This article is based on reading the source code of Kubernetes v1.19.0-rc.3
Kubelet, one of the four components of Kubernetes, maintains the entire lifecycle of a pod and is the last link in the pod creation process of Kubernetes. This article will introduce how Kubelet creates pods.
Architecture of Kubelet
First look at a diagram of the Kubelet’s component architecture, as follows.
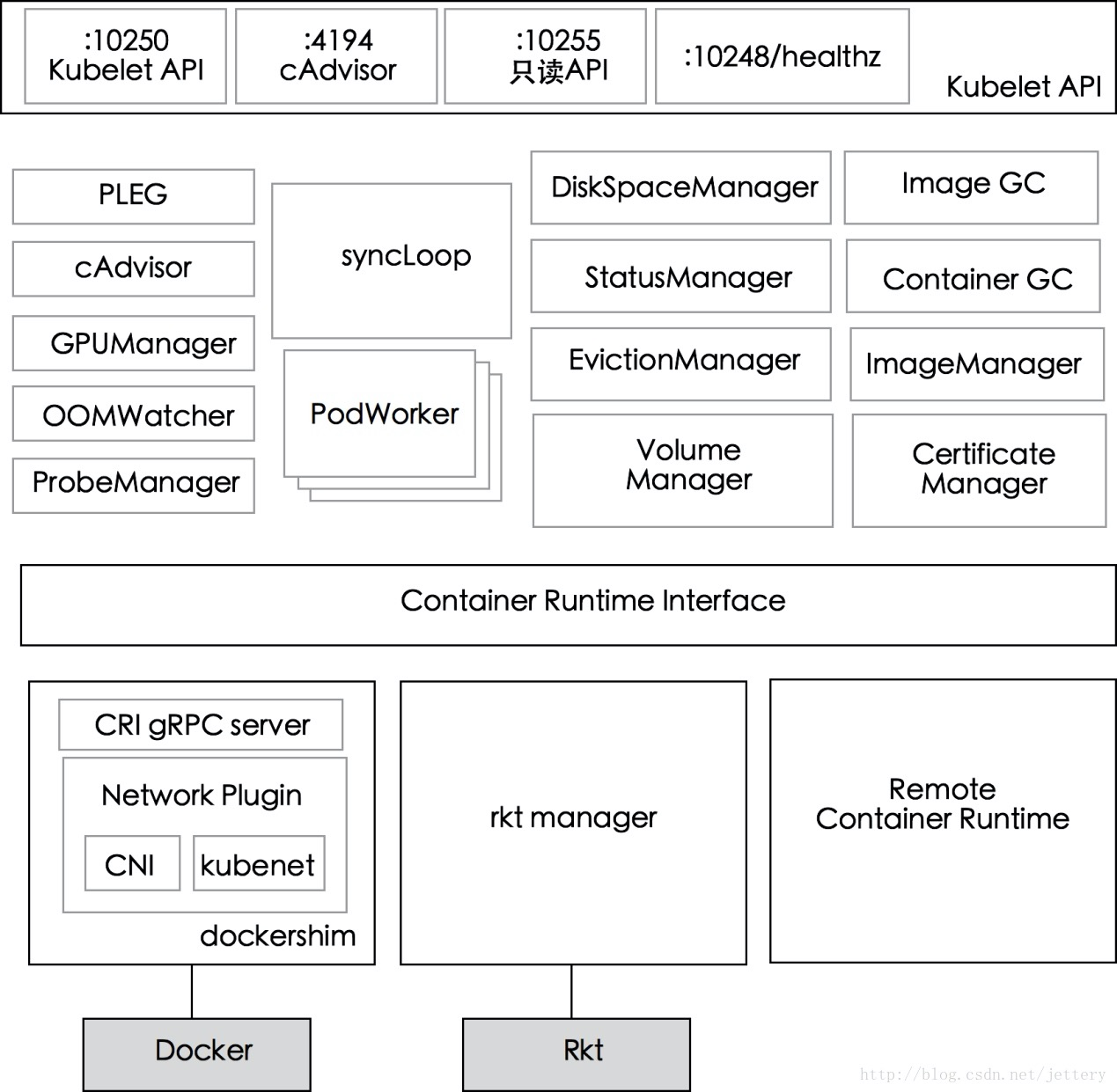
It can be seen that Kubelet is mainly divided into three layers: API layer, syncLoop layer, CRI and the following; API layer is well understood, that is, the part that provides the interface to the outside; syncLoop layer is the core working layer of Kubelet, the main work of Kubelet is centered around this syncLoop, that is, the control loop, run by producers and consumers; CRI provides the interface of container and mirror services, the container can be accessed as a CRI plugin when running. The CRI provides an interface to the container and mirror services, which can be accessed as a CRI plug-in when the container is running.
Let’s take a look at some important components of the syncLoop layer.
