When participating in interviews, Linux processes should be considered a must for me, because many languages don’t bother to implement a set of process management and scheduling, but instead borrow directly from the operating system, especially the Python community which sees no need to duplicate the wheel in this area and uses a simple wrapper around system calls. As a result, it’s hard to really know what’s going to happen to the concurrent code you write if you don’t know much about Linux processes.
The scheduler is the subsystem in the kernel that ensures that processes can work efficiently, and is responsible for deciding which processes to put into operation, when to run them, and for how long. Proper scheduling by the scheduler is a guarantee that system resources will be maximized.
From the first release of Linux in 1991 until version 2.4 of the kernel, the Linux scheduler was fairly rudimentary and primitive in design. In 2.5, however, the scheduler uses a scheduler called O(1) (because its scheduling algorithm has a time complexity of O(1)). However, the O(1) scheduler was inherently underperforming for time-sensitive programs that required user interaction (perhaps because of the slow progress of early Linux desktops), and the 2.6 kernel was developed with the intention of optimizing interactive programs and introducing new scheduling algorithms.
The most famous of these was the Rotating Staircase Deadline scheduler (RSDL).
Until 2.6.23 kernel, this algorithm completely replaced the O(1) algorithm and became known as Completely Fair Scheduling Algorithm, or CFS.
This article will focus on the O(1) algorithm and the CFS algorithm, and briefly explain how CFS is implemented.
Multitasking and Scheduling Basic Concepts
Linux is a multitasking operating system that can execute multiple processes concurrently and interactively at the same time. On a multi-core processor machine, a multitasking operating system enables multiple processes to execute in true parallel on different processors, whereas on a single-processor machine, it only creates the illusion of multiple processes executing simultaneously. Whether single-core or multi-core, the operating system enables multiple processes to be in a blocking or sleep state, leaving only those processes suitable for execution to the processor.
Multitasking systems are generally divided into non-preemptive multitasking and preemptive multitasking. Linux belongs to the latter category, which means that *the scheduler decides when to stop a process so that other processes can get a chance to execute. This forced hang is known as preemption. The amount of time a process can run before it is preempted is pre-determined and has a special name, timeslice, for the process.
Timeslice is the actual amount of processor time allotted to each runnable process. Many operating systems use dynamic timeslice calculation, meaning that the absolute amount of time allotted to a process is calculated dynamically based on the machine’s load, rather than being specified and not changing. However, the Linux scheduler itself does not allocate time slices to achieve fair scheduling.
The essence of the scheduler is the scheduling algorithm, and the algorithmic policy determines what processes the scheduler will let execute when, so let’s start by asking a few practical questions to understand what the scheduling algorithm is trying to do.
IO-intensive and CPU-intensive
Processes can be classified as IO-intensive or CPU-intensive. The former spends most of its time submitting IO requests or waiting for IO requests; such a process is often running, but usually for a short while at a time, because it always ends up blocking while waiting for more IO requests. In contrast, CPU-intensive types spend most of their time executing code and will keep executing unless they are preempted, because they do not have many IO requests or are not likely to block. And the OS scheduler doesn’t let them run very often for responsiveness reasons.
Because the system needs to take responsiveness into account, the scheduler just needs to make sure that it doesn’t let CPU-intensive types run for a long time, but some programs don’t exactly fit into these two classifications, such as office software like Word, which often waits for keyboard input (waiting for IO), while at any given moment, it may stick to the processor frantically processing spell-checking and macro calculations.
How to make the scheduling policy find a balance between two conflicting goals: responsiveness and maximum system utilization. Different systems have different solution strategies, but usually it is a complex set of algorithms, but most of them do not guarantee that low priority processes will be treated fairly, and Linux’s CFS basically solves this problem (in case the number of processes will not be huge).
Process priority problem
The most basic class of scheduling algorithms is priority-based scheduling, which is the idea of grading processes according to their value and other demands on the processor. And there are generally two types, one is that the higher priority runs first and the lower runs later, and processes of the same priority are scheduled on a rotating basis. The other is that processes with higher priority use longer time slices, and the scheduler always chooses the process with unexhausted time slices and the highest priority to run.
Linux uses two different priority ranges, the first one is the nice value, which ranges from -20 to +19 and defaults to 0, and the higher the nice value the lower the priority. Processes with high priority (low nice value) get more processor time compared to processes with low priority (high nice value). However, the allocation of this time varies from system to system, for example macOS uses the absolute value of the time slice, while Linux uses the proportion of the time slice.
The second range is the real-time priority, which defaults to 0 ~ 99. Contrary to the nice value, the higher the value of real-time priority, the higher the priority, and any real-time process has a higher priority than a normal process, which means that the two priority ranges are independent and non-intersecting. And real-time processes are Linux’s preferential treatment for processes with strict time requirements.
