A colleague saw the puzzling goexit when debugging with dlv: what is the goexit function and why is it on top of go fun(){}()? It looks like an “exit” function, so why is it at the top?
In fact, if you have seen the pprof flame chart, you will often see the goexit function.
Let’s reproduce it with an example.
Start dlv debugging with separate breakpoints at the following locations.
Execute the command c to the breakpoint, and then execute the command bt to get the call stack of the main function.
Its upper layer is runtime.main, find the original code location, located in src/runtime/proc.go in the main function, it is the main goroutine of the Go process, here will perform some init operations, open GC, execute the user main function… …
where fn is the main_main function, which represents the user’s main function, and where the execution really gives power to the user.
Continuing with the c command and the bt command, we get the call stack for the go line.
and the call stack for the line println.
As you can see, the top of the call stack is runtime.goexit, and we follow the lines of code indicated to find the goexit code.
This is also an assembly function that then calls the goexit1 and goexit0 functions, whose main function is to zero out the fields of the goroutine and put them in the gFree queue for future reuse.
On the other hand, the address of the goexit function is shoved onto the stack during the creation of the goroutine. The CPU is given the “false impression” that func() is called by the goexit function. This way, when func() finishes executing, it returns to the goexit function to do some cleanup work.
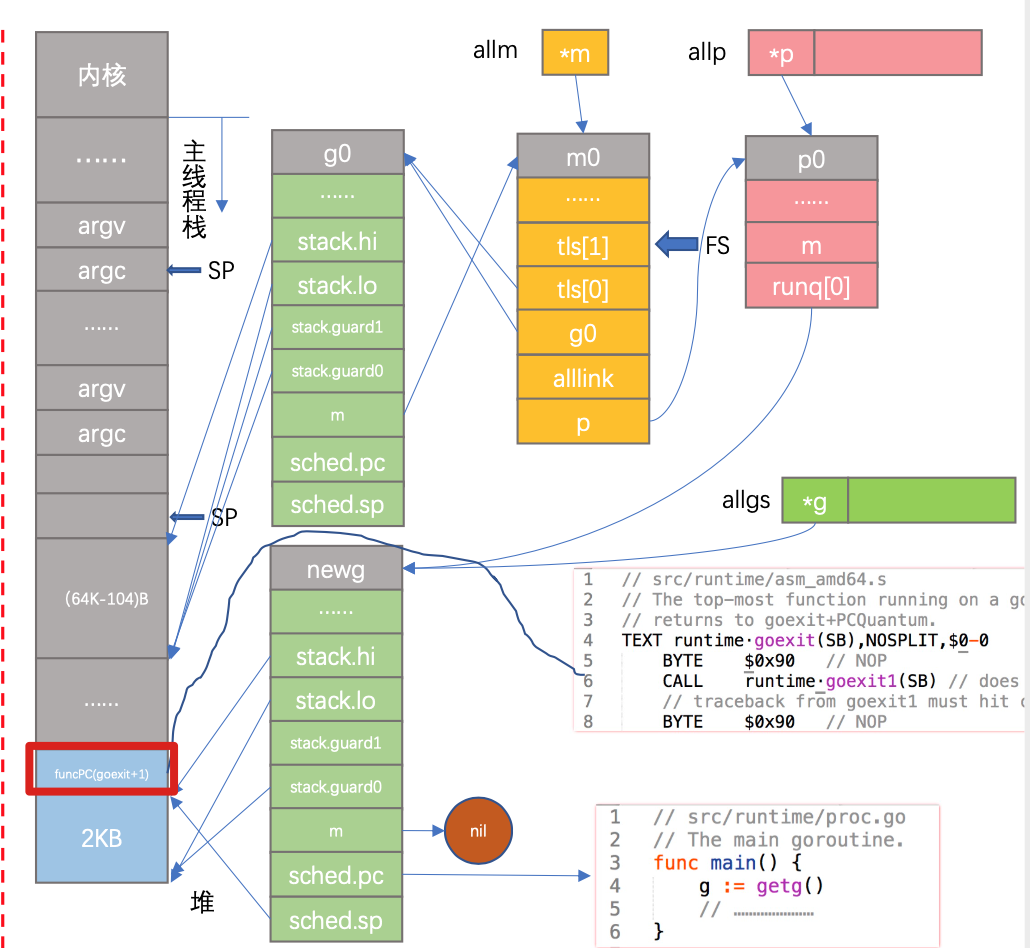
The following diagram shows that the address of the goexit function is tucked at the bottom of the stack of newg.
