eBPF, derived from BPF, is essentially an efficient and flexible virtual class virtual machine component in the kernel that executes bytecode at many kernel hook points in a secure manner. BPF was originally intended for efficient Originally intended for efficient network message filtering, eBPF has been redesigned and is no longer limited to the network stack, but has become a top-level subsystem of the kernel, evolving into a general-purpose execution engine. Developers can develop performance analysis tools, software-defined networking, security, and many other scenarios based on eBPF. In this article, we will introduce the history of eBPF and build an eBPF environment for development practice. All the code in this article can be found in this Github Repository.
Technical Background
Development History
In 1992, Steven McCanne and Van Jacobson wrote a paper entitled The BSD Packet Filter: A New Architecture for User-level Packet Capture. In the paper, the authors described how they implemented network packet filtering in the Unix kernel, a new technique that was 20 times faster than the state-of-the-art packet filtering techniques of the time.
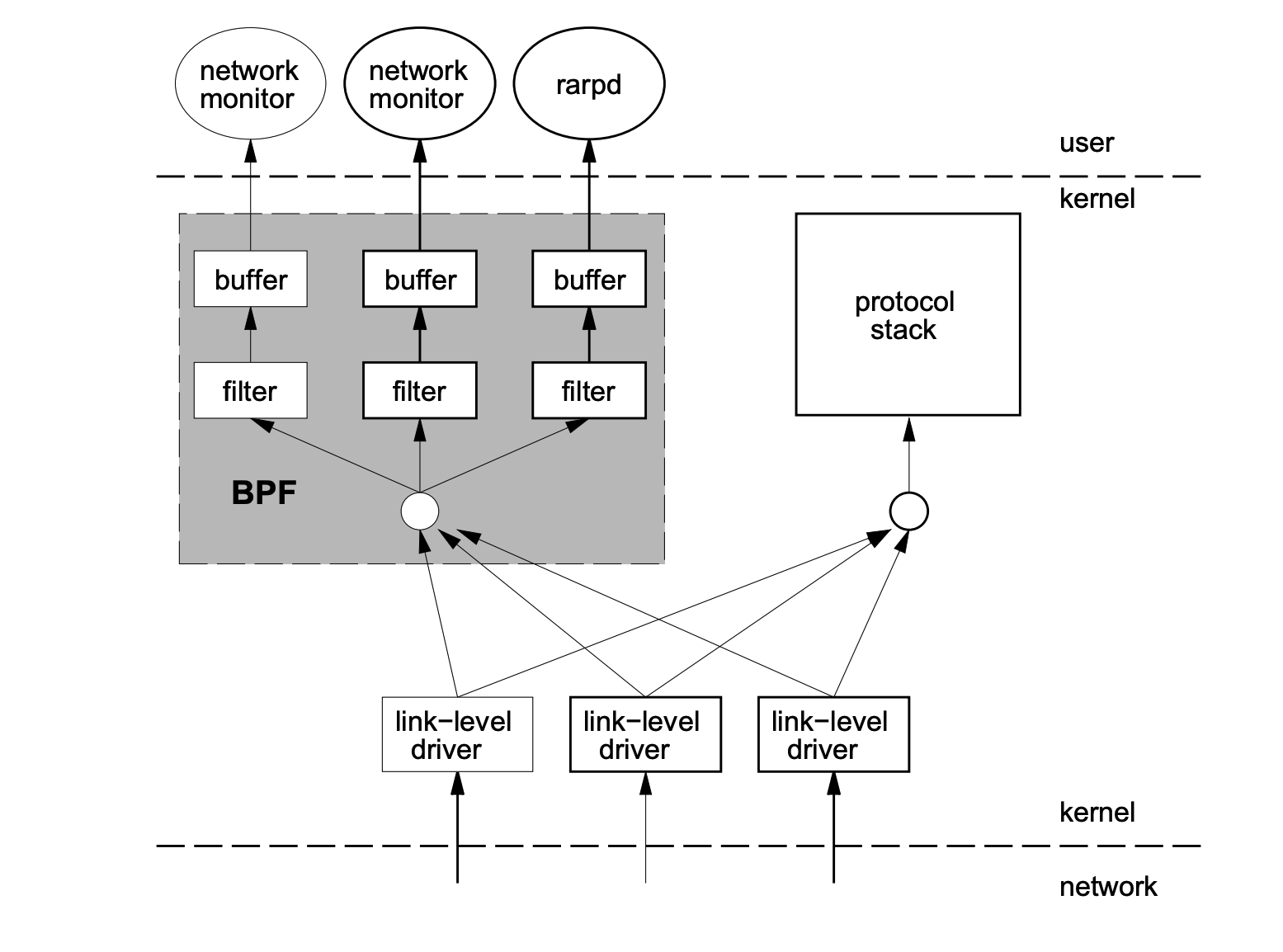
BPF introduces two major innovations in packet filtering.
- A new virtual machine (VM) design that works efficiently on CPUs with a register-based architecture.
- Applications use caches to copy only the data associated with filtered packets, not all of the packet’s information, which minimizes the amount of data processed by BPF.
Because of these great improvements, all Unix systems chose to use BPF as the network packet filtering technique, and to this day many derivatives of the Unix kernel (including the Linux kernel) still use this implementation. tcpdump uses BPF as the underlying packet filtering technique, and we can add -d to the end of the command to see the tcpdump filtering conditions for the underlying assembly directive.
|
|
In early 2014, Alexei Starovoitov implemented eBPF (extended Berkeley Packet Filter). After redesign, eBPF evolved into a general-purpose execution engine on which performance analysis tools, software-defined networks, and many other scenarios can be developed. eBPF first appeared in the 3.18 kernel, and since then the original BPF has been called the classic BPF (cBPF). cBPF is now largely deprecated. Now, the Linux kernel runs only eBPF, and the kernel transparently converts the loaded cBPF bytecode into eBPF before executing it .
eBPF vs. cBPF
The new design of eBPF is optimized for modern hardware, so the instruction set generated by eBPF executes faster than the machine code generated by the old BPF interpreter. The extended version also increases the number of registers in the virtual machine, increasing the original 2 32-bit registers to 10 64-bit registers. Due to the increased number and width of registers, developers can freely exchange more information and write more complex programs using function parameters. All in all, these improvements make the eBPF version 4 times faster than the original BPF.
| Dimension | cBPF | eBPF |
|---|---|---|
| Kernel Version | Linux 2.1.75(1997) | Linux 3.18(2014)[4.x for kprobe/uprobe/tracepoint/perf-event] |
| Number of registers | 2: A, X | 10: R0 - R9, plus R10 a read-only frame pointer. r0 return and exit values of kernel functions in eBPF, R1 - R5 parameter values of eBF programs in the kernel, R6 - R9 registers saved by the callee that the kernel function will save, R10 a read-only stack frame pointer. |
| Register width | 32-bit | 64-bit |
| Storage | 16 memory bits: M[0-15] | 512-byte stack, unlimited size map storage |
| Restricted kernel calls | Very limited, limited to JIT specific | limited, called by the bpf_call instruction |
| Target events | Packets, seccomp-BPF | Packets, kernel functions, user functions, trace point PMCs, etc. |
In June 2014, eBPF was extended to the user space, which became a turning point for BPF technology . As Alexei writes in the notes of the patch commit, “This patch demonstrates the potential of eBPF”. Currently, eBPF is no longer limited to the network stack and has become a top-level subsystem of the kernel.
eBPF and kernel modules
In contrast to the evolution of the Web, eBPF’s relationship to the kernel is somewhat similar to that of JavaScript to the browser kernel. eBPF provides a new kernel-programmable option compared to directly modifying the kernel and writing kernel modules. eBPF program architecture emphasizes security and stability and looks more like a kernel module, but unlike kernel modules, eBPF programs do not need to recompile the Unlike kernel modules, eBPF programs do not require recompilation of the kernel and can ensure that eBPF programs run to completion without crashing the system.
