This article is based on reading the source code of Kubernetes v1.16. The article has some source code, but I will try to describe it clearly by matching pictures
In the Kubernetes Master node, there are three important components: ApiServer, ControllerManager, and Scheduler, which are responsible for the management of the whole cluster together. In this article, we try to sort out the workflow and principle of ControllerManager.
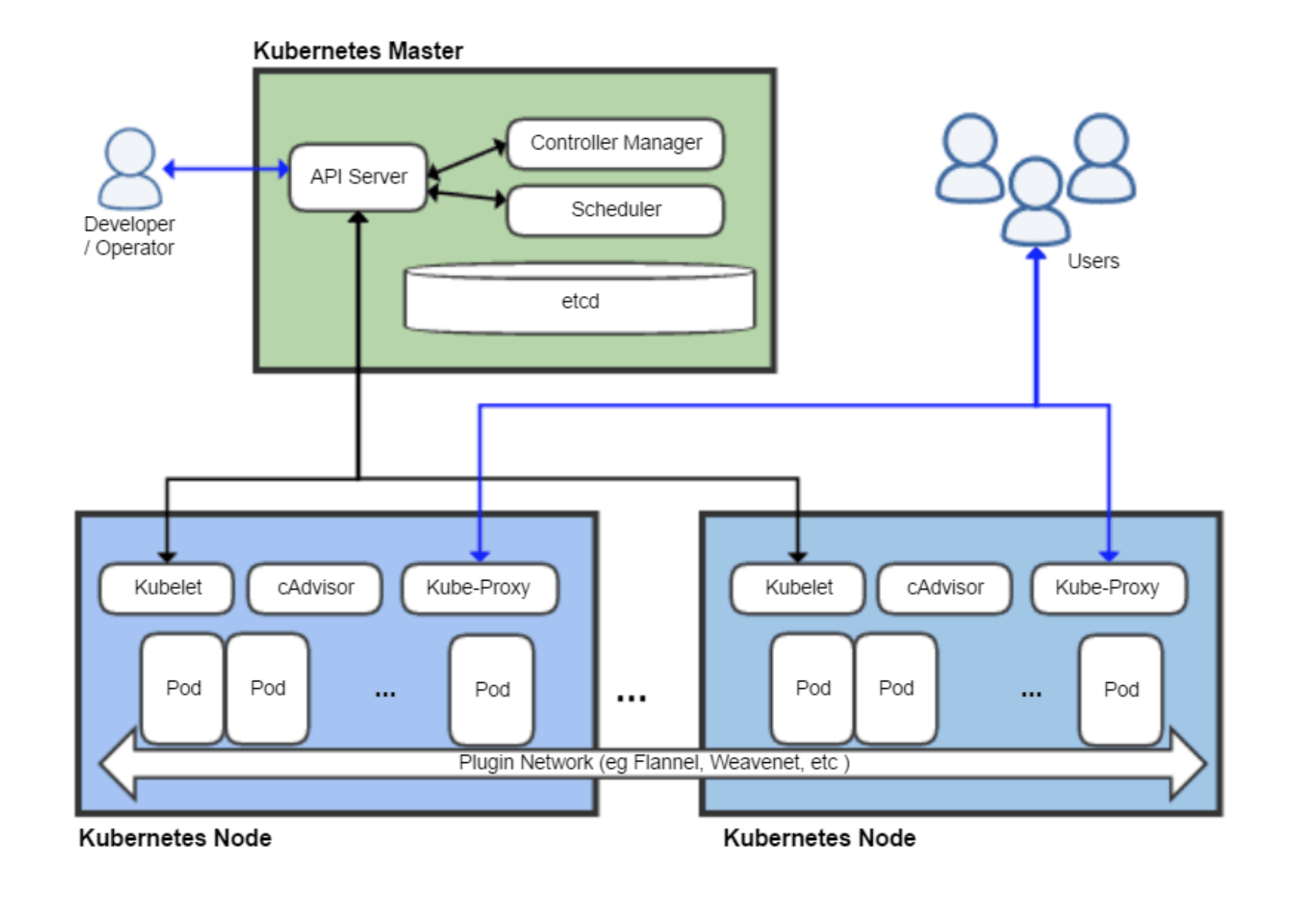
What is Controller Manager
According to the official documentation: kube-controller-manager runs controllers, which are background threads that handle regular tasks in the cluster.
