I. Background
As we all know, Kafka is a star open source project under the Apache Open Source Foundation. As an open source distributed event streaming platform, it is used by thousands of companies for high-performance data pipelines, stream analysis, data integration, and mission-critical applications. In China, large and small companies, whether they deploy their own or use Kafka cloud services like those provided by AliCloud, many Internet applications are already inseparable from Kafka.
The Internet is not bound to a certain programming language, but many people don’t like that Kafka is developed by Scala/Java. Especially for those programmers who have a “religious” devotion to a language and a “hammer in their hands and nails in their eyes”, there is always an urge to rewrite Kafka. But just like many fans of the new language want to rewrite Kubernetes, Kafka has already established a huge start and ecological advantage, and it is difficult to establish a mega-project with the same specifications and the corresponding ecology in the short term (the same hot Kafka-like Apache pulsar in the last two years pulsar) was created in the same time as Kafka, but it was incorporated into the Apache Foundation hosting later).
The Kafka ecosystem is robust, with Kafka clients for all programming languages. The company behind Kafka confluent.inc also maintains clients for all major languages.

Developers of other major languages just need to take advantage of these client sides and make good connections to the Kafka cluster. Well done so much pavement, the following talk about why to write this article.
The current logging scheme for the production environment of the business line is as follows.
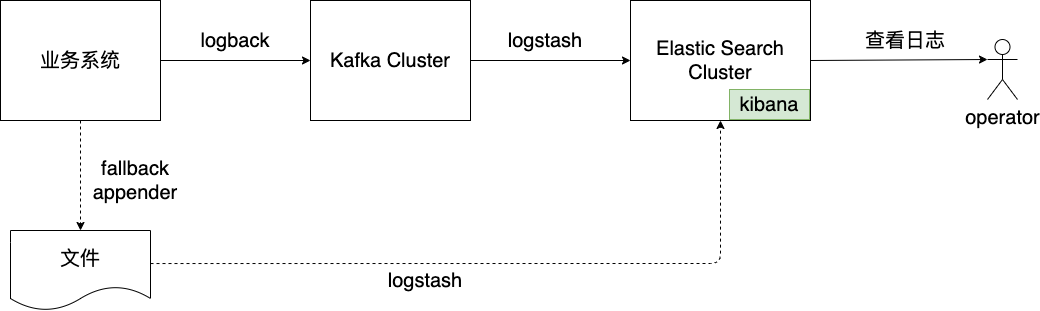
From the diagram we see: The business system writes logs to Kafka, and then consumes the logs through the logstash tool and aggregates them to the Elastic Search Cluster behind for query use . The business system is mainly implemented in Java, and in order to prevent the log from blocking the business process, the business system uses logback, which supports the fallback appender, to write the logs: This way, when the Kafka write fails, the logs This way, when Kafka writes fail, the logs can be written to an alternate file to ensure that the logs are not lost as much as possible .
Considering the reuse of existing IT facilities and solutions, our new system implemented in Go also converges to this no-drop log aggregation solution, which requires that our logger also supports writing to Kafka and supports the fallback mechanism.
Our log package is based on the uber zap package, uber’s zap log package is currently one of the most widely used, high-performance log packages in the Go community, Issue 25 thoughtworks technical radar also lists zap as a recommended tool for the experimental phase, and the thoughtworks team is already using it on a large scale.

However, zap does not natively support writing Kafka, but zap is extensible, and we need to add extensions to it for writing Kafka. And to write Kafka, we can’t do without the Kafka Client package. Currently the mainstream Kafka client in Go community are sarama from Shopify, confluent-kafka-go maintained by confluent.inc, the company behind Kafka, and segmentio/kafka-go.
In this post, I’ll talk about my experience with each of these three clients based on my usage history.
Here, let’s start with Shopify/sarama, which has the most stars.
II. Shopify/sarama: more stars don’t necessarily mean better
The Kafka client package that has the most stars and is most widely used in the Go community is sarama for Shopify, a foreign e-commerce platform.
Here I will demonstrate how to extend zap to support writing kafka based on sarama. in the previous article, I introduced zap built on top of zapcore, which consists of Encoder, WriteSyncer and LevelEnabler, for our functional requirements of writing Kafka We just need to define an implementation that gives a WriteSyncer interface to assemble a logger that supports writing to Kafka .