- PLEG: Call the container runtime interface to get the information of containers/sandboxes of this node, compare it with the locally maintained pod cache, generate the corresponding PodLifecycleEvent, and then send it to Kubelet syncLoop through eventChannel, and then synchronize the pod by the timing task to finally reach the desired state of the user.
- CAdvisor: A container monitoring tool integrated in Kubelet, used to collect monitoring information of this node and containers.
- PodWorkers: Multiple pod handlers are registered to handle pods at different times, including creation, update, deletion, etc.
- oomWatcher: Listener of system OOM, will establish SystemOOM with CAdvisor module, and generate events related to OOM signals received from CAdvisor by Watch.
- containerGC: responsible for cleaning up the useless containers on the node, the specific garbage collection operation is implemented by the container runtime.
- imageGC: Responsible for image recycling on node nodes. When the local disk space where the image is stored reaches a certain threshold, the image recycling will be triggered and the image not used by the pod will be deleted.
- Managers: Contains various managers that manage various resources related to pods. Each manager has its own role and works together in SyncLoop.
How Kubelet works
As mentioned above, Kubelet works mainly around a SyncLoop. With the help of a go channel, each component listens to the loop to consume events or produce pod-related events into it, and the whole control loop runs event-driven. This can be represented by the following diagram.
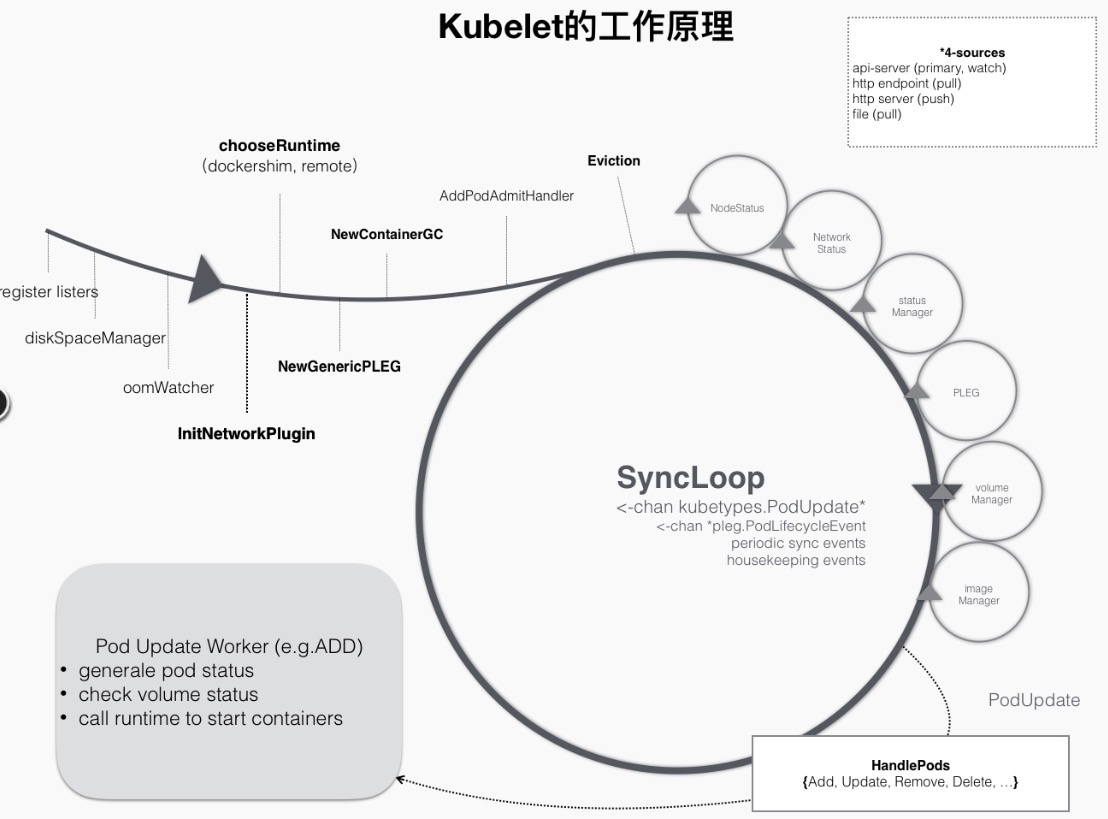
For example, during the pod creation process, when a pod is dispatched to a node, it triggers a handler registered by Kubelet in the loop control, such as the HandlePods section in the figure above. At this point, Kubelet checks the state of the pod in Kubelet memory, determines that it is the pod that needs to be created, and triggers the logic corresponding to the ADD event in the Handler.
SyncLoop
Let’s look at the main loop, SyncLoop.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
func (kl *kubelet) syncLoop(updates <-chan kubetypes.PodUpdate, handler SyncHandler) {
klog.Info("Starting kubelet main sync loop.")