For example, when a Pod created through Deployment exits abnormally, the RS Controller will accept and handle the exit and create a new Pod to maintain the expected number of copies.
Almost every specific resource is managed by a specific Controller to maintain the expected state, and it is the Controller Manager’s responsibility to aggregate all the Controllers:
- provide infrastructure to reduce the complexity of Controller implementation
- start and maintain the Controller’s uptime
In this way, Controller ensures that the resources in the cluster remain in the expected state, and Controller Manager ensures that the Controller remains in the expected state.
Controller Workflow
Before we explain how the Controller Manager provides the infrastructure and runtime environment for the Controller, let’s understand what the Controller workflow looks like.
From a high-dimensional perspective, Controller Manager mainly provides the ability to distribute events, while different Controllers only need to register the corresponding Handler to wait for receiving and processing events.
Take Deployment Controller as an example, the NewDeploymentController method in pkg/controller/deployment/deployment_controller.go includes the registration of Event Handler, for For Deployment Controller, you only need to implement different processing logic according to different events, and then you can achieve the management of the corresponding resources.
|
|
As you can see, with the help of the Controller Manager, the logic of the Controller can be done very purely by implementing the corresponding EventHandler, so what specific work does the Controller Manager do?
Controller Manager Architecture
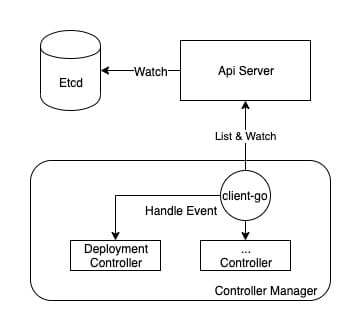
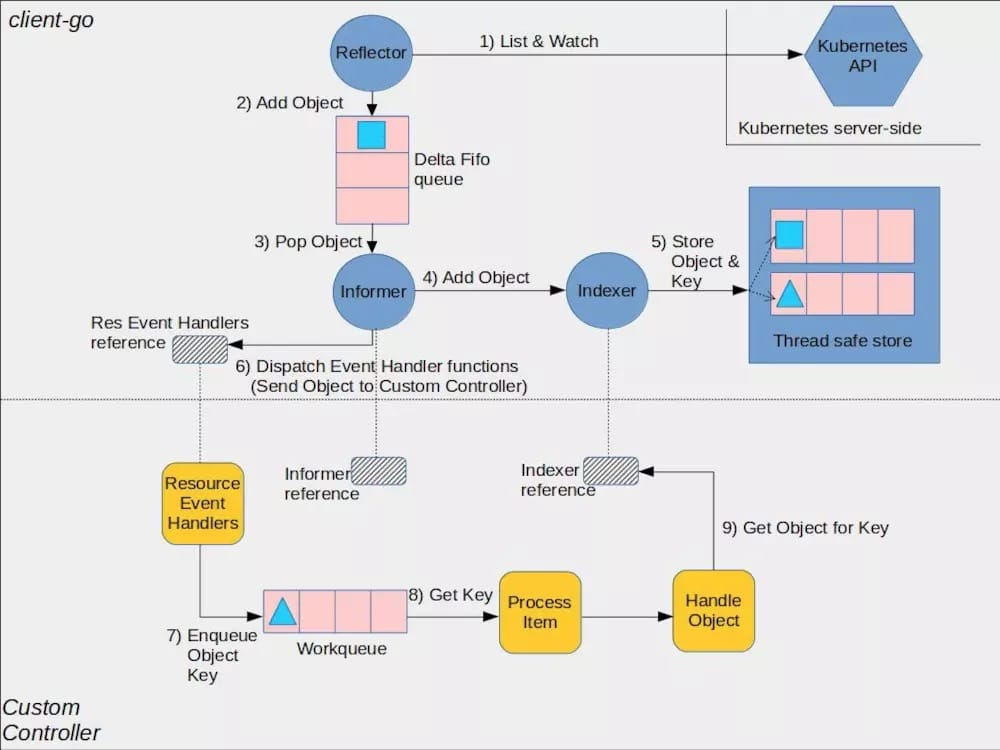
The key module that aids the Controller Manager in event distribution is client-go, and one of the more critical modules is informer.
kubernetes provides an architecture diagram of client-go on github, from which you can see that the Controller is the bottom half (CustomController) of the description, while the Controller Manager is mainly the top half of the completion.
