In the previous articles on advanced Git usage, we’ve learned how Git works and how to use rebase, merge, checkout, reset, etc. Basically, you can use Git without fear, and you can comfortably modify your commit history without losing any You can change your commit history without losing anything. Today, we’re going to add the final piece to the puzzle and learn about the cherry-pick command, which is not used in many scenarios, but can work wonders.
How to Use git cherry-pick
The Git command documentation is not necessarily intuitive, but it is absolutely accurate. The documentation describes git cherry-pick as Apply the changes introduced by some existing commits. Normally we would say that cherry-pick is moving a commit(s) from one branch to another, which is easier to understand, but we’ll explain later why the documentation is the most accurate description.
Suppose we have the following commits.
Now we want to move the e and f commits to the master branch, first we need to switch to master.
|
|
The usage of the cherry-pick command is straightforward, just execute cherry-pick on one or more commits that need to be moved, and note that here we use letters to refer to the actual commit SHA-1 ID.
|
|
The submission history after implementation is as follows.
The actual result is the creation of two new commits f' and g' in the master branch, which have different IDs from f and g.
Usage Scenarios
From the above command explanation, cherry-pick achieves a relatively simple effect, and it looks overlapping with merge and rebase, so let’s see the actual usage scenario of cherry-pick.
Emergency Bug Fixes
Usually in a product Git workflow, there is at least one release branch and a development master branch. When a bug is found, we need to provide a patch to the released product as soon as possible, and also integrate the patch into the main development branch.
For example, let’s say we have a release and have started developing some new features, and during the development of the new features, an existing bug is found, and we create an emergency fix commit to fix the bug and integrate it into the development master branch for testing. This new patch commit can be merged into the development master branch and then directly cherry-pick to the release branch to fix the bug before it affects more users, as illustrated below.
