io_uring is an asynchronous I/O interface provided by Linux. io_uring was added to the Linux kernel in 2019, and after two years of development, it has now become very powerful. This article introduces the io_uring interface based on Linux 5.12.10.
The implementation of io_uring is mainly in fs/io_uring.c.
User State API for io_uring
The implementation of io_uring uses only three syscalls: io_uring_setup , io_uring_enter and io_uring_register. They are used to set up the io_uring context, to commit and fetch completion tasks, and to register buffers shared by kernel users, respectively. Using the first two syscalls is sufficient to use the io_uring interface.
The user and kernel submit and harvest tasks through the commit and completion queues. A large number of abbreviations will appear later in the article, so here are some first introductions.
| Abbreviations | Full Name | Explanation |
|---|---|---|
| SQ | Submission Queue | A circular queue stored in a whole contiguous block of memory space. Used to store the data on which the operation will be performed. |
| CQ | Completion Queue | A circular queue stored in a whole contiguous block of memory space. Used to store the results returned by the completed operation. |
| SQE | Submission Queue Entry | An item in the submission queue. |
| CQE | Completion Queue Entry | Complete one item in the queue. |
| Ring | Ring | SQ Ring, for example, stands for “Submit Queue Information”. It contains information such as queue data, queue size, missing items, etc. |
Initialize io_uring
|
|
The user initializes a new io_uring context by calling io_uring_setup. This function returns a file descriptor and stores the functions supported by io_uring, as well as the offsets of the individual data structures in fd, in params. The user maps fd to memory (mmap) based on the offset and obtains an area of memory shared by the kernel user. This memory area contains the contextual information for io_uring: commit queue information ( SQ_RING ) and completion queue information ( CQ_RING ); and an area dedicated to commit queue elements (SQEs). Only the serial number of the SQE in the SQEs area is stored in SQ_RING, and CQ_RING stores the complete task completion data.
SQ_RING,CQ_RINGare both of typestruct io_rings, and the area holding the submission queue elements is an array ofstruct io_uring_sqe. In fact, a singleio_ringsstructure contains both SQ and CQ information. In the current implementation of io_uring, the regions corresponding to SQ and CQ point to the sameio_ringsstructure. As an example, params hasio_sqring_offsets sq_offin it. Both*(sq_ring_ptr + sq_off.head)and*(cq_ring_ptr + sq_off.head)provide access to the SQ’s head-of-queue number.
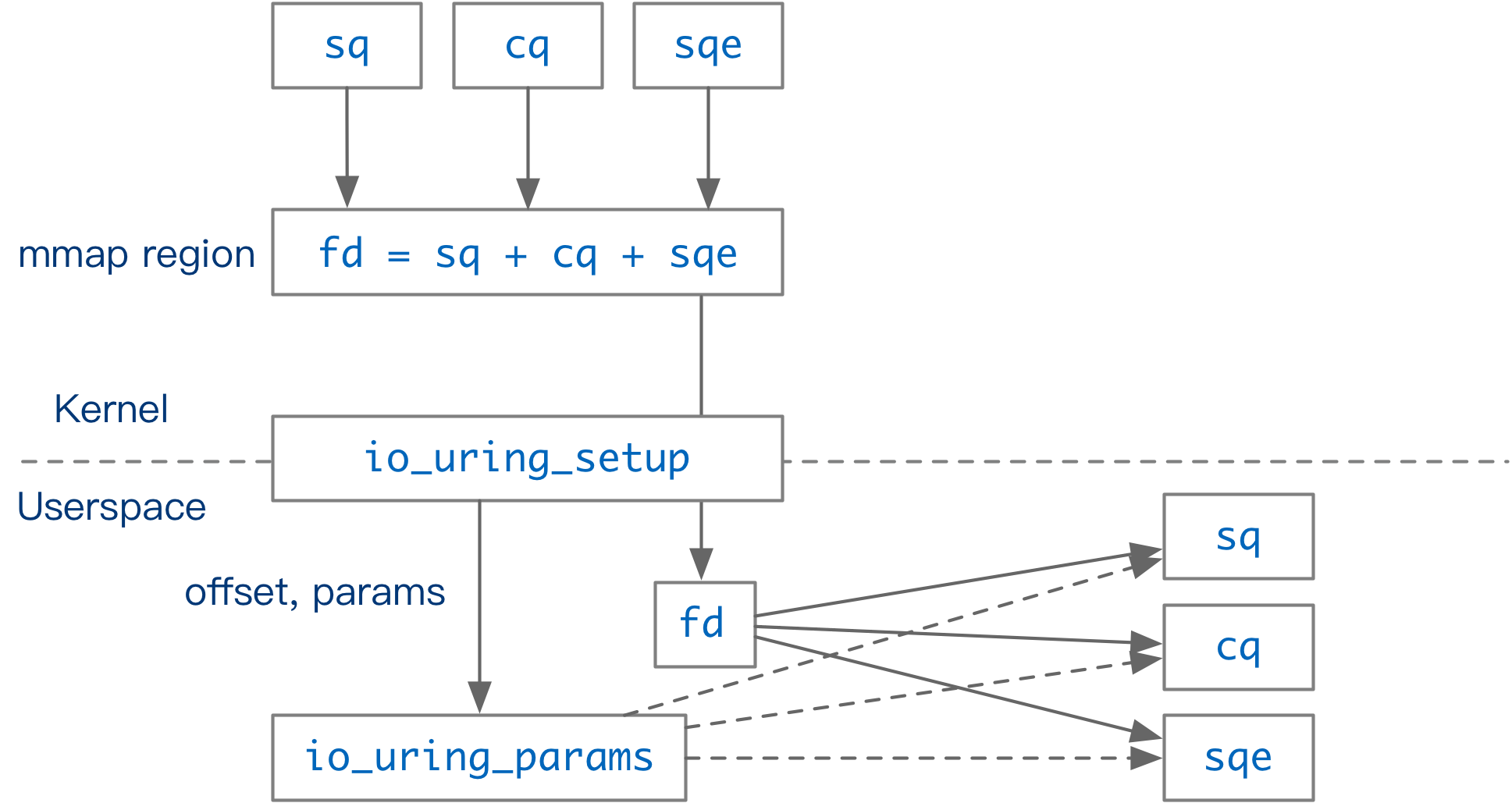