| Dimension | Linux Kernel Modules | eBPF |
|---|---|---|
| kprobes/tracepoints | Support | Support |
| Security | May introduce security vulnerabilities or cause kernel Panic | Checked by verifier, can secure the kernel |
| Kernel functions | can call kernel functions | can only be called through BPF Helper functions |
| compilability | need to compile the kernel | no need to compile the kernel, just introduce the headers |
| Running | on the same kernel | Stable ABI-based BPF programs can be compiled once and run everywhere |
| interact with the application | print logs or files | via perf_event or map structures |
| Data Structure Richness | General | Rich |
| Threshold | High | Low |
| Upgrade | requires uninstall and load, which may cause processing interruption | atomic replacement upgrade, which does not cause processing interruption |
| kernel built-in | depends | kernel built-in support |
eBPF architecture
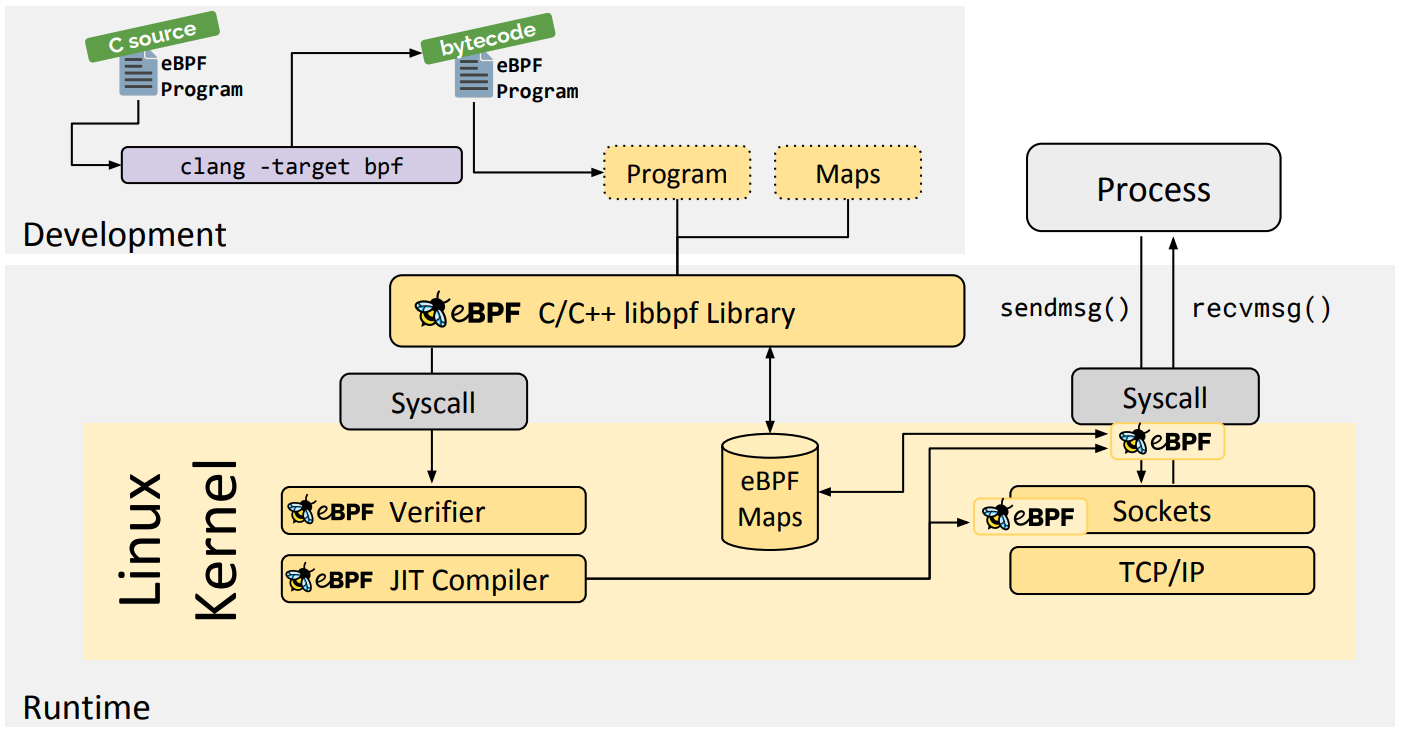
The eBPF is divided into two parts: a user-space program and a kernel program.
- The user space program is responsible for loading the BPF bytecode into the kernel and, if needed, for reading the statistics or event details returned by the kernel.
- The BPF bytecode in the kernel is responsible for executing specific events in the kernel, and if needed, sending the results to the user space via maps or perf-event events.
- The user space program can communicate with the kernel BPF bytecode program in both directions using the map structure, which provides more flexible control over the BPF bytecode program running in the kernel.
The overall structure of eBPF is as follows.
The flow of interaction between the user space program and the BPF bytecode in the kernel is as follows.
-
compile the written BPF code program into BPF bytecode using LLVM or GCC tools
-
load the bytecode into the kernel using the loader
-
The kernel uses the Verfier component to secure the execution of the bytecode to avoid disaster to the kernel, and loads the bytecode into the corresponding kernel module for execution after confirming its security
-
BPF bytecode programs running in the kernel can use two ways to send data back to user space
- maps method can be used to pass back to user space statistical summary information implemented in the kernel (e.g. measurement latency, stack information), etc.
- perf-event is used to send events collected by the kernel to user space in real time, which are read and analyzed by user space programs in real time.
eBPF Restrictions
Although powerful, eBPF technology in the kernel imposes a number of restrictions to ensure safe and timely kernel processing, but as the technology develops and evolves, the restrictions are gradually relaxed or provide corresponding solutions.
-
eBPF programs cannot call arbitrary kernel parameters, but are limited to the BPF Helper functions listed in the kernel module, and the list of supported functions is growing as the kernel evolves.
-
eBPF programs are not allowed to contain unreachable instructions to prevent loading invalid code and delaying the termination of the program.
-
The number of loops in an eBPF program is limited and must end in a finite amount of time, which is primarily used to prevent inserting arbitrary loops in kprobes that would result in locking the entire system; solutions include expanding loops and adding helper functions for common uses that require loops. Linux 5.3 includes support for bounded loops in the BPF, which has a verifiable upper limit on runtime.
-
The eBPF stack size is limited to MAX_BPF_STACK, which as of kernel Linux 5.8 is set to 512; see include/linux/filter.h, this limit is particularly relevant when storing multiple string buffers on the stack: a char[256] buffer will consume half of this stack. There are no plans to increase this limit; the solution is to switch to bpf mapped storage, which is effectively infinite.
-
The eBPF bytecode size was originally limited to 4096 instructions, but as of kernel Linux 5.8, it has now been relaxed to 1 million instructions (BPF_COMPLEXITY_LIMIT_INSNS), see: include/linux/bpf.h, the 4096 instruction limit ( BPF_MAXINSNS ) is still retained for unprivileged BPF programs; the new version of eBPF also supports cascading calls to multiple eBPF programs, which, although there are some limitations on passing information, can be combined to This new version of eBPF also supports cascading calls to multiple eBPF programs, which can be combined to achieve more powerful functionality, although there are some limitations on passing information.
1#define BPF_COMPLEXITY_LIMIT_INSNS 1000000 /* yes. 1M insns */
eBPF in action
Before we dive into the features of eBPF, let’s Get Hands Dirty and get a real feel for what eBPF programs are and how we can develop them. As the eBPF ecosystem evolves, there are now more and more toolchains for developing eBPF programs, which will also be described in detail in the following sections.
- bcc-based development: bcc provides development of eBPF with a Python API in the front end and a C implementation of the back-end eBPF program. It is simple and easy to use, but the performance is poor.
- Based on libebpf-bootstrap development: libebpf-bootstrap provides a convenient scaffolding
- Based on kernel source development: kernel source development is a higher threshold, but also more relevant to the underlying eBPF principles, so this approach is used here as an example
Kernel source code compilation
The system environment is as follows, using Tencent Cloud CVM, Ubuntu 20.04, kernel version 5.4.0
First install the necessary dependencies.
It is generally recommended to use apt to install the source code, which is easy and only installs the current kernel source code, and the size of the source code is around 200M.
The source code is installed in the /usr/src/ directory.
|
|
After successful compilation, you can see a series of target files and binaries in the samples/bpf directory.
Hello World
As mentioned before, eBPF usually consists of two parts: kernel-space programs and user-space programs, and there are many such programs in the samples/bpf directory, with kernel-space programs ending in _kern.c and user-space programs ending in _user.c. Without looking at these complicated programs, let’s write a Hello World for the eBPF program manually.
program hello_kern.c in the kernel.
|
|
function entry
There are some differences between the above code and normal C programming.
- the entry of the program is specified by
pragama __section("tracepoint/syscalls/sys_enter_execve")of the compiler. - The entry argument is no longer
argc, argv, which varies depending on the prog type. In our case, the prog type isBPF_PROG_TYPE_TRACEPOINT, and its entry argument isvoid *ctx.
headers
#include <linux/bpf.h>
The source of this header file is the kernel source header file. It is installed in /usr/include/linux/bpf.h.
