
As we all know, Go is a programming language with garbage collection (GC), so developers usually don’t need to think about memory management, which reduces the mental burden, and while the Go program is running, the GC is quietly working behind the scenes to do the “aftercare “ for the developer: releasing the memory objects that can’t be reached periodically for subsequent reuse.
GC only cares about pointer, as long as there is a pointer in the scanned memory object, it will “follow the path” and find out the “network” where the memory object is located, and those memory objects that are isolated in this “network” are the ones to be scanned. The memory objects that are isolated outside this “net” are the objects to be “cleaned”.
So how does the GC determine if there is a pointer in a memory object during a scan? Let’s talk about it in this article!
Difference between having pointers and not having pointers in memory objects
In an article “Avoiding high GC overhead with large heaps” published in Gopher Academy Blog 2018, the author has used two examples to compare the difference in GC behavior between memory objects with pointers and without pointers. We excerpt these two examples, the first of which is as follows.
1
2
3
4
5
6
7
8
9
10
11
12
|
// demo1.go
func main() {
a := make([]*int, 1e9)
for i := 0; i < 10; i++ {
start := time.Now()
runtime.GC()
fmt.Printf("GC took %s\n", time.Since(start))
}
runtime.KeepAlive(a)
}
|
KeepAlive function is called in the program to ensure that the slice a is not released by GC before the function call point.
We see: demo1 declares a slice variable a containing 1 billion *int, then calls runtime.GC function to manually trigger the GC process and measure the execution time of each GC, let’s see the result of this program (virtualbox virtual machine ubuntu 20.04/go 1.18beta2).
1
2
3
4
5
6
7
8
9
10
11
|
$ go run demo1.go
GC took 698.46522ms
GC took 325.315425ms
GC took 321.959991ms
GC took 326.775531ms
GC took 333.949713ms
GC took 332.350721ms
GC took 328.1664ms
GC took 329.905988ms
GC took 328.466344ms
GC took 330.327066ms
|
We see that each round of GC calls is quite time consuming. Let’s look at a second example.
1
2
3
4
5
6
7
8
9
10
11
12
|
// demo2.go
func main() {
a := make([]int, 1e9)
for i := 0; i < 10; i++ {
start := time.Now()
runtime.GC()
fmt.Printf("GC took %s\n", time.Since(start))
}
runtime.KeepAlive(a)
}
|
This example simply changes the element type of the slice from *int to int. Let’s run this second example.
1
2
3
4
5
6
7
8
9
10
11
|
$ go run demo2.go
GC took 3.486008ms
GC took 1.678019ms
GC took 1.726516ms
GC took 1.13208ms
GC took 1.900233ms
GC took 1.561631ms
GC took 1.899654ms
GC took 7.302686ms
GC took 131.371494ms
GC took 1.138688ms
|
In our experimental environment the performance of each GC round in demo2 is more than 300 times that of demo1! The only difference between the two demos is the element type of the slice. demo1 has an int pointer type, and the GC will scan the billion pointers stored in the slice every time it is triggered, which is why demo1 GC function takes a long time to execute. The sliced elements in demo2 are of type int. From the results of demo2, the GC does not take care of the a in demo2, which is the reason why the execution time of demo2 GC function is shorter (I tested it: in my environment, even if I don’t declare the sliced a and just execute the runtime.GC function 10 times, the average execution time of the function is 1ms or so).
From the above differences in GC behavior, we know that GC can know whether a slice a contains a pointer or not by its type, and then decide whether to scan it further. Let’s see how GC detects that a memory object contains a pointer.
Go is a static language, each variable has its own attributed type and when the variable is allocated on the heap, the memory object on the heap has its own attributed type. the Go compiler creates corresponding type information for each type in the Go application at the compilation stage, which is reflected in the runtime._rtype structure, the Go reflect package’s rtype struct is equivalent to runtime._rtype.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// $GOROOT/src/reflect/type.go
// rtype is the common implementation of most values.
// It is embedded in other struct types.