// The syncTicker wakes up Kubelet to checks if there are any pod workers
// that need to be sync'd. A one-second period is sufficient because the
// sync interval is defaulted to 10s.
syncTicker := time.NewTicker(time.Second)
defer syncTicker.Stop()
housekeepingTicker := time.NewTicker(housekeepingPeriod)
defer housekeepingTicker.Stop()
plegCh := kl.pleg.Watch()
const (
base = 100 * time.Millisecond
max = 5 * time.Second
factor = 2
)
duration := base
// Responsible for checking limits in resolv.conf
// The limits do not have anything to do with individual pods
// Since this is called in syncLoop, we don't need to call it anywhere else
if kl.dnsConfigurer != nil && kl.dnsConfigurer.ResolverConfig != "" {
kl.dnsConfigurer.CheckLimitsForResolvConf()
}
for {
if err := kl.runtimeState.runtimeErrors(); err != nil {
klog.Errorf("skipping pod synchronization - %v", err)
// exponential backoff
time.Sleep(duration)
duration = time.Duration(math.Min(float64(max), factor*float64(duration)))
continue
}
// reset backoff if we have a success
duration = base
kl.syncLoopMonitor.Store(kl.clock.Now())
if !kl.syncLoopIteration(updates, handler, syncTicker.C, housekeepingTicker.C, plegCh) {
break
}
kl.syncLoopMonitor.Store(kl.clock.Now())
}
}
|
SyncLoop starts a dead loop, where only the syncLoopIteration method is called. The syncLoopIteration iterates through all the incoming channels and hands over any pipeline that has a message to the handler.
These channels include:
- configCh: The producer of this channel is provided by the PodConfig submodule in the kubeDeps object. This module will listen for changes in pod information from file, http, and apiserver, and will produce events to this channel once the pod information from a source is updated.
- plegCh: The producer of this channel is the pleg submodule, which will periodically query the container runtime for the current state of all containers, and if the state changes, it will produce events to this channel.
- syncCh: Sync the latest saved pod state periodically.
- livenessManager.Updates(): Health check finds that a pod is unavailable and the Kubelet will automatically perform the correct action based on the pod’s restartPolicy.
- houseKeepingCh: pipeline for housekeeping events, doing pod cleanup.
Code for syncLoopIteration.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
|
func (kl *kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh:
// Update from a config source; dispatch it to the right handler
// callback.
if !open {
klog.Errorf("Update channel is closed. Exiting the sync loop.")
return false
}
switch u.Op {
case kubetypes.ADD:
klog.V(2).Infof("SyncLoop (ADD, %q): %q", u.Source, format.Pods(u.Pods))
// After restarting, Kubelet will get all existing pods through
// ADD as if they are new pods. These pods will then go through the
// admission process and *may* be rejected. This can be resolved
// once we have checkpointing.
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
klog.V(2).Infof("SyncLoop (UPDATE, %q): %q", u.Source, format.PodsWithDeletionTimestamps(u.Pods))
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
klog.V(2).Infof("SyncLoop (REMOVE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
klog.V(4).Infof("SyncLoop (RECONCILE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
klog.V(2).Infof("SyncLoop (DELETE, %q): %q", u.Source, format.Pods(u.Pods))
// DELETE is treated as a UPDATE because of graceful deletion.
handler.HandlePodUpdates(u.Pods)
case kubetypes.SET:
// TODO: Do we want to support this?
klog.Errorf("Kubelet does not support snapshot update")
default:
klog.Errorf("Invalid event type received: %d.", u.Op)
}
kl.sourcesReady.AddSource(u.Source)
case e := <-plegCh:
if e.Type == pleg.ContainerStarted {
// record the most recent time we observed a container start for this pod.
// this lets us selectively invalidate the runtimeCache when processing a delete for this pod
// to make sure we don't miss handling graceful termination for containers we reported as having started.
kl.lastContainerStartedTime.Add(e.ID, time.Now())
}
if isSyncPodWorthy(e) {
// PLEG event for a pod; sync it.
if pod, ok := kl.podManager.GetPodByUID(e.ID); ok {
klog.V(2).Infof("SyncLoop (PLEG): %q, event: %#v", format.Pod(pod), e)
handler.HandlePodSyncs([]*v1.Pod{pod})
} else {
// If the pod no longer exists, ignore the event.
klog.V(4).Infof("SyncLoop (PLEG): ignore irrelevant event: %#v", e)
}
}
if e.Type == pleg.ContainerDied {
if containerID, ok := e.Data.(string); ok {
kl.cleanUpContainersInPod(e.ID, containerID)
}
}
case <-syncCh:
// Sync pods waiting for sync
podsToSync := kl.getPodsToSync()
if len(podsToSync) == 0 {
break
}
klog.V(4).Infof("SyncLoop (SYNC): %d pods; %s", len(podsToSync), format.Pods(podsToSync))
handler.HandlePodSyncs(podsToSync)
case update := <-kl.livenessManager.Updates():
if update.Result == proberesults.Failure {
// The liveness manager detected a failure; sync the pod.