In Linux 5.12, SQEs are 64B in size and CQEs are 16B in size, so the same number of SQEs and CQEs do not require the same amount of space. When initializing io_uring, the kernel allocates entries of SQEs and entries * 2 of CQEs if the user does not set the CQ length in params.
The clever design of io_uring_setup is that the kernel passes messages through an area of memory that is shared with the user. After the context is created, operations such as task submission and task harvesting are performed through this shared memory area. In IO_SQPOLL mode (described in more detail later), operations that require kernel intervention (such as reading and writing files) can be done completely bypassing the Linux syscall mechanism, greatly reducing the overhead of syscall to switch contexts and swipe TLBs.
Description of the task
io_uring can handle a variety of I/O related requests. For example.
- File-related: read, write, open, fsync, fallocate, fadvise, close
- Network related: connect, accept, send, recv, epoll_ctl
- etc.
The following is an example of fsync and describes the structures and functions that may be used to perform this operation.
Definition and implementation of the operation
The io_op_def io_op_defs[] array defines the operations supported by io_uring, as well as some of its arguments in io_uring. For example IORING_OP_FSYNC.
Almost every operation in io_uring has a corresponding preparation and execution function. For example, the fsync operation corresponds to the io_fsync_prep and io_fsync functions.
In addition to synchronous (blocking) operations like fsync, the kernel also supports some asynchronous (non-blocking) calls, such as file reads and writes in Direct I/O mode. For these operations, there is a corresponding asynchronous preparation function in io_uring, ending with _async. For example.
|
|
These functions are io_uring wrappers for a particular I/O operation.
Passing of operation information
The user writes the operation to be performed to the SQ of io_uring. In the CQ, the user can harvest the completion of the task. Here, we introduce the encoding of SQE and CQE.
The SQE and CQE are defined in include/uapi/linux/io_uring.h The SQE is a 64B size structure that contains all the information that the operation may use.
Definition of io_uring_sqe.
CQE is a 16B-sized structure that contains the result of the execution of the operation.
Continuing with fsync as an example. To complete the fsync operation in io_uring, the user needs to set opcode in the SQE to IORING_OP_FSYNC, set fd to the file to be synchronized, and populate fsync_flags. Other operations are similar, just set the opcode and write the parameters needed for the operation to SQE.
In general, programs that use io_uring need to use the 64-bit user_data to uniquely identify an operation. user_data is part of the SQE. After io_uring executes an operation, the user_data of the operation is written to the CQ along with the return value of the operation.