It provides many of the symbols needed for bpf programming, for example
- enum bpf_func_id defines the id of all kerne helper functions
- enum bpf_prog_type defines all the types of prog supported by the kernel.
- struct __sk_buff is the interface in the bpf code to access the kernel struct sk_buff.
etc.
#include “bpf_helpers.h”
comes from libbpf , which needs to be installed by itself. We refer to this header file because of the call to bpf_printk(). This is a kernel helper function.
program explanation
Here we briefly explain the kernel state ebpf program, which is very simple.
bpf_trace_printkis an eBPF helper function that prints information totrace_pipe(/sys/kernel/debug/tracing/trace_pipe), see here for details- The code declares the
SECmacro and defines the GPL license, because the eBPF program loaded into the kernel needs to have a license check, similar to the kernel module
loads the BPF code
User state program hello_user.c
In the user-state ebpf program, it reads as follows.
- Load the compiled kernel-state ebpf target file into the kernel via
load_bpf_file - Read the trace information from
trace_pipeviaread_trace_pipeand print the trace information fromtrace_ pipeand print the trace information to the console
Modify the Makefile file in the samples/bpf directory by adding the following three lines in the corresponding locations.
Recompile and you can see the compiled file successfully.
|
|
Go to the corresponding directory and run the hello program, you can see the following output.
Code Explanation
As mentioned earlier, the load_bpf_file function loads the eBPF bytecode compiled by LLVM into the kernel, how exactly is this done?
- After searching, we can see that
load_bpf_fileis also implemented in thesamples/bpfdirectory, seebpf_load.c. - Read the
load_bpf_filecode to see that it mainly parses the ELF formatted eBPF bytecode and then callsload_and_attachfunction. - In the
load_and_attachfunction, we can see that it calls .bpf_load_programfunction, which is a function provided by libbpf. - The arguments
licenseandkern_versionin the calledbpf_load_programcome from parsing the eBPF ELF file, and the prog_type comes from the type specified in the SEC field inside the bpf code.
|
|
eBPF Features
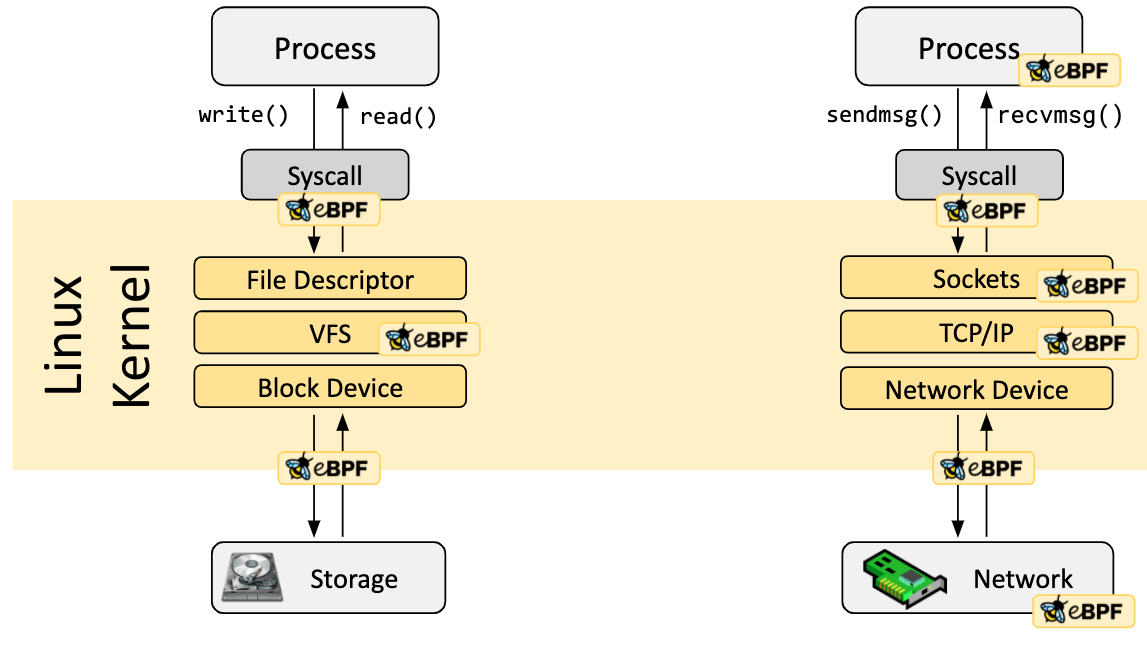
Hook Overview
eBPF programs are event-driven, they run when the kernel or application passes through a defined Hook point. These Hook points are defined in advance and include system calls, function entry/exit, kernel tracepoints, network events, etc.
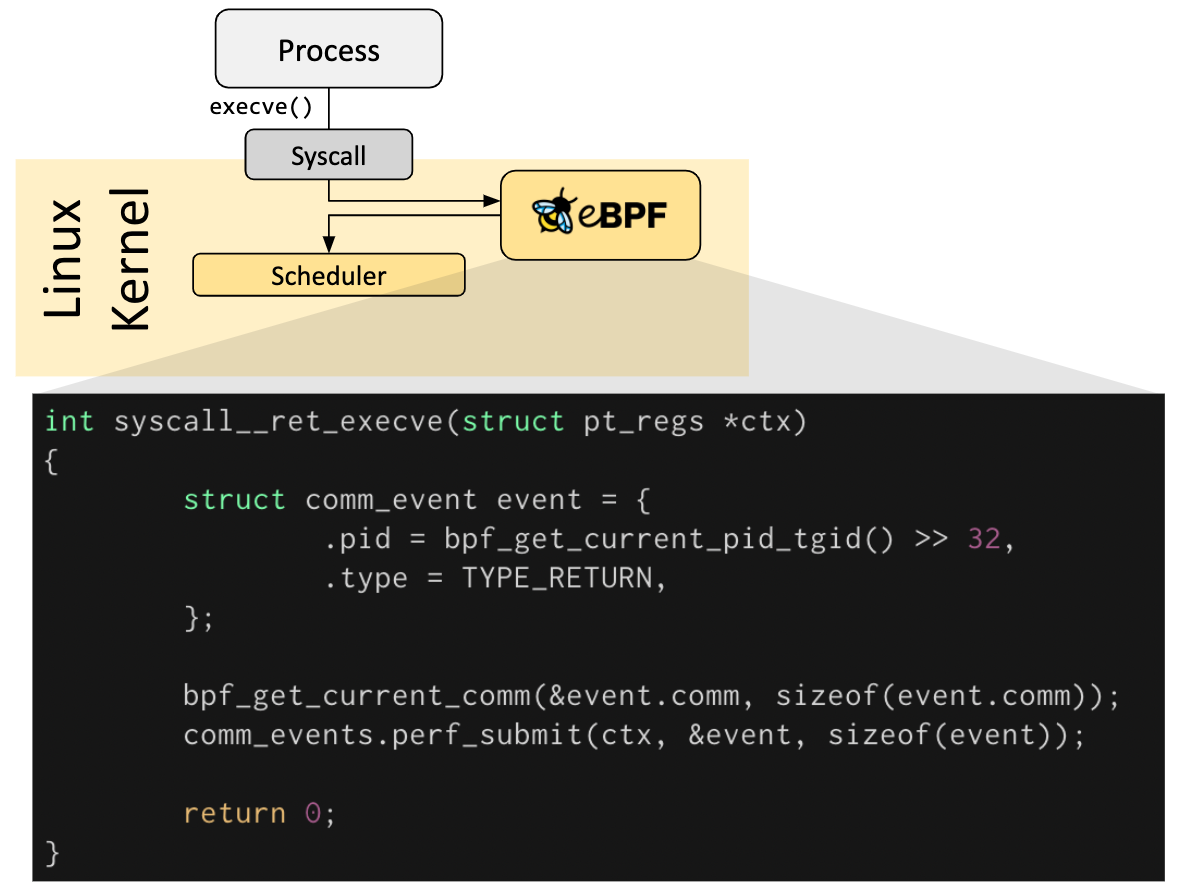
If a Hook point for a specific requirement does not exist, you can mount the eBPF program almost anywhere in the kernel or user program by using kprobe or uprobe.
Verification
With great power there must also come great responsibility.
Every eBPF program loaded into the kernel is subject to Verification, which is used to ensure the security of eBPF programs, mainly by.
