I read an article earlier: Handling 1 Million Requests per Minute with Go.
Today I stumbled upon another article. The principle of the two articles is similar: there are a number of work tasks (jobs), through the work-pool (worker-pool) way, to achieve the effect of multiple worker concurrent processing job.
There are still many differences between them, and the differences in implementation are quite big.
Here is a picture, which is roughly the overall workflow in the first article.
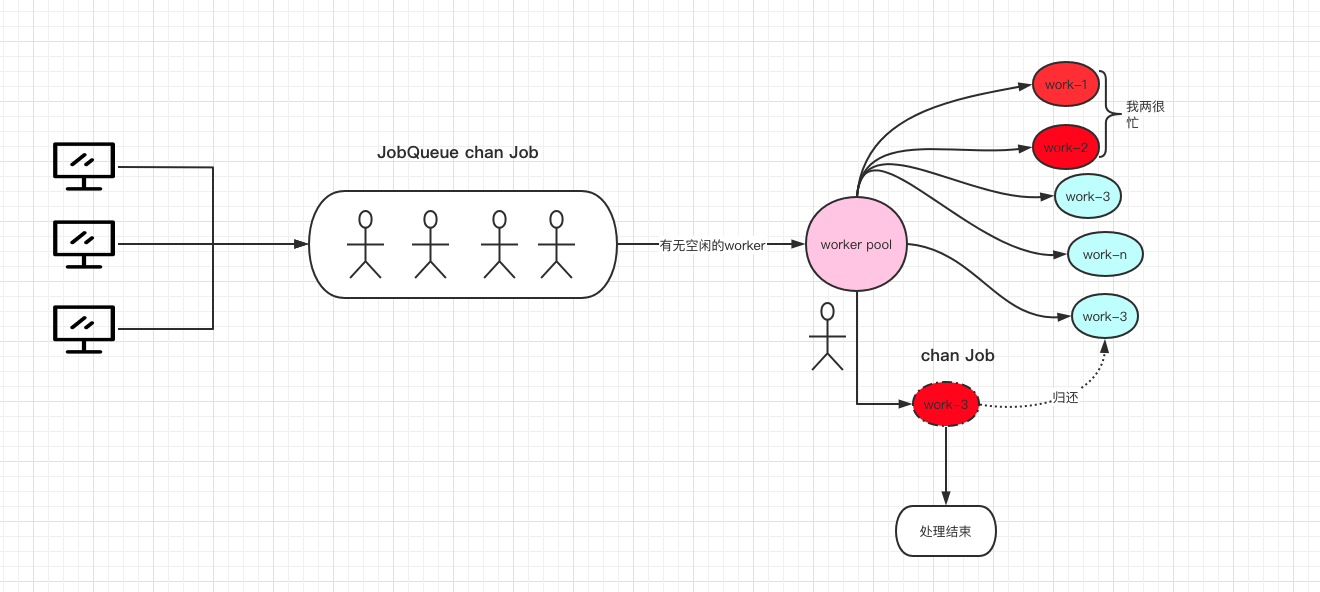
- Each
worker just processes the task and doesn’t care about the result, and doesn’t do further processing on the result.
- As long as the request does not stop, the program will not stop, there is no control mechanism, unless it is down.
The difference in this article is:
First the data will be aggregated from generate (produce data) -> concurrently process data -> process the result. The flowchart is roughly like this.
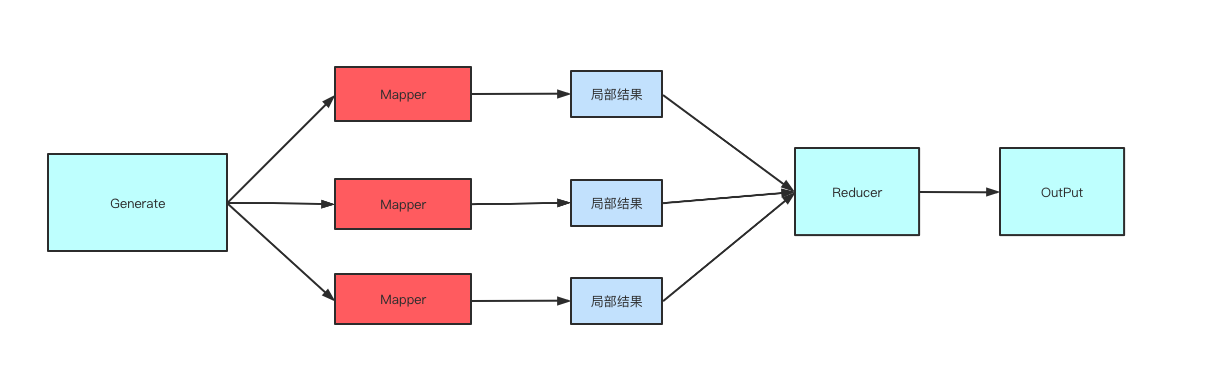
Then it can achieve the effect of controlling the work pool to stop working through context.context.