Time slice
A time slice is a numerical value that indicates how long a process can run before it is preempted. Scheduling policies specify a default time slice, but determining the default time slice is not straightforward. If the time slice is too long, it tends to delay process switching, making the system less responsive to interactions, and if the time slice is too short, it significantly increases the processor time consumed by process switching.
Therefore, a time slice of any length will result in poor system performance, and many operating systems take this very seriously, so the time slice defaults to a more moderate size, such as 10ms. are closely related.
The ratio that processes receive in Linux is also affected by the nice value, thus reflecting the role of priority. Under multiple conditions, the kernel can decide on the running of processes based on time slices: if a new process consumes less usage than the currently executing process, this immediately strips the current process of its execution rights and puts the new process into operation.
Processes that require user interaction
As mentioned earlier, user-interactive processes are more real-time oriented and therefore very special to handle, so let’s take a practical example of how Linux handles processes that require user interaction.
If you have a very CPU-intensive process, such as compiling a huge C program, and a very interactive word processor like Notepad. For the compile process, we don’t care when it runs, it makes no difference to us if it runs half a second earlier or later, but it would be nice to get it done as soon as possible, while for the notepad process, we would prefer to see the feedback immediately after we hit the keyboard (immediately grabbing the compile process).
For achieving the above requirements relies on the system assigning a higher priority and more time slices to the notepad (which may involve the system automatically recognizing that the notepad process needs a higher priority), but in Linux a very simple approach is used that does not even require assigning different priorities. If two processes have the same nice value, then each of them will get 50% of the CPU time (the time slice is a ratio under Linux). Since Notepad is constantly waiting for user input, there is no doubt that the compiler process will be executing most of the time, so Notepad will definitely use less than 50% of the CPU and the compiler will definitely use more than 50%. When the user types, the notepad that has just been woken up will be found to be using less than the compiler process that is executing, so it will immediately take over and respond quickly. When the notepad finishes its work and continues to wait for user input, it will be hung and the execution rights will be assigned to the compiler process again.
Scheduling Algorithms
The above describes what the scheduler does by some simple concepts, and the following starts a formal discussion of the scheduling algorithm.
Scheduler class
Before we talk about scheduling algorithms, we need to explain the scheduler class. Linux schedulers are provided as modules, which are designed to allow different types of processes to have a targeted choice of scheduling algorithms. The modules that provide the different scheduling algorithms are the scheduler classes. For example, CFS is a scheduler class for normal processes (defined in kernel/sched_fair.c), called SCHED_NORMAL in Linux (or SCHED_OTHER in POSIX).
Each scheduler has a priority, and the kernel selects the highest priority scheduler first, which then schedules the process and executes it.
O(1) Scheduling Algorithm
Before we talk about CFS, let’s introduce the traditional Unix scheduling algorithm: the O(1) scheduling algorithm. Modern process schedulers have two general concepts: process priority and time slice, which refers to how long a process runs. Processes are given a time slice after they are created, and processes with higher priority run more often and tend to have more time slices, which is the essence of the O(1) scheduling algorithm.
Obviously, in addition to allowing higher priority processes to preempt as much as possible, the O(1) scheduling algorithm also weights the time slices according to priority. However, as mentioned earlier, the traditional scheduling algorithm uses absolute time length, which also causes some problems. For example, if there are two processes with different priorities, one with a nice value of 0 and the other with a nice value of 1, their weighted time slices are 100ms and 95ms respectively, and their time slices are very close to each other, but if the nice values are changed to 18 and 19, then Their time slices become 10ms and 5 ms, and the former is twice as long as the latter. Thus, although the nice value is only 1, the final result is very different.
Therefore, CFS does not allocate absolute time slices at all, but rather allocates the weight of processor usage.
CFS Scheduling Algorithm
The starting point of CFS is based on a simple idea: Process scheduling should work as if the system has an ideal perfect multitasking processor. In such a system, each process would get 1/n of the processor time (if there are n processes). For example, if we have two runnable processes and run one of them for 5ms and then the other one for 5ms, if the process switching is fast enough, then it seems that in 10ms we can run both processes at the same time and use half of the processor’s power each.
Of course, this is not realistic, because first of all, a processor cannot really run multiple tasks at the same time, and because switching between processes is lossy and cannot be done infinitely fast, CFS adopts a compromise: let each process run for a while, rotate it in a loop, and choose the process that runs the least as the next process, instead of allocating time slices to each process. CFS calculates how long a process should run based on the total number of processes that can run, rather than relying on nice values to calculate time slices (nice values only affect weighting and not absolute values).