-
the process that loads the eBPF program has the necessary privilege level, unless the node has the
unpriviledgedfeature enabled, so that only privileged programs can load eBPF programs-
The kernel provides a configuration item
/proc/sys/kernel/unprivileged_bpf_disabledto disable the use of thebpf(2)system call by unprivileged users, which can be changed with thesysctlcommand -
A special feature is that this configuration item is designed as a one-time kill switch, which means that once it is set to
1, there is no way to change it to0unless you restart the kernel -
Once set to
1, only processes with theCAP_SYS_ADMINprivilege in their initial namespace can call thebpf(2)system call. Cilium will also set this configuration item to 1 when it starts.1$ echo 1 > /proc/sys/kernel/unprivileged_bpf_disabled
-
-
To ensure that eBPF programs do not crash or make the system malfunction.
-
Make sure that eBPF programs cannot get stuck in a dead loop and can
runs to completion. -
Ensure that eBPF programs must meet system requirements for size, and that oversized eBPF programs are not allowed to be loaded into the kernel.
-
To ensure that eBPF programs are of limited complexity,
Verifierwill evaluate all possible execution paths of eBPF programs and must be able to complete the eBPF program complexity analysis in a limited time.
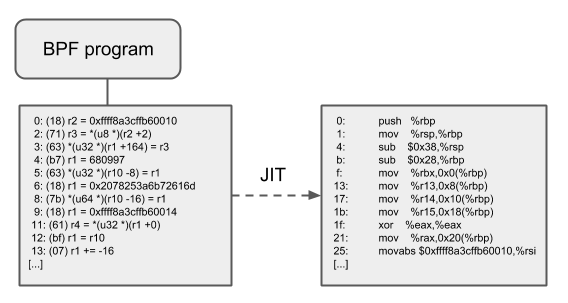
JIT Compilation
Just-In-Time(JIT) compilations are used to translate generic eBPF bytecode into machine-relevant instruction sets, thereby greatly accelerating the execution of BPF programs.
- They reduce the per-instruction overhead compared to interpreters. Typically, instructions can be mapped 1:1 to the underlying architecture’s native instructions.
- This also reduces the size of the generated executable image and is therefore more friendly to the CPU’s instruction cache.
- In particular, for the CISC instruction set (e.g.
x86), JIT makes a number of special optimizations aimed at generating the shortest possible opcode for a given instruction, in order to reduce the space required for the program translation process.
The 64-bit x86_64, arm64, ppc64, s390x, mips64, sparc64 and 32-bit arm, x86_32 architectures all have built-in in-kernel eBPF JIT compilers, which are all functionally identical and can be opened in the following way.
|
|
The 32-bit mips, ppc, and sparc architectures currently have a built-in cBPF JIT compiler. These architectures that only have a cBPF JIT compiler, and those that do not even have a BPF JIT compiler at all, require an in-kernel interpreter to execute eBPF programs.
To determine which platforms support the eBPF JIT, grep HAVE_EBPF_JIT in the kernel source file.
|
|
Maps
BPF Maps are efficient Key/Value stores that reside in kernel space** and contain multiple types of maps that are implemented by the kernel.
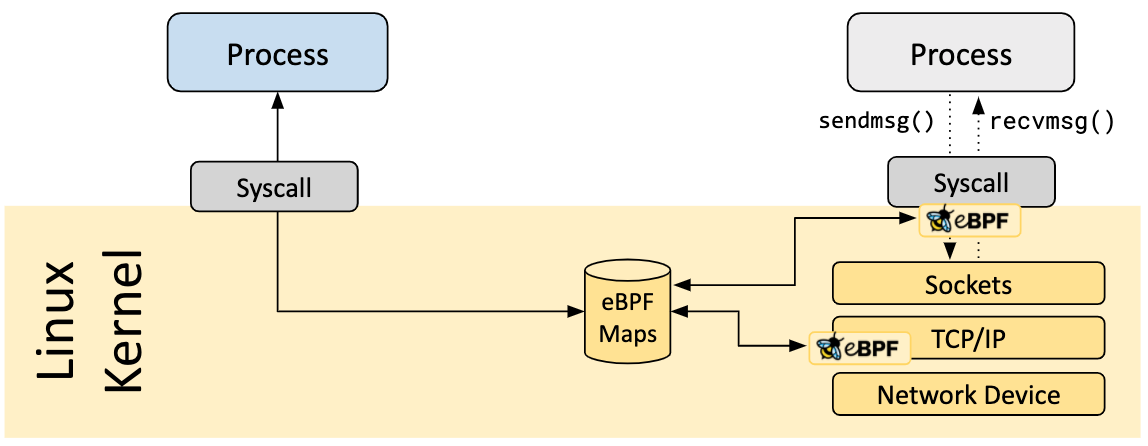
The interaction scenarios of BPF Map are as follows.
- Interaction between a BPF program and a user-state program: After the BPF program is run, the results obtained are stored in the map for the user-state program to access via file descriptors.
- Interaction between BPF programs and kernel programs: Interaction with kernel programs other than BPF programs can also use map as an intermediary.
- Interaction between BPF programs: If a BPF program needs to interact with global variables internally, but for security reasons BPF programs are not allowed to access global variables, you can use map to act as a global variable.
- BPF Tail call: Tail call is a jump from one BPF program to another BPF program. The BPF program first knows the pointer to the other BPF program by using a map of type
BPF_MAP_TYPE_PROG_ARRAY, and then calls the helper function oftail_call()to execute Tail call.
BPF programs that share maps are not required to be of the same program type; for example, tracing programs can share maps with network programs, and a single BPF program can currently directly access up to 64 different maps.
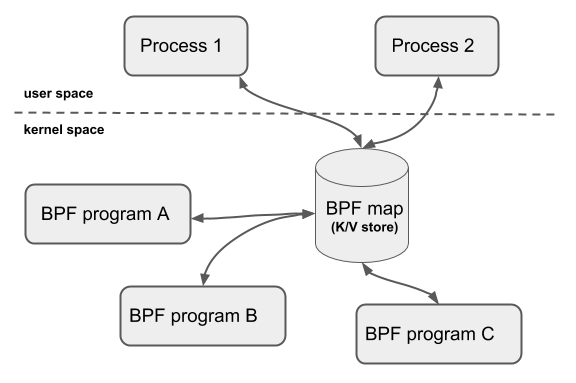
The currently available generic maps are.
BPF_MAP_TYPE_HASHBPF_MAP_TYPE_ARRAYBPF_MAP_TYPE_PERCPU_HASHBPF_MAP_TYPE_PERCPU_ARRAYBPF_MAP_TYPE_LRU_HASHBPF_MAP_TYPE_LRU_PERCPU_HASHBPF_MAP_TYPE_LPM_TRIE
The above maps all use the same set of BPF helper functions to perform lookup, update, or delete operations, but each implements a different backend, each with different semantics and performance characteristics. As multi-CPU architectures matured, BPF Map also introduced per-cpu types such as BPF_MAP_TYPE_PERCPU_HASH, BPF_MAP_TYPE_PERCPU_ARRAY, etc. When you use this type of BPF Map, each CPU stores and sees its own Map data, and the data belonging to different CPUs are isolated from each other. This has the advantage of being more efficient and better performance when performing lookup and aggregation operations. This is especially true if your BPF program is primarily doing collection of time series type data such as traffic data or metrics, etc.
The current non-generic maps in the kernel are.
BPF_MAP_TYPE_PROG_ARRAY: an array map to hold other BPF programs.BPF_MAP_TYPE_PERF_EVENT_ARRAY.BPF_MAP_TYPE_CGROUP_ARRAY: an array to check the cgroup2 member information in skb.BPF_MAP_TYPE_STACK_TRACE: used to store the MAP of the stack trace.BPF_MAP_TYPE_ARRAY_OF_MAPS: holds (holds) pointers to other maps so that the whole map can be replaced atomically at runtime.BPF_MAP_TYPE_HASH_OF_MAPS: holds pointers to other maps so that the entire map can be replaced atomically at runtime.
Helper Calls
eBPF programs cannot call kernel functions at will; to do so would cause the eBPF program to be bound to a specific kernel version, instead it has a set of kernel-defined Helper functions. Helper functions enable BPF to query data from the kernel or push data to the kernel through a set of kernel-defined stable function calls. All BPF helper functions are part of the core kernel and cannot be extended or added to via kernel modules . There are currently dozens of BPF helper functions available, and the number is growing. You can see the current Linux support for Helper functions at Linux Manual Page: bpf-helpers.

