This article will explain the basic operations of concurrent programming in Python. Concurrency and parallelism are twin brothers, and the concepts are often confused. Joe Armstrong, the father of Erlang, has a very interesting diagram that illustrates these two concepts.
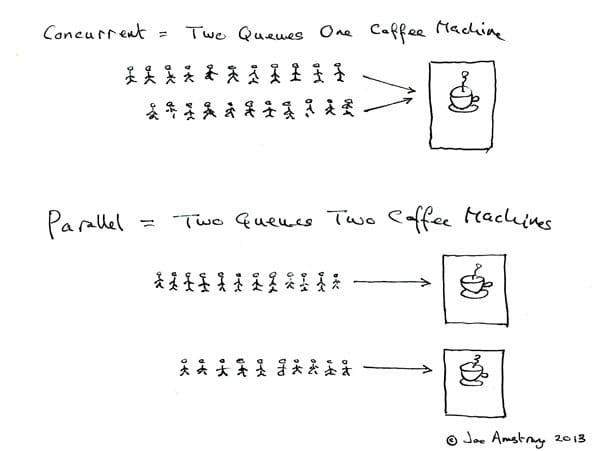
One of my personal preferences is that concurrency is macro-parallel and micro-serial.
GIL
While Python comes with great class libraries to support multithreaded/processed programming, it is well known that Python has a hard time doing true parallelism well because of GIL.
GIL means Global Interpreter Lock, and for an introduction to GIL.
Global Interpreter Lock (English: Global Interpreter Lock, abbreviated GIL), a mechanism used by computer programming language interpreters to synchronize threads, which allows only one thread to be executing at any given moment.
Wikipedia
In fact, the GIL is more a limitation of CPython than of the Python interpreter, because Python is mostly implemented in C for performance, and CPython’s memory management is not thread-safe, so the interpreter prohibits parallel execution of multiple threads in order to ensure overall thread safety.
Because the Python community believes that the operating system’s thread scheduling is already very mature, there is no need to implement it again, so Python’s thread switching is basically dependent on the operating system, and in practice, GIL does not have much effect on single-core CPUs, but introduces the problem of thrashing for multi-core CPUs.
Thread thrashing is a phenomenon where a GIL lock, which is a single resource, is additionally consumed by multiple cores competing for its use.
For example, in the figure below, after thread 1 releases the GIL lock, the OS wakes up thread 2 and assigns it to core 2, but if thread 2 does not successfully obtain the GIL lock, it is hung again. At this point, the resources for switching threads and contexts are wasted.
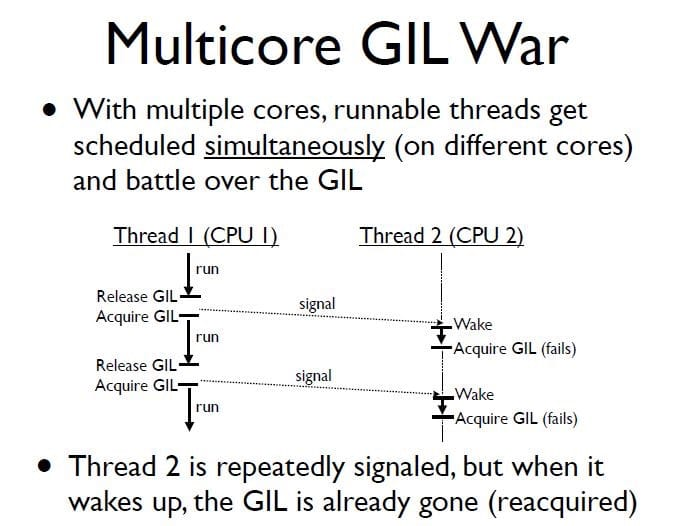
As a result, Python multithreaded programs do not necessarily perform better on multicore CPU machines than on single cores. For computationally intensive programs, then, it is generally better to consider rewriting key parts in C, or using multiple processes to avoid GIL.
Multithreading
To use multithreading in Python, there are thread and threading available as a matter of principle. thread provides low-level, primitive threads and a simple lock, and because thread is too rudimentary and thread management is prone to human error, threading is officially more recommended, and threading is just a wrapper around thread. (thread was renamed _thread in Python3).