Each process runs on a “time slice” of its weight in proportion to the total number of runnable processes. To accurately calculate the time slice, CFS sets a target for an approximation of infinitely small scheduling cycles in perfect multitasking, called: target latency. The smaller the scheduling period, the better the interaction and the closer to perfect multitasking (but also the more switching overhead required). For example, if we set a target latency of 20ms, then if there are two processes of the same priority, each process can only run for 10ms before being preempted, and if there are 5 such tasks, then each task can only allow 4ms.
However, in the above example, if the number of processes is very large, say more than 20, then each process gets less than 1ms of runtime, and may even be less than the time consumed by the process switch. Of course, Linux sets a bottom line to avoid this kind of thing, which is called minimum granularity (usually 1ms by default). Therefore, it can only be said that CFS is fair when the number of processes is not huge (usually there are only a few hundred processes running on the system, and CFS is still very fair at this scale). For example, if the target latency is still 20ms, and one of the two processes has a nice value of 0 and the other 5, the weight of the latter will be 1/3 of the former, i.e. the two processes get 15ms (20 * 2/3) and 5ms (20 * 1/3) of processor time respectively. If the nice values of the two processes are 10 and 15, the two processes still get 15ms and 5ms of processor time, respectively, because the weighting relationship has not changed. Therefore, the nice value does not affect the scheduling decision, only the relative value affects the percentage of processor time allocated.
Under CFS, the amount of processor time any process receives is determined by the relative difference between itself and the nice values of all other runnable processes. nice values have been changed from arithmetic weighting to geometric weighting, and it is the absolute value of time slices that has been changed to a usage ratio, allowing for lower scheduling latency in a multi-process environment.
CFS Implementation
After discussing various concepts, we finally get to the point, which is the implementation of the CFS algorithm. The relevant code is in kernel/sched_fair.c, and our focus is on four main areas.
- Runtime logging
- Selection of the processes to be put into operation
- Scheduler selection
- Sleeping and waking up
Runtime logging
As mentioned above, the core of CFS is the CPU usage ratio, so it is important to keep track of the running time of processes. On most Unix systems, a time slice of absolute time is allocated to a process, and each time a system clock beat occurs, the time slice is reduced by one beat period. Whenever a process’s time slice is reduced to 0, it is preempted by a process that has not yet been reduced to 0.
However, CFS does not have absolute time slices, but it still needs to keep track of each process’ runtime to ensure that each process runs only for the processor runtime that is fairly allocated to it. And the bookkeeping information is stored in its structure pointer se in the process’s task_struct.
In the structure, there is an important member variable vruntime, which is a record of the total runtime (sum of time spent running) of the process, and this time is weighted (priority, machine load, etc.). Virtual time is measured in ns, so vruntime and the system timer beat are no longer relevant.
The kernel updates the vruntime of a process by calling the uodate_curr() function (defined in kernel/sched_fair.c) at regular intervals, which calculates the execution time of the current process and will call __uodate_curr() to get the runtime weighted by the machine load (total number of processes that can run). The value is then added to the original vruntime to obtain the new vruntime.
Selecting the processes to put into operation
If the perfect multitasking processor described above existed, then each runnable process should have the same vruntime value. However such a processor does not exist, then CFS tries to move closer to that direction, i.e., it picks the process with the smallest vruntime each time it selects a process.
CFS uses a red-black tree to organize the runnable queue. A red-black tree, or rbtree for short, is a self-balancing binary search tree where each node in the tree corresponds to a key value that can be used to quickly retrieve data on the node. I will write a separate article about the data structure later (database indexes are also generally based on red-black trees).
When the CFS scheduler needs to pick the next running process, it only needs the __pick_next_entity() method to find the process with the lowest virtual runtime in the tree. (i.e., the leftmost leaf node of the search tree, which the kernel actually takes out a global variable for quick access) and puts this process into operation.
If a blocking process meets the wait condition or if a new process is created by fork(), it is inserted into the tree by the enqueue_entity() method, in order to ensure that it rings as soon as possible. The newly inserted node is compared with the leftmost leaf node, and if the new node is the leftmost leaf node, the scheduler will immediately put the new process into operation.
Conversely, if a process is blocked (or otherwise) and becomes inoperable, the scheduler removes the process from the red-black tree via the dequeue_entity() method, which calls the rb_next() method to find the new leftmost node if it is the leftmost node.
Scheduler selection
As mentioned earlier, the kernel supports several schedulers, and CFS is just one of them. The main entry point for process scheduling is the function schedule() defined under kernel/sched.c, which does the following to select a process and put it into operation, and its logic is very simple.
