1. Go’s TCP network programming model for classical blocking I/O
The Go language has made rapid development over the past decade or so since its birth and has been widely accepted and used by developers around the world for a wide range of applications, including: Web services, databases, network programming, system programming, DevOps, security detection and control, data science, and artificial intelligence. The following are some of the results of the official Go 2020 developer survey.
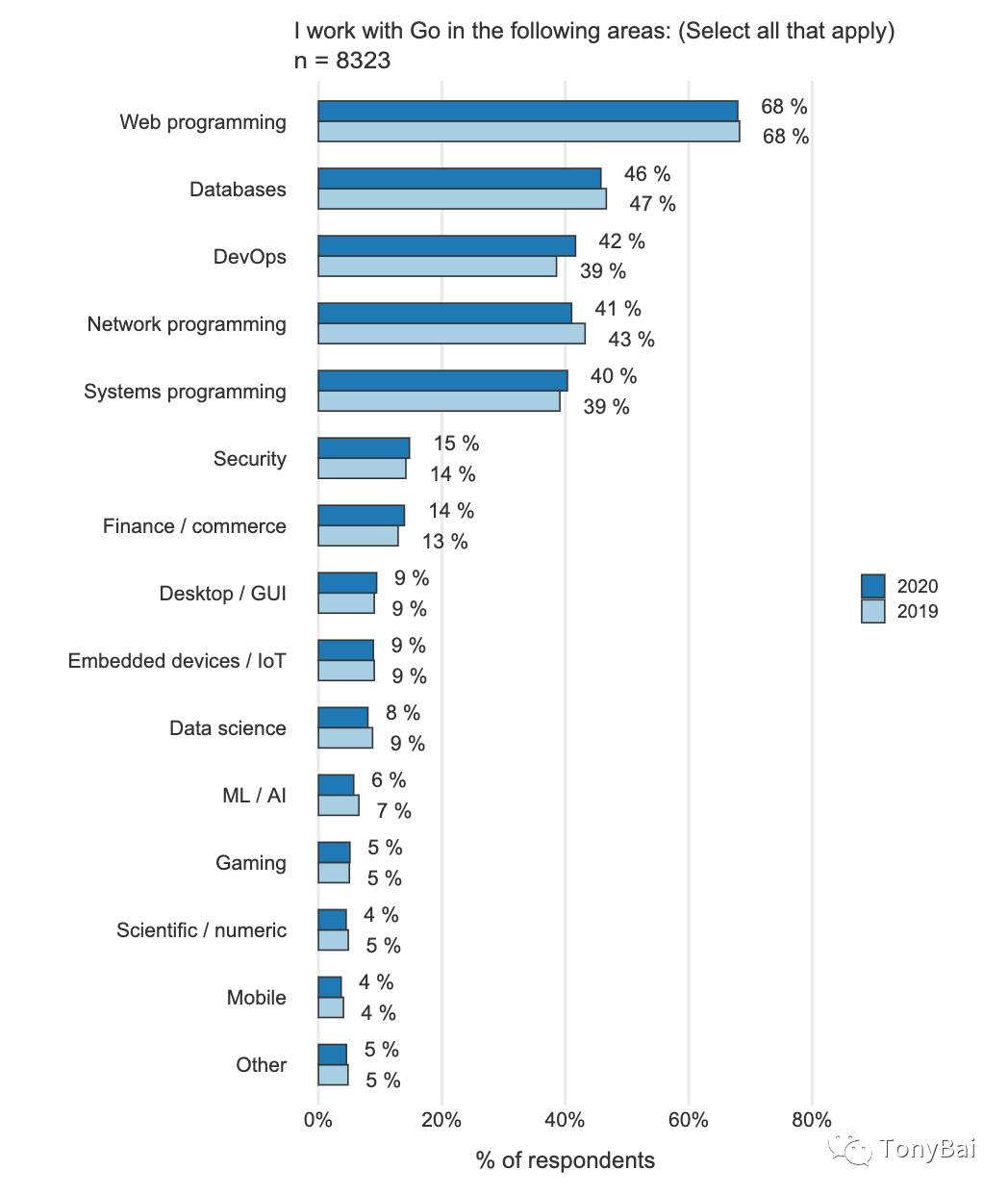
We see “Web Programming” and “Network Programming” in first and fourth place respectively, an application area data distribution that fits well with the Go language’s original design goals for large-scale distributed web services. Network communication This piece is an essential and critical part of server-side programming. net package of the Go standard library is the basis for network programming in Go. Even if you don’t use the functions/methods or interfaces of the net package for TCP sockets directly, you have always used the net/http package, which implements HTTP, the application layer protocol, and still uses TCP sockets at the transport layer.