Informer Factory
As you can see from the above diagram, Informer is a very critical “bridge”, so the management of Informer is the first thing that Controller Manager does.
Since each Informer maintains a watch long connection to the Api Server, this single instance factory ensures that each type of Informer is instantiated only once by providing a unique entry point for all Controllers to get an Informer.
The initialization logic of this singleton factory.
|
|
As you can see from the initialization logic above, the most important part of the sharedInformerFactory is the map named informers, where the key is the resource type and the value is the Informer that cares about that resource type. each type of Informer will be instantiated only once and stored in the map. Different Controllers will only get the same Informer instance when they need the same resource.
For Controller Manager, maintaining all the Informers to work properly is the basic condition for all Controllers to work properly. The sharedInformerFactory maintains all informer instances through this map, so the sharedInformerFactory also takes the responsibility of providing a unified startup portal.
|
|
When the Controller Manager starts, the most important thing is to run all the Informers through the Start method of this factory.
Informer creation
Here’s how these Informers are created, the Controller Manager is initialized in the NewControllerInitializers function in cmd/kube-controller-manager/app/controllermanager.go. Because of the lengthy code, here is an example of the Deployment Controller only.
The logic for initializing the Deployment Controller is in the startDeploymentController function in cmd/kube-controller-manager/app/apps.go.
|
|
The most critical logic is in deployment.NewDeploymentController, which actually creates the Deployment Controller, and the first three parameters of the creation function are Deployment, ReplicaSet, and Pod’s Informer. As you can see, the Informer’s singleton factory provides an entry point for creating Informers with different resources using the ApiGroup as the path.
However, it is important to note that.Apps().V1().Deployments() returns an instance of type deploymentInformer, but deploymentInformer is not really an Informer (despite its Informer name). It is just a template class whose main function is to provide templates for the creation of Informers focused on Deployment as a specific resource.
The real logic for creating an Informer is in deploymentInformer.Informer() (client-go/informers/apps/v1/deployment.go), and f.defaultInformer is the default Deployment Informer creation template method to create an Informer that focuses only on Deployment resources by passing the resource instance and this template method into the InformerFor method of the Informer factory.
To briefly explain.
- you can get an Informer template class of a specific type through the Informer factory (i.e.
deploymentInformerin this case) - it is the
Informer()method of the Informer template class that actually creates the Informer for that particular resource. 3. - the
Informer()method just creates the real Informer through theInformerForof the Informer factory
The template method (design pattern) is used here, and although it’s a bit convoluted, you can refer to the following diagram to sort it out. The key to understanding it is that the Informer’s differentiated creation logic is delegated to the template class.
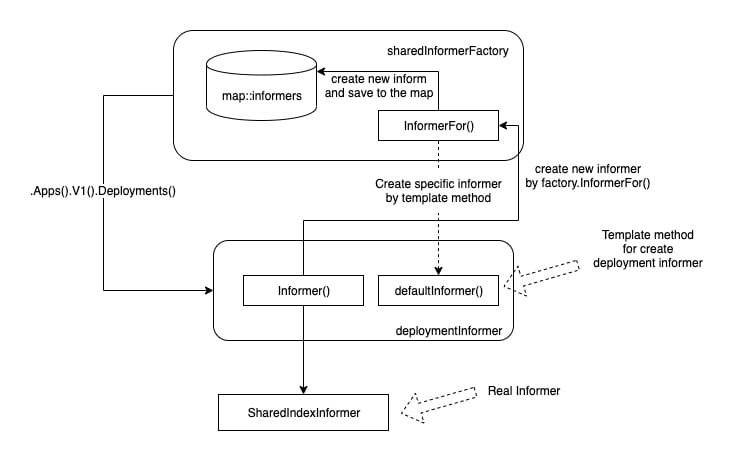
Finally, the structure named sharedIndexInformer will be instantiated and will actually take on the responsibilities of the Informer. It is also the instance that is registered to the Informer factory map.
