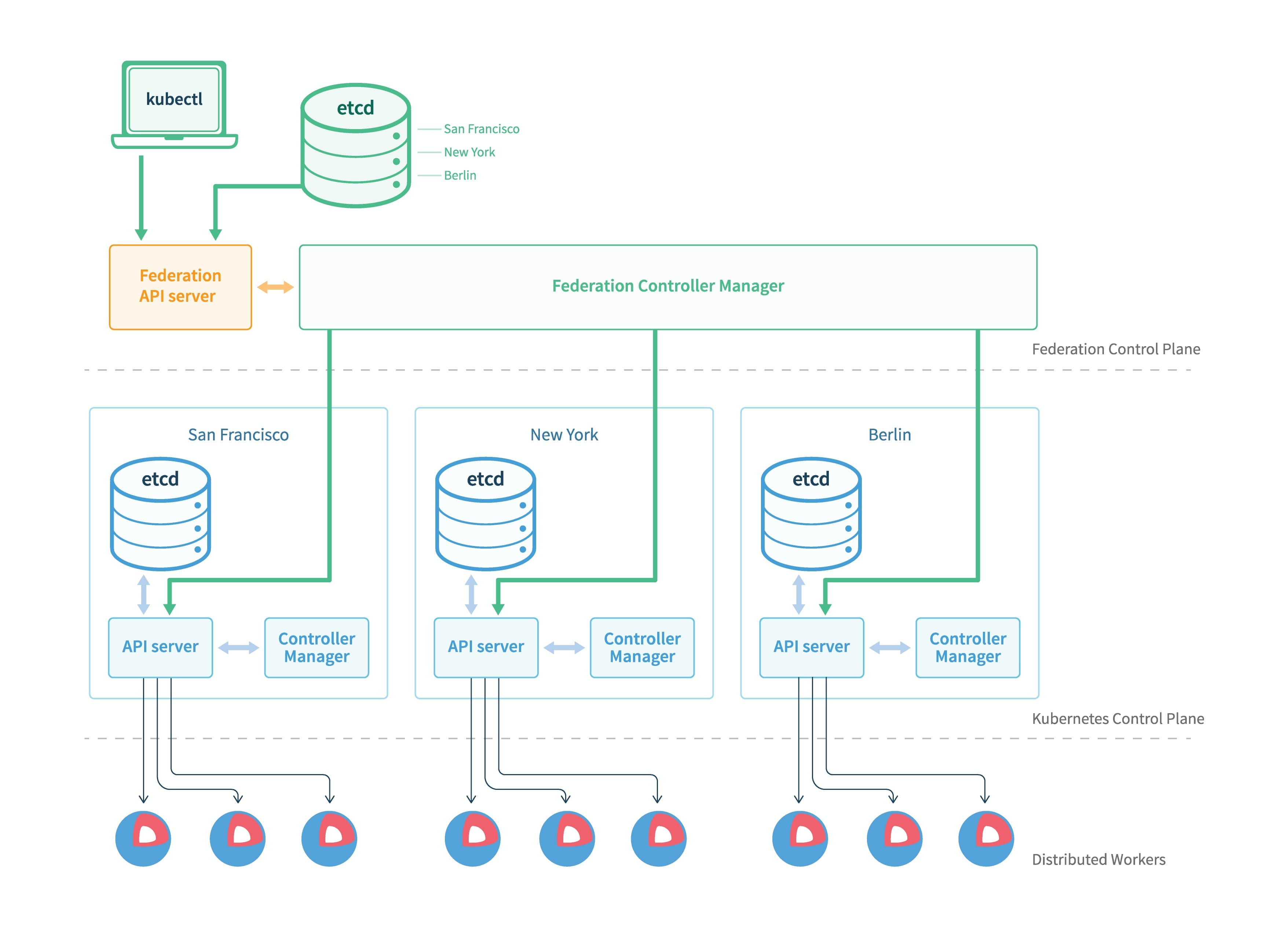
The basic architecture of v1 is shown in the figure above, with three main components.
- Federation API Server: similar to K8s API Server, providing a unified resource management portal, but only allows the use of Adapter to expand the supported K8s resources.
- Controller Manager: Provides resource scheduling and state synchronization among multiple clusters, similar to kube-controller-manager.