The corresponding paths are
|
|
Take a look at the key lines of code in newproc1.
The newg here is the goroutine created, and each new goroutine will execute this code. The sched structure is actually the execution site of the goroutine, where the execution progress of the goroutine is stored whenever it is called off the CPU. The progress is mainly SP, BP, and PC, which represent the top-of-stack address, bottom-of-stack address, and instruction location respectively. When the goroutine gets the execution right from the CPU again, it will load SP, BP, and PC into the registers to resume running from the breakpoint.
Back to the above lines of code, pc is assigned to funcPC(goexit) and finally in gostartcall.
|
|
sp is actually the top of the stack, line 7 of the code put buf.pc, that is, the address of goexit, in the place of the top of the stack, familiar with Go function call statute friends know that this location is actually return addr, in the future, and so func() execution is completed, will return to the parent function to continue to execute, here the parent function is actually goexit. goexit`.
Everything is already predetermined.
But note that the difference between the main goroutine and the normal goroutine is that the former, after executing the user’s main function, will directly execute the exit call and the whole process will exit.
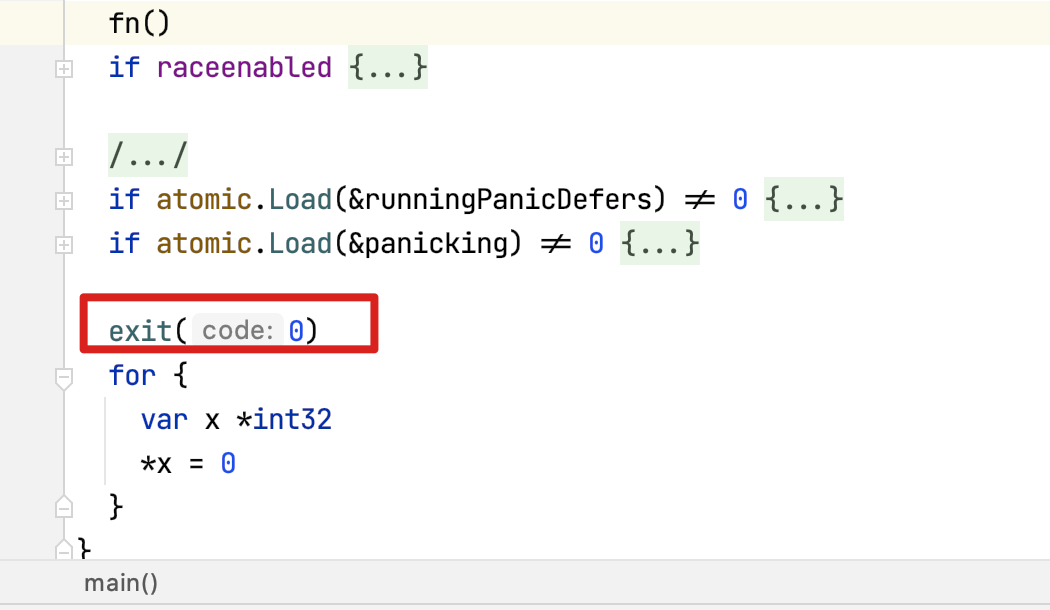
It does not go to the goexit function. Instead, when the normal goroutine finishes executing, it goes directly to the goexit function and does some cleanup work.
That’s why as soon as the main goroutine finishes executing, it doesn’t wait for other goroutines and just exits. Everything is because of the exit call.
Today we talked about how goexit is placed on the stack of a goroutine, so that it can return to the goexit function after the goroutine is finished executing.
Isn’t it clearer what seemed to be very difficult to understand?
There are no secrets in front of the source code.