Creating threads in Python is very simple.
|
|
Creating threads directly is simple and elegant, or if the logic is complex, multi-threading can be accomplished by inheriting from the Thread base class.
|
|
Multiprocessing
In Python, you can use the multiprocessing library to implement multiprocess programming. As with multithreading, there are two ways to use multiprocess programming.
Create processes directly.
|
|
Inherits the process parent class.
|
|
In addition to the common multiprocessing programming, I think the most significant aspect of multiprocessing is that it provides a set of specifications, and under this library there is a dummy module, multiprocessing.dummy, which wraps threading and provides a thread implementation with the same API as multiprocessing. In other words, class::multiprocessing.Process provides a process task class, while class::multiprocessing.dummy.Process, with the existence of multiprocessing.dummy, provides the same API for thread implementation as multiprocessing. can quickly change a multiprocessing program into a multithreaded one.
|
|
This is the reason why I usually choose multiprocessing, both for multi-threaded and multi-processed programming.
In addition to creating processes directly, you can also use process pools (or process pools in multiprocessing.dummy).
|
|
Thread pool.
|
|
There’s a problem with the example where the pool needs to be closed before it joins, otherwise an exception is thrown, but Tim Peters, author of Python’s Zen, explains.
As to Pool.close(), you should call that when - and only when - you’re never going to submit more work to the Pool instance. So Pool.close() is typically called when the parallelizable part of your main program is finished. Then the worker processes will terminate when all work already assigned has completed.
It’s also excellent practice to call Pool.join() to wait for the worker processes to terminate. Among other reasons, there’s often no good way to report exceptions in parallelized code (exceptions occur in a context only vaguely related to what your main program is doing), and Pool.join() provides a synchronization point that can report some exceptions that occurred in worker processes that you’d otherwise never see.
Synchronization Primitives
In multi-process programming, there is no need to consider thread safety in memory because of resource isolation between processes, but in multi-threaded programming, you need synchronization primitives to preserve thread safety.
Locks can be used to protect a section of memory space, and semaphores can be shared by multiple threads.
In threading you can see two types of locks: Lock locks and RLock reuse locks, with the differences as named. Both locks can only be owned by one thread. The first lock can only be acquired once, while the reuse lock can be acquired multiple times, but also requires the same number of releases before it can actually be released.
Strange problems are often encountered when multiple threads make changes to the same memory space at the same time.
|
|
As above is a typical non-thread-safe result of count not achieving the desired effect. The lock allows you to control access to a certain piece of code, or a certain memory space.
|
|
Of course, the above example is very violent, directly forcing concurrency to serial.
For semaphores, which are commonly used in scenarios where limited resources are strongly occupied, you can define a fixed size semaphore for multiple threads to obtain or release, thus controlling the execution of tasks by threads, such as the following example, which controls up to 5 tasks in execution.
|
|
Queue and Pipe
Because of the memory isolation of multiple processes, there is no memory contention problem. However, at the same time, data sharing between multiple processes becomes a new problem, and inter-process communication is common: queue, pipe, and signal.
Only queues and pipes are explained here.
Queues are commonly used in the two-process model and are generally used in the producer-consumer mode, where the producer process issues tasks to the queue and the consumer takes out tasks from the queue head for execution.
|
|
In theory each process can read or write to the queue, which can be thought of as a half-duplex route. But often there are only specific read processes (e.g. consumers) and write processes (e.g. producers), even though these processes are only defined by the developer.
Pipe, on the other hand, is more like a full-duplex route.
|
|
Libraries
In addition to the threading and multiprocessing libraries described above, there is also a ridiculously useful library called concurrent.futures. Unlike the previous two libraries, this one is a higher level of abstraction and hides a lot of the underlying stuff, but is also very useful for that reason. Use the official example.
The library comes with process and thread pools that can be managed by the context manager, and it is very easy to get the results for asynchronous tasks after they are executed. Let’s conclude with another official example of multi-process computing.
|
|