//
// rtype must be kept in sync with ../runtime/type.go:/^type._type.
type rtype struct {
size uintptr
ptrdata uintptr // number of bytes in the type that can contain pointers
hash uint32 // hash of type; avoids computation in hash tables
tflag tflag // extra type information flags
align uint8 // alignment of variable with this type
fieldAlign uint8 // alignment of struct field with this type
kind uint8 // enumeration for C
// function for comparing objects of this type
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
gcdata *byte // garbage collection data
str nameOff // string form
ptrToThis typeOff // type for pointer to this type, may be zero
}
|
The gcdata field in this structure type is for the GC, so let’s see what it really is! How do we see it? Since the reflect.rtype type is a non-export type, we need to do some hacking of the native Go language source code. I add a line of code before the definition of the rtype structure in the type.go file of the reflect package.
We use the type alias mechanism introduced in Go 1.9 to export rtype so that we can use reflect.Rtype outside the standard library.
Some of you may ask: Will the Go compiler use the latest source code to compile our Go example program after changing the local Go standard library source code? You can experiment with it yourself.
Let’s get a slice of the type corresponding to the rtype, to see what the gcdata is?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
// demo4.go
package main
import (
"fmt"
"reflect"
"unsafe"
)
type tflag uint8
type nameOff int32 // offset to a name
type typeOff int32 // offset to an *rtype
type rtype struct {
size uintptr
ptrdata uintptr // number of bytes in the type that can contain pointers
hash uint32 // hash of type; avoids computation in hash tables
tflag tflag // extra type information flags
align uint8 // alignment of variable with this type
fieldAlign uint8 // alignment of struct field with this type
kind uint8 // enumeration for C
// function for comparing objects of this type
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
gcdata *byte // garbage collection data
str nameOff // string form
ptrToThis typeOff // type for pointer to this type, may be zero
}
func bar() []*int {
t := make([]*int, 8 )
return t
}
func main() {
t := bar()
v := reflect.TypeOf(t)
rtyp, ok := v.(*reflect.Rtype)
if !ok {
println("error")
return
}
r := (*rtype)(unsafe.Pointer(rtyp))
fmt.Printf("%#v\n", *r)
fmt.Printf("*gcdata = %d\n", *(r.gcdata))
}
|
The bar function returns a sliced instance t allocated on the heap, we get the type information of t by reflect.TypeOf, by type assertion we get the rtype information of the type: rtyp, but gcdata is also a non-export field and is a pointer, we want to dereference it, we define a local rtype type here again locally, the for exporting the value of the memory pointed to by gcdata.
Run this example.
1
2
3
|
$go run demo4.go
main.rtype{size:0x18, ptrdata:0x8, hash:0xaad95941, tflag:0x2, align:0x8, fieldAlign:0x8, kind:0x17, equal:(func(unsafe.Pointer, unsafe.Pointer) bool)(nil), gcdata:(*uint8)(0x10c1b58), str:3526, ptrToThis:0}
*gcdata = 1
|
We see that gcdata points to a byte of memory with a value of 1 (0b00000001 in binary). The value on each bit of this byte pointed to by gcdata represents whether an 8-byte block of memory contains a pointer or not. Such a byte identifies whether each 8-byte memory cell in a 64-byte memory block contains a pointer. If the type length exceeds 64 bytes, then the gcdata used to represent the pointer map also points to more than 1 byte of valid bytes.
The slice type is represented in the runtime layer as the following structure.
1
2
3
4
5
6
7
|
// $GOROOT/src/runtime/slice.go
type slice struct {
array unsafe.Pointer
len int
cap int
}
|
Here the size of the slice type structure after memory alignment is 24, which is less than 64 bytes, so Go uses one byte to represent the pointer map of the slice type. And *gcdata=1, i.e. the bit on the lowest bit is 1, which means a pointer is stored in the first 8 bytes of the slice type. It is a bit easier to understand with the following schematic diagram.