// We should not use the pod from livenessManager, because it is never updated after
// initialization.
pod, ok := kl.podManager.GetPodByUID(update.PodUID)
if !ok {
// If the pod no longer exists, ignore the update.
klog.V(4).Infof("SyncLoop (container unhealthy): ignore irrelevant update: %#v", update)
break
}
klog.V(1).Infof("SyncLoop (container unhealthy): %q", format.Pod(pod))
handler.HandlePodSyncs([]*v1.Pod{pod})
}
case <-housekeepingCh:
if !kl.sourcesReady.AllReady() {
// If the sources aren't ready or volume manager has not yet synced the states,
// skip housekeeping, as we may accidentally delete pods from unready sources.
klog.V(4).Infof("SyncLoop (housekeeping, skipped): sources aren't ready yet.")
} else {
klog.V(4).Infof("SyncLoop (housekeeping)")
if err := handler.HandlePodCleanups(); err != nil {
klog.Errorf("Failed cleaning pods: %v", err)
}
}
}
return true
}
|
The process of creating a pod
Kubelet pod creation process is triggered by ADD event in configCh, so here is the main flow of Kubelet after receiving ADD event.
Handler
When an ADD event occurs in configCh, the loop will trigger the HandlePodAdditions method of SyncHandler. The flow of this method can be described by the following flowchart.
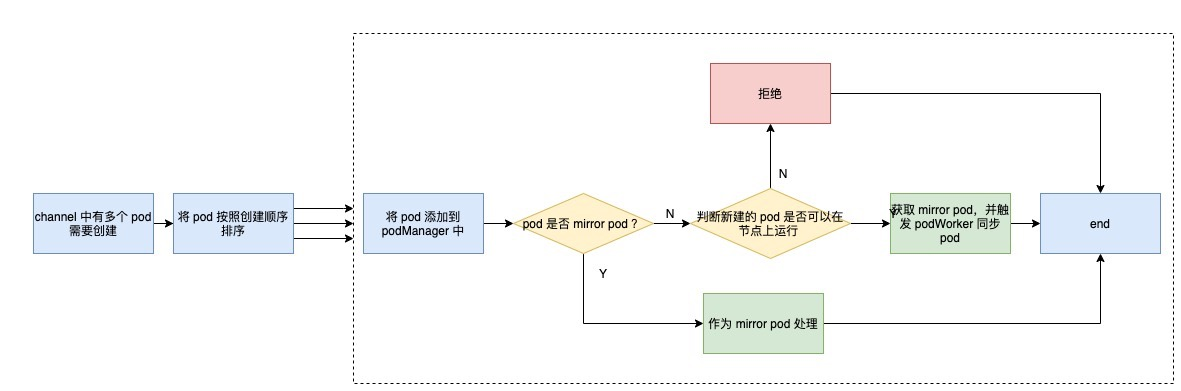
First of all, the handler will sort all the pod installation creation time, and then process them one by one.
First add the pod to the podManager to facilitate subsequent operations; then determine if it is a mirror pod, if it is, it will be treated as a mirror pod, otherwise it will be treated as a normal pod, here is an explanation of mirror pod.
A mirror pod is a copy of the static pod created by the kueblet in the apiserver. Since the static pod is managed directly by Kubelet, apiserver is not aware of the existence of the static pod and its lifecycle is hosted directly by Kubelet. In order to view the corresponding pod via the kubectl command, and to view the static pod’s logs directly via the kubectl logs command, Kubelet creates a mirror pod for each static pod via the apiserver.
The next step is to determine whether the pod can run on the node, which is also known as pod access control in Kubelet. Access control mainly includes these aspects:
- whether the node meets the pod affinity rules
- whether the node has enough resources to allocate to the pod
- whether the node uses HostNetwork or HostIPC, and if so, whether it is in the node’s whitelist
- the /proc mount directory meets the requirements
- whether the pod is configured and whether the correct AppArmor is configured
When all conditions are met, the podWorker is finally triggered to synchronize the pod.
The code corresponding to HandlePodAdditions is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
func (kl *kubelet) HandlePodAdditions(pods []*v1.Pod) {
start := kl.clock.Now()
sort.Sort(sliceutils.PodsByCreationTime(pods))
for _, pod := range pods {
existingPods := kl.podManager.GetPods()
// Always add the pod to the pod manager. Kubelet relies on the pod
// manager as the source of truth for the desired state. If a pod does
// not exist in the pod manager, it means that it has been deleted in
// the apiserver and no action (other than cleanup) is required.
kl.podManager.AddPod(pod)
if kubetypes.IsMirrorPod(pod) {
kl.handleMirrorPod(pod, start)
continue
}
if !kl.podIsTerminated(pod) {
// Only go through the admission process if the pod is not
// terminated.