Let’s start by looking at the function that creates the logger from the top down.
|
|
There is nothing related to the kafka client in this code. The New function is used to create a *Logger instance, which takes the first argument of the io. Note that we use the zap.AtomicLevel type to store the logger’s level information, based on the fact that the zap.AtomicLevel level supports hot updates, we can dynamically modify the logger’s log level at runtime.
Next, we will implement a type that satisfies the zapcore.WriteSyncer interface based on sarama’s AsyncProducer.
|
|
NewKafkaSyncer is the same function that creates zapcore.WriteSyncer, which uses the sarama.AsyncProducer interface type for its first argument, in order to be able to take advantage of the mock test package provided by sarama. The last parameter is the WriteSyncer parameter used during fallback.
NewKafkaAsyncProducer function is used to facilitate the user to create sarama.AsyncProducer quickly, where the config uses the default config value. In the config default value, the default value of Return.Successes is false, which means that the client does not care about the success status of messages written to Kafka, and we do not need to create a separate goroutine to consume AsyncProducer.Successes(). But we need to focus on write failures, so we set Return.Errors to true and start a goroutine in NewKafkaSyncer to handle the log data of write failures and write them to the fallback syncer.
Next, let’s look at the Write and Sync methods of the kafkaWriteSyncer.
|
|
Note: b in the above code will be reused by zap, so we need to make a copy of b and send the copy to sarama before throwing it to the sarama channel.
From the above code, here we are wrapping the data to be written into a sarama.ProducerMessage and send it to the input channel of the producer. What is the reason for this situation? This is mainly because the kafka logger based on sarama v1.30.0 had a hang in our validation environment, and the network might have fluctuated at that time, causing the connection between the logger and kafka to be abnormal, and we initially suspect that this position is blocking, causing the business to be blocked. There is a fix in sarama v1.32.0, which is very similar to our hang phenomenon.
But there is a serious problem with doing so, that is, in the stress test, we found that a large number of logs could not be written to kafka, but were written to the fallback syncer. The reason for this is that we see in sarama’s async_producer.go that the input channel is an unbuffered channel, and there is only one dispatcher goroutine that reads messages from the input channel, and considering the scheduling of the goroutine, the logs are written to the fallback syncer. Considering the scheduling of the goroutine, it is not surprising that a large number of logs are written to the fallback syncer.
|
|
Some people say here can add timer (Timer) to do timeout, to know the log are on the critical path of program execution, every write a log to start a Timer feels too consuming (even Reset reuse Timer). If sarama doesn’t hang the input channel at any time, then let’s not use a trick like select-default in the Write method.
A nice thing about sarama is that it provides the mocks test package, which can be used both for self-testing of sarama and for self-testing of go packages that depend on sarama, taking the above implementation as an example, we can write some tests based on the mocks test package.
|
|
NewAsyncProducerreturns an implementation that satisfies thesarama.AsyncProducer` interface. Then set expect, for each message, and write two logs here, so set it twice. Note: Since we are handling the Errors channel in a separate goroutine, there are some competing conditions here . In concurrent programs, the Fallback syncer must also support concurrent writes. zapcore provides zapcore.Lock which can be used to wrap a normal zapcore.WriteSyncer into a concurrency-safe WriteSyncer.
However, there was a “serious” problem with sarama. We remove the select-default operation for the input channel and create a concurrent-write applet for concurrently writing logs to kafka.
|
|
We start a kafka service locally using docker-compose.yml, which is officially provided by kafka.
Then we use the consumer tool that comes with the kafka container to consume data from the topic named test, and the consumed data is redirected to 1.log.
|
|
Then we run concurrent_write.
The concurrent_write program starts 10 goroutines, each goroutine writes 1w logs to kafka, most of the time you can see 10w logs in the 1.log in the benchmark directory, but when using sarama v1.30.0, sometimes you can see less than 10w logs. but when I use sarama v1.30.0, I sometimes see less than 10w logs, and I don’t know where the “missing” logs are. With sarama v1.32.0, this has not happened yet.
Well, it’s time to look at the next kafka client package!