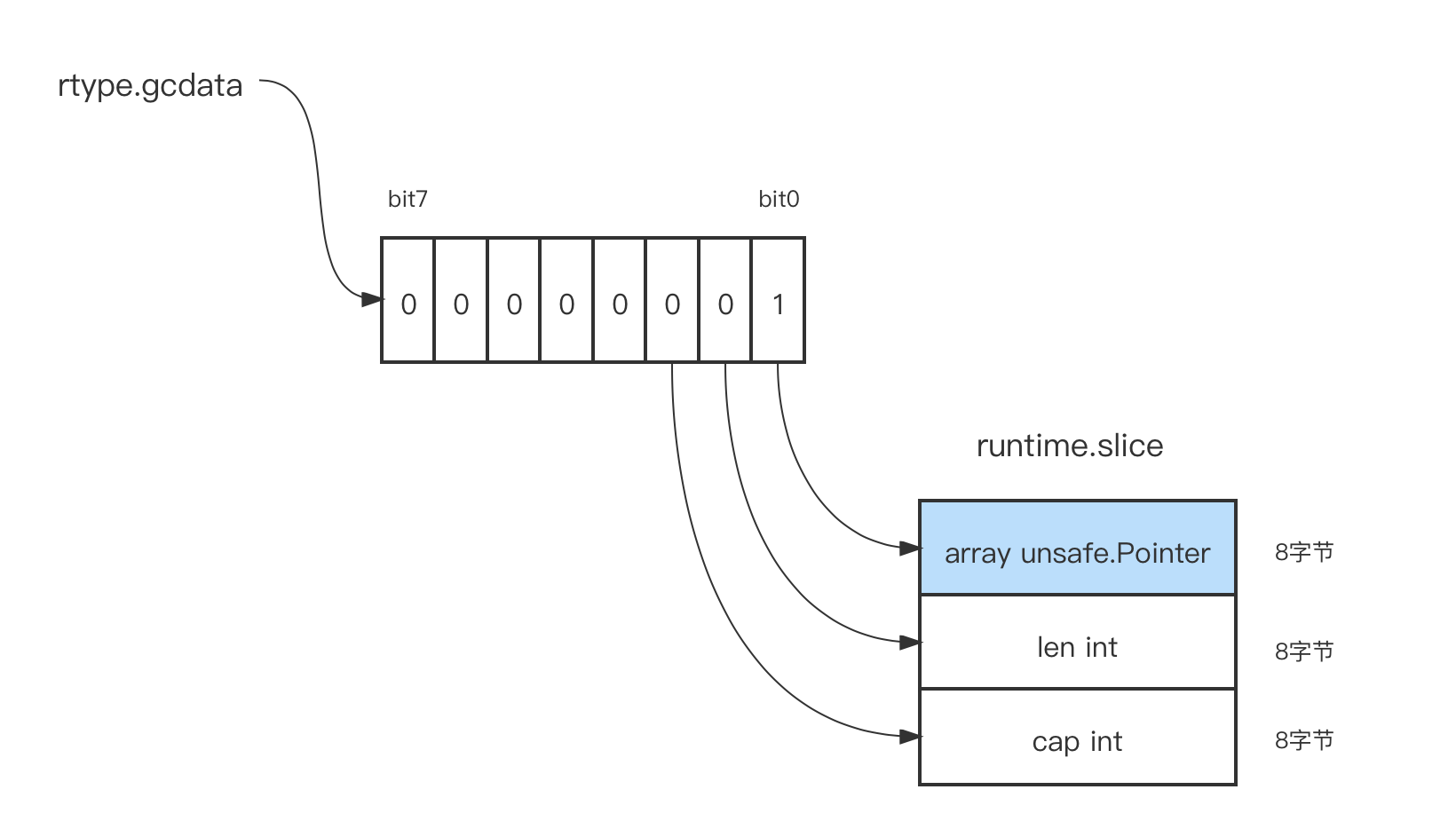
We can also further check whether each element in the slice contains a pointer. Since the elements of this slice are of the pointer type, the value of the bitmap pointed to by rtype.gcdata of each element should be 1. Let’s verify this.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
//demo5.go
... ...