- Etcd: stores the Federation’s resources
In the v1 version, the general steps to create a federation resource are as follows: write all the configuration information of the federation to the annotations of the resource object, the whole creation process is similar to K8s, the resource will be created to the Federation API Server, and then the Federation Controller Manager will create the annotations according to the After that, the Federation Controller Manager will create the resource to each subcluster according to the configuration in annotations; here is an example of ReplicaSet.
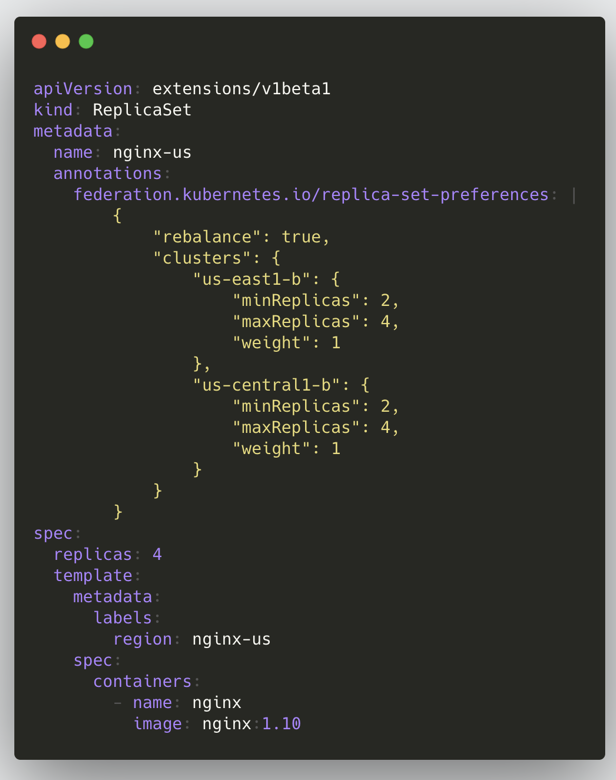
There are two main problems associated with this architecture.
- not being flexible enough to add a new Adapter every time a new resource is created (committing the code for re-release); and the object will carry many Federation-specific Annotation
- Lack of independent API object version control, e.g. Deployment is GA in Kubernetes, but only Beta in Federation v1
Federation v2