Informer operation
Since the real Informer instance is an object of type sharedIndexInformer, when the Informer factory is started (by executing the Start method), it is the sharedIndexInformer that is actually run.
The sharedIndexInformer is a component in client-go, and its Run method is a few dozen lines long, but it does a lot of work. This is where we get to the most interesting part of the Controller Manager.
|
|
The startup logic of sharedIndexInformer does several things.
- creates a queue named
fifo. - creates and runs an instance called
controller. - started
cacheMutationDetector. - started
processor.
These terms (or components) were not mentioned in the previous article, but these four things are the core of what the Controller Manager does, so I’ll cover each of them below.
sharedIndexInformer
sharedIndexInformer is a shared Informer framework where different Controllers only need to provide a template class (like the deploymentInformer mentioned above) to create an Informer specific to their needs.
The sharedIndexInformer contains a bunch of tools to do the Informer’s job, and the main code is in client-go/tools/cache/shared_informer.go. Its creation logic is also in there.
|
|
In the creation logic, there are several things to look out for:
- processor: provides the function of EventHandler registration and event distribution
- indexer: provides resource caching functionality
- listerWatcher: provided by the template class, contains the List and Watch methods for a specific resource
- objectType: used to mark which specific resource type to focus on
- cacheMutationDetector: monitors the Informer’s cache
In addition, it also contains the DeltaFIFO queue and controller mentioned in the startup logic above, which are described below.
sharedProcessor
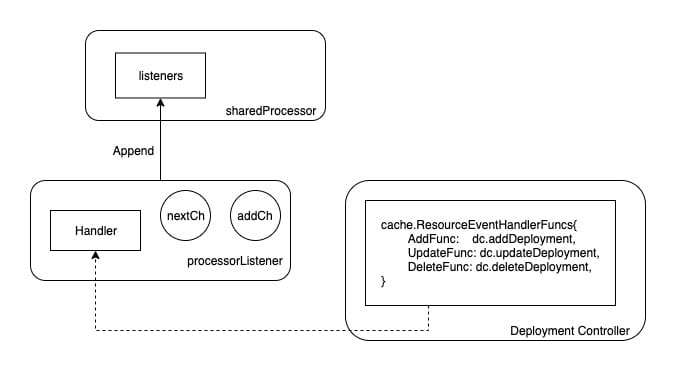
processor is a very interesting component in sharedIndexInformer. Controller Manager ensures that different Controllers share the same Informer through an Informer singleton factory, but different Controllers have different Handlers registered to the shared Informer.
The processor is the component that manages the registered Handlers and distributes events to different Handlers.
The core of sharedProcessor’s work revolves around the Listener slice of listeners.
When we register a Handler to the Informer, it is eventually converted into an instance of a structure called processorListener.
|
|
This instance contains mainly two channels and the Handler method registered outside. The processorListener object instantiated here will eventually be added to the sharedProcessor.listeners list.
As shown in the diagram, the Handler method in the Controller will eventually be added to the Listener, which will be appended to the Listeners slice of the sharedProcessor.
As mentioned before, sharedIndexInformer will run sharedProcessor when it starts, and the logic for starting sharedProcessor is related to these listeners.
|
|
As you can see, sharedProcessor will execute the run and pop methods of listener in sequence when it starts, so let’s look at these two methods now.
Starting the listener
Since the listener contains the Handler methods registered with the Controller, the most important function of the listener is to trigger these methods when an event occurs, and listener.run is to keep getting events from the nextCh channel and executing the corresponding handler.
|
|
You can see that listener.run keeps getting events from the nextCh channel, but where do the events in the nextCh channel come from? It is the responsibility of listener.pop to put the events in nextCh.
listener.pop is a very clever and interesting piece of logic.
|
|
The reason why listener contains two channels: addCh and nextCh is that Informer cannot predict whether listener.handler is consuming events faster than they can be produced, so it adds a buffer called pendingNotifications. queue to hold events that have not been consumed in time.