Task submission and completion
io_uring interacts with the user via a ring queue.
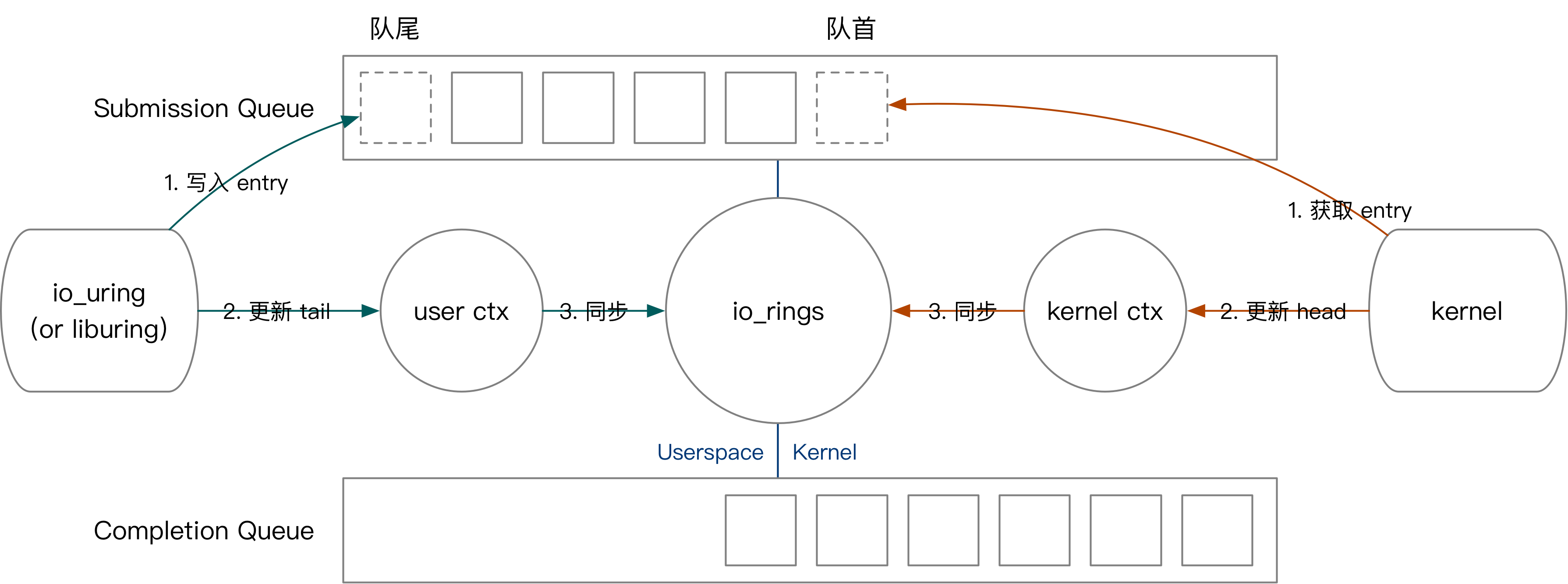
We will first introduce the kernel user interaction of io_uring with the example of a user-submitted task. The user submits a task as follows.
- Write the SQE to the SQEs area, and then write the SQE number to the SQ. (corresponds to the first green step in the diagram)
- Update the queue header of the user state record. (corresponds to the second step in green in the figure)
- If there are multiple tasks that need to be submitted at the same time, the user keeps repeating the above process.
- Write the final queue head number to the
io_uringcontext shared with the kernel. (corresponds to the third green step in the diagram)
Next we briefly describe the process of kernel fetching tasks, kernel completing tasks, and user harvesting tasks.
- The kernel state fetches the task by reading the SQE from the tail of the queue and updating the SQ tail in the
io_uringcontext.
