ElasticSearch Operator
The core features of the current ElasticSearch Operator.
- Elasticsearch, Kibana and APM Server deployments
- TLS Certificates management
- Safe Elasticsearch cluster configuration & topology changes
- Persistent volumes usage
- Custom node configuration and attributes
- Secure settings keystore updates
Installation
Installing ElasticSearch Operator is very simple, based on ‘all in one yaml’, quickly pulling up all the components of Operator and registering the CRD.
|
|
CRD
Operator has registered three main CRDs: APM, ElasticSearch, Kibana.
ElasticSearch Cluster Demo
A complete ElasticSearch Cluster Yaml, including the creation of ES clusters, local PV and Kibana.
|
|
Operator management of ElasticSearch
Like many declarative Api-based implementations of the Operator, the focus of the Elastic Operator revolves around the Reconcile function.
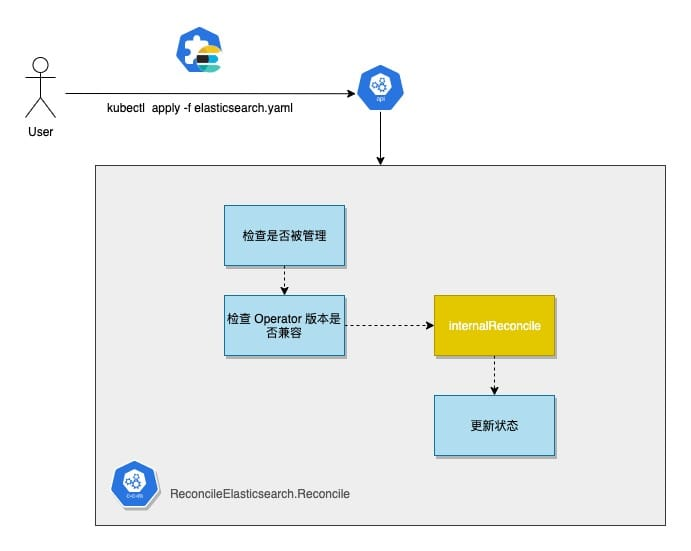
The Reconcile function completes the entire lifecycle management of the ES cluster, which is of interest to me and briefly explains the implementation of the following functions.
- configuration initialization and management
- scale up and scale down of cluster nodes
- lifecycle management of stateful applications
Cluster creation
After receiving an ElasticSearch CR, the Reconcile function first performs a number of legitimacy checks on the CR, starting with the Operator’s control over the CR, including whether it has a pause flag and whether it meets the Operator’s version restrictions. Once it passes, it calls internalReconcile for further processing.
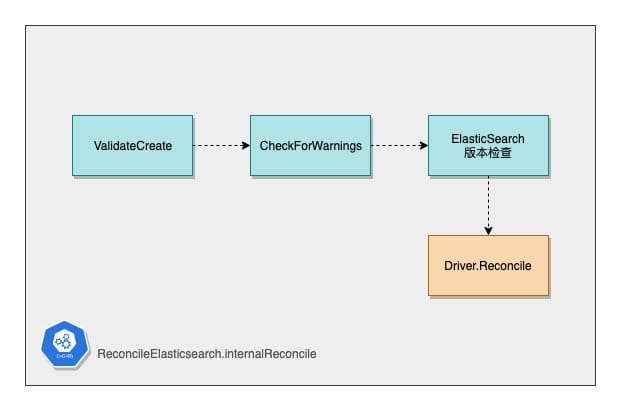
The internalReconcile function begins by focusing on checking the business legitimacy of ElasticSearch CRs by defining a number of validations that check the legitimacy of the parameters of the CRs that are about to perform subsequent operations.
|
|
Once the ES CR legitimacy check is passed, the real Reconcile logic begins.
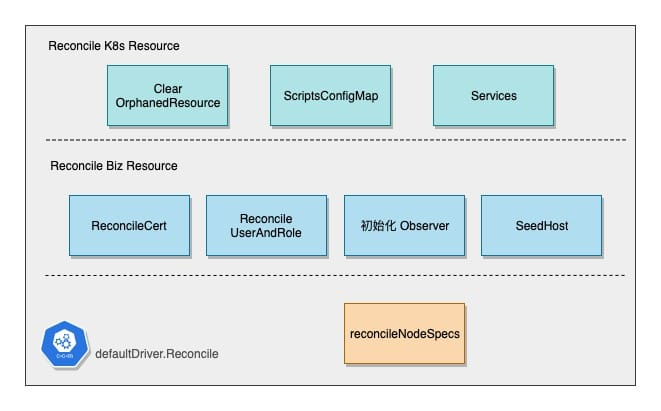
I have divided the subsequent Driver operations into three parts.