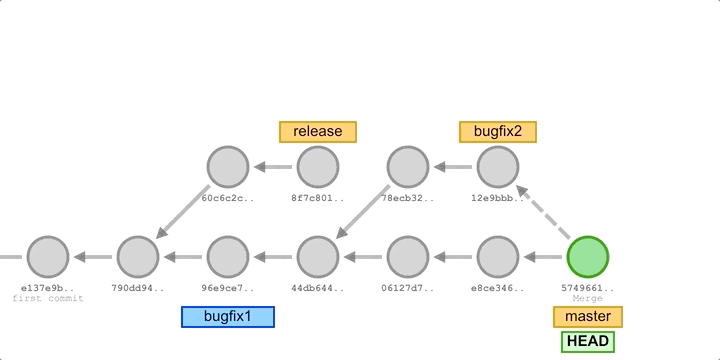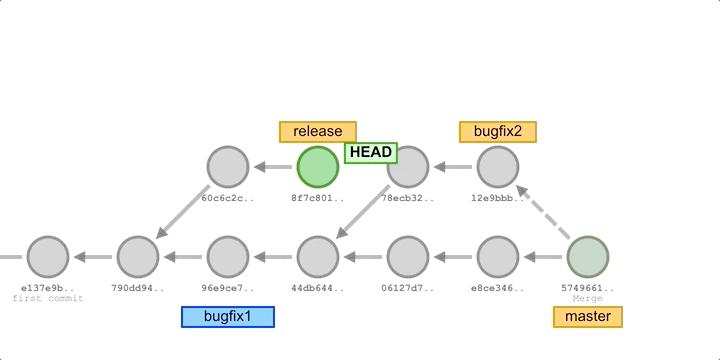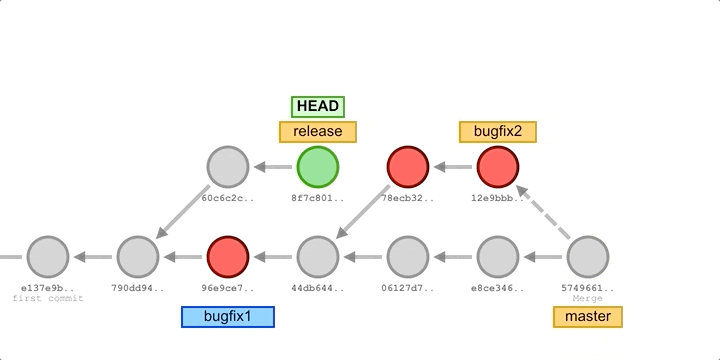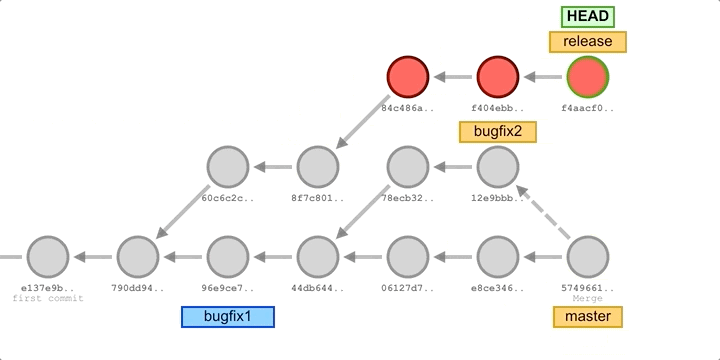
In the above image, we’ve added some new commits to the main development branch master, fixed some bugs and merged in two bugfix branches, and then cherry-picked all the commits from the bugfix branch to the release branch. In some Git workflows, you might create a bugfix branch based on the release branch, and then cherry-pick those commits to the master after merging in the release.
Picking individual commits from abandoned branches
Sometimes a feature branch may become obsolete due to changing requirements and not be merged into the master branch. Sometimes, a Pull Request may be closed without a merge. We can use commands like git log and git reflog to find some useful commits and cherry-pick them into the master branch.
Other scenarios
There are other scenarios where you can use cherry-pick to move a commit to the right branch if you created it on the wrong branch without realizing it, or if you want to take a commit that a team member developed on another branch to your own branch for some reason, and so on.
In these limited scenarios, we can use rebase or merge with reset to achieve the same effect, but the advantage of cherry-pick is that it is simple and straightforward enough that a single command can achieve what would otherwise require a series of commands. However, we still need to use cherry-pick with caution and be aware of some of its dangers.
In-depth understanding of cherry-pick
Suppose we have a code repository that has just added main.py via commit A. The contents of the main.py file are as follows.
Now we create a new new-feature branch for subsequent modifications.
|
|
First create a commit B, add a new file setup.py and make the following changes to main.py.
Then we created another commit C, added a new file README.md and continued to add a line of code to main.py.
Finally, we switch back to master at the beginning and execute cherry-pick on the latest commit C of new-feature.
The implementation process is simple and is illustrated below.
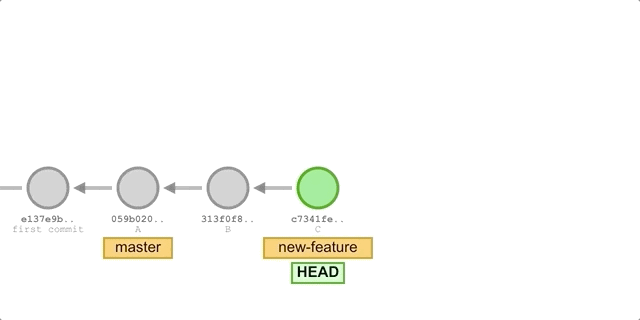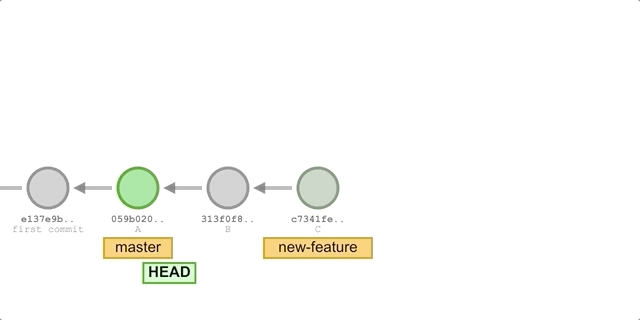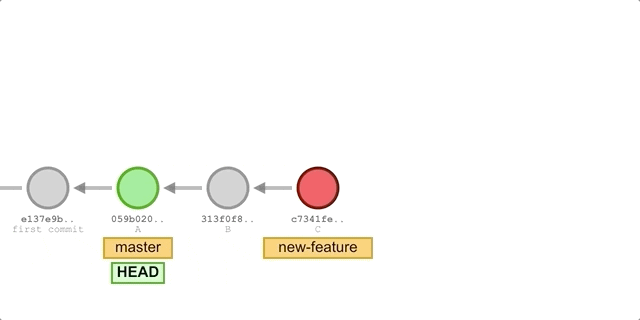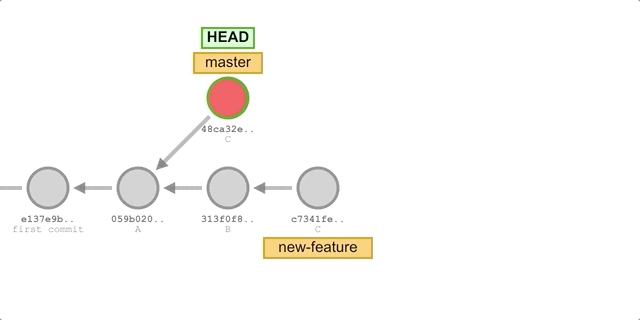
But now let’s guess, how many files does master have now? How many lines of print statements will there be in main.py?