The helper functions that can be used by different types of BPF programs may be different , e.g:
- A BPF program that attaches to a socket can call only a subset of the helper functions that the former can call, compared to a BPF program that attaches to the tc layer.
- The wrapped and unwrapped helper functions used by
lightweight tunnelingcan only be used by the lower tc layer, while the event output helper functions used by push notifications to the user state can be used by both tc and XDP programs.
All helper functions share the same generic, system call-like function method, which is defined as follows.
|
|
The kernel abstracts the helper functions into BPF_CALL_0() to BPF_CALL_5() macros, similar in form to the corresponding type of system calls. The definition of these macros can be found in include/linux/filter.h. Take bpf_map_update_elem for example, you can see that it updates the map element by calling the callback function of the corresponding map.
|
|
This approach has a number of advantages.
Although cBPF allows its load instructions to perform out-of-scope accesses (overload) in order to fetch data from a seemingly impossible packet offset to wake up a multifunction helper function, each cBPF JIT still needs to implement the corresponding support for this cBPF extension. In eBPF, however, the JIT compiler compiles the newly added helper functions in a transparent and efficient manner, meaning that the JIT compiler only needs to emit a call instruction because the register mapping is such that the BPF assignments already match the underlying architecture’s calling conventions. matches the underlying architecture’s calling conventions. This makes it very easy to extend the core kernel with helper functions. All BPF helper functions are part of the core kernel and cannot be extended or added via the kernel module .
The function signatures mentioned above also allow the verifier to perform type check. The
struct bpf_func_protoabove holds all the information that the checker needs to know about the helper function so that the checker can ensure that the expected type of the helper function matches the current contents of the BPF program registers.The parameter types range from arbitrary values to restrictions to specific types, such as the
pointer/sizeparameter pair of the BPF stack buffer, from which the helper function can read data or write data to. For this case, the verifier can also perform additional checks, for example, whether the buffer has been initialized.
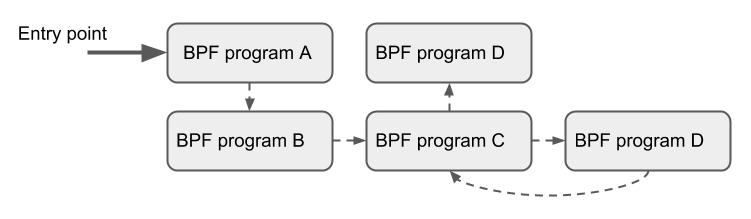
Tail Calls
Tail calls are a mechanism by which a BPF program can call another BPF program and not return to the original program when the call is complete.
- This call has minimal overhead compared to a normal function call, because it is implemented with a long jump, reusing the original stack frame.
- BPF programs are independently verified, so to pass state, either use the per-CPU map as a scratch buffer or, in the case of tc programs, some fields of
skb(e.g.cb[]). - Only programs of the same type can tail-call and they have to match the JIT compiler, so either the JIT compiler executes or the interpreted programs, but not both.
BPF to BPF Calls
In addition to BPF helper functions and BPF tail calls, a new feature has recently been added to the BPF core infrastructure: BPF to BPF calls. Before this feature was introduced to the kernel, a typical BPF C program had to take special care of all code that needed to be reused. For example, it was declared as always_inline in the header file . When LLVM compiles and generates the BPF object file, all of these functions will be inlined, and therefore repeated multiple times in the generated object file, resulting in code size bloat.
|
|
This is necessary because of the lack of support for function calls in the BPF program loader, verifier, interpreter and JIT. Starting with Linux 4.16 and LLVM 6.0, this limitation has been addressed and BPF programs no longer need to use the always_inline declaration everywhere. As a result, the above code can be more naturally rewritten as:
|
|
The BPF-to-BPF call is an important performance optimization that greatly reduces the size of the generated BPF code and is therefore more friendly to the CPU instruction cache (i-cache) .
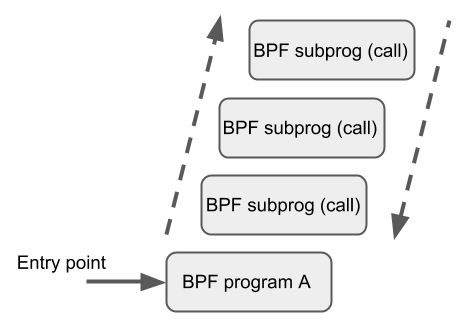
The BPF helper function calling convention also applies to BPF inter-function calls: * r1 - r5 is used to pass parameters.
-
r1-r5are used to pass arguments and return results tor0. -
r1-r5are scratch registers,r6-r9are reserved registers as usual. -
The maximum nested call depth is
8. -
The caller can pass a pointer (e.g., a pointer to the caller’s stack frame) to the callee, but not vice versa.
-
Currently, BPF inter-function calls and BPF tail calls are incompatible** because the latter require reusing the current stack setup, while the former add an extra stack frame and thus do not conform to the desired layout of tail calls.
The BPF JIT compiler emits separate images for each function body, and later modifies the address of the function call in the image in the final JIT pass. It has been shown that this approach requires minimal modification to the various JITs because they can be implemented to treat BPF inter-function calls as regular BPF helper function calls.
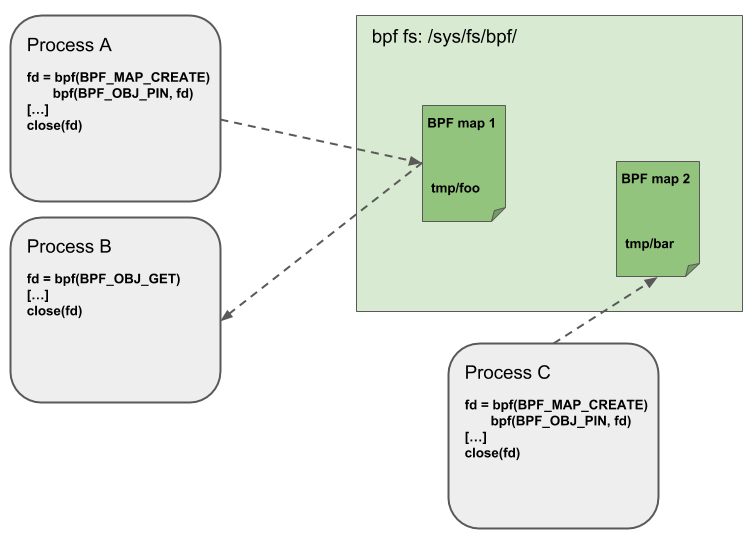
Object Pinning
BPF maps and programs can only be accessed as kernel resources via file descriptors behind anonymous inodes in the kernel. This brings a number of advantages.
- User-space applications can use most of the file descriptor-related APIs.
- File descriptors passed to Unix sockets work transparently, etc.
But at the same time, file descriptors are limited by the process lifecycle, making operations like map sharing very unwieldy, which introduces a lot of complexity in some specific scenarios.
For example, iproute2, where the tc or XDP eventually exits after preparing the environment and loading the program into the kernel. In this case, the maps are also not accessible from user space, when they would be useful. For example, the maps shared in the ingress and egress locations of the data path (which can count packets, bytes, PPS, etc.). In addition, third-party applications may want to monitor or update maps while the BPF program is running.
To solve this problem, the kernel implements a minimum kernel space BPF file system into which BPF maps and BPF programs can be pinned, a process called object pinning. The BPF-related file system is not singleton, it supports multiple mounted instances, hard links, soft It supports multiple mounted instances, hard links, soft links, and so on.
Accordingly, the BPF system call is extended with two new commands, as shown below.
BPF_OBJ_PIN: pin an object.BPF_OBJ_GET: Get a pinned object.
Hardening
Protection Execution Protection
To avoid code corruption, BPF locks the entire image after interpretation by the BPF interpreter (struct bpf_prog) and the image after JIT compilation (struct bpf_binary_header) as read-only in the kernel for the lifetime of the program. Any data corruption in these locations (e.g., due to some kernel bug) triggers the generic protection mechanism and therefore causes the kernel to crash rather than allowing the corruption to occur silently.
To see which platforms support setting image memory to read-only, you can use the following search.
The CONFIG_ARCH_HAS_SET_MEMORY option is not configurable, so platforms either have built-in support or they don’t, and those architectures that don’t currently support it may do so in the future.
