The database used by Open Hackathon is MongoDB, and in containerization, the security of data is a top priority.
Storage issues
Stateful applications need to use PersistentVolume when deployed on Kubernetes, but if the underlying PV storage is unreliable, even with PV, data security is still not guaranteed.
In a general usage scenario, the application needs to define a PersistentVolumeClaim to describe the required storage resources and use the PersistentVolumeClaim in the Pod, and the cluster will create or find a PersistentVolumeClaim based on the description in the PersistentVolumeClaim. PersistentVolume, so when the Pod reads and writes to the Volume in the container, the data is persisted to the PersistentVolume.
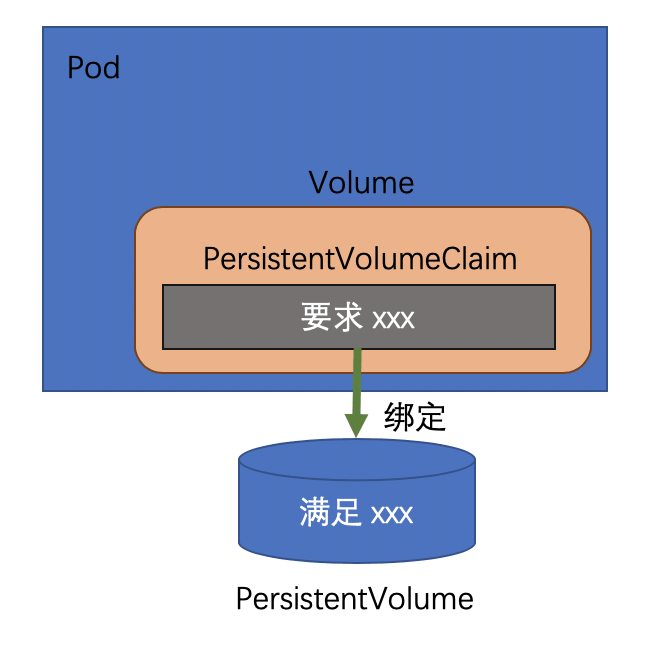
There are two ways to create PersistentVolume, the first one is to create several PersistentVolume manually by the cluster administrator, when PersistentVolumeClaim is created, the cluster will look for PersistentVolume that meets the requirements and bind to it. When PersistentVolumeClaim is deleted, the binding relationship is released and PersistentVolume is triggered by the recycling policy.
The second way is to create a default StorageClass and use the underlying storage that supports auto-expansion, when PersistentVolumeClaim is created, the cluster will automatically create a PersistentVolume in the underlying storage and bind to it. When PersistentVolumeClaim is deleted, PersistentVolume is automatically cleaned up as well.
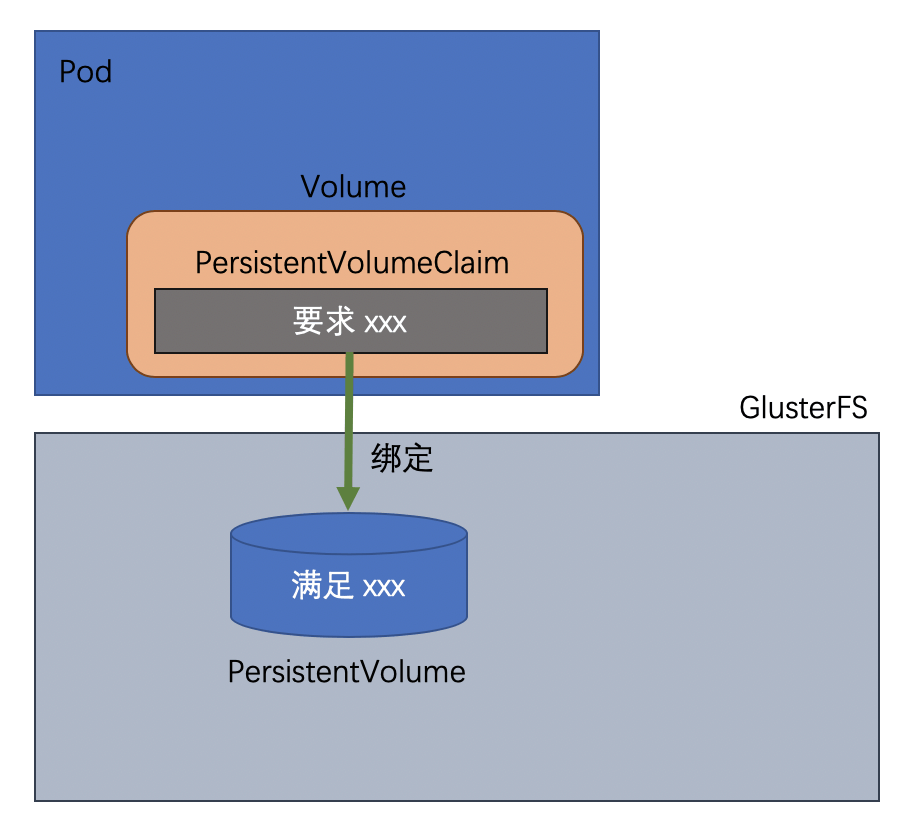
But no matter which of these two approaches, you need to consider what the underlying storage is, i.e. where exactly the PersistentVolume data is stored. If you are building your own cluster, you can consider Ceph, GlusterFS.
