sync.Pool is Golang’s built-in object pooling technology, which can be used to cache temporary objects to avoid the consumption and pressure on GC caused by frequent creation of temporary objects.
You can see sync.Pool used extensively in many well-known open source libraries. For example, the HTTP framework Gin uses sync.Pool to reuse the gin.Context object that is created with each request. sync.Pool can also be found in grpc-Go, kubernates, and others.
Note, however, that sync.Pool cached objects can be cleared without notice at any time, so sync.Pool should not be used in scenarios where persistent objects are stored.
The sync.Pool is the official library built into goroutine and is very well designed. sync.Pool is not only concurrency-safe, but also lock free, and there is a lot to learn about it.
This article will explore the underlying implementation of sync.Pool based on the go-1.16 source code.
Basic Usage
Before we talk about the underlying sync.Pool, let’s take a look at the basic usage of sync.Pool. The sample code is as follows.
When sync.Pool is initialized, it requires the user to provide a constructor New for the object. The user uses Get to get the object from the object pool and Put to return the object to the object pool. The entire usage is relatively simple.
Next, let’s take a closer look at how sync.Pool is implemented.
The underlying implementation of sync.Pool
Before we talk about sync.Pool, let’s talk about Golang’s GMP scheduling. In the GMP scheduling model, M represents the system threads, and only one P can be running on an M at the same time, which means that the logic on P is single-threaded from the thread dimension.
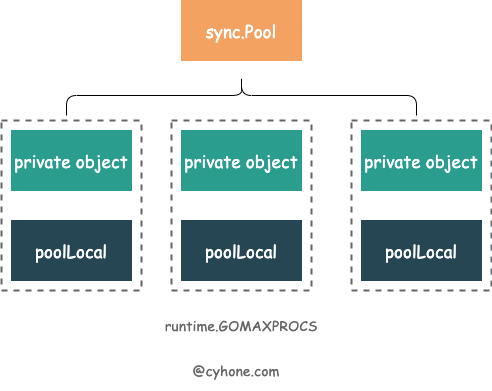
sync.Pool takes advantage of this feature of GMP. For the same sync.Pool, each P has its own local object pool poolLocal. This is shown in the figure below.
The code for sync.Pool is defined as follows sync/pool.go#L44:
|
|
Among them, we need to focus on the following three fields.
localis an array with the length of the number of P’s. Its element type ispoolLocal. This stores the local pool of objects corresponding to each P. It can be approximated as[P]poolLocal.localSize. represents the length of the local array. Since P can be modified at runtime by calling runtime.GOMAXPROCS, we still have to uselocalSizeto correspond to the length of thelocalarray.Newis the user-supplied function that creates the object. This option is also not required. Get may return nil when it is not filled in.
A few other fields that we don’t need to care too much about for now, here’s a quick overview.
victimandvictimSize. This pair of variables represents the pool of objects before the last round of cleanup, with the same semantics local and localSize. victim is described in more detail below.noCopyis a detection method in the Golang source code that disables copying. A copy of a sync.Pool can be detected with thego vetcommand.
Since each P has its own poolLocal, Get and Put operations give priority to accessing the pool. Due to the nature of P, the whole concurrency problem is much simpler when manipulating local object pools, and concurrency conflicts can be avoided as much as possible.
Let’s look at the definition of the local object pool poolLocal, as follows.
The role of the pad variable is covered below and will not be discussed here for now. We can look directly at the definition of poolLocalInternal, where each local object pool contains two items: * private private variables.
privateprivate variables; Get and Put operations give priority to accessing private variables, and do not go deeper than that if the private variables can satisfy the situation.shared. The type is poolChain, and it is easy to see from the name that this is a linked table structure, and this is the local object pool of P.
poolChain implementation
The entire storage structure of poolChain is shown in the following figure.