Go is a cross-platform programming language with its own runtime. Due to the need of Go runtime scheduling, Go designs and implements its own TCP socket network programming model based on I/O multiplexing mechanism (epoll on linux, kqueue on macOS and freebsd). And, in keeping with its design philosophy of simplicity, Go exposes a simple TCP socket API interface to language users, leaving the “complexity” of Go TCP socket network programming to itself and hiding it in the Go runtime implementation. This way, in most cases, Go developers do not need to care about whether the socket is blocking or not, nor do they need to register the socket file descriptor callback function into a system call like epoll themselves, but simply do it in the simplest and easiest to use “blocking I/O model” in the corresponding goroutine for each connection. “Socket operations are performed in the simplest and easiest to use “blocking I/O model” in the goroutine corresponding to each connection (as shown in the figure below), a design that greatly reduces the mental burden on web application developers.
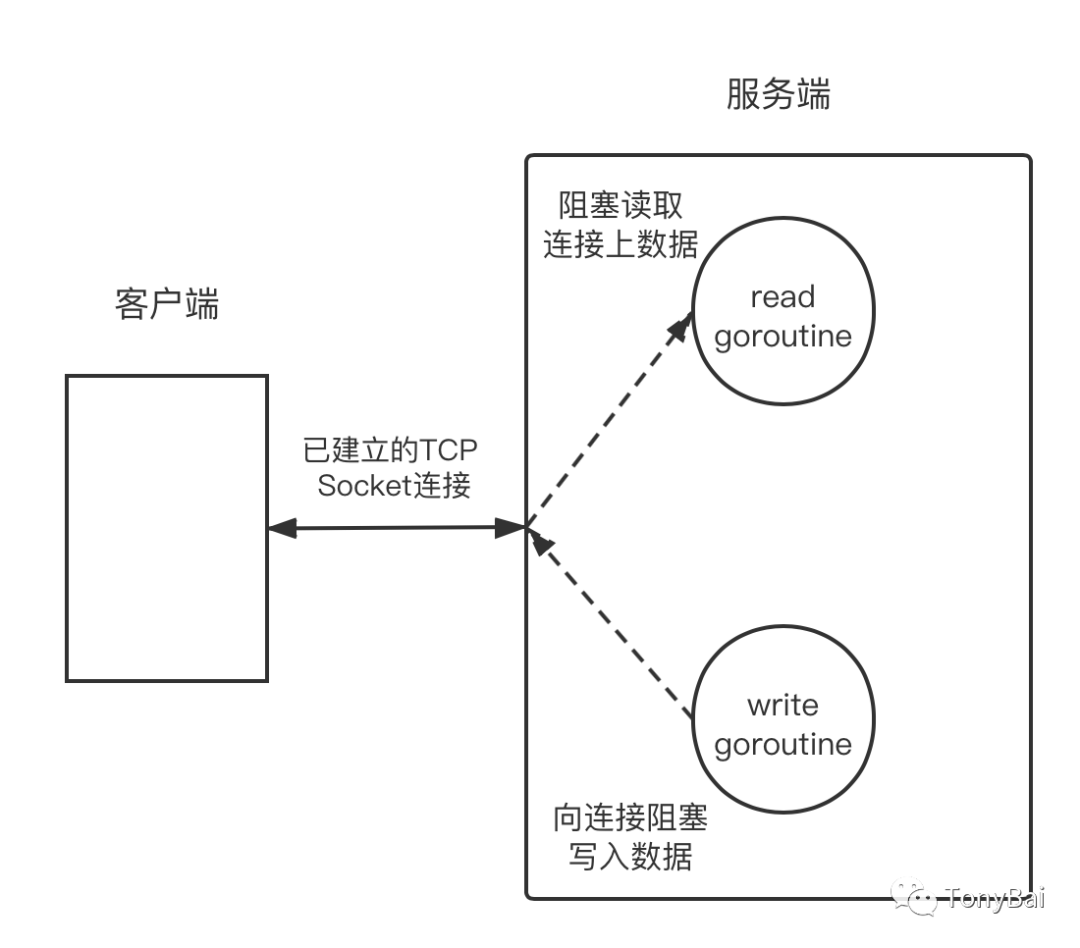
This is the classic Go tcp network programming model. Since TCP is a full-duplex model, each end (peer) can read and write separately on the established connection, so in Go we often create two goroutines for an established TCP connection, one for reading data from the connection (or the read goroutine can reply directly if a response (ack) is needed), and one for writing newly generated business data to the connection. one is responsible for writing the newly generated business data to the connection.
As an example, a typical program structure of a read goroutine is as follows.
|
|
From the above code, we see that for each successful connection established to the server, the program will start a reader goroutine responsible for reading data from the connection, and after processing, return (write to the connection) response (ack). The structure of this program is so straightforward that it can’t be any more straightforward. Even if you are a novice network programmer, it will not take many brain cells to understand such a program.