With the experience and lessons learned from v1, the community has proposed a new cluster federation architecture: Federation v2; the evolution of the Federation project can also be found in the article Kubernetes Federation Evolution.
The v2 release leverages CRD to implement the overall functionality by defining multiple custom resources (CRs), thus eliminating the API Server from v1. The v2 release consists of two components.
- admission-webhook provides access control
- controller-manager handles custom resources and coordinates state across clusters
The general process to create a federated resource in v2 is as follows.
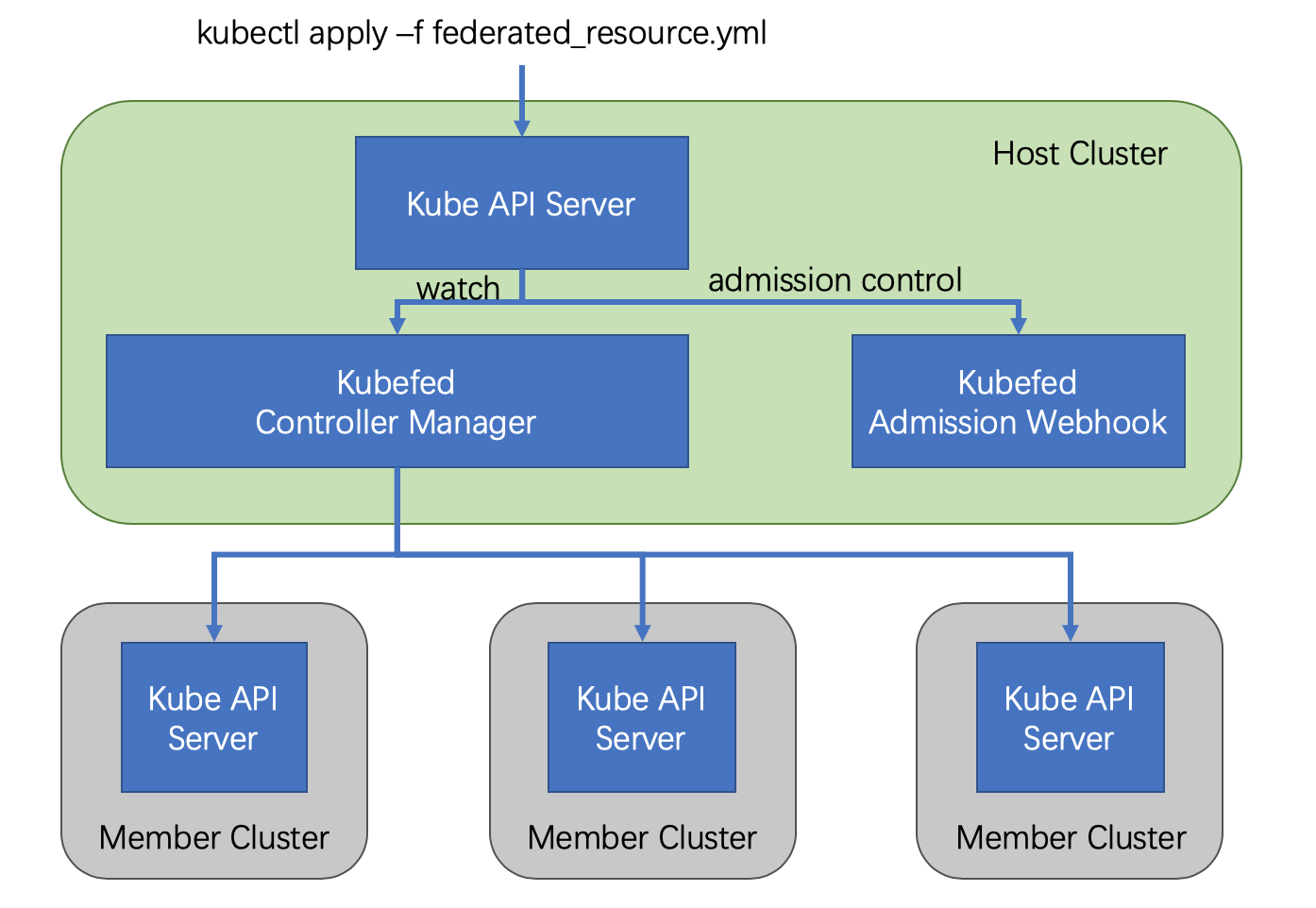
The Federated Resource is created in the API Server of the Host cluster, and then the controller-manager intervenes to distribute the corresponding resources to different clusters, and the rules of distribution are written in the Federated Resource object.
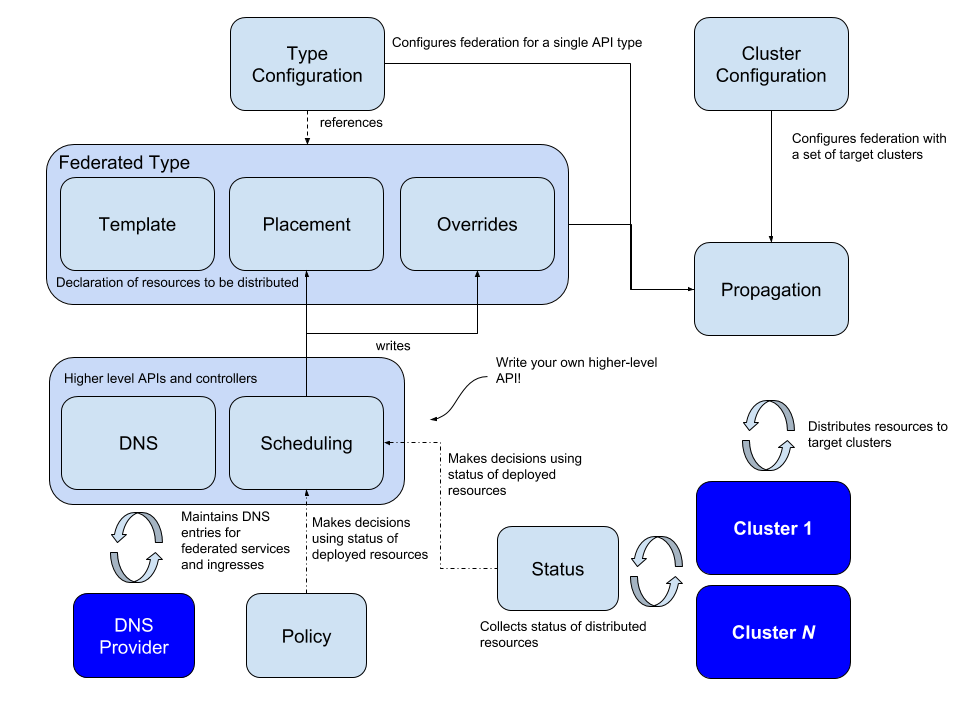
Logically, Federation v2 is divided into two major parts: configuration and propagation; configuration mainly contains two configurations: Cluster Configuration and Type Configuration.