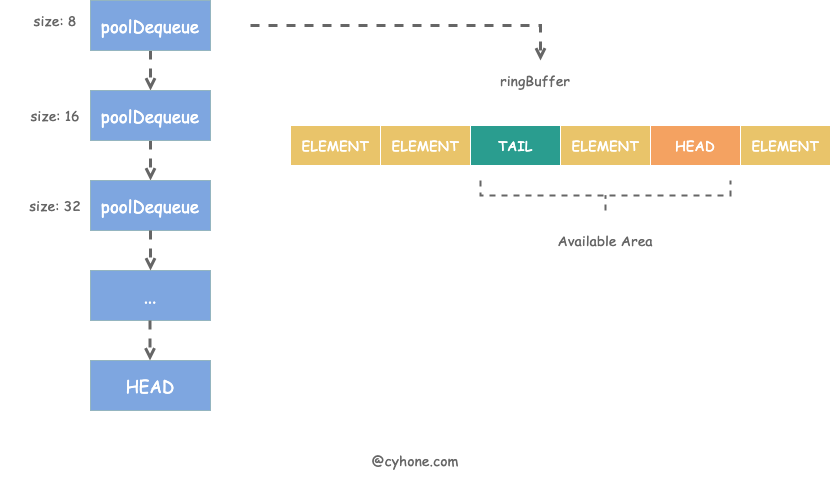
As you can probably guess from the name, a poolChain is a linkedlist structure with the head HEAD pointing to the most recently allocated element item. Each item in the chain is a poolDequeue object. poolDequeue is essentially a ring buffer structure. The corresponding code is defined as follows.
Why is poolChain such a complex structure of a linkedlist + ring buffer? Can’t we simply have a single element for each link table item?
The ring buffer is used because it has the following advantages.
- The memory is pre-allocated and the allocated memory items can be reused over and over again.
- Since ring buffer is essentially an array, it is a contiguous memory structure, which is very convenient for CPU Cache. when accessing an item of poolDequeue, all the data items in its vicinity may be loaded into the unified Cache Line, making access faster.
These two features of the ring buffer are ideal for the sync.
As a ring buffer, poolDequeue naturally needs to record the values of its head and tail. However, in the definition of poolDequeue, head and tail are not separate variables, but only a uint64 headTail variable.
This is because the headTail variable wraps the head and tail together: the high 32 bits are the head variable and the low 32 bits are the tail variable. This is shown in the following figure.

Why this complex packing operation? This is actually a very common lock free optimization.
For a poolDequeue, it may be accessed by more than one P at the same time (see the object-stealing logic in the Get function below), which can cause concurrency problems.
For example, when there is only one ring buffer space left, i.e. head - tail = 1. If multiple P’s access the ring buffer at the same time, without any concurrency measures, both P’s may get the object, which is definitely not expected.
How does sync.Pool achieve this without introducing Mutex locks? sync.Pool makes use of the CAS operation in the atomic package. Both P’s may get the object, but when the headTail is finally set, only one P will call CAS successfully and the other CAS will fail.
|
|
When updating head and tail, the operation is also performed with atomic variables + bitwise operations. For example, when implementing head++, the following code is needed.
Implementation of Put
Let’s look at the implementation of the Put function. The Put function allows us to put unused objects back or forward into the sync.Pool.The code logic of the Put function is as follows.
As you can see from the above code, pin() is called first in the Put function. The pin function is very important, it has three functions.
-
Initialize or recreate the local array. When the local array is empty, or does not match the current
runtime.GOMAXPROCS, it triggers a re-creation of the local array to match the number of P’s. ** When the local array is empty, or does not match the current `runtime. -
The logic of the code is very simple: it takes the elements from the local array based on the index. The logic of this paragraph is as follows.
-
Prevents the current P from being preempted. This is very important. Since Go 1.14, Golang has implemented preemptive scheduling: a goroutine will be forced to hang by the scheduler if it occupies P for too long. If a goroutine is hung during a Put or Get, it is possible that the next time it is restored, the binding will not be the same P as the last one. Then the whole process will be completely messed up. Therefore, procPin from the runtime package is used here to temporarily disallow P to be preempted.
Next, the Put function will set the current poolLocal private variable private as a preference. If the private variable is set successfully, then it will not write to the shared cache pool. This makes the operation more efficient.
If the private variable has already been set, then it will only write to the poolChain of the current P’s local cache pool. Next, let’s see how the internal cache poolChain of each P of sync.Pool is implemented.
When putting, it will directly fetch the head element of the poolChain’s chain, HEAD.
- If HEAD does not exist, a new poolDequeue with buffer length 8 is created and the object is placed in it.
- If HEAD exists and the buffer is not full, the element will be placed in the poolDequeue directly.
- If the HEAD exists but the buffer is full, create a new poolDequeue with 2 times the length of the previous HEAD. At the same time, the HEAD of the poolChain is pointed to the new element.
The process of Put is relatively simple, the whole process does not need to interact with other P’s poolLocal.
Implementation of Get
After understanding how Put is implemented, let’s move on to the Get implementation. The Get operation allows you to get an object from a sync.Pool.
Compared to the Put function, the Get implementation is more complex. Not only does it involve manipulating the local object pool of the current P, but it also involves stealing objects from the local object pools of other P’s. The code logic is as follows. The code logic is as follows.