As we know, TCP Transmission Control Protocol is a connection-oriented, reliable, byte-stream-based transport layer communication protocol, so TCP socket programming is mostly stream data (streaming) processing. This data is characterized by sequential byte-by-byte transfers with no obvious data boundaries at the transport layer (only the application layer can identify protocol data boundaries, which depends on the definition of the application layer protocol). 1000 bytes are sent by the TCP sender and 1000 bytes are received by the TCP receiver. The sender may send the 1000 bytes in one send operation, but the receiver may read the 1000 bytes in 10 read operations, i.e. there is no strict one-to-one correspondence between the send action on the sender side and the receive action on the receiver side . This is fundamentally different from the datagram-based data transfer form of the UDP protocol (more on the differences between tcp and udp can be found in the book “TCP/IP Volume 1: Protocols”).
In this article we will look at the basic model for parsing custom TCP stream-based protocols based on the classic Go blocking network I/O model.
2. Brief description of the custom protocol
To facilitate the subsequent content development, we now describe here the custom stream protocol we are about to parse. There are two common modes of definition for TCP-based custom application layer flow protocols.
- Binary mode
Using length field separation, common ones include: mqtt (one of the most commonly used application layer protocols for IoT), cmpp (China Mobile Internet SMS gateway interface protocol), etc.
- Text mode
Use specific separators to segment and identify, common ones include http, etc.
Here we use binary mode to define the application layer protocols we are about to parse, and the following protocols are defined.

This is a request-response protocol. The first field of both the request and reply packets is the total packet length, which is the most important field used at the application layer to “split the packet”. The second field is used to identify the packet type, and here we define four types.
The ID is the flow of messages requested on each connection and is mostly used by the request sender to subsequently match the response packet. The only difference between the request packet and the response packet is the last field, the request packet defines the payload (payload), while the response packet defines the response status field of the request packet (result).
Once the definition of the application layer protocol packet is clear, let’s see how to parse such a stream protocol.
3. Create Frame and Packet abstractions
Before we actually start writing the code, let’s establish two abstractions for the above application layer protocols: Frame and Packet.