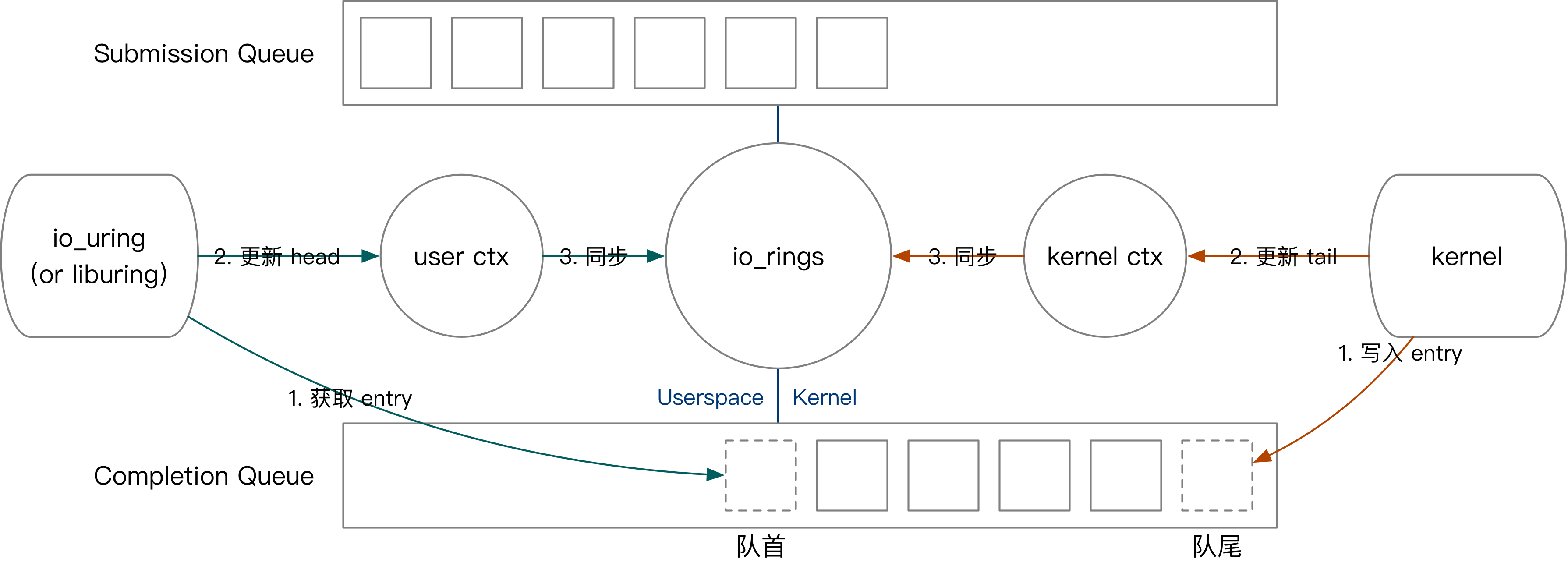
- Kernel state harvesting task: write CQE to CQ, update context CQ head.
- User state harvesting task: read CQE from CQ, update context CQ tail.
Implementation of io_uring
After describing the user state interface of io_uring, we can now detail how io_uring is implemented in the kernel.
io_uring has two options at creation time, corresponding to the different ways in which io_uring handles tasks.
- With
IORING_SETUP_IOPOLLturned on,io_uringwill perform all operations using polling. - With
IORING_SETUP_SQPOLLturned on,io_uringcreates a kernel thread dedicated to harvesting user-submitted tasks.
The setting of these options affects how the user interacts with io_uring afterwards.
- None of them, submit the task via
io_uring_enter, no syscall is needed to harvest the task. - Only
IORING_SETUP_IOPOLLis enabled, and tasks are submitted and harvested viaio_uring_enter. - Enable
IORING_SETUP_SQPOLLto submit and harvest tasks without any syscall. Kernel threads will sleep after a period of inactivity and can be woken up withio_uring_enter.
Kernel thread-based task execution
Each io_uring is supported by a lightweight ipool of o-wq threads, enabling asynchronous execution of Buffered I/O. For Buffered I/O, the contents of the file may be in the page cache or may need to be read from the disk. If the contents of the file are already in the page cache, they can be read directly during io_uring_enter and harvested when returning to the user state. Otherwise, the read and write operations are performed in the workqueue.
If the ioring_setup_iopoll option is not specified when creating io_uring, the io_uring operations are put into the io-wq for execution.