// We failed pods that we rejected, so activePods include all admitted
// pods that are alive.
activePods := kl.filterOutTerminatedPods(existingPods)
// Check if we can admit the pod; if not, reject it.
if ok, reason, message := kl.canAdmitPod(activePods, pod); !ok {
kl.rejectPod(pod, reason, message)
continue
}
}
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
kl.dispatchWork(pod, kubetypes.SyncPodCreate, mirrorPod, start)
kl.probeManager.AddPod(pod)
}
}
|
The work of podWorkers
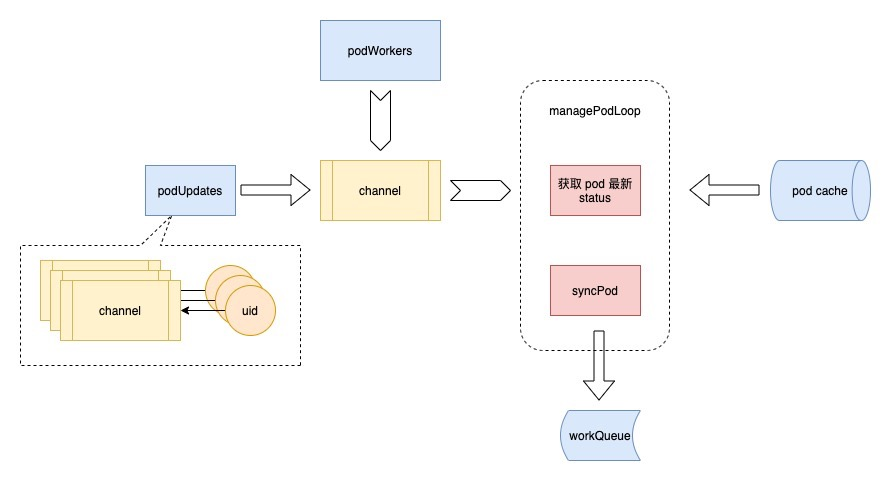
Next, let’s see what podWorker does. podWorker maintains a map called podUpdates, with pod uid as the key, and a channel for each pod; when a pod has an event, it first gets the corresponding channel from this map, then starts a goroutine to listen to this channel, and executes managePodLoop. On the other hand, podWorker passes the pods that need to be synchronized into this channel.
After receiving the event, managePodLoop will first get the latest status of the pod from the pod cache to ensure that the pod currently being processed is up-to-date; then it will call the syncPod method to record the synchronized result in the workQueue and wait for the next scheduled synchronization task.
The whole process is shown in the following figure.
The code in podWorker that handles pod events.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
func (p *podWorkers) UpdatePod(options *UpdatePodOptions) {
pod := options.Pod
uid := pod.UID
var podUpdates chan UpdatePodOptions
var exists bool
p.podLock.Lock()
defer p.podLock.Unlock()
if podUpdates, exists = p.podUpdates[uid]; !exists {
podUpdates = make(chan UpdatePodOptions, 1)
p.podUpdates[uid] = podUpdates
go func() {
defer runtime.HandleCrash()
p.managePodLoop(podUpdates)
}()
}
if !p.isWorking[pod.UID] {
p.isWorking[pod.UID] = true
podUpdates <- *options
} else {
// if a request to kill a pod is pending, we do not let anything overwrite that request.
update, found := p.lastUndeliveredWorkUpdate[pod.UID]
if !found || update.UpdateType != kubetypes.SyncPodKill {
p.lastUndeliveredWorkUpdate[pod.UID] = *options
}
}
}
func (p *podWorkers) managePodLoop(podUpdates <-chan UpdatePodOptions) {
var lastSyncTime time.Time
for update := range podUpdates {
err := func() error {
podUID := update.Pod.UID
status, err := p.podCache.GetNewerThan(podUID, lastSyncTime)
if err != nil {
p.recorder.Eventf(update.Pod, v1.EventTypeWarning, events.FailedSync, "error determining status: %v", err)
return err
}
err = p.syncPodFn(syncPodOptions{
mirrorPod: update.MirrorPod,
pod: update.Pod,
podStatus: status,
killPodOptions: update.KillPodOptions,
updateType: update.UpdateType,
})
lastSyncTime = time.Now()
return err
}()
// notify the call-back function if the operation succeeded or not
if update.OnCompleteFunc != nil {
update.OnCompleteFunc(err)
}
if err != nil {
// IMPORTANT: we do not log errors here, the syncPodFn is responsible for logging errors
klog.Errorf("Error syncing pod %s (%q), skipping: %v", update.Pod.UID, format.Pod(update.Pod), err)
}
p.wrapUp(update.Pod.UID, err)
}
}
|
syncPod
The syncPod method called by the podWorker above in managePodLoop is actually the SyncPod method of the Kubelet object, in the file pkg/kubelet/kubelet.go.
This method is the one that actually interacts with the container runtime layer. First, it determines if it is a kill event, if so, it directly calls the runtime’s killPod; then it determines if it can run on the node, which is the Kubelet access control mentioned above; then it determines if the CNI plugin is ready, if not, it only creates and updates the Then determine whether the pod is a static pod, and if so, create the corresponding mirror pod; then create the directory where the pod needs to be mounted; and finally call syncPod of runtime.
The whole process is shown as follows.