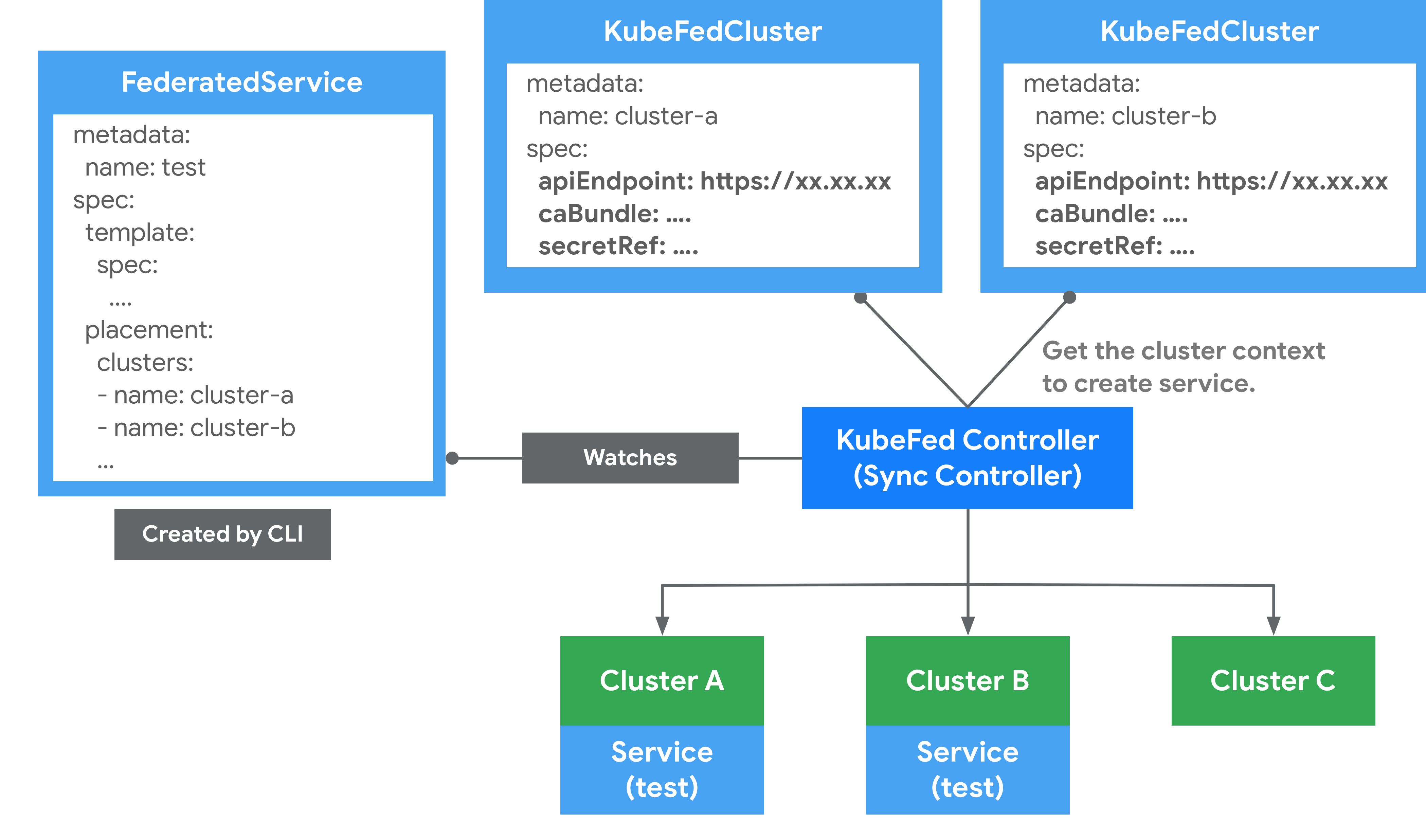
Cluster Configuration
This is used to store API authentication information for federated clusters and can be used to join/remove clusters via kubefedctl join/unjoin. When successfully joined, a KubeFedCluster CR is created to store cluster related information such as API Endpoint, CA Bundle and Token. The controller-manager will later use this information to access different Kubernetes clusters.