For public cloud services, you can consider the storage service provided by the service provider, for example, in Huawei Cloud CCE (hosted Kubernetes cluster), you can use cloud hard disk for the underlying storage: https://support.huaweicloud.com/usermanual-cce/cce_01_0044.html
|
|
Single Instance Deployment
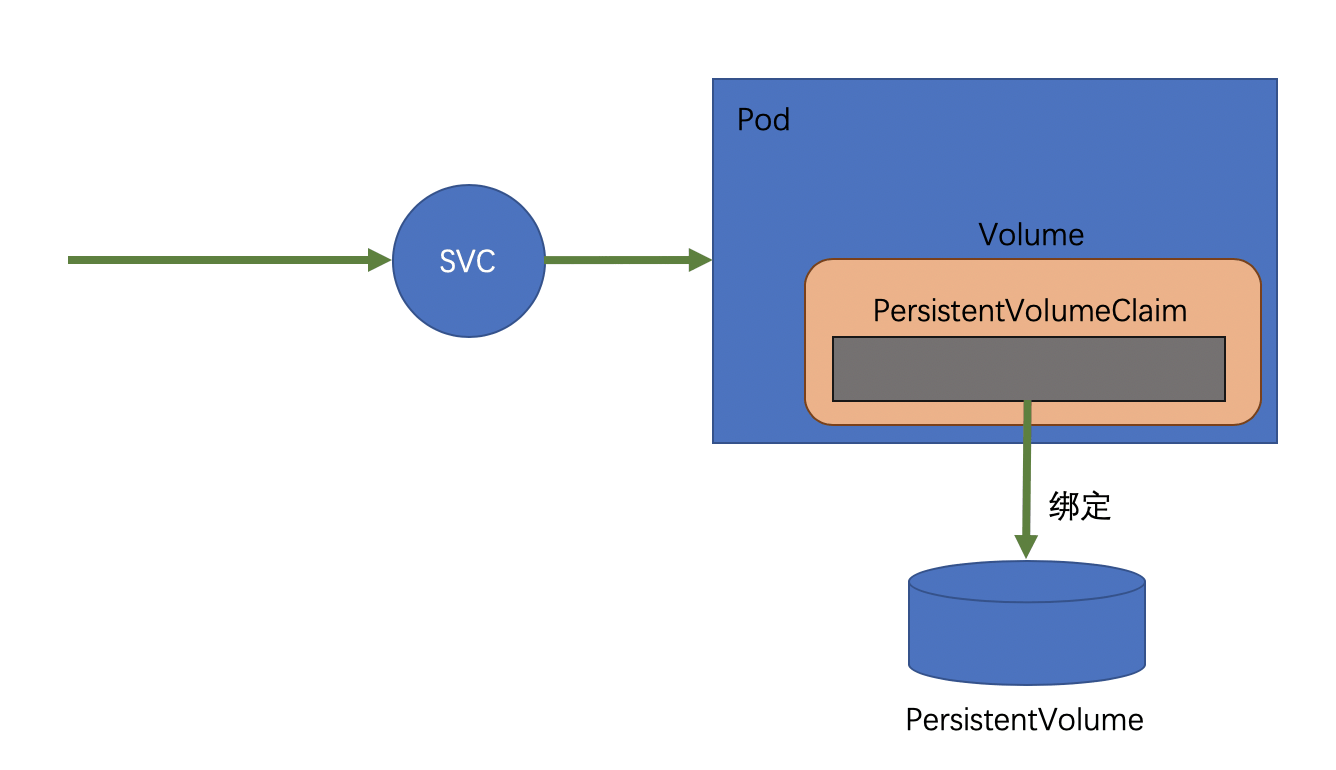
For scenarios without high availability requirements, you can use single-instance deployments, where you only need to run one instance of MongoDB and mount a persistable store for that instance.
|
|
There are two points to note.