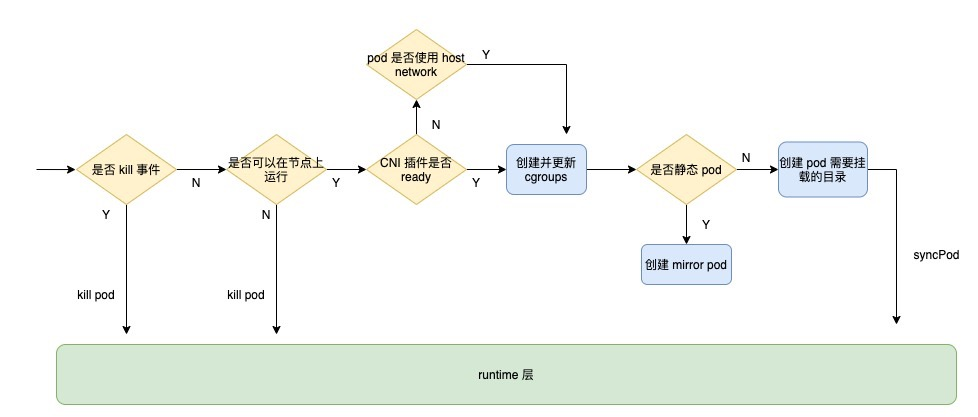
The syncPod code for Kubelet is as follows. To understand the main flow, I removed some of the optimization code, so you can check the source code yourself if you are interested.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
|
func (kl *kubelet) syncPod(o syncPodOptions) error {
// pull out the required options
pod := o.pod
mirrorPod := o.mirrorPod
podStatus := o.podStatus
updateType := o.updateType
// if we want to kill a pod, do it now!
if updateType == kubetypes.SyncPodKill {
...
if err := kl.killPod(pod, nil, podStatus, killPodOptions.PodTerminationGracePeriodSecondsOverride); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToKillPod, "error killing pod: %v", err)
// there was an error killing the pod, so we return that error directly
utilruntime.HandleError(err)
return err
}
return nil
}
...
runnable := kl.canRunPod(pod)
if !runnable.Admit {
...
}
...
// If the network plugin is not ready, only start the pod if it uses the host network
if err := kl.runtimeState.networkErrors(); err != nil && !kubecontainer.IsHostNetworkPod(pod) {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.NetworkNotReady, "%s: %v", NetworkNotReadyErrorMsg, err)
return fmt.Errorf("%s: %v", NetworkNotReadyErrorMsg, err)
}
...
if !kl.podIsTerminated(pod) {
...
if !(podKilled && pod.Spec.RestartPolicy == v1.RestartPolicyNever) {
if !pcm.Exists(pod) {
if err := kl.containerManager.UpdateQOSCgroups(); err != nil {
klog.V(2).Infof("Failed to update QoS cgroups while syncing pod: %v", err)
}
...
}
}
}
// Create Mirror Pod for Static Pod if it doesn't already exist
if kubetypes.IsStaticPod(pod) {
...
}
if mirrorPod == nil || deleted {
node, err := kl.GetNode()
if err != nil || node.DeletionTimestamp != nil {
klog.V(4).Infof("No need to create a mirror pod, since node %q has been removed from the cluster", kl.nodeName)
} else {
klog.V(4).Infof("Creating a mirror pod for static pod %q", format.Pod(pod))
if err := kl.podManager.CreateMirrorPod(pod); err != nil {
klog.Errorf("Failed creating a mirror pod for %q: %v", format.Pod(pod), err)
}
}
}
}
// Make data directories for the pod
if err := kl.makePodDataDirs(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToMakePodDataDirectories, "error making pod data directories: %v", err)
klog.Errorf("Unable to make pod data directories for pod %q: %v", format.Pod(pod), err)
return err
}
// Volume manager will not mount volumes for terminated pods
if !kl.podIsTerminated(pod) {
// Wait for volumes to attach/mount
if err := kl.volumeManager.WaitForAttachAndMount(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedMountVolume, "Unable to attach or mount volumes: %v", err)
klog.Errorf("Unable to attach or mount volumes for pod %q: %v; skipping pod", format.Pod(pod), err)
return err
}
}
// Fetch the pull secrets for the pod
pullSecrets := kl.getPullSecretsForPod(pod)
// Call the container runtime's SyncPod callback
result := kl.containerRuntime.SyncPod(pod, podStatus, pullSecrets, kl.backOff)
kl.reasonCache.Update(pod.UID, result)
if err := result.Error(); err != nil {
// Do not return error if the only failures were pods in backoff
for _, r := range result.SyncResults {
if r.Error != kubecontainer.ErrCrashLoopBackOff && r.Error != images.ErrImagePullBackOff {
// Do not record an event here, as we keep all event logging for sync pod failures
// local to container runtime so we get better errors
return err
}
}
return nil
}
return nil
}
|
The whole process of creating a pod comes to the syncPod part of the runtime layer, so here’s a look at the process here.