- Reconcile Kubernetes Resource
- Reconcile ElasticSearch Cluster Business Config & Resource
- Reconcile Node Spec
The first step is to clean up the mismatched Kubernetes resources, then check and create the Script ConfigMap, and the two Services.
ElasticSearch will use two services, which are created and corrected in this step.
- TransportService: headless service, used by the es cluster zen discovery
- ExternalService: L4 load balancing for es data nodes
Script ConfigMap is an operation that surprised me, because ES Cluster is stateful, so there is part of the startup initialization and downtime wrap-up. Operator generates the relevant scripts and mounts them to the Pod via ConfigMap and executes them in the Pod’s Lifecycle hook. The Operator renders three scripts, which are also self-explanatory in their naming:
readiness-probe-script.shpre-stop-hook-script.shprepare-fs.sh
After the K8s resources are created, other dependencies needed for the ES cluster to run, such as CAs and certificates, user and permission profiles, seed host configuration, etc., are created with the appropriate ConfigMap or Secret and are waiting to be injected into the Pod at startup.
In addition, the Operator also initializes the Observer here, which is a component that periodically polls the ES state and caches the latest state of the current Cluster, which is also a disguised implementation of Cluster Stat Watch, as will be explained later.
Once these startup dependencies are ready, all that remains is to create the specific resources to try to pull the Pod up.
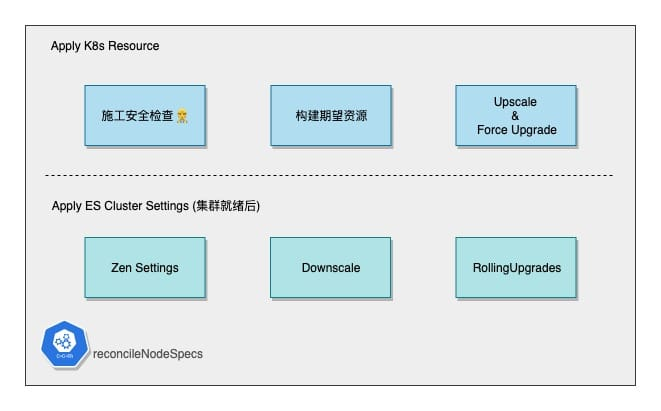
Formal creation and correction of ES resources is done in two phases, with the watershed being the readiness of the ES Cluster (whether the ES cluster is accessible via Service).
The first phase starts with a construction security check.
- the local cache of resource objects meets expectations
- whether the StatefulSet and Pods are in order (number of Generations and Pods)
Then the expected StatefulSet & Service resources are constructed according to the CR and the subsequent operation is to try to approximate the final state constructed here.
For the resources described in the end-state, the Operator will create a limited flow, which is a bit more complicated here, but the basic process is to gradually modify the number of copies of the StatefulSet until it reaches the expectation.
If there is an old Pod that needs to be updated, the Pod will be deleted by a simple and effective delete po to force the update. This is the end of the first phase, and the associated K8s resources are basically created.
However, the creation of the ES cluster is not yet complete. Once the Operator can access the ES cluster through the http client, the second phase of creation is performed.
The first step is to adjust the Zen Discovery configuration based on the current Master count and the Voting-related configuration.
Later on, we will scale down and roll upgrade, but the creation of the cluster is complete.
Rolling Upgrades
Since ElasticSearch is a stateful application like a database, I am interested in ES cluster upgrades and subsequent lifecycle maintenance. In Reconcile Node Specs, Scale Up is relatively simple to do, thanks to ES’s domain-based self-discovery via Zen, so new Pods are automatically added to the cluster when they are added to Endpoints.