- Mongo’s authentication username and password are configured in
Secret. - The SVC specifies that the ClusterIP is None, which means that the service will be resolved to PodIP directly.
- the Deployment’s publishing policy is to rebuild, because PV can only be mounted to one Pod, so you should avoid multiple Pods at the same time (the Deployment can not be expanded).
High Availability Cluster
There are many options for Mongo to do HA, there is a post in Kubernetes Blog about how to build HA mongoDB using GCE, using the replica set high availability solution, the replica set solution should be the simplest in Kubernetes, only need to define a StatefulSet can be solved.
The StatefulSet maintains multiple Pods, each of which has a PV for persistent storage.
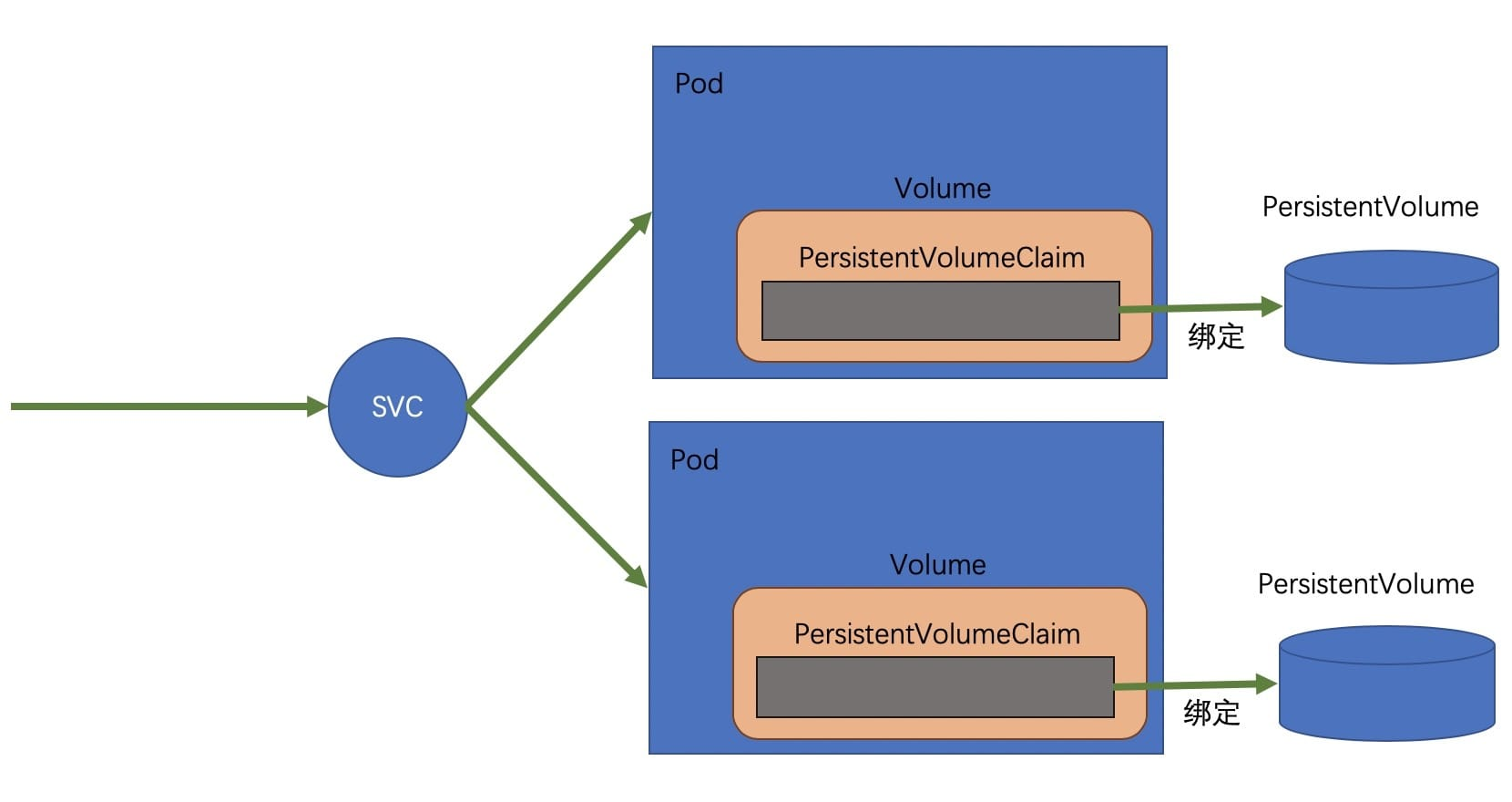
For details, please refer to: Running MongoDB on Kubernetes with StatefulSets