Mitigation Against Spectre
To defend against the Spectre v2 attack, the Linux kernel provides the CONFIG_BPF_JIT_ALWAYS_ON option, which, when turned on BPF interpreter will be completely removed from the kernel and the JIT compiler will be enabled forever.
- If applied in a VM-based environment, the client kernel will not reuse the kernel’s BPF interpreter, thus avoiding certain related attacks.
- In the case of a container-based environment, this configuration is optional, and if the JIT feature is turned on, the interpreter may still be removed at compile time to reduce the complexity of the kernel.
- For JIT on mainstream architectures (e.g.
x86_64andarm64) it is usually recommended to turn this switch on.
Setting /proc/sys/net/core/bpf_jit_harden to 1 will do some additional hardening for unprivileged user JIT compilations. These additional hardenings will slightly degrade the performance of the program, but are effective in reducing the potential attack surface in the event that a non-trusted user is operating on the system. Still, these performance losses are relatively small compared to switching to an interpreter altogether. For the x86_64 JIT compiler, if CONFIG_RETPOLINE is set, indirect jumps for tail calls are implemented with retpoline. At the time of writing this article, this configuration is turned on in most modern Linux distributions.
Constant Blinding
Currently, enabling hardening blind all user-supplied 32- and 64-bit constants in BPF programs at JIT compile time to defend against JIT spraying attacks that inject native opcodes into the kernel as immediate numbers. This attack is effective because: immediate numbers reside in executable kernel memory, so some kernel bugs may trigger a jump action that, if it jumps to the start of immediate numbers, will start executing them as native instructions.
Blinded JIT constants are implemented by randomizing the actual instruction. In this approach, the original immediate-based operation is converted to a register-based operation by rewriting the instruction. Instruction rewriting breaks down the process of loading a value into two parts.
- load a blinded (immediate) number
rnd ^ imminto a register - perform an iso-or operation (xor) on the register and
rnd.
This way the original imm immediate resides in the register and can be used for real operations. What is described here is only the blinded process of the load operation, in fact all general-purpose operations are blinded. The following is the result of a JIT compilation of a program with reinforcement turned off.
|
|
The result of the above program being loaded by a non-privileged user via BPF after the hardening has been opened (constant blinding has been performed here).
|
|
The two programs are semantically identical, but in the second way, the original immediate count is no longer visible in the program after disassembly. Also, the hardening disables any JIT kernel compliance (kallsyms) from being exposed to privileged users, and the JIT image address no longer appears in /proc/kallsyms.
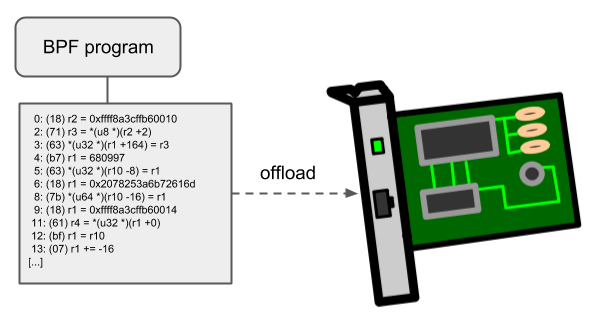
Offloads
BPF network programs, especially tc and XDP BPF programs, have an offload to hardware interface in the kernel so that BPF programs can be executed directly on the NIC.
Currently, Netronome’s nfp driver supports offload BPF via the JIT compiler, which translates BPF instructions into the instruction set implemented by the NIC. In addition, it also supports offloading BPF maps to the NIC, so offloaded BPF programs can perform map lookup, update, and delete operations.
eBPF interface
BPF System Call
eBPF provides the bpf() system call to operate on BPF Map or program with the following function prototype.
function has three arguments, of which.
cmdspecifies the type of command to be executed by the bpf system call, and each cmd is accompanied by a parameterattrbpf_attr unionallows data to be passed between kernel and user space, the exact format depends on thecmdparameter- The
sizeparameter indicates the size of thebpf_attr unionobject in bytes
The cmd can be of the following types, which can be basically divided into two types: manipulating an eBPF Map and manipulating an eBPF program.
BPF_MAP_CREATE: creates aneBPF Mapand returns a file descriptor pointing to the MapBPF_MAP_LOOKUP_ELEM: finds an element in a Map by its key and returns its valueBPF_MAP_UPDATE_ELEM: creates or updates an element key/value pair in a MapBPF_MAP_DELETE_ELEM: Deletes an element in a Map based on keyBPF_MAP_GET_NEXT_KEY: Find an element in a Map based on key and return the key of the next elementBPF_PROG_LOAD: checks and loads an eBPF program, returning the file descriptor associated with the program- …
The structure of the bpf_attr union is shown below, which can be populated with different information depending on the cmd.
|
|
Commands for using eBPF programs
The BPF_PROG_LOAD command is used to verify and load the eBPF program with the filled parameter bpf_xattr, which is shown below in libbpf bpf_load_program in libbpf, you can see that the bpf system call is eventually called.
|
|
Implementation of bpf_map_lookup_elem in libbpf.
Implementation of bpf_map_update_elem in libbpf.
|
|
Implementation of bpf_map_delete_elem in libbpf.
Implementation of bpf_map_get_next_key in libbpf.
Note that the libbpf functions here are not quite the same as the helper functions mentioned before, you can see the current Linux supported Helper functions at Linux Manual Page: bpf-helpers to see the current Helper functions supported by Linux. Take bpf_map_update_elem as an example, the eBPF program calls the helper function with the following parameters.
|
|
The first argument here comes from the bpf_map created by the SEC(".maps") syntactic sugar.
For a user-state program, the function prototype is as follows, where the eBPF map is accessed via fd.
|
|
BPF Program Types
The program type loaded by the function BPF_PROG_LOAD specifies four things.
- Where the program can be attached.
- Which helper functions in the kernel are allowed to be called by the validator.
- Whether data from network packets can be accessed directly.
- The type of object passed to the program as the first argument.
In fact, the program type essentially defines an API. even new program types are created to distinguish between the different lists of functions allowed to be called (e.g. BPF_PROG_TYPE_CGROUP_SKB versus BPF_PROG_TYPE_SOCKET_FILTER).
The bpf program is hooked to different hook points in the kernel. Different hook points have different entry parameters and different capabilities. Different prog types are defined, and the set of kernel functions that can be called by bpf programs with different prog types is also different. When a bpf program is loaded into the kernel, the kernel verifier program checks which helper functions are called based on the entry parameters of the program according to the bpf prog type.
The list of eBPF program types currently supported by the kernel is shown below.
BPF_PROG_TYPE_SOCKET_FILTER: a network packet filterBPF_PROG_TYPE_KPROBE: Determines whether kprobe should be triggeredBPF_PROG_TYPE_SCHED_CLS: a network traffic control classifierBPF_PROG_TYPE_SCHED_ACT: a network traffic control actionBPF_PROG_TYPE_TRACEPOINT: Determines whether a tracepoint should be triggeredBPF_PROG_TYPE_XDP: a network packet filter that runs in the receive path from the device driverBPF_PROG_TYPE_PERF_EVENT: Determines if the perf event handler should be triggeredBPF_PROG_TYPE_CGROUP_SKB: a network packet filter for control groupsBPF_PROG_TYPE_CGROUP_SOCK: a network packet filter for control groups that is allowed to modify socket optionsBPF_PROG_TYPE_LWT_*: a network packet filter for lightweight tunnelsBPF_PROG_TYPE_SOCK_OPS: a program for setting socket parametersBPF_PROG_TYPE_SK_SKB: a network packet filter for forwarding packets between socketsBPF_PROG_CGROUP_DEVICE: Determines whether device operations are allowed
As new program types are added, kernel developers also find the need to add new data structures.
For example, which bpf helper function can be accessed by the BPF_PROG_TYPE_SCHED_CLS bpf prog? Let’s see how the source code implements this.
Each prog type defines a struct bpf_verifier_ops structure. When a prog is loaded into the kernel, the kernel calls the get_func_proto function of the corresponding structure, depending on its type.
For BPF codes of type BPF_PROG_TYPE_SCHED_CLS, the verifier calls tc_cls_act_func_proto to check if all the helper functions called by the program are legitimate.
BPF code call timing
Each prog type has a different timing.
BPF_PROG_TYPE_SCHED_CLS
BPF_PROG_TYPE_SCHED_CLS is called as follows.