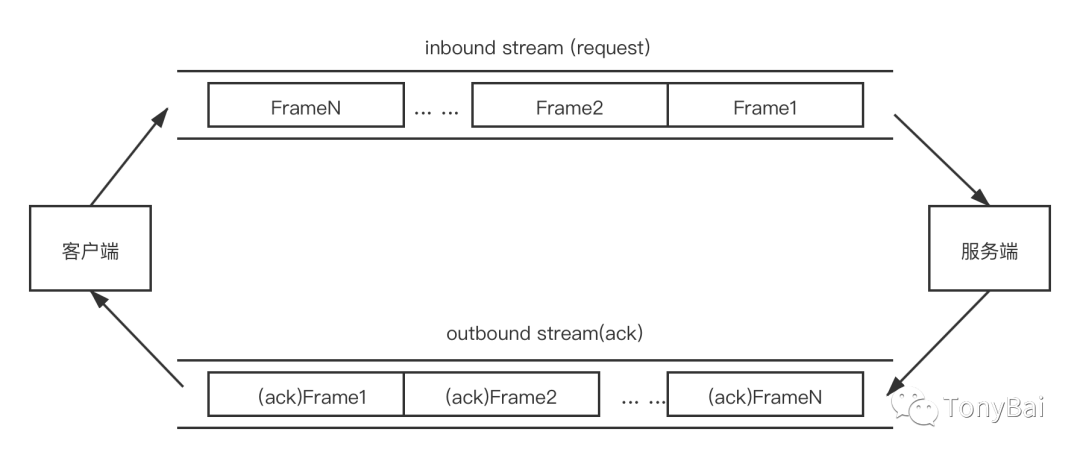
First, we set up the data flow from client to server or server to client, which is composed of one Frame after another, and the above protocols are encapsulated in these individual Frames. We can separate Frame from Frame by a specific method.
Each Frame consists of a totalLength and frame payload, as shown in the following left Frame structure.
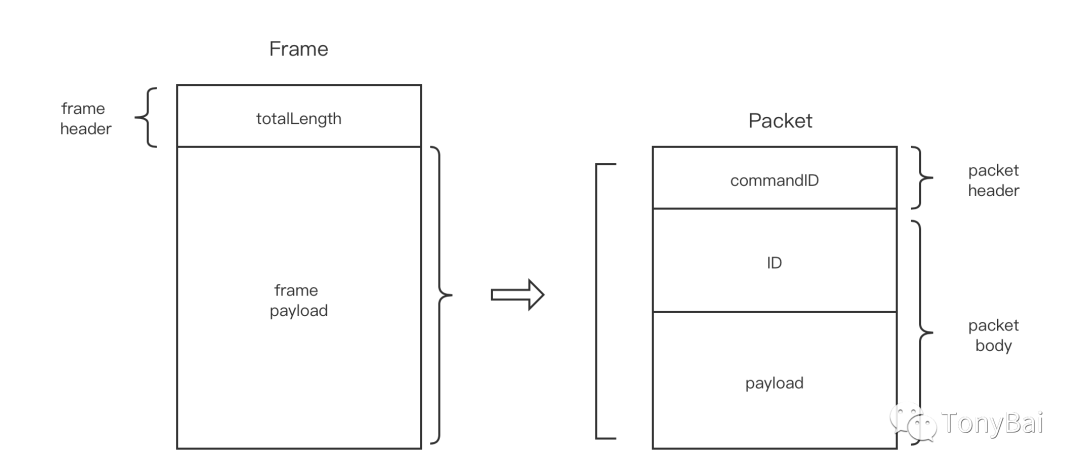
In this way, we can isolate the Frames from each other by using Frame header: totalLength. We define a Frame payload as a packet, and the structure of each packet is shown in the right side of the figure above. Each packet contains the commandID, ID and payload (packet payload) fields.
This way we convert the above protocol into a TCP stream consisting of two abstractions, Frame and Packet.
4. Basic program structure for blocking TCP stream protocol parsing
After creating the abstraction, we need to start parsing the protocol! The following diagram shows the server flow diagram for parsing the blocking TCP stream protocol.