III. confluent-kafka-go: the package that requires cgo to be opened is still a bit annoying
The confluent-kafka-go package is a Go client maintained by confluent.inc, the technology company behind kafka, and can be considered the official Go client for Kafka. The only “problem” with this package, however, is that it is built on the kafka c/c++ library librdkafka, which means that once your Go application relies on the confluent-kafka-go, you will have a hard time achieving static compilation of Go applications and cross-platform compilation. Since all business systems rely on log packages, once the dependency on confluent-kafka-go can only be dynamically linked, our build toolchain all needs to be changed, which is slightly more costly.
However, confluent-kafka-go is easy to use, has good write performance, and does not have the same “lost messages” as the previous sarama, here is an example of a confluent-kafka-go based producer.
|
|
Here we still use 10 goroutines to write 1w messages each to kafka. Note: Producer instances created with kafka.NewProducer by default are not concurrency safe, so here a sync.Mutex is used to manage their Produce calls synchronously. We can verify that confluent-kafka-go is running by starting a kafka service locally, as in the example in sarama.
Since the confluent-kafka-go package is implemented based on the kafka c library, we cannot turn off CGO, and if we do, we will encounter the following compilation problem.
|
|
Therefore, by default Go programs that rely on the confluent-kafka-go package will be dynamically linked, and the compiled program results are viewed via ldd as follows (on CentOS).
|
|
So is it possible to compile statically with CGO on? Theoretically, yes.
But the confluent-kafka-go package is officially confirmed not to support static compilation yet. Let’s try statically compiling it with CGO on.
|
|
Static linking will statically link the symbols of the c part of confluent-kafka-go, which may be in c runtime libraries such as libc, libpthread, or system libraries, but by default CentOS does not have the .a (archive) versions of these libraries installed. We need to install them manually.
|
|
After installation, we then execute the static compile command above.
|
|
This time our static compilation worked!
But there are some warnings! Let’s ignore these warnings and try to see if the compiled producer-static is available. Starting the local kafka service with docker-compose and executing producer-static, we find that the application can write 10w messages to kafka normally, without errors occurring in between. At least in the producer scenario, the application does not execute the code containing dlopen, getaddrinfo.
However, this does not mean that the above static compilation approach is not problematic in other scenarios, so let’s wait for the official solution to be released. Or use the builder container to build your confluent-kafka-go based application.
Let’s move on to segmentio/kafka-go.
iv. segmentio/kafka-go: sync is slow, async is fast
Like sarama, segmentio/kafka-go is a pure go implementation of the kafka client and has been tested in many companies’ production environments. segmentio/kafka-go provides low-level conn api and high-level api (reader and writer), taking writer as an example. Relative to the low-level api, it is concurrently safe, but also provides connection hold and retry, without the need for developers to implement their own, in addition writer also supports sync and async write, timeout write with context.
But Writer’s sync mode is very slow, only a few dozen a second, but async mode is fast!
However, like confluent-kafka-go, segmentio/kafka-go does not provide a mock test package like sarama, we need to build our own environment to test. kafka-go official advice: start a kafka service locally and run the test . In the age of lightweight containers, it’s worth thinking about whether mock is needed.
The experience with segmentio/kafka-go has been great, and I haven’t encountered any major problems so far, so I won’t give examples here. See the benchmark section below for examples.
V. Write performance
Even a brief comparison cannot be done without benchmark, and test cases for sequential benchmark and concurrent benchmark are created here for each of the three packages above.
|
|
Start a kafka service locally and run the benchmark.
|
|
We see that although sarama has an advantage in memory allocation, the overall performance is segmentio/kafka-go optimal.
VI. Summary
This article compared three mainstream kafka client packages from the Go community: Shopify/sarama, confluent-kafka-go, and segmentio/kafka-go. sarama is the most widely used and the one I have studied for the longest time, but it also has the most pitfalls and is abandoned; confluent-kafka-go is official but based on cgo. go is official but based on cgo, so I have no choice but to give up; finally, we chose segmentio/kafka-go, which has been running online for some time and no major problems have been found so far.
However, the comparison in this article is limited to the scenario of Producer, which is an “incomplete” introduction. We will add more practical experience in more scenarios later.
The source code in this article can be downloaded from here.