|
|
Type Configuration
defines which Kubernetes API resources are to be federated; for example, if you want to federate ConfigMap resources across clusters, you must first create the new resource FederatedConfigMap in the Host cluster via CRD, then create the configmaps resource with the name Type configuration (FederatedTypeConfig) resource with the name configmaps, and then describe the ConfigMap to be managed by the FederatedConfigMap so that the Kubefed controller-manager knows how to create the Federated resource. An example is as follows.
|
|
Federated Resource CRD
There is another key CRD: Federated Resource. If you want to add a new resource to be federated, you need to create a new FederatedXX CRD that describes the structure and distribution strategy of the corresponding resource (to which clusters it needs to be distributed); the Federated Resource CRD consists of three main parts Templates
- Templates to describe the resources to be federated
- Placement to describe the clusters that will be deployed and will not be distributed to any cluster if not configured
- Overrides to allow overriding of some resources of some clusters
An example is shown below.
|
|
These FederatedXX CRDs can be created by kubefedctl enable <target kubernetes API type>, or you can generate/write the corresponding CRDs yourself and create them again.
Combined with the Cluster Configuration, Type Configuration and Federated Resource CRD introduced above, the overall architecture and related concepts of the v2 version are much clearer.
Scheduling
Kubefed can currently only do some simple inter-cluster scheduling, i.e., manual designation, for manual designation of scheduling is divided into two main parts, one is directly in the resource to set the destination cluster, and the other is through ReplicaSchedulingPreference for proportional allocation.
Specifying directly in the resource can be done by specifying a list of clusters through clusters or by selecting clusters based on cluster labels through clusterSelector, but there are two points to note.
- If the
clustersfield is specified,clusterSelectorwill be ignored - The selected clusters are equal, and the resource will deploy an undifferentiated copy in each selected cluster
If you need to schedule differently across multiple clusters, you need to introduce ReplicaSchedulingPreference for scaled scheduling.
|
|
totalReplicas defines the total number of replicas, clusters describes the maximum/minimum replicas for different clusters and the weights.
Currently ReplicaSchedulingPreference only supports deployments and replicasets as resources.
Karmada
Karmada is a multi-cloud container orchestration project open-sourced by Huawei. This project is a continuation of Kubernetes Federation v1 and v2, and some basic concepts are inherited from these two versions.
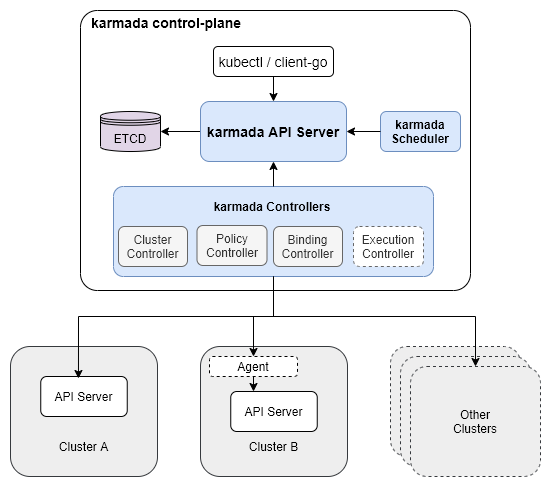
Karmada has three main components.
- Karmada API Server: essentially a normal K8s API Server, bound to a separate etcd to store those resources to be federally hosted
- Karmada Controller Manager: a collection of controllers that listen to objects in the Karmada API Server and communicate with member cluster API servers
- Karmada Scheduler: provides advanced multi-cluster scheduling policies
Similar to Federation v1, we have to write a resource to Karmada’s own API Server, before controller-manager distributes resources to each cluster according to some policies; however, this API Server is native to K8s, so it supports any resources and will not have the problems in the previous The distribution policy of federated resources is also controlled by a separate CRD, and there is no need to configure Federated Resource CRD and Type Configure in v2.