Finally, through the code, you will see that it is not a worker-pool in the traditional sense, as will be explained later.
The following diagram clearly shows the overall flow.
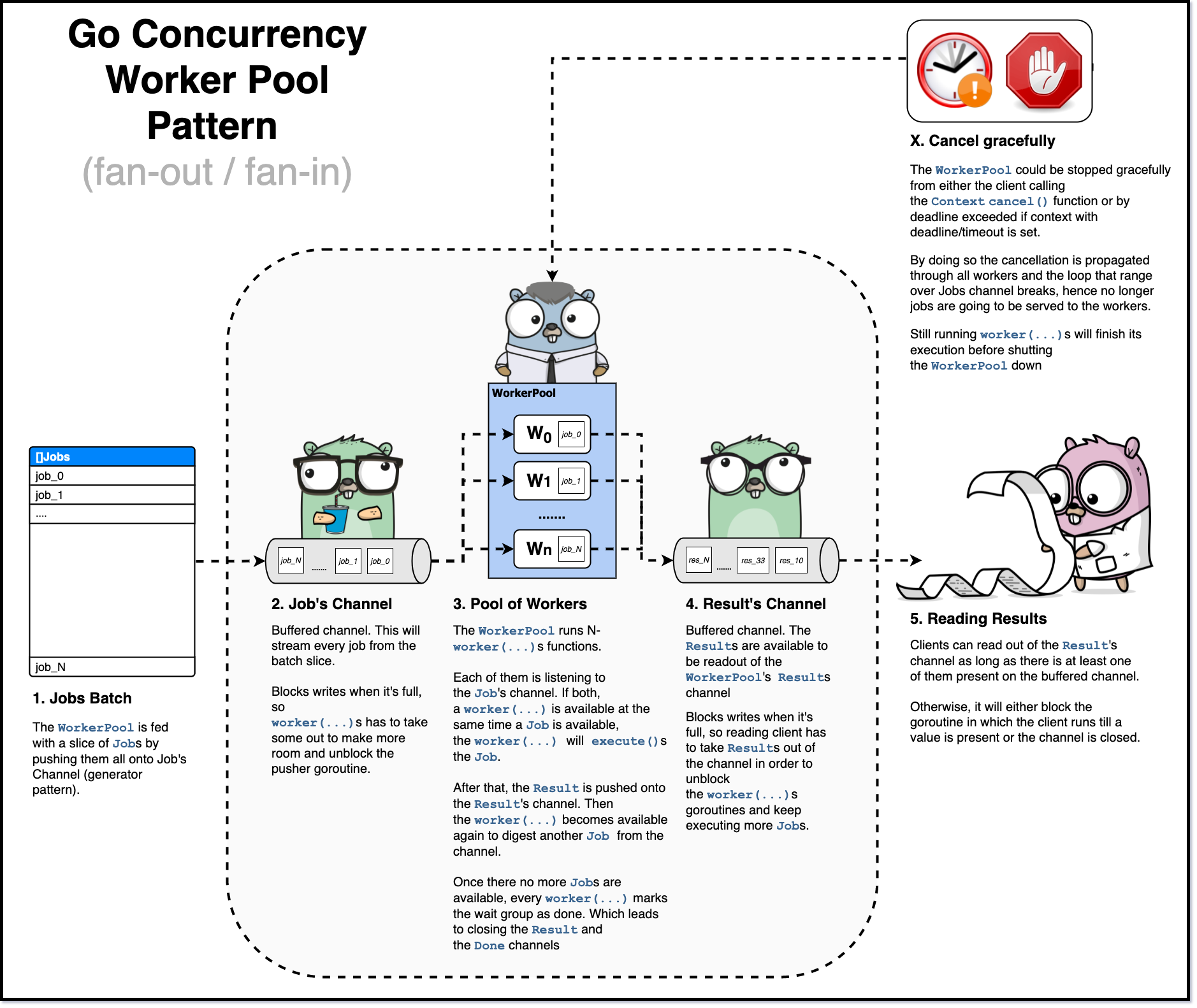
By the way, the code implemented in this article is much simpler than the code for Handling 1 Million Requests per Minute with Go.
First look at job.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
package wpool
import (
"context"
)
type JobID string
type jobType string
type jobMetadata map[string]interface{}
type ExecutionFn func(ctx context.Context, args interface{}) (interface{}, error)
type JobDescriptor struct {
ID JobID
JType jobType
Metadata map[string]interface{}
}
type Result struct {
Value interface{}
Err error
Descriptor JobDescriptor
}
type Job struct {
Descriptor JobDescriptor
ExecFn ExecutionFn
Args interface{}
}
// 处理 job 逻辑,处理结果包装成 Result 结果
func (j Job) execute(ctx context.Context) Result {
value, err := j.ExecFn(ctx, j.Args)
if err != nil {
return Result{
Err: err,
Descriptor: j.Descriptor,
}
}
return Result{
Value: value,
Descriptor: j.Descriptor,
}
}
|
This can be done briefly. Eventually each job will be wrapped into a Result after processing and returned.