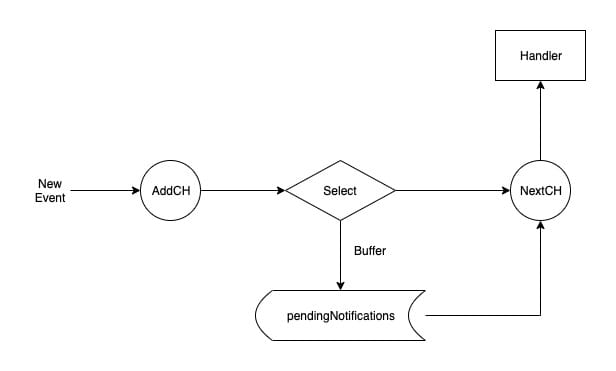
The pop method, on the one hand, keeps getting the latest events from addCh to make sure the producer doesn’t block. Then it determines if a buffer exists, and if it does, it adds the event to the buffer, and if not, it tries to push it to nextCh.
On the other hand, it determines if there are any events left in the buffer, and if there is still stock, it keeps passing it to nextCh.
The pop method implements a distribution mechanism with a buffer that allows events to be continuously passed from addCh to nextCh. But the question arises, where do the addCh events come from?
The source is very simple, listener has an add method with an event as input, which pushes the new event into addCh. The add method is called by the sharedProcessor that manages all the listeners.
As mentioned above, the sharedProcessor is responsible for managing all the Handlers and distributing events, but it is the distribute method that does the real distributing.
|
|
So far, we have a clearer picture of one part:
- the Controller registers the Handler with the Informer.
- Informer maintains all Handlers (listener) through
sharedProcessor. - Informer receives the event and distributes it through
sharedProcessor.distribute. - the Controller is triggered by the corresponding Handler to handle its own logic
So the remaining question is where do the Informer events come from?
DeltaFIFO
Before analyzing the Informer fetch event, a very interesting gadget that needs to be told in advance is the fifo queue created during sharedIndexInformer.Run.
|
|
DeltaFIFO is a very interesting queue, the code for which is defined in client-go/tools/cache/delta_fifo.go. The most important thing for a queue is definitely the Add and Pop methods. DeltaFIFO provides several Add methods, and although different methods are distinguished according to different event types (add/update/delete/sync), they all end up executing queueActionLocked.
|
|
The first parameter of the queueActionLocked method, actionType, is the event type.
The event type and the incoming queue method show that this is a queue with business functions, not just “first in, first out”, and there are two very clever designs in the incoming queue method.
- the events in the queue will first determine if there are unconsumed events for the resource, and then handle them appropriately.
- if the list method finds that the resource has already been deleted, it will not be processed.
The second point is easier to understand, if a list request is triggered and the resource to be processed is found to have been deleted, then it does not need to be queued again. The first point needs to be seen together with the out of queue method.
|
|
DeltaFIFO’s Pop method has one input, which is the handler function. When it comes out of the queue, DeltaFIFO will first get the resource all events according to the resource id, and then hand it over to the handler function.
The workflow is shown in the figure.
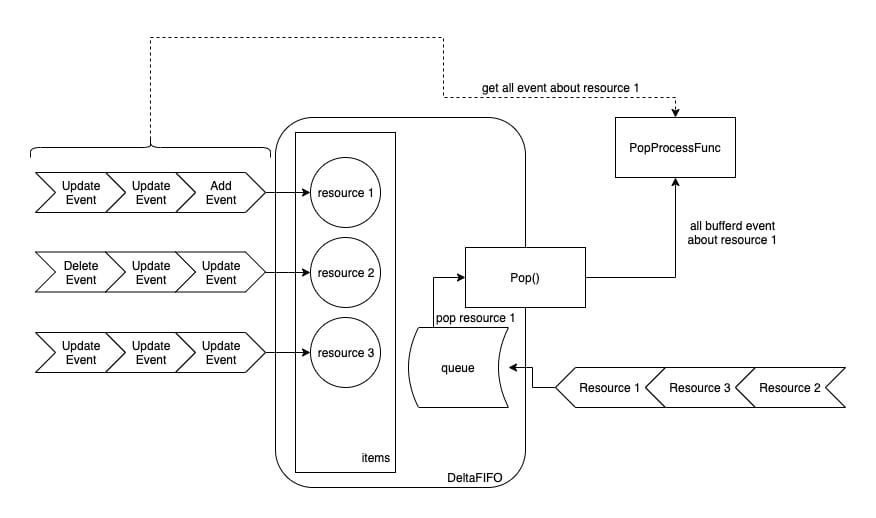
In general, DeltaFIFO’s queue method first determines if the resource is already in items, and if it is, the resource is not yet consumed (still queued), so it appends the event directly to items[resource_id]. If it is not in items, then items[resource_id] is created and the resource id is appended to queue.