Egress direction
In the egress direction, after the tcp/ip stack is running, there is a hook point. This hook point can attach the BPF_PROG_TYPE_SCHED_CLS type of bpf prog in the egress direction. After this bpf code is executed, the qos, tcpdump, and xmit to NIC driver code will be run. In this bpf code you can modify the contents of the message, the address, etc. After the changes are made, you can see them through tcpdump, because the tcpdump code is executed after that.
Ingress direction
There is a hook point in the ingress direction, before deliver to the tcp/ip stack and after tcpdump. This hook point can attach BPF_PROG_TYPE_SCHED_CLS type of bpf prog in ingress direction. Here you can also modify the message. But the result of the modification is not visible in tcpdump.
|
|
execution portal cls_bpf_classify
The real entry point for executing the bpf instruction, regardless of egress or ingress direction, is cls_bpf_classify. It traverses the bpf prog link list in tcf_proto and executes BPF_PROG_RUN(prog->filter, skb) for each bpf prog.
|
|
BPF_PROG_RUN executes the bpf instruction for JIT compile, or if the kernel does not support JIT, it calls the interpreter to execute the byte code for bpf.
The entry parameter that BPF_PROG_RUN passes to bpf prog is skb, whose type is struct sk_buff , defined in the file include/linux/skbuff.h.
But in the bpf code, you cannot access sk_buff directly for security reasons. bpf accesses struct sk_buff by accessing struct __sk_buff. __sk_buff is a subset of sk_buff and is the interface to the sk_buff-oriented bpf program. accesses to __sk_buff in bpf code are translated in the verifier program into accesses to the corresponding fileds of sk_buff.
When loading the bpf prog, the verifier calls the hook of tc_cls_act_convert_ctx_access inside the tc_cls_act_verifier_ops structure above. It will eventually call the following function to modify the ebpf directive so that the access to __sk_buff becomes an access to struct sk_buff.
BPF Attach type
A type of bpf prog can be attached to different hooks in the kernel, and these different hooks are different attach types.
The correspondence is defined in the following function.
|
|
When a bpf prog attaches to a specific hook point via the bpf() system call, the attach type needs to be specified in its entry parameter.
Interestingly, bpf prog of type BPF_PROG_TYPE_SCHED_CLS cannot attach via the bpf system call because it does not have a corresponding attach type defined, so its attachment requires an additional implementation via the netlink interface, which is still very complicated.
Introduction to common prog types
There are currently 30 types of prog types in the kernel. Each type can do different things, so I will only talk about the ones I usually use for work.
The best way to understand a prog type is to
- look up the attach_type_to_prog_type table and get its attach type.
- then search the kernel code to see where these attach types are called in the kernel.
- Finally, look at its entry parameters and return value handling to basically understand what it does.
BPF_PROG_TYPE_SOCKET_FILTER
is the first program type to be added to the kernel. When you attach a bpf program to a socket, you get access to all packets that are processed by the socket. socket filtering does not allow you to modify these packets and their destinations. It only provides you with the ability to observe these packets. In your program you can get things like the protocol type.
In tcp for example, the call is made from tcp_v4_rcv->tcp_filter->sk_filter_trim_cap to filter packets, or trim packets. udp, icmp also have related calls.
BPF_PROG_TYPE_SOCK_OPS
The bpf hook, called when a tcp protocol event occurs, defines 15 types of events. The attach type of these events is BPF_CGROUP_SOCK_OPS. Different enum is passed in at different call points, for example
- BPF_SOCK_OPS_TCP_CONNECT_CB is for the active tcp connect call.
- BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB is called on passive connect success.
Main functions: tcp tuning, event statistics, etc.
BPF_PROG_TYPE_SOCK_OPS This program type allows you to modify the link options of a socket when packets are transmitted at various stages of the kernel network stack. They attach to cgroups much like BPF_PROG_TYPE_CGROUP_SOCK and BPF_PROG_TYPE_CGROUP_SKB, but the difference is that they can be called several times throughout the life of the connection. Your bpf program receives an op argument that represents the operation that the kernel will perform over the socket link. Therefore, you know when to call the program during the lifetime of the link. On the other hand, you can get the ip address, port, etc. You can also modify the link’s link options to set the timeout and change the packet round-trip delay time.
As an example, Facebook uses it to set a short recovery time objective (RTO) for connections within the same data center.RTO is a time that refers to the recovery time of the network after a failure, a metric that also indicates how long the network is unavailable in case of unacceptable conditions.Facebook believes that there should be a very short RTO, Facebook modified this time to use the bpf procedure.
BPF_PROG_TYPE_CGROUP_SOCK_ADDR
It corresponds to many attachment types, usually called when bind, connect, pass in the address of the sock.
The main role: for example, the implementation of clusterip in cilium, in the active connect, modified the destination ip address, is to use this.
BPF_PROG_TYPE_CGROUP_SOCK_ADDR, this type of program allows you to manipulate IP addresses and port numbers in userspace programs controlled by a specific cgroup. In some cases, the system will use multiple IP addresses when you want to ensure that a specific set of userspace programs use the same IP address and port. These BPF programs give you the flexibility to manipulate these bindings when you place these userspace programs in the same cgroup. This ensures that all incoming and outgoing connections to these applications use the IP and port provided by the BPF program.
BPF_PROG_TYPE_SK_MSG
BPF_PROG_TYPE_SK_MSG, These types of programs let you control whether a message sent to a socket should be delivered. When the kernel creates a socket, it is stored in the map mentioned earlier . When you attach a program to this socket map, all messages sent to those sockets are filtered. Before filtering the message, the kernel copies the data, so you can read the messages and give your decision: for example, SK_PASS and SK_DROP.
BPF_PROG_TYPE_SK_SKB
Call point: called when tcp sendmsg.
Main purpose: for sock redir.
BPF_PROG_TYPE_SK_SKB, this kind of program allows you to get socket maps and socket redirects. socket maps allows you to get some references to sockets. When you have these references, you can use the associated helpers to redirect an incoming packet from one socket to another scoket. You can forward network packets between sockets without leaving the kernel space, and Cillium and Facebook’s Katran use this type of program extensively for traffic control.
BPF_PROG_TYPE_CGROUP_SOCKOPT
Call points: getsockopt, setsockopt.
BPF_PROG_TYPE_KPROBE
Similar to ftrace’s kprobe, at the hook point of the function entry/exit, used for debug.
BPF_PROG_TYPE_TRACEPOINT
Similar to ftrace’s tracepoint.
BPF_PROG_TYPE_SCHED_CLS
As in the example above.
BPF_PROG_TYPE_XDP
A hook point before the sk_buff data structure is generated when the NIC driver receives the packet.
BPF_PROG_TYPE_XDP allows your bpf program to do this very early in the network packet’s arrival at the kernel. In such a bpf program, you may get just a little bit of information because the kernel has not had enough time to process it. Because it’s early enough, you can process these packets at a very high level of the network.
XDP defines a number of ways to handle this, for example
- XDP_PASS means that you will pass the packet to another subsystem of the kernel to handle.
- XDP_DROP means that the kernel should discard the packet.
- XDP_TX means that you can forward this packet to the network interface card (NIC) the first time it receives it.
BPF_PROG_TYPE_CGROUP_SKB
BPF_PROG_TYPE_CGROUP_SKB allows you to filter the network traffic for the entire cgroup. In this program type, you can do some control over the network traffic before it reaches the programs in this cgoup. Any packet that the kernel tries to pass to any process in the same cgroup will pass through one of these filters. Also, you can decide what processes in the cgroup should do when sending network packets through this interface. In fact, you can find it very similar in type to BPF_PROG_TYPE_SOCKET_FILTER. The biggest difference is that cgroup_skb is attaching to all processes in this cgroup, not a special process. In a container environment, bpf is very useful.
- ingress direction, tcp calls this bpf to do filtering when it receives a message (tcp_v4_rcv).
- In the egress direction, ip calls it to do packet loss filtering on outgoing packets (ip_finish_output) The input parameter is skb.
BPF_PROG_TYPE_CGROUP_SOCK
Called on sock create, release, post_bind. It is mainly used to do some permission checking.
BPF_PROG_TYPE_CGROUP_SOCK, this type of bpf program allows you to execute your bpf program when any process in a cgroup opens a socket. This behavior is similar to the behavior of CGROUP_SKB, but it is provided to you when a process in a cgoup opens a new socket, rather than giving you permission control for network packets to pass through. This is useful for providing security and access control for groups of programs that can open sockets without having to restrict the functionality of each process separately.
eBPF tool chain
bcc
BCC is a collection of compilation tools for BPF, providing a Python/Lua API on the front-end, implemented in C/C++ itself, and integrated with LLVM/Clang to rewrite, compile and load BPF programs, providing some more user-friendly functions for users to use.