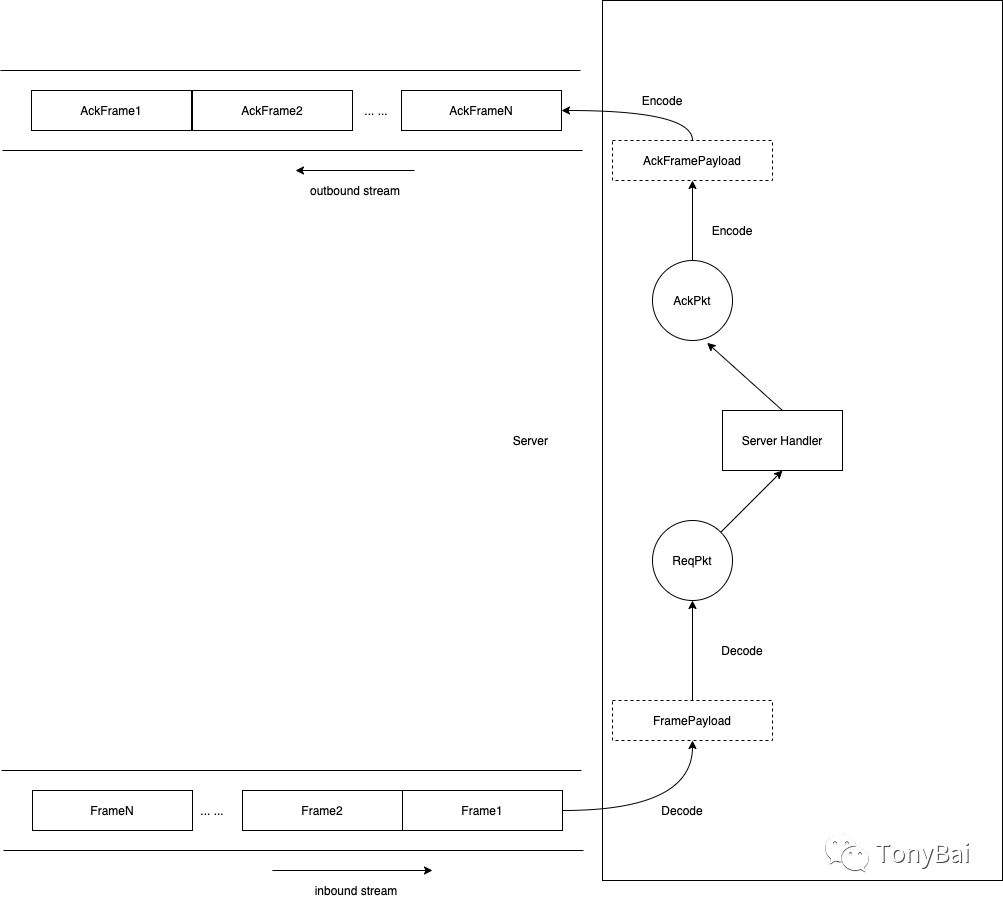
We see that the tcp stream data is successively decoded by frame decode and packet decode to get the packet data required by the application layer, and the response from the application layer is successively written to the tcp response stream after encoding by packet and encoding by frame.
Let’s take a look at the code of frame encoding and decoding. We first define the interface type of frame encoder.
|
|
We define the input of the stream data as io.Reader and the output of the stream data as io.Writer. As in the design sense in the above diagram, the Decode method returns the framePayload and Encode encodes the input framePayload into a frame and writes it to the outbound tcp stream.
Once the set of interface methods is defined, let’s give an implementation of the StreamFrameCodec interface.
|
|
In the above in this implementation, there are three points to note.
-
the network byte order uses BigEndian, so either Encode or Decode, we are using binary.
-
binary.Read or Write will read or write bytes corresponding to the number of bytes according to the width of the parameter, here totalLen uses int32, then Read or Write will only operate on 4 bytes in the stream.