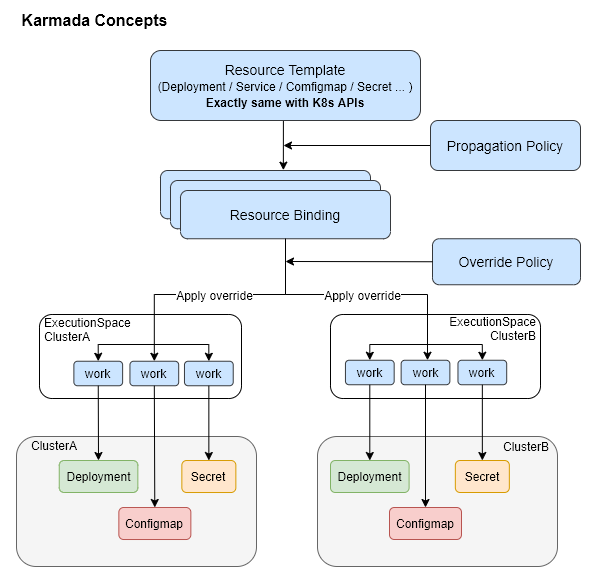
Some basic concepts of Karmada.
- Resource Template: Karmada uses K8s native API definitions as resource templates to facilitate quick interface to the K8s ecosystem toolchain.
- Propagaion Policy: Karmada provides a separate policy API to configure resource distribution policies.
- Override Policy: Karmada provides a separate differentiation API to configure cluster-related differentiation, such as configuring different clusters to use different mirrors
Cluster
Cluster resource records are similar to Federation v2 in that they contain the necessary information to access the managed cluster: API Endpoint, CA Bundle, and Access Token.
But one difference is that there are two sync modes for Karmada’s Cluster resources: Push and Pull; Push is the most common and common way, the Karmada component of the host cluster will be responsible for synchronizing and updating the status of such clusters; Pull mode member clusters will run a karmada-agent component, which collects its own state and updates the state of the host cluster’s corresponding Cluster resources.
Propagaion Policy
To distribute resources to member clusters in Karmada, you need to configure this separate PropagationPolicy CR; take the following nginx application as an example, starting with the Resource Template, which is the normal K8s Deployment .
You can then configure a PropagationPolicy to control the distribution policy for this nginx Deployment resource. In the example below, the nginx application is distributed to the member1 and member2 clusters on a 1:1 weighting.
|
|
After creating these two resources in Karmada API Server, you can query the status of the resources through Karmada API Server.
However, note that this does not mean that the application is running on the cluster where the Karmada API Server is located. In fact, there is no workload on this cluster, it just stores these Resource Templates, and the actual workloads are running in the member1 and member2 clusters configured in PropagationPolicy above, which can be seen by switching to the member1/member2 cluster.
The distribution policy also supports LabelSelector, FieldSelector and ExcludeClusters in addition to the most common cluster name specified above, and if all these filters are set, only clusters with all conditions met will be filtered out; in addition to cluster affinity, it also supports SpreadConstraints: dynamic grouping of clusters by region, zone and provider, which allows you to distribute applications to only certain types of clusters.
For resources with replicas (such as the native Deployment and StatefulSet), it supports updating this number of replicas as required when distributing resources to different clusters, e.g. I want 2 replicas for nginx applications on member1 cluster and only 1 replica for member2; there are a number of policies. The first is ReplicaSchedulingType, which has two optional values.
Duplicated: the number of replicas for each candidate member cluster is the same, copied from the original resource, and the effect is the same without setting theReplicaSchedulingStrategy.Divided: The replicas are divided into parts according to the number of valid candidate clusters, and the number of replicas per cluster is determined byReplicaDivisionPreference.
This ReplicaDivisionPreference in turn has two optional values.
Aggregated: Schedules these replicas to as few clusters as possible, taking into account the resources available in the cluster. If one cluster can hold all the replicas, they will only be scheduled to this one cluster, and the corresponding resources will exist on other clusters, but the number of replicas is 0Weighted: the number of replicas is divided according toWeightPreference, thisWeightPreferenceis very simple, it directly specifies how much weight each cluster has
The full and detailed structure can be found in Placement’s API definition.
Override Policy
Override Policy is as simple as adding the OverridePolicy CR to configure different clusters with different configurations, see an example directly.
|
|
Demo
Finally, see an official Karmada example.