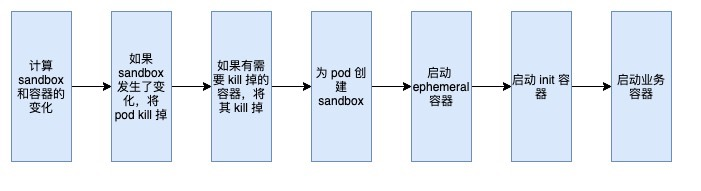
The process is very clear, first calculate the pod sandbox and container changes, if the sandbox has changed, the pod will kill off, and then kill its related containers; then create a sandbox for the pod (whether it is a pod that needs to be newly created or a pod whose sandbox has changed and been deleted); later is to start the ephemeral container, init container and business container.
Among them, the ephemeral container is a new feature of k8s v1.16, which runs temporarily in an existing pod in order to complete user-initiated operations, such as troubleshooting.
The entire code is as follows, and here again some optimization code has been removed to show the main flow.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
func (m *kubeGenericRuntimeManager) SyncPod(pod *v1.Pod, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, backOff *flowcontrol.Backoff) (result kubecontainer.PodSyncResult) {
// Step 1: Compute sandbox and container changes.
podContainerChanges := m.computePodActions(pod, podStatus)
klog.V(3).Infof("computePodActions got %+v for pod %q", podContainerChanges, format.Pod(pod))
if podContainerChanges.CreateSandbox {
ref, err := ref.GetReference(legacyscheme.Scheme, pod)
if err != nil {
klog.Errorf("Couldn't make a ref to pod %q: '%v'", format.Pod(pod), err)
}
...
}
// Step 2: Kill the pod if the sandbox has changed.
if podContainerChanges.KillPod {
killResult := m.killPodWithSyncResult(pod, kubecontainer.ConvertPodStatusToRunningPod(m.runtimeName, podStatus), nil)
result.AddPodSyncResult(killResult)
...
} else {
// Step 3: kill any running containers in this pod which are not to keep.
for containerID, containerInfo := range podContainerChanges.ContainersToKill {
...
if err := m.killContainer(pod, containerID, containerInfo.name, containerInfo.message, nil); err != nil {
killContainerResult.Fail(kubecontainer.ErrKillContainer, err.Error())
klog.Errorf("killContainer %q(id=%q) for pod %q failed: %v", containerInfo.name, containerID, format.Pod(pod), err)
return
}
}
}
...
// Step 4: Create a sandbox for the pod if necessary.
podSandboxID := podContainerChanges.SandboxID
if podContainerChanges.CreateSandbox {
var msg string
var err error
...
podSandboxID, msg, err = m.createPodSandbox(pod, podContainerChanges.Attempt)
if err != nil {
...
}
klog.V(4).Infof("Created PodSandbox %q for pod %q", podSandboxID, format.Pod(pod))
...
}
...
// Step 5: start ephemeral containers
if utilfeature.DefaultFeatureGate.Enabled(features.EphemeralContainers) {
for _, idx := range podContainerChanges.EphemeralContainersToStart {
start("ephemeral container", ephemeralContainerStartSpec(&pod.Spec.EphemeralContainers[idx]))
}
}
// Step 6: start the init container.
if container := podContainerChanges.NextInitContainerToStart; container != nil {
// Start the next init container.
if err := start("init container", containerStartSpec(container)); err != nil {
return
}
...
}
// Step 7: start containers in podContainerChanges.ContainersToStart.
for _, idx := range podContainerChanges.ContainersToStart {
start("container", containerStartSpec(&pod.Spec.Containers[idx]))
}
return
}
|
Finally, let’s look at what sandboxes are. In the field of computer security, a sandbox is a mechanism for isolating a program to limit the privileges of untrustworthy processes. docker uses this technique in containers, creating a sandbox for each container, defining its cgroup and various namespace to isolate the container; each pod in k8s shares a sandbox for each pod in k8s, so all containers in the same pod can interoperate and be isolated from the outside world.
Let’s look at the process of creating a sandbox for a pod in Kubelet. First, define the pod’s DNS configuration, HostName, log path, and sandbox port, which are all shared by the containers in the pod; then define the linux configuration for the pod, including the father cgroup, IPC/Network/Pid namespace, sysctls, and Linux permissions; after everything is configured, then The whole process is as follows.
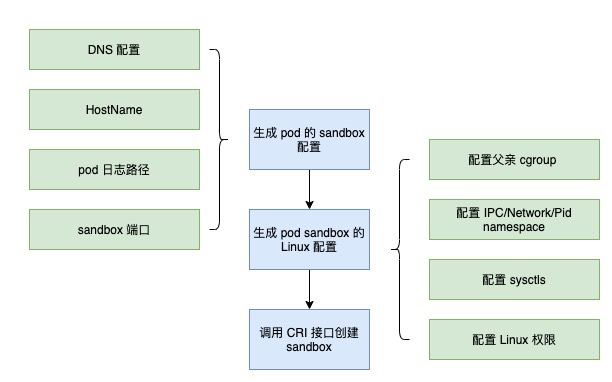
Source code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
|
func (m *kubeGenericRuntimeManager) createPodSandbox(pod *v1.Pod, attempt uint32) (string, string, error) {
podSandboxConfig, err := m.generatePodSandboxConfig(pod, attempt)
...