The correct answer is: we will encounter a merge conflict 😝. After resolving the conflict, we will have a modified main.py file and a newly added README.md file in commit C.
Why would this be the case? Using this example, let’s take a deeper look at how cherry-pick is actually executed.
What changes are applied
Each commit is a complete snapshot of the files, but it is clear from the example that the cherry-pick process does not apply all the files in the target commit (otherwise the current master would contain the setup.py file added in commit B), but only the files that have changed in the target commit (README.md and main.py). It follows that the statement “moving a commit from one branch to another” is inaccurate, and that cherry-pick only applies the changes introduced in the target commit, i.e., the files that have changed in that commit.
How to apply
Having established that cherry-pick will only apply the changed files in the target commit, let’s look at the process of applying the changes. Internally, “apply” is a three-way merge, just like merge. This time we’ll represent the parties in a three-way merge in a different way, when we run git cherry-pick <commit C>.
- LOCAL: The merge is performed on top of that commit (i.e., the HEAD of the branch you are currently on).
- REMOTE : The commit you are targeting with
cherry-pick(i.e.<commit C>). - BASE: The parent commit of the commit you want to
cherry-pickon (i.e. C^, the previous commit of C), usually the common ancestor of LOCAL and REMOTE (but maybe not, as in this example).
The execution of cherry-pick is a three-way merge with BASE as the base and LOCAL and REMOTE as the content to be merged, and the result of the merge is added as a new commit after LOCAL (the details of the algorithm execution are not described). We can verify this by the following.
-
First, change the
merge.conflictstylein the example Git repository todiff3.1$ git config merge.conflictstyle diff3 -
Then re-execute the example steps above and look at the contents of the
main.pyfile where the merge conflict occurred.Compared to the regular
diffdisplay of LOCAL and REMOTE,diff3displays one more side from BASE via|||||||. From the results, we can confirm that BASE is the parent commit of commit C (i.e., commit B).
Handling conflicts
Conflicts in cherry-pick are handled in the same way as rebase and merge. We look at the conflicting files with git status, modify them and remove the special tags, mark them as resolved with git add, and finally commit the changes with git commit.
During conflict resolution, we can also run git cherry-pick --continue to commit everything after resolving all conflicts, use git cherry-pick --skip to skip this commit while processing multiple commits, or use git cherry-pick --abort to cancel the cherry-pick operation and revert to the state before the operation was performed.
Summary
git cherry-pick is not widely used, it can be useful in some specific scenarios, but since its merge mechanism risks introducing unexpected file changes, we should be careful when using it to consider the possible results.
There are two other easy misconceptions about cherry-pick that need to be clarified.
cherry-pickdoes not apply a snapshot of the entire file represented by the commit, but only affects the files that were added, deleted, or changed in that commit.cherry-pickdoes not simply apply thediffcontents of the target commit and its parent commit, but instead does a three-way merge internally between the current branch pointing to the commit and the target commit using that parent commit as a base, so there is a possibility of merge conflicts.