- call
pick_next_task()to get a task. - put the task into operation.
The real scheduler-related logic is in pick_next_task(), which does the following things.
- iterate through the scheduling classes according to their priority.
- return immediately if there is a runnable process under this scheduling class.
pick_next_task() does a simple optimization for CFS, so that if all runnable tasks are under the CFS scheduler, it no longer iterates through other scheduling classes, but keeps taking tasks from the CFS scheduler.
Sleeping and waking up
A dormant (blocking) process is in a special non-executable state. There can be many reasons for blocking, such as waiting for a signal, or waiting for input from the user keyboard, etc. Either way, the kernel does the same thing: the process marks itself as dormant, removes itself from the executable red-black tree and puts it in the waiting queue, then calls schedule() to select and execute a different process.
As mentioned in the previous article, there are two process states for hibernation: TASK_INTERRUPTIBLE and TASK_UNINTERRUPTIBLE, and in either state, the hibernating process is on the same wait queue.
Waiting queue is a simple chain of processes waiting for some event to occur. Processes on the queue are woken up when the event associated with the waiting queue occurs, and to avoid creating competing conditions, the implementations of hibernation and wake-up cannot have batches. However, a simple implementation may result in a process starting to hibernate even after the adjudication condition is true, which will then cause the process to hibernate indefinitely, so the process is added to the waiting queue as follows.
- call the macro
DEFINE_WAIT()to create an entry in the wait queue - call
add_wait_queue()to add itself to the queue - call
prepare_to_wait()to change the status of the process toTASK_INTERRUPTIBLEorTASK_UNINTERRUPTIBLE - if the state is set to
TASK_INTERRUPTIBLEthen signal wakeup (pseudo wakeup) to check and process the signal - after waking up, check if the wait condition is true, if so, jump out of the loop, otherwise call
schedule()again and keep repeating - After jumping out of the loop (condition is met), the process sets itself to
TASK_RUNNINGand calls thefinish_wait()method to remove itself from the waiting queue
The wake-up operation is done with wake_up(), which wakes up all processes on the specified waiting queue, and the main logic of wake_up() is in the call to try_to_wake_up().
- set the process to
TASK_RUNNING - call
enqueue_task()to put the process into the red-black tree - if the process waking up has a higher priority than the currently executing process, immediately seize it
- set the
need_reschedflag (to mark if rescheduling is triggered)
However, as mentioned above, because there are pseudo-wakes, processes are not always woken up because the wait condition is met.
Preempting Process Context Switching
A context switch is a switch from one executable process to another executable process. At the end of the article, it talks about context switching and preemption of processes.
The context switch function context_switch() handled by the kernel is defined in kernel/sched.c, and it basically does two things.
-
call
switch_mm()to switch the virtual memory map from the previous process to the new process -
call
switch_to()to switch from the processor state of the previous process to the processor state of the new process (including stack information, register information, etc.)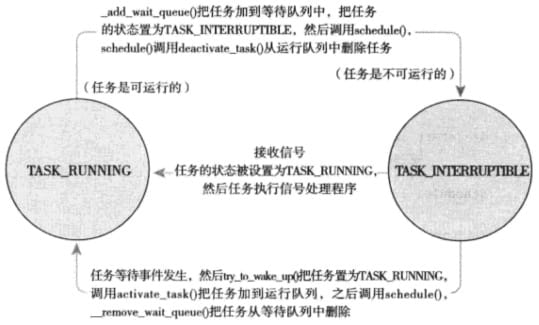
When the kernel is about to return to user space, if need_resched is flagged, it causes schedule() to be called, at which point user preemption occurs. Because a process returning to user space from the kernel knows that it is safe to either continue execution or choose a new process to execute, the process can check that need_resched is marked, either after a system call or after an interrupt, to determine whether schedule() needs to be called again. In summary, general user preemption occurs when.
- returning to user space from a system call
- return to user space from an interrupt handler
Since Linux has full support for kernel preemption, the kernel can preempt an executing task at any time as long as the scheduling is safe (no locks are held) The determination of locks in Linux is done by counting, and preempt_count is introduced in thread_info to keep track of held locks. safe, and the new process happens to have the need_resched flag set, then the current process can be preempted.
Explicit preemption occurs if a process in the kernel is blocked or if schedule() is called explicitly. Explicit preemption is never supported, because if a function explicitly calls schedule(), it makes itself clear that it can be safely preempted.
Preemption by the kernel typically occurs when.
- before the interrupt handler is executing and returns to kernel space
- when the kernel code is once again preemptable
- If a task in the kernel explicitly calls
schedule(). - When a task in the kernel blocks