Start with an introduction to k8s knowledge points and common terms.
Master
The Master node, the brain of k8s, is the control node of the cluster and is responsible for the management and control of the cluster. All other Nodes register themselves with the Master and report all information about themselves on a regular basis. The following four processes run on the Master node.
- Api Server: The service process that provides the HTTP Rest interface; the only entry point for all resource add, delete, and check operations; the entry point for cluster control,
kubectlis directly responsible for the Api Server. - Controller Manager : The automated control center for all resource objects.
- Scheduler: responsible for resource scheduling, mainly scheduling Pods to the specified Node.
- etc Server : All the data of resource objects are stored in etcd.
Node
If a Node does not report information for more than a specified period of time, it will be judged as out-of-connection by the Master, and the status of the Node will be marked as unavailable, and then the Master will trigger the automatic process of “workload transfer”. There are three main processes running on the Node.
- kubelet: responsible for creating, starting and stopping containers corresponding to Pods; works closely with Master nodes to achieve the basic functions of cluster management; Node reports information to Master through kubelet.
- kube-proxy: implements the communication and load balancing mechanism of the Service.
- Docker Engine: responsible for the creation and management of local containers.
Namespace
Namespace is used to implement multi-tenant resource isolation. By assigning the resource objects inside the cluster to different Namespace. When creating a resource object, you can specify which Namespace it belongs to.
Pods
Pods are the smallest scheduling unit of k8s.
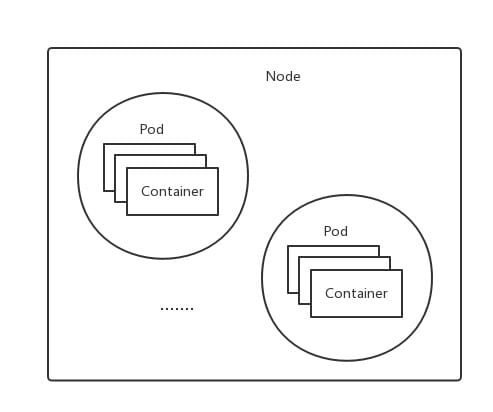
As shown in the figure above, Pods are composed of one container, called a container group. The containers that make up a Pod are divided into Pause containers and individual business containers. The state of the Pause container represents the state of the entire Pod, and since the Pause container does not die easily, this ensures the judgment of the Pod’s state as a whole; while all business containers share the IP and Volume of the Pause, which solves the problem of communication and sharing of resources among the closely connected business containers. kubelet scheduling.
Pods have unique IPs, and k8s uses the Endpoint (pod_ip + containerPort) as the external communication address for a service process in a Pod. The Endpoint of a Pod has the same lifecycle as the Pod, and when the Pod is destroyed, the corresponding Endpoint is also destroyed.
There are two types of Pods.
- Normal Pods, which are stored in etcd and are dispatched to a Node for binding, and are instantiated into a set of containers and started by a kubelet in the Node after dispatch.
- Static Pods, which are stored in a specific file on a specific Node and are started and run only in that Node.
Volume
is defined on a Pod and is mounted to a specific file directory by multiple containers within a Pod. Note that Volume has the same lifecycle as Pod.
Role: Multiple containers in a Pod share files; let the container’s data write to the host’s disk; write files to network storage; centralized definition and management of container configuration files.
Types
- emptyDir: Created when a Pod is assigned to a Node without specifying a directory file on the host. when a Pod is removed, the data on emptyDir is permanently deleted.
- hostPath: Mounts a file or directory on the host on the Pod. Pods with the same configuration on different Nodes may have inconsistent access results to directories and files on the Volume because the directories and files on the host are different; if resource quota management is used, k8s cannot include the resources used by hostPath on the host in the management.
- Usage: Log files generated by containers need to be saved permanently; need to access the Docker engine on the host, define hostPath as the host /var/lib/docker directory.
- Other: such as gcePersistentDisk, awsElasticBlockStore, etc., are permanent disks provided by specific cloud services. pods are not deleted when they end, they are only unmounted. The Pods are not deleted at the end of the day, they are only uninstalled. You need to install specific virtual machines and persistent disks as required to use them.
Deployment
Used to better solve the Pod orchestration problem, which uses ReplicaSet internally to achieve the purpose.
Usage scenarios.
- Generating RS and completing the process of creating a copy of the Pod.
- Checking if the deployment action is complete.
- Updating Deployment to create a new Pod.
- Rollback.
- Hanging or recovery.
Description of the number of Pods
- DESIRED: Desired value for the number of Pod replicas
- CURRENT: The current number of replicas
- UP_TO_DATE: The number of Pod copies of the latest version
- AVAILABLE: Number of Pod copies currently available in the cluster
Label
Definition form: key=value. We mainly use Label Selector to query and filter the resource objects of certain labels.
Usage scenarios.
- kube-controller filtering Pods to be monitored
- kube-proxy process builds a routing table for Service requests to Pods.
- kube-scheduler process to implement Pod directed scheduling
Annotation
Definition form: key=value
Difference from Label.
- Label has strict naming rules
- Label defines metadata and is used in Label Selector; Annotation is additional information arbitrarily defined by the user
Usage Scenarios.