While BCC does its best to simplify the work of BPF program developers, its “black magic” (using the Clang front-end to modify user-written BPF programs) makes it difficult to find problems and solutions when they occur. Naming conventions and automatically generated trace point structures must be remembered. The libbcc library has a large LLVM/Clang library integrated into it, which makes it problematic to use.
- using high CPU and memory resources to compile BPF programs at the start of each tool, which may cause problems when running on a server that is already short of system resources.
- relying on kernel header packages that must be installed on each target host. Even so, if something not exported in the kernel is required, the type definition needs to be manually copied/pasted into the BPF code.
- Since BPF programs are compiled at runtime, many simple compilation errors can only be detected at runtime, which affects the development experience.
With the implementation of BPF CO-RE, we can use the libbpf library provided by kernel developers to develop BPF programs directly, in the same way as writing ordinary C user-state programs: compile once to generate small binaries. libbpf, as the BPF program loader, takes over the functions of redirection, loading, validation, etc., and BPF program developers only need to focus on the correctness and performance of BPF programs. program developer only needs to focus on the correctness and performance of the BPF program. This approach minimizes overhead and removes large dependencies, making the overall development process much smoother.
Brendan Gregg, a performance optimization guru, gives comparative performance data after converting a BCC tool with libbpf + BPF CO-RE.
As my colleague Jason pointed out, the memory footprint of opensnoop as CO-RE is much lower than opensnoop.py. 9 Mbytes for CO-RE vs 80 Mbytes for Python.
We can see that the libbpf + BPF CO-RE version saves nearly 9 times the memory overhead at runtime compared to the BCC version, which is more friendly to servers that are already strapped for physical memory resources.
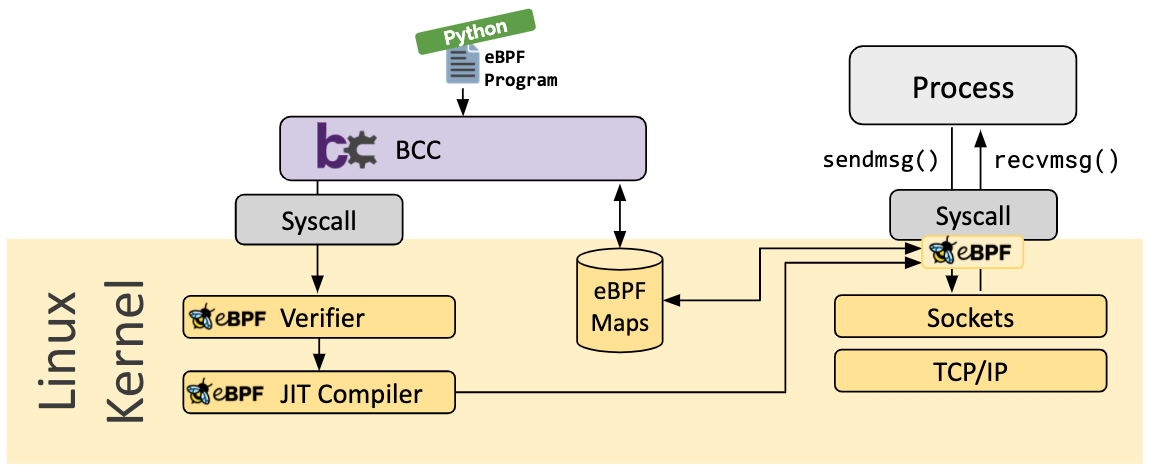
bpftrace
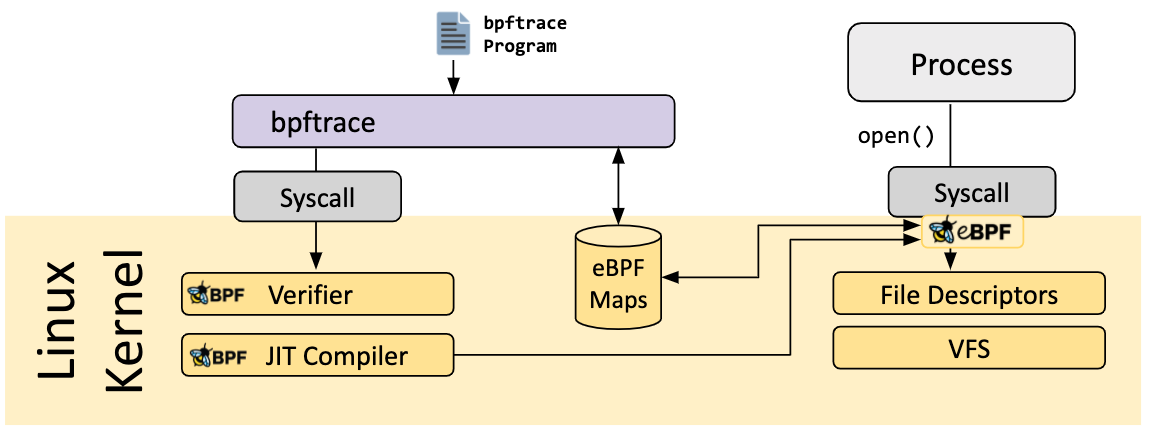
bpftrace is a high-level tracing language for Linux eBPF and available in recent Linux kernels (4.x). bpftrace uses LLVM as a backend to compile scripts to eBPF bytecode and makes use of BCC for interacting with the Linux eBPF subsystem as well as existing Linux tracing capabilities: kernel dynamic tracing (kprobes), user-level dynamic tracing (uprobes), and tracepoints. The bpftrace language is inspired by awk, C and predecessor tracers such as DTrace and SystemTap.
eBPF Go Library
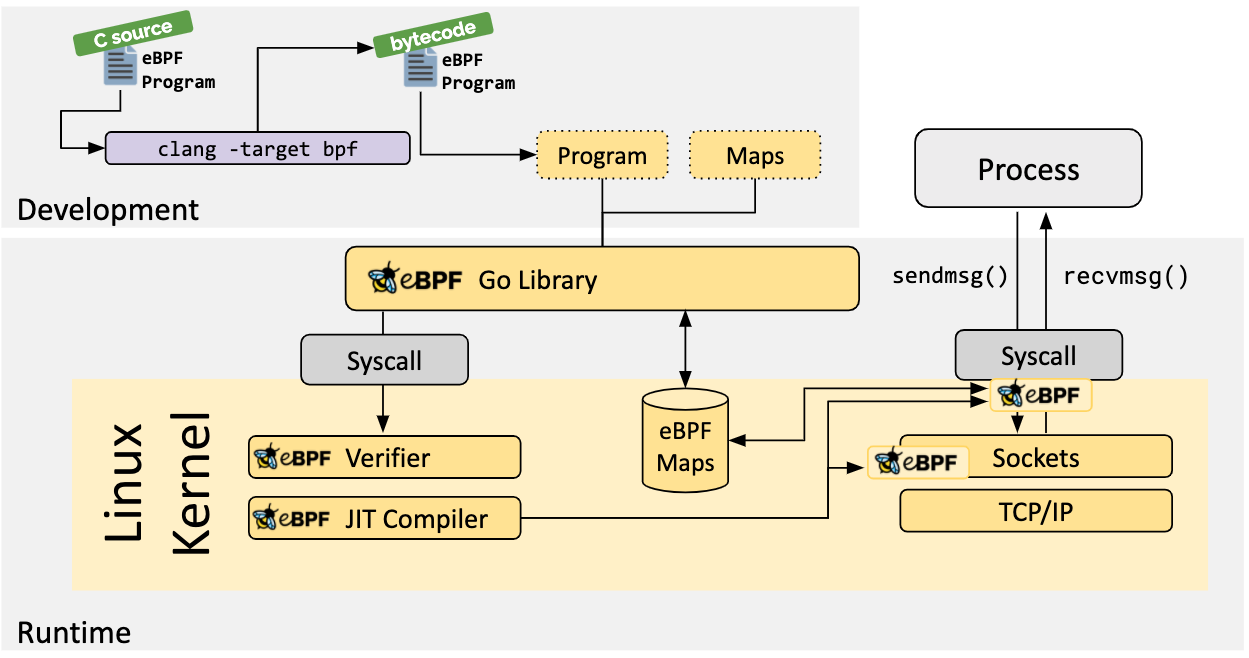
libbpf