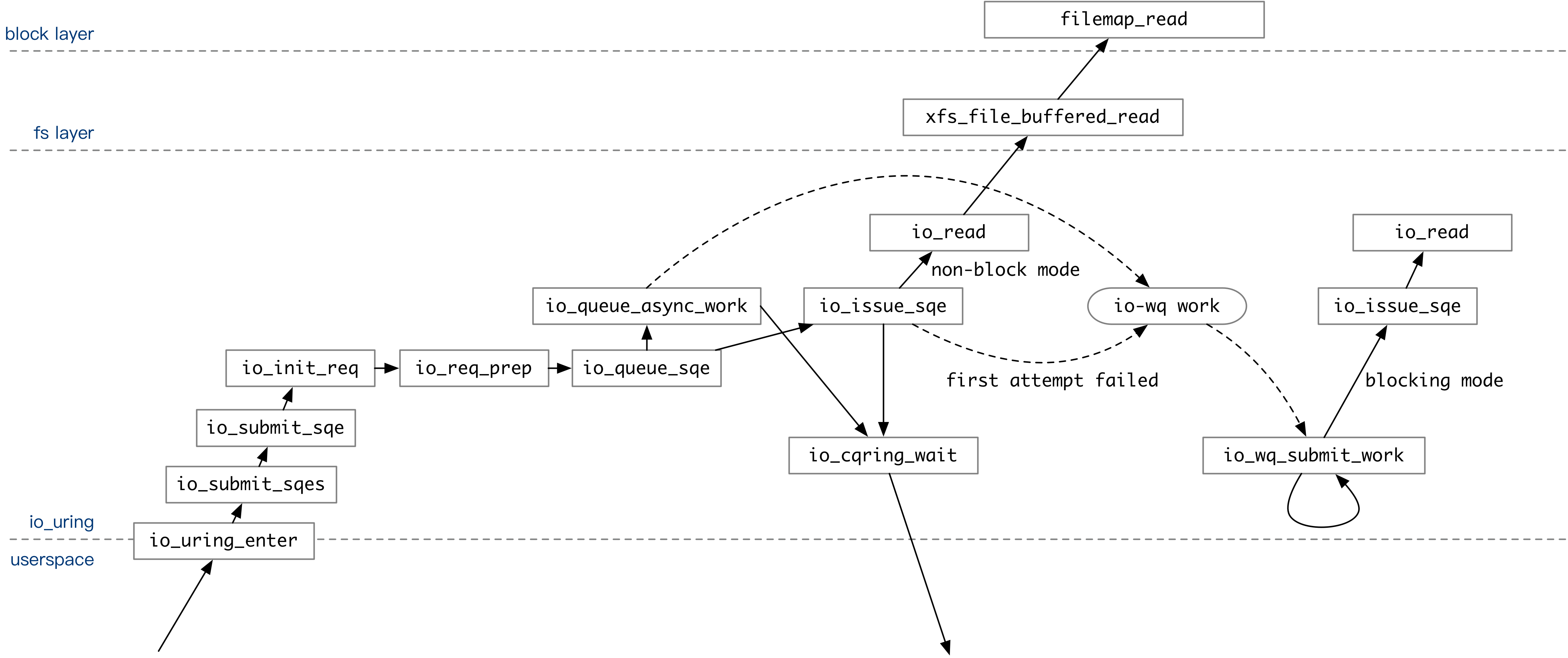
The above diagram covers the entire invocation flow of the user executing an operation via io_uring when IOPOLL mode is turned off. The user-submitted SQE is executed once in io_queue_sqe on a trial basis after a series of processing.
- If the
IOSQE_ASYNCoption is specified in the SQE, the operation is placed directly into the io-wq queue. - If the
IOSQE_ASYNCoption is not specified,io_uringwill first attempt to execute the operation contained in the SQE once in non-blocking mode. For example, when executingio_read, if the data is already in the page cache, theio_readoperation in non-blocking mode will succeed. If it succeeds, it returns directly. If unsuccessful, it is put into io-wq.
After all operations have been committed to the kernel queue, if the user has set the IORING_ENTER_GETEVENTS flag, io_uring_enter will wait for the specified number of operations to complete before returning to the user state.
After that, Linux will schedule the io-wq kernel thread at any time. At this point, the io_wq_submit_work function keeps executing the user-specified operations in blocking mode. After an operation is fully executed, its return value is written to CQ. The user knows which operations are processed by the kernel by the end of the CQ in the io_uring context, without having to call io_uring_enter again.

As you can observe from the flame chart, the kernel spends a lot of time processing read operations when IOPOLL is closed.
Polling-based task execution
Specify the IORING_SETUP_IOPOLL option when creating io_uring to enable I/O polling mode. In general, files opened in O_DIRECT mode support read/write operations using polling mode.
In polling mode, io_uring_enter is only responsible for committing operations to the kernel’s file read/write queue. After that, the user needs to call io_uring_enter several times to poll for the completion of the operation.