The DeltaFIFO out-of-queue method gets the resource id at the top of the queue from queue, then takes all the events for that resource from items, and finally calls the PopProcessFunc type handler passed in by the Pop method.
So, the feature of DeltaFIFO is that it is the events (of the resource) that are in the queue, and when it comes out of the queue, it gets all the events of the first resource in the queue. This design ensures that there is no starvation due to a resource creating events like crazy, so that other resources do not have the chance to be processed.
controller
DeltaFIFO is a very important component, and the only thing that really makes it valuable is the Informer controller.
While the K8s source code does use the word controller, this controller is not a resource controller like a Deployment Controller. Rather, it is a top-down event controller (taking events from the API Server and sending them down to the Informer for processing).
The responsibilities of the controller are twofold.
- get events from the Api Server via List-Watch and push the events into DeltaFIFO
- call the Pop method of DeltaFIFO with the
HandleDeltasmethod of thesharedIndexInformeras an argument
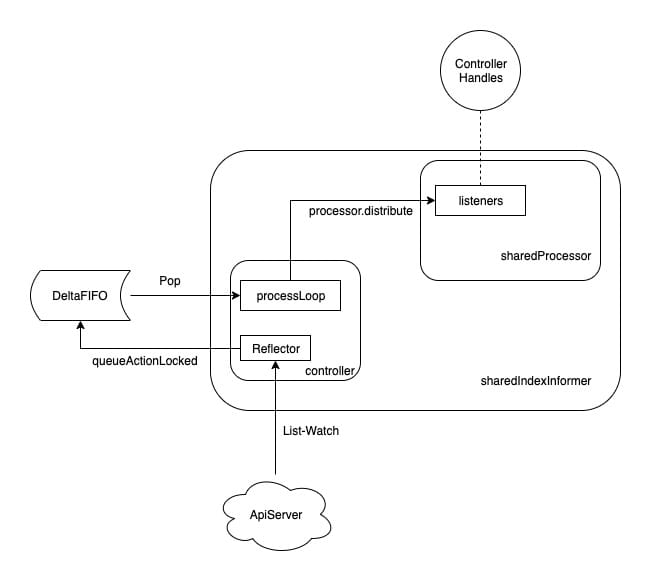
The definition of controller is very simple and its core is Reflector.
The code of Reflector is rather cumbersome but simple, it is to list-watch through the listerWatcher defined in sharedIndexInformer and push the obtained events into the DeltaFIFO.
After the controller starts, it starts the Reflector and then executes the processLoop, which is a dead loop that keeps reading the resource events from the DeltaFIFO and handing them to the HandleDeltas method of the sharedIndexInformer (assigned to config. Process).
|
|
If we look at the HandleDeltas method of the sharedIndexInformer, we can see that the whole event consumption process works.
|
|
We learned earlier that the processor.attribute method distributes events to all listeners, and the controller uses the Reflector to get the events from the ApiServer and put them in the queue, then takes the events from the queue via the processLoop for the resource to be processed, and finally calls the processor.attribute via the HandleDeltas method of the sharedIndexInformer. All events, and finally the processor.attribute is called via the HandleDeltas method of the sharedIndexInformer.
Thus, we can organize the entire flow of events as follows.
Indexer
Above, we have sorted out all the logic from receiving to distributing events, but in the HandleDeltas method of sharedIndexInformer, there is some logic that is more interesting, that is, all events are updated to s.indexer first and then distributed.