- build information, release information, Docker image information, etc.
- Addresses of log repositories, monitoring repositories, analysis repositories, and other repositories
- Program debugging tool information
- Contact information for the team
Replica Set
Replica Set(RS) is an upgraded version of Replication Controller(RC). The only difference between the two is the support for selectors; ReplicaSet supports set-based selector requirements as described in the labels user guide, while Replication Controller only supports equality-based selector requirements.
We generally use Deployment to define RSs, and rarely create them directly, thus forming a complete orchestration mechanism for creating, deleting, and updating Pods.
What can be defined in RS are: the expected number of replicas (Replicas) for Pods; Label Selector for filtering target Pods; and template for creating new Pods when the number of Pod replicas is less than the expected number.
The Master’s Controller Manager periodically patrols the system for currently live target Pods to ensure that the number of target Pod instances is equal to the desired value. Deleting RSs does not affect Pods and supports collection-based Label Selector; it enables Pod scaling up and scaling down by changing the number of Pod copies in RSs; it enables rolling upgrade of Pods by changing the mirror version in Pod templates in RSs.
Service
Definition: microservice in a microservice architecture.
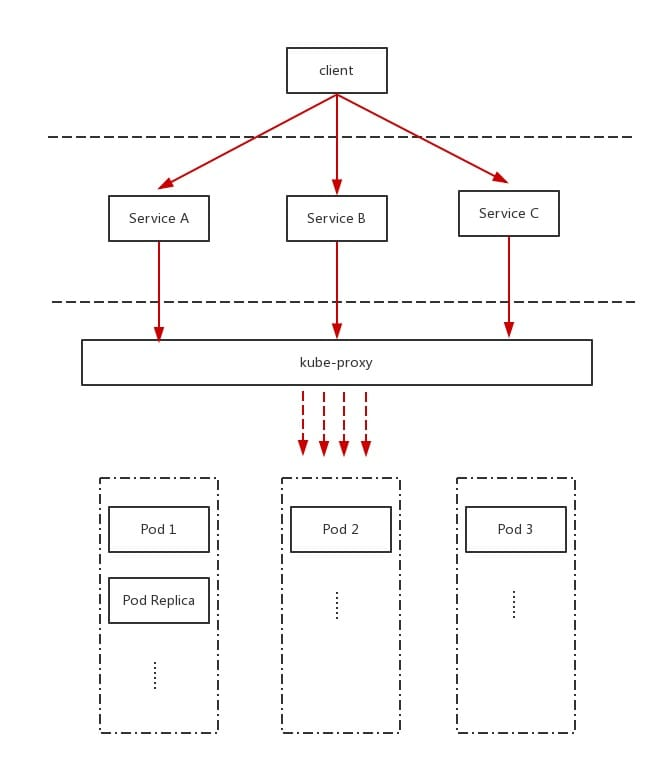
Service defines an access entry address for a service through which clients access the cluster instance behind it. service is interfaced with the back-end Pod copy cluster through Label Selector. service communicates with each other via TCP/IP.
Load balancing
The kube-proxy process is an intelligent load balancer that forwards requests for the Service to the back-end Pods. all copies of the Pods are grouped together, providing an external service port to which the Endpoint list of these Pods is added to the forwarding list. Clients access this service through the external IP + service port of the load balancing.
ClusterIP
A Service has a globally unique virtual IP, called ClusterIP, and each Service becomes a communication node with a globally unique IP. Unlike a Pod, the Endpoint of a Pod changes when the Pod is destroyed, but the ClusterIP does not change during the lifetime of the Service. And as long as a DNS domain name mapping is done with the Name of the Service and the ClusterIP of the Service, service discovery can be realized.
The Service generally defines a targetPort, which is the exposed port of the container providing the service. The specific business process provides TCP/IP access on the targetPort in the container; and the port property of the Service defines the virtual interface of the Service.
Service Discovery
before: Each Service generates some corresponding Linux environment variables that are automatically injected when the Pod container is started.
now: The DNS system is introduced by means of an Add-On value-added package, which is implemented by using the service name as the DNS domain name.
External System Access Service
There are three types of IPs in k8s.
- Node IPThe IP address of the physical NIC of each node in the cluster; all servers belonging to this network communicate directly with each other over this network; nodes outside the cluster must communicate over the Node IP when accessing the cluster.
- Pod IPDocker Engine assigned based on the IP address segment of the docker0 bridge; virtual Layer 2 network; containers of different Pods communicate with each other through the virtual Layer 2 network where the Pod IP is located.
- Cluster IP
- Service-only: IP addresses are managed and assigned by kuber.
- Cannot be pinged: because there is no physical network object to respond to.
- Cluster IP can only be combined with Service Port to form a specific communication port: separate Cluster IP does not have a TCP/IP communication base; belongs to the closed space of the kuber cluster; nodes outside the cluster need some additional operations if they need access.
- Communication between the Node IP network, Pod IP network and Cluster IP network is a programmatic routing rule of kuber’s own making.
The method of accessing the Service by external systems in k8s is mainly through NodePort, which is implemented by opening a corresponding TCP listening port on each Node for the Service that needs to provide external access. At this point, external systems can access the service by using the IP + NodePort of any of the Nodes.