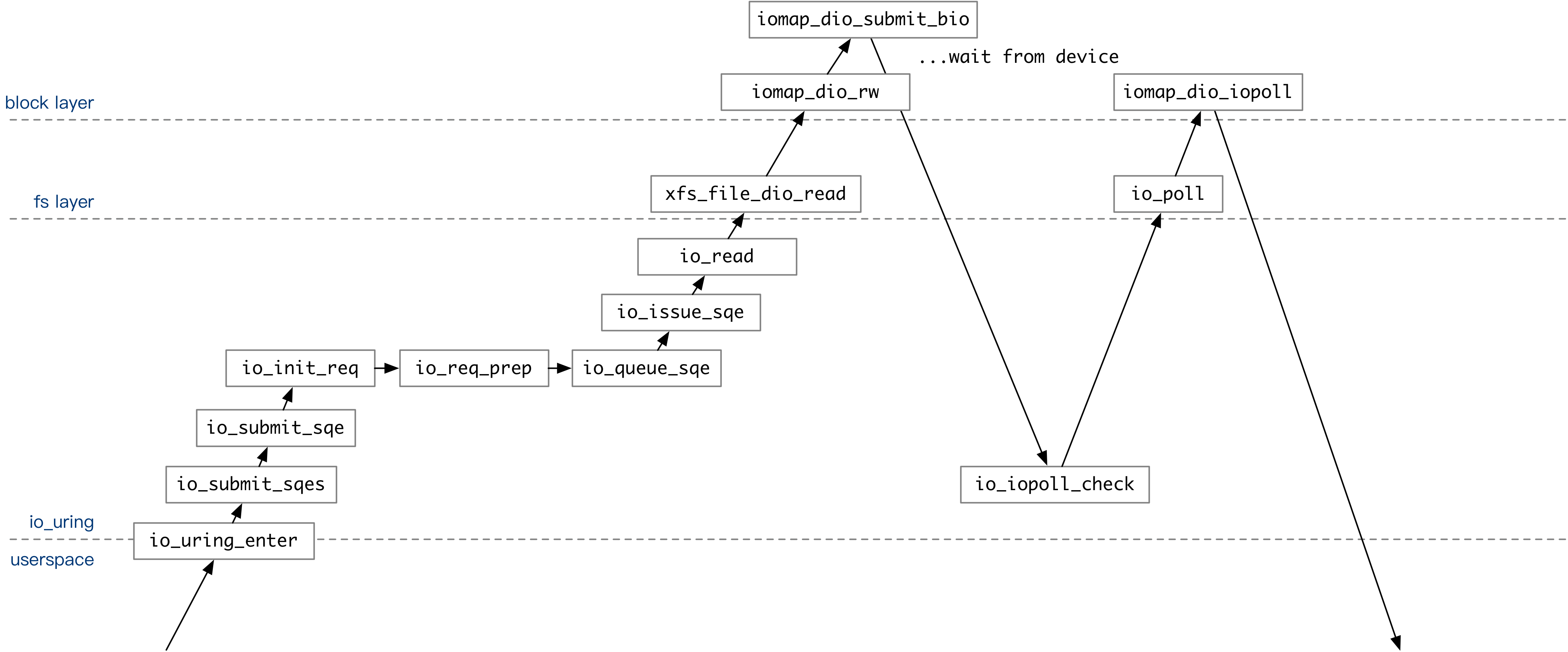
In polling mode, io-wq will not be used. When submitting tasks, io_read calls the kernel’s Direct I/O interface directly to submit tasks to the device queue.
If the user sets the IORING_ENTER_GETEVENTS flag, io_uring_enter calls the kernel interface via io_iopoll_check to poll the task for completion before returning to the user state.