As mentioned earlier, the Indexer is a thread-safe store, used as a cache in order to relieve the pressure on the ApiServer when the resource controller (Controller) queries the resource.
When there is any event update, the cache in Indexer will be refreshed first, and then the event will be distributed to the resource controller, who will get the resource details from Indexer first, thus reducing unnecessary query requests to the APIServer.
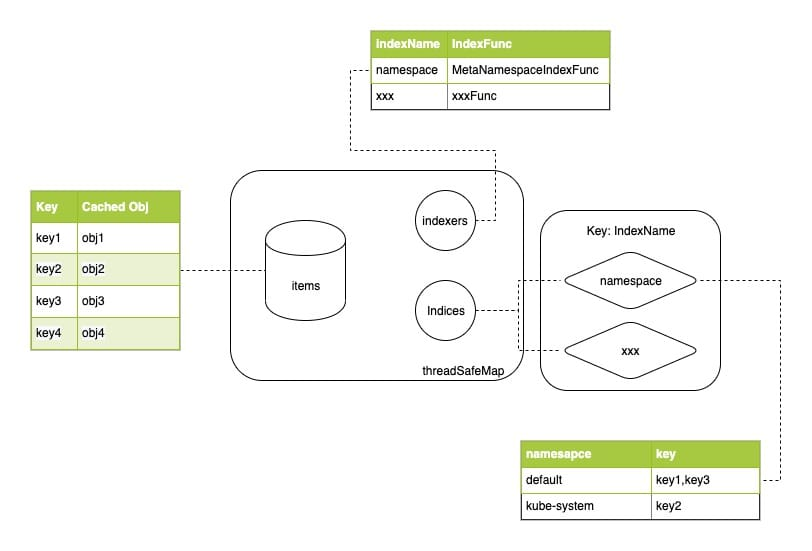
The specific implementation of Indexer storage is in client-go/tools/cache/thread_safe_store.go, and the data is stored in threadSafeMap.
In essence, threadSafeMap is a map with a read/write lock, in addition to which it is possible to define indexes, which are interestingly implemented by two fields.
Indexersis a map that defines a number of indexing functions, key is indexName and value is the indexing function (which calculates the index value of the resource).Indicesholds the mapping between index values and data keys,Indicesis a two-level map, the key of the first level is indexName, which corresponds toIndexersand determines what method is used to calculate the index value, and value is a map that holds the association “index value - resource key” association.
The relevant logic is relatively simple and can be found in the following diagram.
MutationDetector
The HandleDeltas method of the sharedIndexInformer updates data to the s.indexer in addition to the s.cacheMutationDetector.
As mentioned at the beginning, when sharedIndexInformer starts, it also starts a cacheMutationDetector to monitor the indexer’s cache.
Because the indexer cache is actually a pointer, multiple Controllers accessing the indexer’s cached resources actually get the same resource instance. If one Controller does not play nice and modifies the properties of a resource, it will definitely affect the correctness of other Controllers.
When the Informer receives a new event, the MutationDetector saves a pointer to the resource (as does the indexer) and a deep copy of the resource. By periodically checking whether the resource pointed to by the pointer matches the deep copy stored at the beginning, we know whether the cached resource has been modified.
However, whether monitoring is enabled or not is affected by the environment variable KUBE_CACHE_MUTATION_DETECTOR. If this environment variable is not set, sharedIndexInformer instantiates dummyMutationDetector and does nothing after startup.
If KUBE_CACHE_MUTATION_DETECTOR is true, sharedIndexInformer instantiates defaultCacheMutationDetector, which performs periodic checks of the cache at 1s intervals, triggering a failure handler function if it finds the cache modified, or a panic if the function is not defined.
Summary
This article explains the Controller Manager in a narrow sense, as it does not include a specific resource manager (Controller), but only explains how the Controller Manager “Manages Controller”.
You can see that the Controller Manager does a lot of work to ensure that the Controller can focus only on the events it cares about, and the core of this work is the Informer. When you understand how the Informer works with other components, it becomes clear what the Controller Manager paves the way for the Resource Manager.