-
ReadFull will generally read the full number of bytes you need, unless it encounters EOF or ErrUnexpectedEOF.
Next, let’s look at Packet codecs. Unlike Frame, Packet has multiple types (only Conn, submit, connack, submit ack are defined here). So let’s first abstract the common interface that these types need to follow.
Decode is to decode a byte stream data into a Packet type, which may be conn, submit, etc. (judged by the decoded commandID). Encode is to encode a Packet type into a byte stream data. The following is the Packet interface implementation for submit and submitack types.
|
|
However, the various types of codecs mentioned above are called only if it is clear what type the data stream is, so we need to provide an external function Decode at the package level, which is responsible for resolving the corresponding type from the byte stream (based on the commandID) and calling the Decode method of the corresponding type.
|
|
Similarly, we need packet-level Encode functions to call the corresponding Encode method to encode the object according to the incoming packet type.
|
|
Well, everything is ready but the wind! Let’s write the program structure to connect the tcp conn to Frame and Packet.
|
|
In the above program, the main function is the standard “one connection per goroutine” structure, and the key logic is in handleConn. In handleConn, we see a very clear code structure.
Here, a classic blocking TCP stream parsing demo is finished (you can verify it by running the client and server provided in the demo).
5. Possible optimization points
In demo1 above, we directly pass the net.Conn instance to frame.Decode as a real parameter to the io.Reader parameter, so that every time we call the Read method we are reading data directly from Conn. However, Go runtime uses net poller to convert net.Conn.Read to io multiplexed wait, avoiding the need to convert every direct read from net.Conn to a single system call. But even then, there may be one more goroutine context switch (in case the data is not yet ready). Although the cost of goroutine context switching is much smaller compared to thread switching, after all, such switching is not free and we want to reduce it. We can reduce the frequency of real calls to net.Conn.Read by caching the reads. We can transform the demo1 example like the following.
|
|
bufio internally tries to read the size of its internal cache (buf) from net.Conn each time, instead of the size of the data the user passed in that it wants to read. This data is cached in memory so that subsequent Reads can get the data directly from memory instead of reading from net.Conn each time, thus reducing the frequency of goroutine context switches.
In addition to this, our implementation of frame Decode in the frame package is as follows.
|
|
We see that each call to this method allocates a buf, and the buf is indefinite, these heap memory objects on the critical path of the program will bring pressure to the GC, we want to try to avoid or reduce its frequency, one possible way is to try to reuse the object, in Go when it comes to reuse memory objects, we think of sync. Pool, but there is a problem here, that is, “indefinite length”, which makes it more difficult to use sync.
mcache is a multi-level sync.Pool package open-sourced by the Bytedance technical team. It allows you to choose different sync.Pool pools depending on the size of the object you want to allocate. Somewhat similar to tcmalloc’s multi-level (class) memory object management, and Go runtime’s mcache is also similar. mcache is divided into a total of 46 levels, one sync.Pool per level.
We can allocate memory from mcache to replace the action of requesting a []byte each time to achieve memory object reuse and reduce GC pressure.
|
|
With mcache.Malloc, we need to call mcache.Free to return the memory object at a specific location, and Decode in the packet is the best place to do that.
The above are two of the more obvious optimization points that can be identified without using a tool like pprof, and there are probably many more, so I won’t list them all here.
6. simple stress test
Now that the optimization points are given, let’s roughly stress test the program before and after optimization. We add counters based on the standard library expvar to both versions of the program (take the pre-optimized demo1 as an example).
|
|
In the monitor package, we calculate the processing performance per second.
|
|
With the expvar-based counter, we can get the processing performance of the program per second by using the expvarmon tool with the export csv function (the compression test client can use the demo1-with-metrics client). The following performance comparison chart is obtained on a 4-core 8g cloud host (conditions are limited, and the press test client and server are placed on one machine, which is bound to interfere with each other).