However, since each node maintains part of the shard, node offline or node upgrade will involve the handling of shard data.
|
|
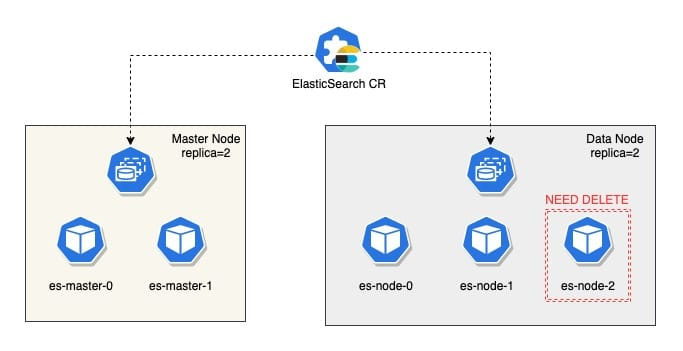
The logic of Scale Down, or downline nodes, is not complicated and still involves calculating the difference between the expected and current. Determine to what amount the StatefuleSet should adjust the replica.
If the replica is zero, the StatefulSet is deleted directly, if not, the node downs are started.
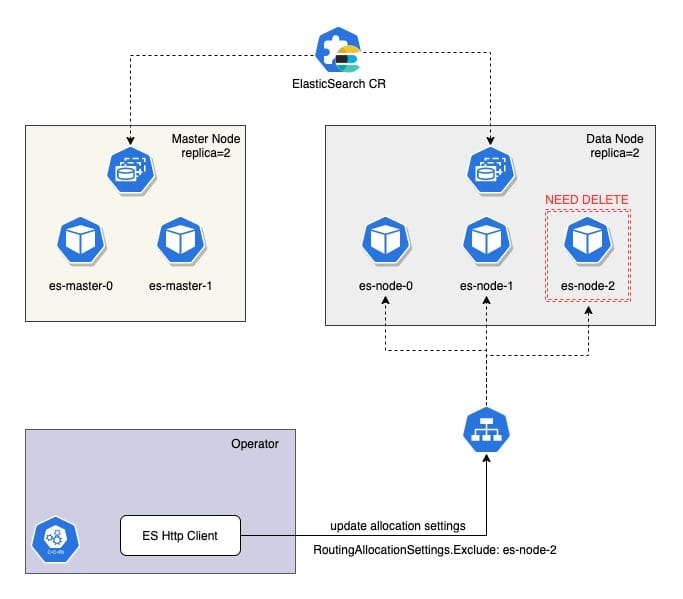
The first step is to calculate which Nodes need to be taken offline, and then trigger the reallocation of shards through the setting api to exclude the Nodes that will be taken offline.
Finally, it checks if the shard in the Node is cleared, and if not, it requeue for the next processing, and if it is cleared, it starts the real update replica operation.
The first step is to calculate the old and new resources and clear the old ones. After the clearing is done, ShardsAllocation is opened via ES Client to ensure the recovery of shards in the Cluster.
Watch
As mentioned above, the ElasticSearch Operator has a built-in Observer module that implements Watch for ES cluster state by polling.
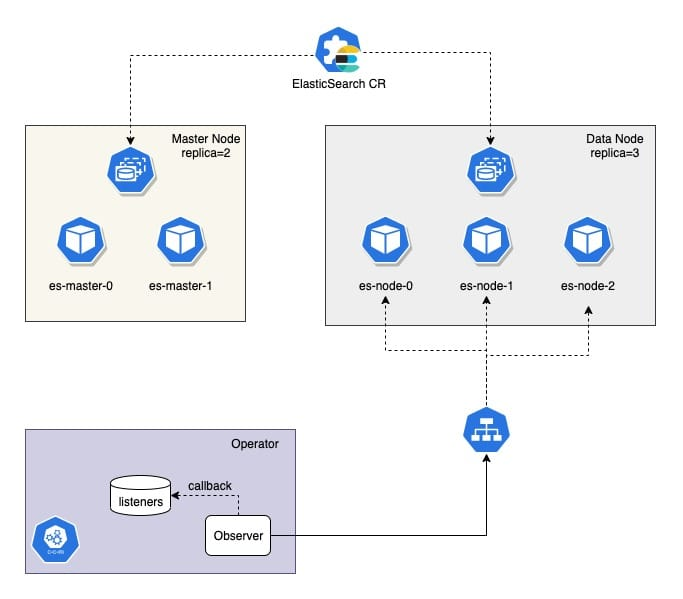
ObserverManager manages several Observer, each ES Cluster has a single instance of Observer and polls the state of ES Cluster regularly. If the state changes, it will trigger the registered listeners.