The following section is the core code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
package wpool
import (
"context"
"fmt"
"sync"
)
// 运行中的每个worker
func worker(ctx context.Context, wg *sync.WaitGroup, jobs <-chan Job, results chan<- Result) {
defer wg.Done()
for {
select {
case job, ok := <-jobs:
if !ok {
return
}
results <- job.execute(ctx)
case <-ctx.Done():
fmt.Printf("cancelled worker. Error detail: %v\n", ctx.Err())
results <- Result{
Err: ctx.Err(),
}
return
}
}
}
type WorkerPool struct {
workersCount int //worker 数量
jobs chan Job // 存储 job 的 channel
results chan Result // 处理完每个 job 对应的 结果集
Done chan struct{} //是否结束
}
func New(wcount int) WorkerPool {
return WorkerPool{
workersCount: wcount,
jobs: make(chan Job, wcount),
results: make(chan Result, wcount),
Done: make(chan struct{}),
}
}
func (wp WorkerPool) Run(ctx context.Context) {
var wg sync.WaitGroup
for i := 0; i < wp.workersCount; i++ {
wg.Add(1)
go worker(ctx, &wg, wp.jobs, wp.results)
}
wg.Wait()
close(wp.Done)
close(wp.results)
}
func (wp WorkerPool) Results() <-chan Result {
return wp.results
}
func (wp WorkerPool) GenerateFrom(jobsBulk []Job) {
for i, _ := range jobsBulk {
wp.jobs <- jobsBulk[i]
}
close(wp.jobs)
}
|
The entire WorkerPool structure is simple. jobs is a cache channel. Each task is put into jobs and waits to be processed by woker.
results is also a channel type, and its role is to hold the result Result of each job processing.
First initialize a worker-pool with New, and then execute Run to start running.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func New(wcount int) WorkerPool {
return WorkerPool{
workersCount: wcount,
jobs: make(chan Job, wcount),
results: make(chan Result, wcount),
Done: make(chan struct{}),
}
}
func (wp WorkerPool) Run(ctx context.Context) {
var wg sync.WaitGroup
for i := 0; i < wp.workersCount; i++ {
wg.Add(1)
go worker(ctx, &wg, wp.jobs, wp.results)
}
wg.Wait()
close(wp.Done)
close(wp.results)
}
|
When initializing, we pass in the worker number, which corresponds to each g running work(ctx,&wg,wp.jobs,wp.results) , which forms the worker-pool. WaitGroup, we can wait for allworkerjobs to finish, which means that thework-pool` is finished, but of course it could be because the job processing is finished, or it could be stopped.
How does each job data source come from?
1
2
3
4
5
6
7
|
// job数据源,把每个 job 放入到 jobs channel 中
func (wp WorkerPool) GenerateFrom(jobsBulk []Job) {
for i, _ := range jobsBulk {
wp.jobs <- jobsBulk[i]
}
close(wp.jobs)
}
|
corresponds to the work of each worker.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func worker(ctx context.Context, wg *sync.WaitGroup, jobs <-chan Job, results chan<- Result) {
defer wg.Done()
for {
select {
case job, ok := <-jobs:
if !ok {
return
}
results <- job.execute(ctx)
case <-ctx.Done():
fmt.Printf("cancelled worker. Error detail: %v\n", ctx.Err())
results <- Result{
Err: ctx.Err(),
}
return
}
}
}
|
Each worker tries to fetch data from the same jobs, which is a typical fan-out pattern. When the corresponding g gets the jobs for processing, it sends the result to the same results channel, which is another fan-in pattern. Contextallows us to do stop-run control for eachworker`.
Finally, there is the collection of processing results.
1
2
3
4
|
// 处理结果集
func (wp WorkerPool) Results() <-chan Result {
return wp.results
}
|
Then the overall test code is :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
func TestWorkerPool(t *testing.T) {
wp := New(workerCount)
ctx, cancel := context.WithCancel(context.TODO())
defer cancel()
go wp.GenerateFrom(testJobs())
go wp.Run(ctx)
for {
select {
case r, ok := <-wp.Results():
if !ok {
continue
}
i, err := strconv.ParseInt(string(r.Descriptor.ID), 10, 64)
if err != nil {
t.Fatalf("unexpected error: %v", err)
}
val := r.Value.(int)
if val != int(i)*2 {
t.Fatalf("wrong value %v; expected %v", val, int(i)*2)
}
case <-wp.Done:
return
default:
}
}
}
|
After looking at the code, we know that this is not a worker-pool in the traditional sense. It does not initialize a real worker-pool like the Handling 1 Million Requests per Minute with Go article, and once it receives a job, it tries to fetch a worker from the pool, give the corresponding job to the work for processing, wait for the work is processed, it is redirected to the work pool and waits to be utilized next time.