The role of pin() and the role of the private object are the same as in the PUT operation, so we won’t go over them here. Let’s focus on the rest of the logic.
First, the Get function tries to fetch an object from the poolChain of the current P’s local object pool. When fetching data from the current P’s poolChain, the data is fetched from the head of the chain. Specifically, the poolDequeue at the head of the chain is fetched first, and then the data is fetched from the head of the poolDequeue.
If no data is fetched from the current P’s poolChain, it means that the current P’s cache pool is empty, so it will try to steal objects from other P’s cache pools. This also corresponds to the internal implementation of the getSlow function.
In the getSlow function, the index value of the current P is incremented to try to fetch data from the poolChain of other P’s one by one. Note that when trying to fetch data from other P’s poolChain, it starts at the end of the chain.
When popTail is called on the poolChain of other P, the poolDequeue at the end of the chain is fetched first, and then the data is fetched from the end of the poolDequeue. If no data is fetched from this poolDequeue, it means that the poolDequeue is empty, and the poolDequeue is removed from the poolChain directly, and the next poolDequeue is tried.
If the data is not fetched from the local object pool of other P, it is also not fetched. Next, it tries to fetch data from victim. As mentioned above, victim is a pool of objects that was cleaned in the previous round, and fetching objects from victim is the same way as popTail.
Finally, if all the cache pools are out of data, the user-set New function is called to create a new object.
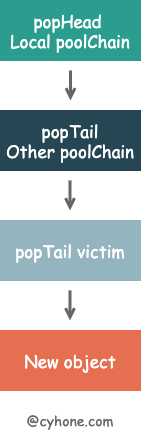
sync.Pool is designed to start from the head when manipulating the local poolChain, either push or pop. And when fetching data from other P’s poolChain, only the tail popTail can be fetched. This minimizes concurrency conflicts.
Object cleanup
sync.Pool does not have an object cleanup policy or cleanup interface open to the public. As we mentioned above, when stealing objects from other P’s, the empty poolDequeue will be phased out, but in addition, the sync.Pool must also have other object cleanup mechanisms, otherwise the object pool will probably expand indefinitely and cause memory leaks.
Golang’s cleanup logic for sync.Pool is very simple and brutal. Golang’s runtime will trigger a call to poolCleanup to clean up allPools before each round of GC.
Here we need to formally introduce the victim mechanism of the sync.Pool, which is also mentioned in the object-stealing logic of the Get function.
In each round of sync.Pool cleanup, the pool of objects is not completely cleaned up for the time being, but is placed in the victim. In other words, after each round of GC, the object pool of sync.Pool is transferred to victim, and the victim of the previous round is emptied out.
Why is this done? This is because Golang wants to prevent the sync.Pool from being suddenly emptied after a GC, which would affect the performance of the program. So we use victim as a transition first, and if we can’t get the data in the current round of object pool, we can also get it from victim, so that the program performance will be smoother.
The victim mechanism was first used in CPU Cache, you can read this wiki: Victim_cache for more details.
Other optimizations
false sharing problem avoidance
When we talk about poolLocal above, we find this strange structure: poolLocal has a pad attribute, and from the way this attribute is defined, it is clearly designed to round up to an integer multiple of 128 Byte. Why is this done?
Here it is to avoid the false sharing problem with CPU Cache: CPU Cache Lines are usually in 64 byte or 128 byte units. In our scenario, the poolLocal of each P is in the form of an array. If the CPU Cache Line is 128 byte and the poolLocal is less than 128 byte, the cacheline will take the memory data of other P’s poolLocal to make up a whole Cache Line. If two adjacent P’s are running on two different CPU cores at the same time, they will overwrite the CacheLine and cause the Cacheline to fail repeatedly, and the CPU Cache will be useless.
CPU Cache is the closest cache to the CPU, and if it is used well, it will greatly improve the performance of the program. Golang uses the pad method to prevent false sharing, so that the CacheLine is not shared with other P’s poolLocal.
How sync.Pool performs
To recap, sync.Pool maximizes performance by.
- Using the GMP feature to create a local object pool poolLocal for each P to minimize concurrency conflicts.
- Each poolLocal has a private object, and access to private objects is prioritized to avoid complex logic.
- Use
pinto lock the current P during Get and Put to prevent goroutine from being preempted and causing program chaos. - Use object stealing mechanism to fetch objects from other P’s local object pool and victim during Get.
- Make full use of CPU Cache feature to improve program performance.