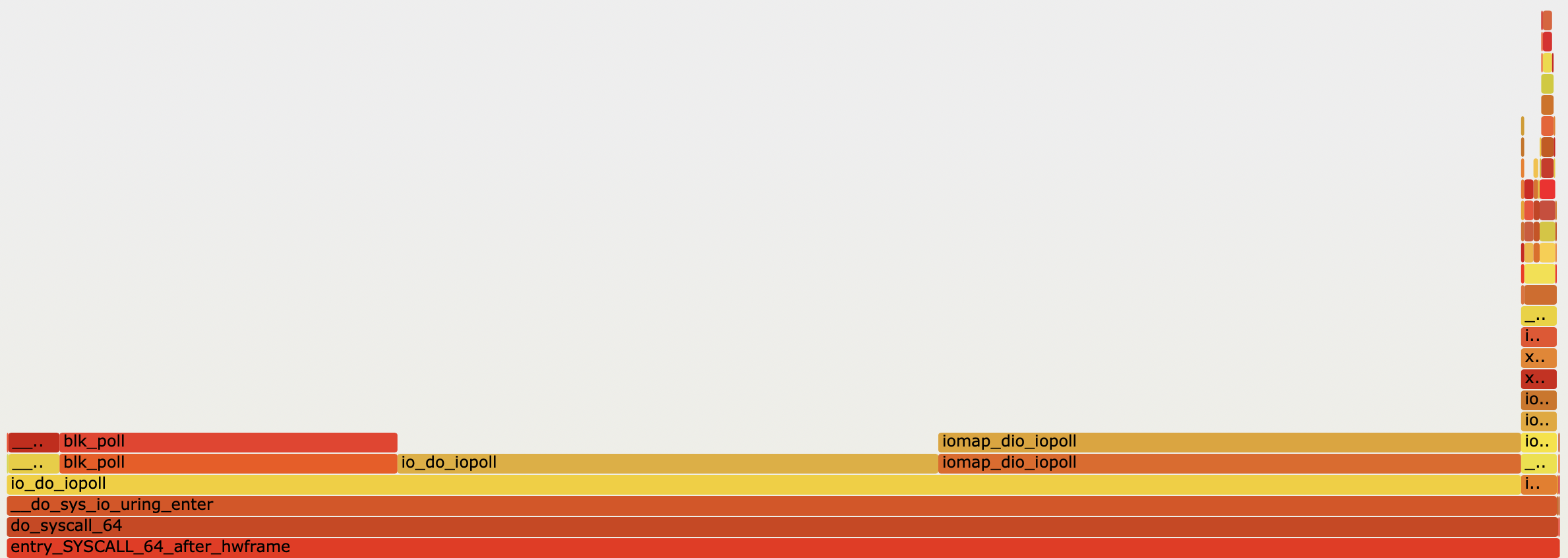
As you can see from the flame chart, io_uring_enter spends only a small fraction of its time on the task submission piece. Most of the time is spent polling for I/O operations to complete.
Task dependency management for io_uring
In a real production environment, we often have the need to write to a file n times and then use fsync to drop it. When using io_uring, the tasks in SQ are not necessarily executed sequentially. Setting the IO_SQE_LINK option to the operation establishes a sequential relationship between tasks. The first task after IO_SQE_LINK must be executed after the current task is completed.
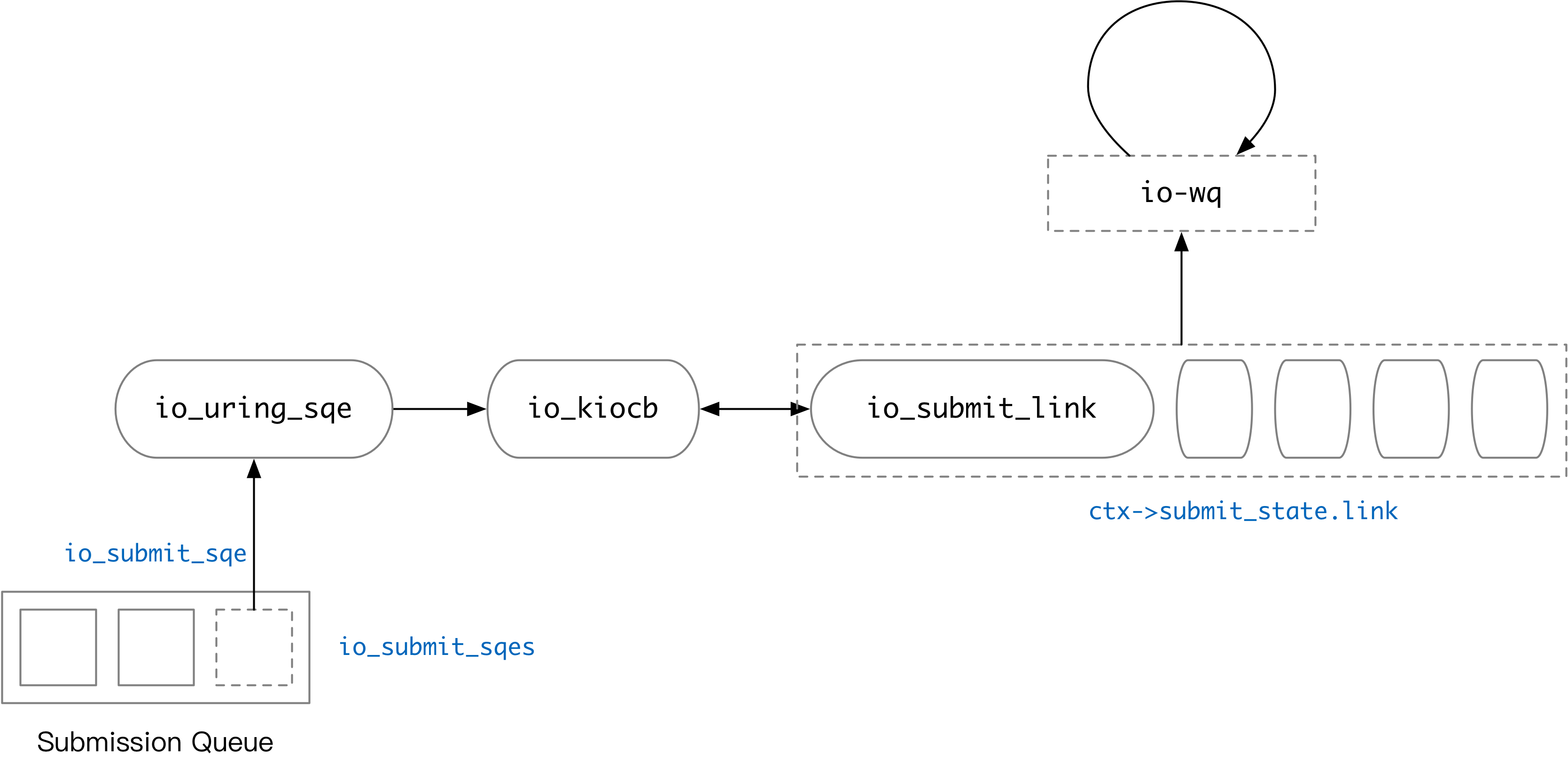
io_uring internally uses a linkedlist to manage the dependencies of tasks. Each operation becomes an io_kiocb object after being processed by io_submit_sqe. It is possible that this object will be placed in the linkedlist. io_submit_sqe does special processing for SQEs containing IO_SQE_LINK, as follows.
- The current linkedlist is empty (none of the previous tasks had
IO_SQE_LINK, or finished processing a chain) and the current taskIO_SQE_LINK, then a new linkedlist is created. - The linkedlist has been created and the new task is still
IO_SQE_LINK, then the current task is put into the linkedlist. - The linkedlist has been created and the currently processed task does not have
IO_SQE_LINK, put the current task into the linkedlist and start processing the whole linkedlist in order.