There is only one listener implemented, healthChangeListener, which is very simple, it is to send an event to the chan when it finds a state change, and the cluster health has changed.
|
|
The chan is related to the Watch capability provided by contoller-runtime, which triggers the Reconcile process started by the Operator when an event is posted. This enables the discovery of a change in the business state and the continuation of the CR to the Operator for correction.
|
|
Operator’s License Management
ElasticSearch is a commercially licensed software, and the license management in Operator really gives me a new understanding of App On K8s license management.
At the end of last year, I was involved in the development of a K8s-based system, and I was confused about how to manage the license of a “cloud operating system” like K8s, and ES Operator gave me a concrete solution.
The first is the structure of the license, Operator defines two kinds of licenses, one is the license provided to ES Cluster, and this model will be applied to the ES cluster eventually.
|
|
The other is the License structure that is managed by the Operator, which performs verification and logical processing based on these models.
|
|
License validation and use
The Operator’s License is simple but adequate (probably legal enough), and is done by the License Controller and ElasticSearch Controller together.
The License Controller watches the ElasticSearch CR, and after receiving a new event, it looks for a Secret containing a License under the same Namespace as the Operator, and looks for an available License based on the expiration time, ES version, and other information.
Then, using the public key injected at the compilation stage, the License is checked for signature, and if it passes, a specific Secret (Cluster Name with a fixed suffix) containing the License is created for the ElasticSearch CR.
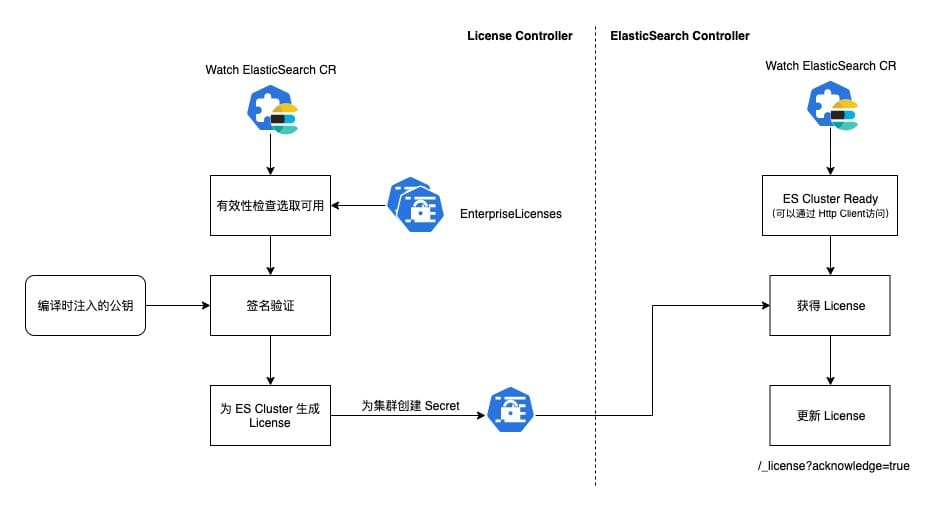
The ElasticSearch Controller is the main controller that manages the life cycle of ElasticSearch and determines if the ES Cluster is ready after receiving events from the CR (Http requests can be made through the Service). If it is ready, it will look for the Secret containing the License according to the name convention, and if it exists, it will update the License through the Http Client.
Summary
As a stateful application, ElasticSearch Operator not only manages K8s In addition to managing K8s resources, the ElasticSearch Operator also uses the ES Client to complete lifecycle management through a babysitting service. This is a clever design, but it relies heavily on the ES Cluster’s own self-management capabilities (e.g., rescheduling of data slices, self-discovery, etc.).
If the stateful application that needs to be managed does not have such perfect self-management capabilities, each correction operation will require multiple requeue reconcile to complete, which will inevitably make the recovery time long. For stateful applications, the longer the recovery time (downtime), the more damage is done. Perhaps it is a better direction to separate instance management (Pod management), and business management (application configuration and data recovery, etc.).