// Create pod logs directory
err = m.osInterface.MkdirAll(podSandboxConfig.LogDirectory, 0755)
...
podSandBoxID, err := m.runtimeService.RunPodSandbox(podSandboxConfig, runtimeHandler)
...
return podSandBoxID, "", nil
}
func (m *kubeGenericRuntimeManager) generatePodSandboxConfig(pod *v1.Pod, attempt uint32) (*runtimeapi.PodSandboxConfig, error) {
podUID := string(pod.UID)
podSandboxConfig := &runtimeapi.PodSandboxConfig{
Metadata: &runtimeapi.PodSandboxMetadata{
Name: pod.Name,
Namespace: pod.Namespace,
Uid: podUID,
Attempt: attempt,
},
Labels: newPodLabels(pod),
Annotations: newPodAnnotations(pod),
}
dnsConfig, err := m.runtimeHelper.GetPodDNS(pod)
...
podSandboxConfig.DnsConfig = dnsConfig
if !kubecontainer.IsHostNetworkPod(pod) {
podHostname, podDomain, err := m.runtimeHelper.GeneratePodHostNameAndDomain(pod)
podHostname, err = util.GetNodenameForKernel(podHostname, podDomain, pod.Spec.SetHostnameAsFQDN)
podSandboxConfig.Hostname = podHostname
}
logDir := BuildPodLogsDirectory(pod.Namespace, pod.Name, pod.UID)
podSandboxConfig.LogDirectory = logDir
portMappings := []*runtimeapi.PortMapping{}
for _, c := range pod.Spec.Containers {
containerPortMappings := kubecontainer.MakePortMappings(&c)
...
}
if len(portMappings) > 0 {
podSandboxConfig.PortMappings = portMappings
}
lc, err := m.generatePodSandboxLinuxConfig(pod)
...
podSandboxConfig.Linux = lc
return podSandboxConfig, nil
}
// generatePodSandboxLinuxConfig generates LinuxPodSandboxConfig from v1.Pod.
func (m *kubeGenericRuntimeManager) generatePodSandboxLinuxConfig(pod *v1.Pod) (*runtimeapi.LinuxPodSandboxConfig, error) {
cgroupParent := m.runtimeHelper.GetPodCgroupParent(pod)
lc := &runtimeapi.LinuxPodSandboxConfig{
CgroupParent: cgroupParent,
SecurityContext: &runtimeapi.LinuxSandboxSecurityContext{
Privileged: kubecontainer.HasPrivilegedContainer(pod),
SeccompProfilePath: v1.SeccompProfileRuntimeDefault,
},
}
sysctls := make(map[string]string)
if utilfeature.DefaultFeatureGate.Enabled(features.Sysctls) {
if pod.Spec.SecurityContext != nil {
for _, c := range pod.Spec.SecurityContext.Sysctls {
sysctls[c.Name] = c.Value
}
}
}
lc.Sysctls = sysctls
if pod.Spec.SecurityContext != nil {
sc := pod.Spec.SecurityContext
if sc.RunAsUser != nil {
lc.SecurityContext.RunAsUser = &runtimeapi.Int64Value{Value: int64(*sc.RunAsUser)}
}
if sc.RunAsGroup != nil {
lc.SecurityContext.RunAsGroup = &runtimeapi.Int64Value{Value: int64(*sc.RunAsGroup)}
}
lc.SecurityContext.NamespaceOptions = namespacesForPod(pod)
if sc.FSGroup != nil {
lc.SecurityContext.SupplementalGroups = append(lc.SecurityContext.SupplementalGroups, int64(*sc.FSGroup))
}
if groups := m.runtimeHelper.GetExtraSupplementalGroupsForPod(pod); len(groups) > 0 {
lc.SecurityContext.SupplementalGroups = append(lc.SecurityContext.SupplementalGroups, groups...)
}
if sc.SupplementalGroups != nil {
for _, sg := range sc.SupplementalGroups {
lc.SecurityContext.SupplementalGroups = append(lc.SecurityContext.SupplementalGroups, int64(sg))
}
}
if sc.SELinuxOptions != nil {
lc.SecurityContext.SelinuxOptions = &runtimeapi.SELinuxOption{
User: sc.SELinuxOptions.User,
Role: sc.SELinuxOptions.Role,
Type: sc.SELinuxOptions.Type,
Level: sc.SELinuxOptions.Level,
}
}
}
return lc, nil
}
|
Summary
The core work of Kubelet revolves around the control loop, which uses go’s channel as a basis for the producer and consumer to work together to make the control loop work and achieve the desired state.