It appears that consecutive IO_SQE_LINK records in the SQ are processed sequentially in a sequential relationship. All tasks are committed before the end of io_submit_sqes. Therefore, if tasks have a sequential relationship, they must be submitted in bulk in the same io_uring_enter syscall.
Other options for controlling io_uring task dependencies include IOSQE_IO_DRAIN and IOSQE_IO_HARDLINK, which are not expanded here.
Summary and Insights
io_uringcan be roughly divided into four modes: default,IOPOLL,SQPOLL, andIOPOLL + SQPOLL. You can choose to turn onIOPOLLdepending on whether the operation requires polling or not. If you need higher real-time performance and less syscall overhead, you can consider turning onSQPOLL.- If you are only using Buffered I/O,
io_uringis usually not a significant performance gain over direct user-state calls to syscall. The fact thatio_uringinternally performs Buffered I/O operations via io-wq is not much different in nature from calling syscall directly in user state, but only reduces the overhead of switching between user and kernel states. Theio_uringcommit task has to go through theio_uring_entersyscall, and the latency and throughput should not be as good as a file I/O method such as mmap. - If you don’t want to try to execute a task immediately upon commit (like the previously mentioned case where the file contents are already in the page cache), you can add the
IOSQE_ASYNCflag to force the io-wq. - Use
IO_SQE_LINK,IOSQE_IO_DRAINandIOSQE_IO_HARDLINKto control the dependencies of tasks.
Appendix
Testing with fio’s io_uring mode
|
|