func main() {
t := bar()
v := reflect.ValueOf(t)
for i := 0; i < len(t); i++ {
v1 := v.Index(i)
vtyp := v1.Type()
rtyp, ok := vtyp.(*reflect.Rtype)
if !ok {
println("error")
return
}
r := (*rtype)(unsafe.Pointer(rtyp))
fmt.Printf("%#v\n", *r)
fmt.Printf("*gcdata = %d\n", *(r.gcdata))
}
}
|
This example outputs a bitmap of each slice element, with the following result.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
$go run demo5.go
gomain.rtype{size:0x8, ptrdata:0x8, hash:0x2522ebe7, tflag:0x8, align:0x8, fieldAlign:0x8, kind:0x36, equal:(func(unsafe.Pointer, unsafe.Pointer) bool)(0x1002c40), gcdata:(*uint8)(0x10c1be0), str:566, ptrToThis:0}
*gcdata = 1
main.rtype{size:0x8, ptrdata:0x8, hash:0x2522ebe7, tflag:0x8, align:0x8, fieldAlign:0x8, kind:0x36, equal:(func(unsafe.Pointer, unsafe.Pointer) bool)(0x1002c40), gcdata:(*uint8)(0x10c1be0), str:566, ptrToThis:0}
*gcdata = 1
main.rtype{size:0x8, ptrdata:0x8, hash:0x2522ebe7, tflag:0x8, align:0x8, fieldAlign:0x8, kind:0x36, equal:(func(unsafe.Pointer, unsafe.Pointer) bool)(0x1002c40), gcdata:(*uint8)(0x10c1be0), str:566, ptrToThis:0}
*gcdata = 1
main.rtype{size:0x8, ptrdata:0x8, hash:0x2522ebe7, tflag:0x8, align:0x8, fieldAlign:0x8, kind:0x36, equal:(func(unsafe.Pointer, unsafe.Pointer) bool)(0x1002c40), gcdata:(*uint8)(0x10c1be0), str:566, ptrToThis:0}
*gcdata = 1
main.rtype{size:0x8, ptrdata:0x8, hash:0x2522ebe7, tflag:0x8, align:0x8, fieldAlign:0x8, kind:0x36, equal:(func(unsafe.Pointer, unsafe.Pointer) bool)(0x1002c40), gcdata:(*uint8)(0x10c1be0), str:566, ptrToThis:0}
*gcdata = 1
main.rtype{size:0x8, ptrdata:0x8, hash:0x2522ebe7, tflag:0x8, align:0x8, fieldAlign:0x8, kind:0x36, equal:(func(unsafe.Pointer, unsafe.Pointer) bool)(0x1002c40), gcdata:(*uint8)(0x10c1be0), str:566, ptrToThis:0}
*gcdata = 1
main.rtype{size:0x8, ptrdata:0x8, hash:0x2522ebe7, tflag:0x8, align:0x8, fieldAlign:0x8, kind:0x36, equal:(func(unsafe.Pointer, unsafe.Pointer) bool)(0x1002c40), gcdata:(*uint8)(0x10c1be0), str:566, ptrToThis:0}