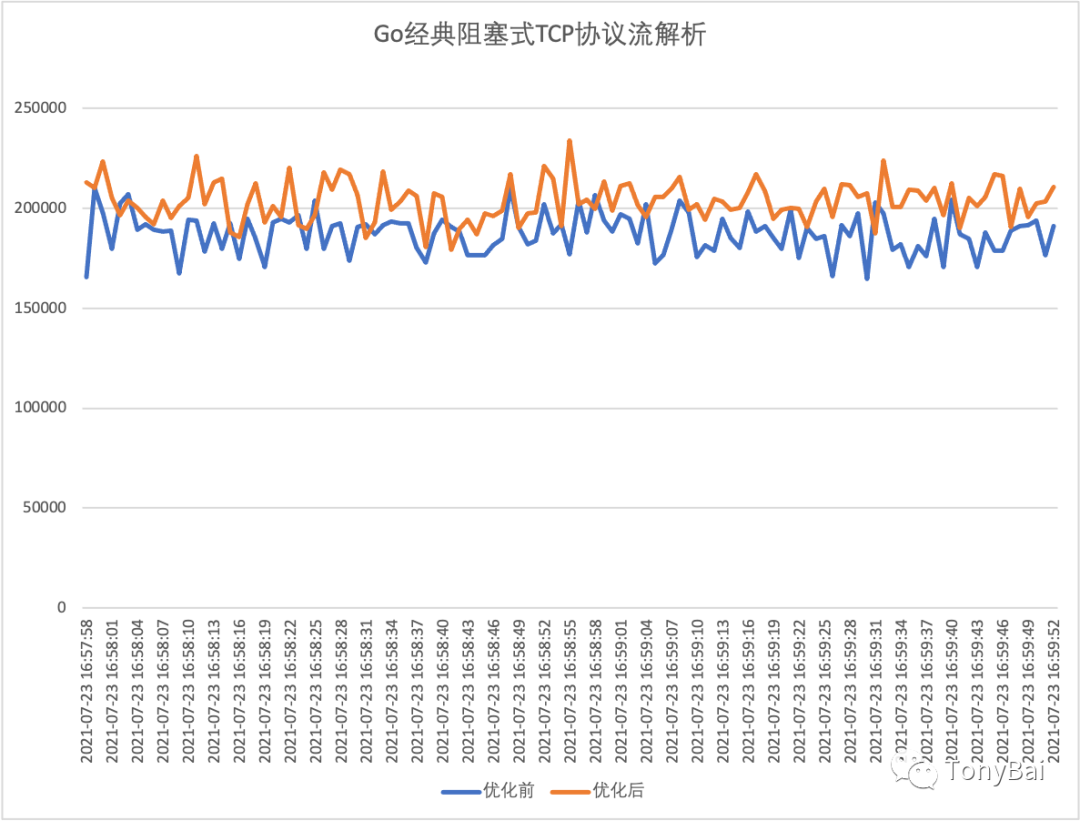
We see that the optimized program is slightly better than the pre-optimized one in terms of trend (though not very stable).
If you think collecting instantaneous values is too professional enough ^_^, you can also add a go-metrics-based metric to the program under test, and leave that assignment to everyone :)
7. Summary
In this paper, we have briefly illustrated the TCP network programming model for Go classical blocking I/O. The biggest benefit of this model is its simplicity, reducing the mental burden on developers when dealing with network I/O and focusing more attention on the business level. The paper gives a framework for parsing implementations of custom flow protocols based on this model and illustrates some optimization points that can be made. In non-mega-connection scenarios, such models can have good performance and development efficiency. Once the number of connections skyrockets, the number of goroutines handling these connections increases linearly, and the overhead of goroutine scheduling increases significantly, at which point we need to consider whether to use other models to cope, which we will talk about in subsequent chapters.
All the code involved in this paper can be downloaded from here https://github.com/bigwhite/experiments/tree/master/tcp-stream-proto