*gcdata = 1
main.rtype{size:0x8, ptrdata:0x8, hash:0x2522ebe7, tflag:0x8, align:0x8, fieldAlign:0x8, kind:0x36, equal:(func(unsafe.Pointer, unsafe.Pointer) bool)(0x1002c40), gcdata:(*uint8)(0x10c1be0), str:566, ptrToThis:0}
*gcdata = 1
|
The output matches the expected result.
Let’s look at another example of a type that cannot be represented by a single-byte bitmap.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
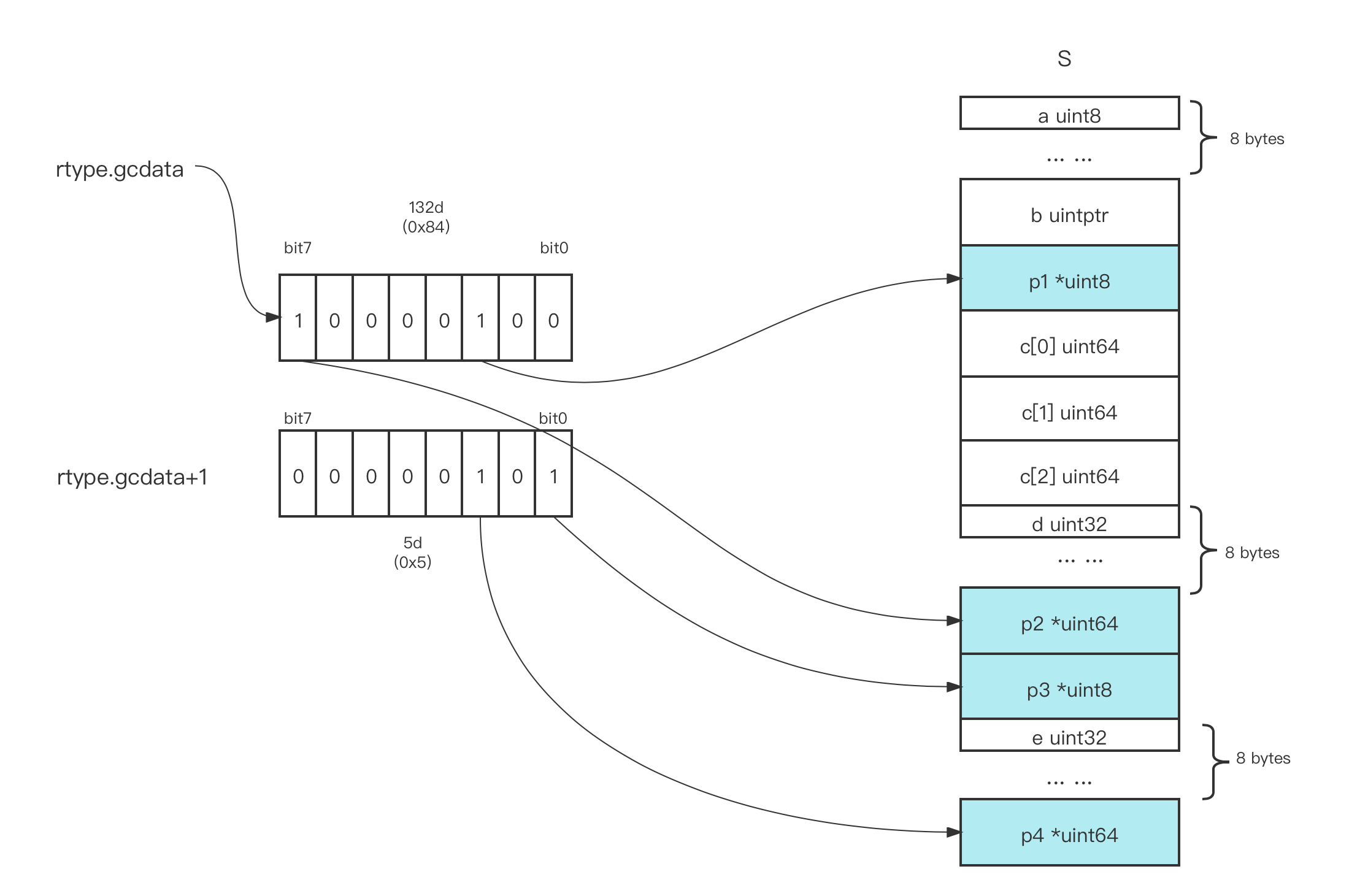
// demo6.go
... ...
type S struct { // 起始地址
a uint8 // 0
b uintptr // 8
p1 *uint8 // 16
c [3]uint64 // 24
d uint32 // 48
p2 *uint64 // 56
p3 *uint8 // 64
e uint32 // 72
p4 *uint64 // 80
}
func foo() *S {
t := new(S)
return t
}
func main() {
t := foo()
println(unsafe.Sizeof(*t)) // 88
typ := reflect.TypeOf(t)
rtyp, ok := typ.Elem().(*reflect.Rtype)
if !ok {
println("error")
return
}
fmt.Printf("%#v\n", *rtyp)
r := (*rtype)(unsafe.Pointer(rtyp))
fmt.Printf("%#v\n", *r)
fmt.Printf("%d\n", *(r.gcdata))
gcdata1 := (*byte)(unsafe.Pointer(uintptr(unsafe.Pointer(r.gcdata)) + 1))
fmt.Printf("%d\n", *gcdata1)
}
|
In this example, we define a very large structure type S with a size of 88. It is impossible to represent its bitmap with one byte, so Go uses two bytes, and we output the bitmap of these two bytes.
1
2
3
4
5
6
|
$go run demo6.go
88
reflect.rtype{size:0x58, ptrdata:0x58, hash:0xcdb468b2, tflag:0x7, align:0x8, fieldAlign:0x8, kind:0x19, equal:(func(unsafe.Pointer, unsafe.Pointer) bool)(0x108aea0), gcdata:(*uint8)(0x10c135b), str:3593, ptrToThis:19168}
main.rtype{size:0x58, ptrdata:0x58, hash:0xcdb468b2, tflag:0x7, align:0x8, fieldAlign:0x8, kind:0x19, equal:(func(unsafe.Pointer, unsafe.Pointer) bool)(0x108aea0), gcdata:(*uint8)(0x10c135b), str:3593, ptrToThis:19168}
132
5
|
We convert the results into a schematic diagram, as follows.
A prerequisite for understanding the structure size above and the starting address of each field is understanding memory alignment.